南充市老年人养老意愿及其影响因素分析
2020-01-07王珊川李明东陶卫国许世杰
王珊川,李明东,陶卫国,陈 丽,许世杰
(1.西华师范大学,四川 南充 637000;2.四川德尔博睿科技股份有限公司,四川 南充 637000;3.南充市民政局,四川 南充 637000)
0 引言
2010年的第六次全国人口普查结果显示,我国60岁及其以上的老年人口达到1.78亿,占总人口比重为13.3%;2011年底,60岁及其以上的老年人口达到1.85亿,占比为13.7%;根据2017年我国国务院印发的《“十三五”国家老龄事业发展和养老体系建设规划》,预计到2020年,60岁以上老年人口将增加到2.55亿人,占总人口的17.8%左右.这些数据都表明,我国人口老龄化的速度不断在加快.面对日益严峻的人口老龄化,养老问题成了现在最热的话题.为解决养老问题,了解老年人养老意愿尤为重要.以南充市为例,对南充市市辖三区的46个社区里年龄为50岁及以上的准老人及老年人进行问卷调查,通过分析他们的养老意愿及其影响因素,以期为解决养老问题提供帮助,为完善多元化养老模式提供依据.
对于已有的有关养老方面的研究大多数使用Logistic算法、SPSS数据分析软件[1-4]对数据进行分析处理.养老数据的研究方法较为单一,本文提出使用支持向量机递归特征消去方法(SVM-RFE)、支持向量机(SVM)来对养老数据进行研究分析,使用PyCharm软件处理数据,为养老数据的研究提出新的研究处理方法.
1 问卷调查
1.1 调查对象
为了使调查具有普遍代表性,南充市民政局组织协调三区民政局,具体负责落实46个社区的问卷调查.在市区民政局的领导下,课题组组织西华师范大学在校学生20余人,进入各个社区,组织年龄为50岁及其以上的准老人及老年人填写调查问卷.
1.2 调查方法
通过广泛查阅资料、咨询专家等方法,充分研讨后,课题组设计了《居家养老问卷调查》表.应用设计的调查表,在各区民政局的统一协调下,调查小组进入各个社区,组织50岁及以上的准老年人及老年人进行问卷调查.最后,收回1 836份问卷,其中有效问卷为1 816份,问卷率有效为98.9%.
2 研究方法
分析不同养老意愿选择的影响因素,使用支持向量机递归特征消去方法(SVM-RFE)得到因素影响从大到小的排序集合,构造排序集合的子集,采用支持向量机(SVM)分类方法,以其精确度、ROC曲线和RUC值为指标,选取显著的影响因素,以便为解决养老问题提供更直接的帮助.
2.1 支持向量机
支持向量机是Corinna Cortes等人基于统计学习理论和结构风险最小化原理提出的一种机器学习算法.
假设给定数据集为T={(x1,y1),(x2,y2),…,(xN,yN)},其中xi∈χ=Rn,yi∈y={+1,-1},i=1,2,…,N,xi为第i个特征向量,也称为实例,yi为xi的类标记,当yi=+1时,称xi为正例;当yi=-1时,称xi为负例,(xi,yi)称为样本点.
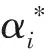
2.2 支持向量机递归特征消去方法
2002年,Guyon等人提出了SVM-RFE算法.SVM-RFE算法的核心思想是反复构建SVM模型,根据重要性选出最差的特征并选择出来,重复这个过程,最后得到一个特征的排序集合.
2.3 精确度、ROC曲线和RUC值
精确度:ACC=(TP+TN)/(P+N),即(真阳性+真阴性)/总样本数.
ROC曲线(又称受试者工作特征曲线、感受性曲线)以假阳性概率为横轴,真阳性概率为纵轴,可以反映分类器的准确性.
真阳性率(TPR):(TPR)=TP/P=TP/(TP+FN)
假阳性率(FPR):(FPR)=FP/N=FP/(FP+TN)
其中TP(真阳性)表示正确的肯定,TN(真阴性)表示正确的否定,FP(假阳性)表示错误的肯定,FN(假阴性)表示错误的否定.
AUC为ROC曲线所覆盖的区域面积,AUC值越大,分类器分类效果越好.
