融合核密度估计和奇异值分解的多样化推荐算法
2020-01-08李卫疆罗潘虎
李卫疆,罗潘虎
(昆明理工大学 信息工程与自动化学院,昆明 650500)
1 引 言
随着互联网的发展,互联网信息的爆炸式增长给人们带来了严重的信息过载,比如电影、书籍、音乐等方面,如何从大量的资源池中准确的找出用户感兴趣的信息是各大互联网企业的研究焦点.以电影推荐为例,电影市场每年都会推出数以千计的电影,然而如此多的电影中符合某个用户需求的并没有多少,这使得用户很难快速找出他喜欢的影片,而随着时间的推移,积累的影片数量越来越多,用户就更难寻找到他所感兴趣的影片,在这种背景下,推荐系统应运而生,目前,推荐系统的主要工作内容是通过信息过滤技术向用户准确的推送用户感兴趣的信息,避免用户在信息海中浪费时间[1,2].
现今的推荐算法大多关注推荐的准确性上,但在实际中,单纯的提高准确率有时并不能提高用户对物品推荐的满意度[3],一方面,这使得展示给用户的信息过于单一,展现在用户面前的很多是当前时期的热门物品,虽然这提高的准确率,但用户很可能从其它渠道知道了这个物品,比如他的朋友告诉他或者是满大街的海报等等,这样的推荐显然是无效的.另一方面,会使得推荐系统的数据集中于热门物品,这将导致严重的马太效应,致使资源整体曝光率变得极低,热门的物品愈发热门,冷门的更加冷门,从而很多用户感兴趣的信息埋没在庞大的资源池中,因为用户感兴趣的信息不仅仅只有当前热门信息[4,5].提高物品的多样化推荐不仅对提升用户满意度有帮助,它对网上商店的影响也非常大,根据帕累托原理可以知道,少数的商品占据了大量的市场空间,如果推荐系统能把更多的长尾商品展示出来,商品制造商会更有动力去丰富商品的种类数量[6,7].如何能让更多的信息展示在用户面前,如何发现用户感兴趣的长尾信息,提高推荐的多样性,在今后将是研究推荐算法性能的焦点之一.
推荐结果多样性研究面临很多问题,准确率与覆盖率是一对相互矛盾的指标,当准确率较高时覆盖率会相对低,反之亦然,因此目前面临最大的难题便是如何即保证准确性不降低而又能提高推荐多样性.
针对此问题,本文通过兴趣核密度估计的方式挖掘用户潜在兴趣,寻找与用户兴趣相近的邻居,由于在同一兴趣集合下的物品较多,其邻居在该兴趣集合中选择的物品在很大可能上也不一样,由此产生的推荐结果会跳出热门物品影响,当用户足够多的时候,在该兴趣集合下的所有项目都可能被推荐出来,从而提高推荐结果总体多样性,得到推荐预评分后填充到SVD矩阵中解决数据稀疏问题.SVD算法具有推荐准确率高的优点,可以用其来保证推荐的准确率.
2 相关工作
一个好的推荐系统应当在保证推荐准确率的前提下充分提高资源池中物品的曝光率,如果推荐系统只以提高准确率为目标,随着推荐数据的积累,长期以后推荐系统将只会推荐当前热点,使得推荐结果过于单一.
多样化推荐研究分为个体多样性和总体多样性两个方面,个体多样性通过对用户给出的推荐列表计算,通过考量推荐列表中物品的相似程度来确定列表多样性程度[8,9],其主要目的是避免给用户推荐的物品相似度过高,给单个用户推荐相似度过高的物品会导致无效推荐,比如一个用户喜欢看战争片,如果一个推荐系统采用传统协同过滤的方法来进行推荐,那么它会尽可能多的推荐当前的热门战争片,而一段相对短的时间内热门战争片是有限的,用户可能全部都看过,这时候给出的推荐列表就是无效推荐.总体多样性是指在资源池中物品的曝光数量,总体多样性高可以为用户提供更多的选择,很多优秀的电影作品用户自己并不能挖掘出来,这些物品可能是很多年以前的,但是它恰巧是用户所需要的,总体多样性一般用覆盖率来衡量,即已推荐出的物品占物品总数的百分比,本文的工作主要在提高推荐总体多样性.