3 数据分析
3.1 过程分析
数据分析思路如下:
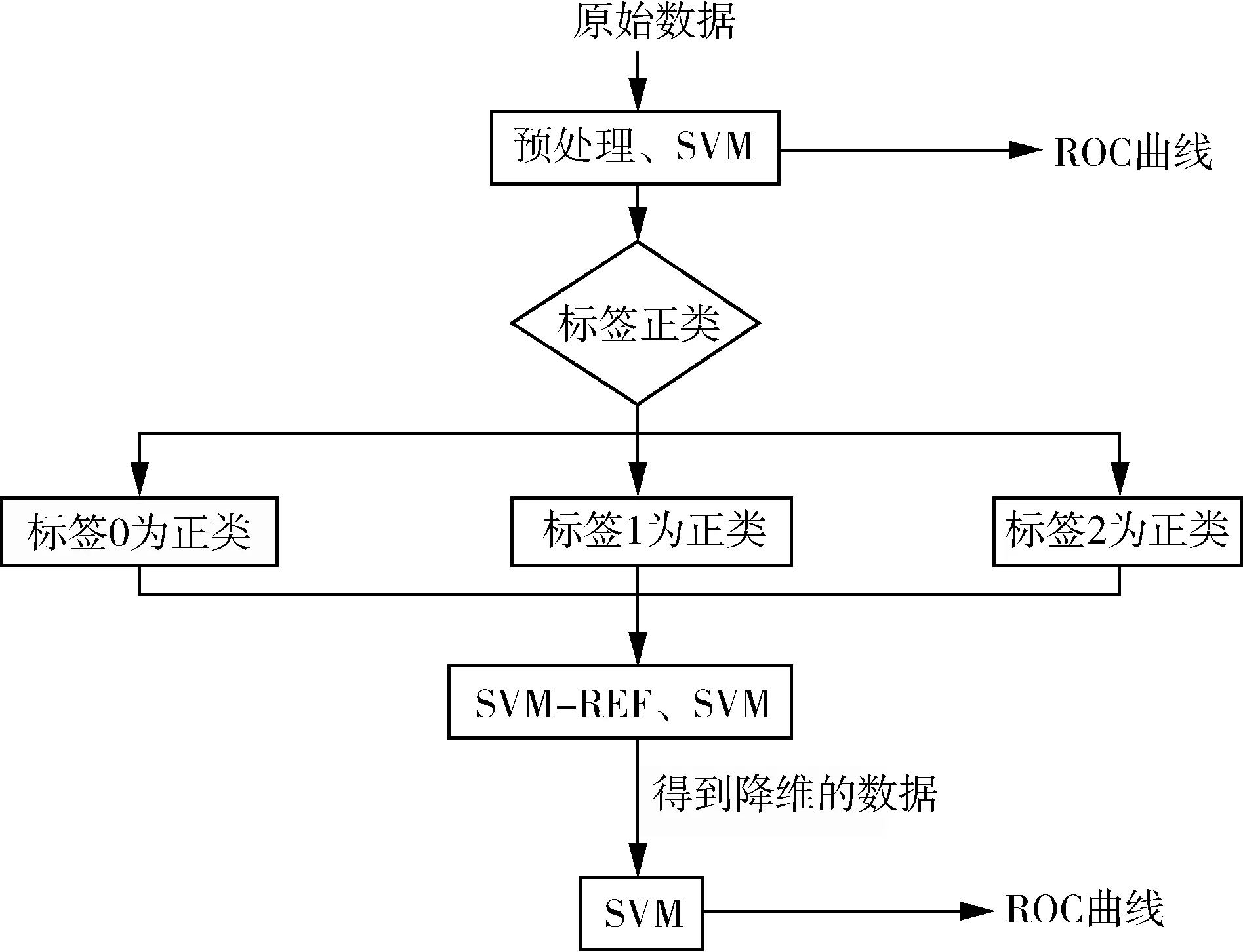
图1 分析过程
0表示倾向于选择居家养老,1表示倾向于选择社区养老,2表示倾向于选择机构养老.用SVM-REF、SVM对老年人不同倾向选择的影响因素做分析,得到显著的影响因素,即降维后的特征.
3.1.1 原始数据的处理
参与数据分析的原始数据有13个特征,1~13表示,分别是性别、年龄、受教育程度、身体情况、退休前行业、子女数量、自有住房面积、经济来源、家庭月均收入、每月能承受的养老费、体检频率、保险方式、是否满足现在的养老方式;有3个分类标签,分别是居家养老、社区养老以及机构养老.
对原始数据进行处理,得到3个分类的数据分布、3个分类的ROC曲线图和以不同分类标签为正类的精确度,如图2.可以从图中看出,老年人倾向于选择居家养老的居多,13个特征因素对社区养老有比较高的敏感度和关联度.