现有的多样化推荐算法主要有两个研究方向,第一种是使用现有的协同过滤算法来计算预测评分,然后对得出的推荐候选集进行重新排序,按比例取出一些长尾项目推荐给用户,第二种方法是改进计算预测评分的方法,通过一些特殊方法提高低流行度项目的优先级.
Adomavicius G[10]等在2012年根据物品的流行度对推荐列表进行重排,首先根据物品的预测评分进行排序,然后设定流行度阈值,删除流行度高于此阈值的项目得出推荐列表,此算法对提高推荐结果总体多样性有一定帮助,但是仅仅使用用户的行为数据作为推荐候选集,推荐结果往往还是会偏向热门物品;Zhang M[9]等人提出了一种基于聚类的的多样化算法,首先,实验表明该算法在准确率和多样性方面取得比较好的平衡,但该算法只考虑了用户兴趣范围内的物品,对于用户兴趣之外的物品不会被推荐;Mcnee S M[11]提出了一种贪心选择算法,追求最大化推荐列表的多样化程度,该方法以常用预测评分方法为基础,在组织推荐列表时加以考虑物品与推荐列表中其它物品的相异程度,虽然该方法在多样化方面的性能优秀,但由于不考虑用户兴趣分布导致准确率太低;Adomavicius G[12]等人在2011提出了一种基于图论的算法,首先用常用的系统过滤算法得出候选集,并计算他们的预测得分,然后把用户集合和其对应的候选物品集合分为两组建立二分图,对应的预测评分为用户顶点到对应推荐物品顶点的权值,最后通过二分图最大匹配的方式得出每个用户的推荐结果集合,该方法的精确度和多样化程度取决于训练集中每个用户的物品数,用户的物品数越多,推荐结果多样化程度就越高,但它的精度就会相应降低.
针对以上问题,本文提出了的KDE-SVD算法,该算法是通过预评分公式(6)计算得到的预评分来提高低流行度物品的优先级来实现多样化推荐的,与其它算法相比,该算法只需要用到用户对物品的评分和物品的基本特征属性,对于在不容易采集用户或物品更多信息的情况下比较方便和实用,该算法的第一个部分是从与用户兴趣相近的邻居那里获得邻居的物品集合,然后对当前用户不曾拥有的物品进行预评分,在预评分的过程中就已经对低流行度的物品提高了它的优先级,所以它是独立的一部分,因此,用户兴趣估计这部分可以和其它推荐精度高而多样化程度差的算法结合使用.
3 KDE-SVD模型
3.1 核密度估计基本概念
核密度估计是统计学上一种常用于估算样本概率密度的方法,是对直方图的自然拓展,通过拟合函数曲线的方式消除直方图图像不连续和bins对图像观察的影响,如图1、图2所示,图1bins过大掩盖了数据细节,而图2通过减小bins显示出了数据细节,然而,bins不可能无限减小,这时由数据拟合出的函数曲线便可很好的描述数据分布.
图1 学生成绩统计图1Fig.1 Student achievement statistics 1
3.2 基于核密度估计的评分预测
定义1.设数据集{X|x1,x2,x3,…,xn}为X的独立同分布随机变量,且它服从的密度分布函数为f(x),其中x∈X,定义函数:
(1)
公式(1)称为函数f(x)的核密度估计,其中,参数h为带宽,用于,通常是一个预先给定的正数,φ(°) 为该核密度估计的核函数.
定义2.一件物品在分类上可以同时属于多种类属,比如一部电影可以同时属于战争片与爱情片,假设C={c1,c2,c3,…,cn}为物品空间的所有类别集合,物品i的所属类别C={c1,c2,c4,c5},物品j的所属类别C={c2,c3,c5,c6},此时物品i与物品j之间有两个相同的类别属性,即它们之间有一定的共同点,这种共同点称为类别相似度,它的计算公式定义为:
(2)
定义两个物品类别间距离公式为:
di,j=1-simc(i,j)
di,j越大表示两个物品的共同点越少.
进行用户兴趣分布计算时,核函数的对密度估计影响较小[13],为方便计算,本文选用高斯核函数作为本文核密度估计的核函数.
(3)
用户u在高斯核函数下的兴趣分布公式为:
(4)
其中Iu表示用户u评价过的物品,I表示整个物品空间,ru,i表示用户u对物品i的评分,h为核密度估计的带宽.
图2 学生成绩统计图2Fig.2 Student achievement statistics 2
在兴趣分布属于概率分布,无法用计算距离的方式计算用户之间的相似度.在信息论中,往往使用KL散度计算两个概率间的差异,由于KL散度不具备对称性,用于计算用户相似度时需先对称化,两个用户间的相似度计算公式定义为:
(5)
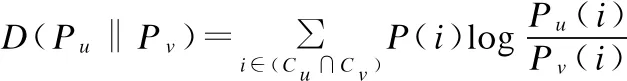
D(Pu‖Pv)为用户u和用户v之间的KL散度.
根根据由KL散度计算的用户相似度,便可用近邻算法即可获得离目标用户最近的邻居集,然后用相似度作为权重加权计算邻居用户对目标物品的评分,该值即可作为目标用户对目标物品的预测评分,预测评分公式定义为:
(6)
其中,μ为用户的评分平均值.
3.3 带宽及其计算
核核密度估计中的带宽指的是核函数的方差,带宽大小对核密度估计的影响要远大于核函数种类的影响[14],当带宽过小时得到的概率密度曲线极其陡峭,虽然能最大限度地描述样本分布,但却不利于观察样本的分布特点,当带宽过大时得到的概率密度函数曲线过于平滑,会掩盖样本分布细节.
在数据样本确定的情况下,可以先计算样本的概率密度,然后使用最小化L2风险函数(MISE)的方式求得最佳带宽h,设:
(7)
在Weak-Assumptions的情况下有:
(8)
其中AMISE为渐进均平方积分误差[15],从而有:
(9)
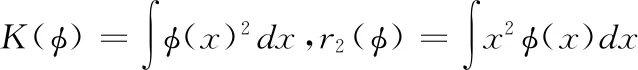
用求AMISE(h)一阶导数0点的方式获取AMISE(h)的最小值,其最小值即为MISE(h)的最小值,根据公式(9)有:
(10)
得:
(11)
3.4 融合核密度估计的SVD的推荐算法
在3.2节中,我们使用核密度估计的方式估计用户兴趣分布,通过匹配用户之间兴趣相似度的差异程度获取与用户兴趣相似的邻居,但这样产生的邻居用户是兴趣相似的邻居而不是行为相似的邻居,比如用户i和用户j都喜欢看战争电影,他们此时是兴趣相似的邻居,但能把用户i看过的战争电影全部推荐给用户j吗,这显然是不行的,虽然都是战争电影,但电影的剧情、演员等因素仍然会极大影响一个用户的行为,由此产生的推荐列表多样性较高但精度相对低,因此需要结合奇异值分解算法提高推荐结果的精确度.
奇异值分解算法(SVD)是推荐系统中常用的一种方法,具有速度快、精度高等优点,是目前最流行的推荐算法之一.对于任意一个Rm×n(m>n)矩阵,均可分解成Rm×n=U×Σ×V,其中U为m×m的矩阵,Σ为m×n的矩阵,其为一个对角矩阵,除了对角线外,其余地方值均为0,对角线上的值称为奇异值,V为n×n的矩阵,U和V均为正交矩阵.
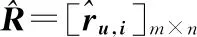
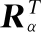
4 实验结果及分析
4.1 实验数据
本文实验使用的数据集是GroupLens提供的ML-1M数据集进行对算法的评估.该数据集一共有1000209个评分,由6040名用户对3962部电影评分而产生,每名用户至少有20个评分,评分值为1-5的整数,电影共分为19大类,整个用户-评分矩阵填充率为4.1%.实验时随机抽取80%的用户作为训练数据,其余作为测试数据.
4.2 评价指标
本文采用准确率(Precision)和覆盖率(Coverage)两个指标来评价本文模型.令P(u)为模型给用户的推荐列表,Q(u)为用户的实际看过的电影列表.