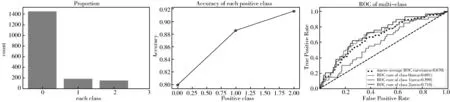
图2 数据的基本分析
3.1.2 不同标签作正类的数据处理
应用SVM-REF对不同标签为正类的数据进行特征排序,如图3,13个特征分别以1~13代表,颜色的深浅代表特征影响的大小,越浅影响越大.
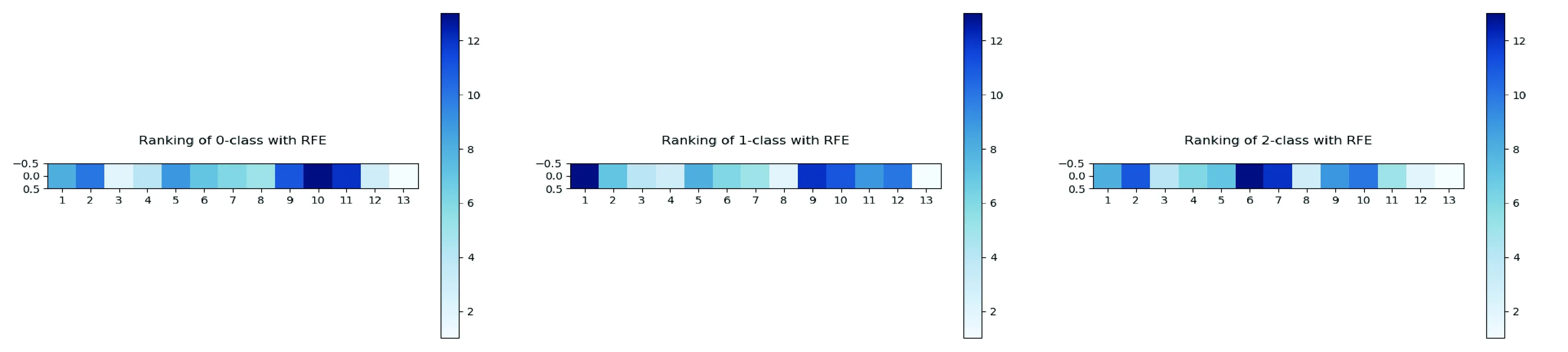
图3 正类分别是0、1、2的排序集合
根据排序序列构造特征子集F1,F2,…,F13,并且F1⊂F2⊂…⊂F13.利用支持向量机的判别正确率以及AUC值来评估这些子集的优劣,从而获得最优的影响因素.如图4,以0标签为正类时,选择排序特征的前6个特征;如图5,以1标签为正类时,选择排序特征的前4个特征;如图6,以2标签为正类时,选择排序特征的前4个特征.
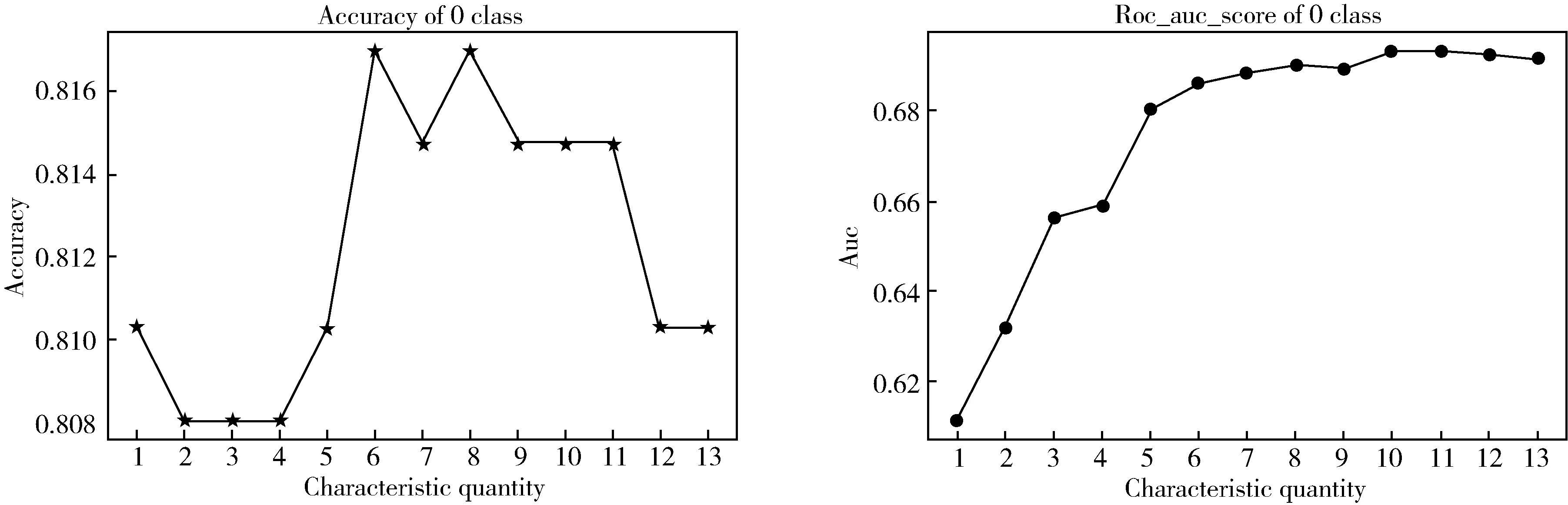
图4 以0为正类的准确值和RUC值