准确率用于评价该模型推荐的准确度,计算公式为:
(12)
覆盖率是衡量推荐系统对长尾物品发掘能力的指标,覆盖率越大表示物品库中被推荐的物品个数越多,其计算公式为:
(13)
其中|∪u∈UP(u)|表示推荐系统推荐出的电影集合,集合中元素互斥,|I|为电影总数.
4.3 P-C值
在推荐系统中,对于准确率和覆盖率到目前还没有统一的综合评价方法,为了在准确度和覆盖率找到比较好的平衡点,受F值的启发,本文提出了P-C值的概念,P-C值计算公式为:
(14)
其中,α为调节P和C重要程度的参数,P为准确率,C为覆盖率.
4.4 相似度计算
在协同过滤中,相似度算法用于计算用户之间的相似度,常用的有余弦相似度、欧氏距离等,本实验采用余弦相似度作为相似度计算方式,其公式为:
(15)
其中vi、vj分别表示用户i和用户j在用户-评分矩阵SVD分解后而得的Vm×m向量中的位置向量,vi,k、vj,k分别为用户i和用户j在m维空间中第k维的值.
余弦相似度在计算用户相似度时并没有考虑用户的评分习惯.因此本文对余弦相似度算法进行改进,对用户的每个评分都减去他的评分平均值,改进后的余弦相似度公式为:
(16)
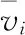
4.5 实验分析
实验1.图3为使用核密度估计对三位用户估计其兴趣分布的兴趣分布函数图,从图中可以看出,用户3和用户100的兴趣分布比较相近,和用户5差别较大.在数据集中,用户3和用户100喜爱的电影类型较为相似,与用户5差别较大,与函数图像所展示的情况一致,因此本文提出的用户兴趣分布估计方法可以比较好的估计用户兴趣分布.
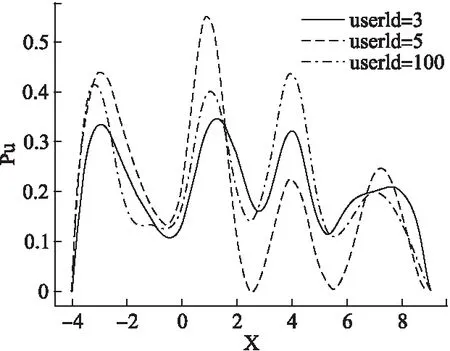
图3 三个用户的兴趣分布函数图Fig.3 Three users′ interest distribution function graph
实验2.本组实验意在考量在不同的带宽下,核函数的差异和对实验结果的影响,由于推荐列表的长度和Σk×k维度也会影响推荐的准确度,因此本实验的结果为针对不同核函数和不同带宽调节推荐列表参数和Σk×k维度参数达到最优的结果,Gaussian Kernel与Cosin Kernel做对比得到的结果如下:
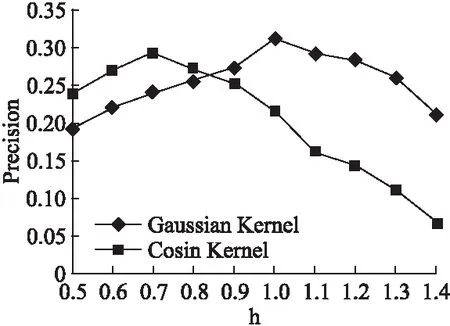
图4 两种核函数随带宽的变化情况Fig.4 Variation of two kernel functions with bandwidth
从图4中可以看到,带宽在0.5到1.4之间变化时,两个核函数在最高点处的差距非常小,Cosin Kernel核函数在带宽为0.7处取得最大准确率0.292,Gaussian Kernel核函数在带宽为1.0处取得最大准确率0.311.两条曲线走势基本相同,Cosin Kernel对应的折线从0.5到0.7时持续上涨,0.7以后下降非常迅速,Gaussian Kernel对应的折线在0.5到1.0之间持续上涨,当带宽大于1.0时,开始下降,但下降幅度没有Cosin Kernel对应的折线陡峭,两条折线的最高点处所对应的带宽与3.3节所述方法计算而得的带宽差值很小,验证了3.3节所述带宽计算方法真实有效.随着带宽的增长,两个核函数对应的准确率有越来越低的趋势,这是因为带宽过大时会掩盖掉大量的数据分布细节,导致对用户某个项目的兴趣进行估计时产生很大的泛化.
实验3.本组实验意在对比本文算法与其它算法之间的准确率和覆盖率,评估本文算法性能.为此,本文算法将与SVD(Singular Value Decomposition)、PS[7](Probabilistic Selection)、PSVM[16]三种算法进行比较,表1为本组实验结果.
SVD:SVD是矩阵分解类算法中最有代表的算法之一.该算法的提出是为了解决推荐准确率差问题,在覆盖率上考虑较少,本文算法便是在SVD的基础上进行改进,提高其覆盖率.
PS:PS是采用概率选择的方式对初始排序列表进行抽选生成推荐列表,对于一个项目,先按一定概率确定它是不是需要推荐的类型,再按一定的概率确定它是不是要推荐的项目,该算法在准确率和覆盖率上有比较好的平衡.
PSVM:该模型是LAD模型与结构化支持向量机SSVM相融合的一个模型,它在组织推荐列表时充分考虑了时间推移对用户兴趣的变化,在准确率和覆盖率上也有比较好的平衡.表1中的四组实验结果均为通过参数对准确率与覆盖率进行平衡得比较好的结果.在三组实验中,均取推荐列表长度为70,以此消除召回率不同而带来的实验误差.
表1 三种算法实验结果对比
Table 1 Comparison of experimental results of three algorithms
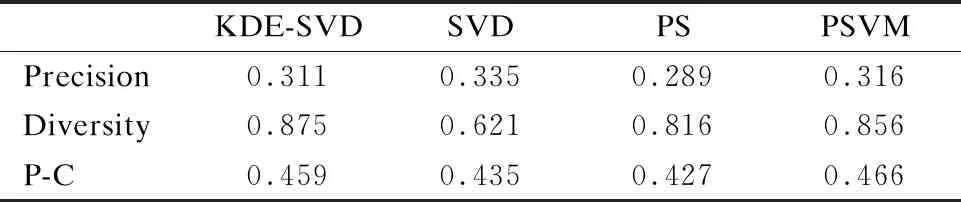
KDE-SVDSVDPSPSVMPrecision0.3110.3350.2890.316Diversity0.8750.6210.8160.856P-C0.4590.4350.4270.466
从表1中可以看到,KDE-SVD算法由于在推荐时充分考虑了用户的兴趣分布,相比于只考虑用户评分的SVD算法虽然Precision有小幅度降低,但Coverage却有大幅度提升,说明在推荐过程中考虑用户兴趣分布可以得到更好的推荐效果.和PS对比,KDE-SVD比PS有更好的准确率和覆盖率,从P-C值可以看出KDE-SVD在准确率与覆盖率的平衡上也明显比PS好,.和PSVM相比,虽然在准确率方面略低,但在覆盖率上略有优势.综上三点说明本文提出的融合核密度估计与奇异值分解推荐算法可以提高推荐系统在准确率与覆盖率方面的平衡能力,可以在精度不明显下降的情况下大幅提高覆盖率.
5 总 结
随着互联网的发展,推荐系统作为互联网个性化服务的主要实现方式受到越来越多的研究者的关注.针对如何提高总体覆盖率,本文用核密度估计的方式估计用户的兴趣分布,然后用与户兴趣分布相似的邻居的评分对当前用户未评分的物品进行预测评分,以此提高物品曝光率,在同一兴趣下有很多物品,不同的用户在一个兴趣下选择的物品往往是不一样的,在用户量大的情况下,任何一个物品都可能被推荐出来.针对如何保证准确率不明显下降问题,本文将上阶段得到的预测评分填入用户-评分矩阵,然后用推荐算法中准确率高的SVD算法对其进行分解,在SVD分解而得的m维空间中用相似度算法找出对当前用户行为相似的邻居,此时得出邻居即是兴趣相似和行为相似调和的邻居.在真实数据集上实验表明,本文算法可以保证精确率较高的情况下提高总体覆盖率.在本文,仅考虑了总体多样性的提升,而在个体多样性考虑较少,因此,下一步将研究如何提升个体多样性,提高推荐质量.