图5 以1为正类的准确值和RUC值
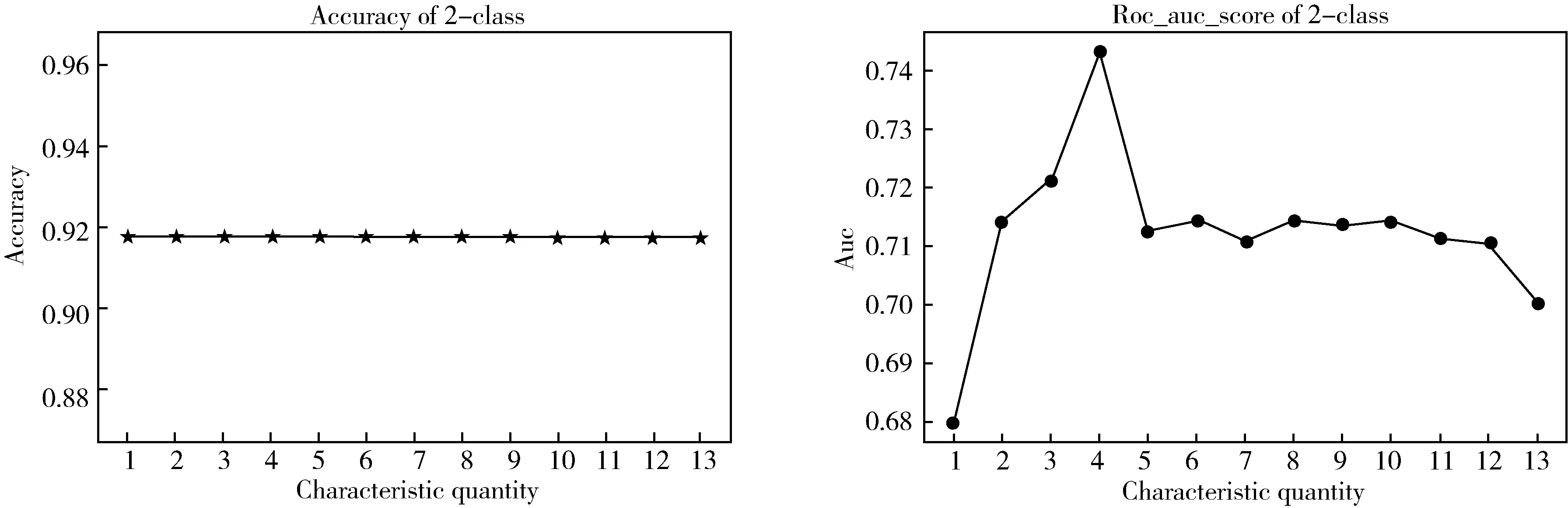
图6 以1为正类的准确值和RUC值
3.1.3 降维后数据处理
利用降维后的数据做ROC曲线并计算AUC值,如图7,降维后的数据单个对应的分类准确性有所上升,但是对于总分类的准确性小有幅度的下降.

图7 对应正类依次为0、1、2的ROC图
3.2 数据处理结果分析
由分析结果可知,对于居家养老,是否满意现在养老方式、受教育程度、保险方式、身体情况、经济来源、自有住房面积对选择倾向具有较大影响;据表1知,越满意现在养老方式的越倾向于选择居家养老;受教育程度越低的越倾向于选择居家养老,目前老年人文凭普遍偏低,这与刘小春等[1-2]的研究结果一致;选择医疗保险的老年人更倾向于选择居家养老;身体状况越健康越倾向于选择居家养老;经济来源越不独立越倾向于选择居家养老,特别是经济来源是子女提供;自有住房面积越多的越倾向于选择居家养老.
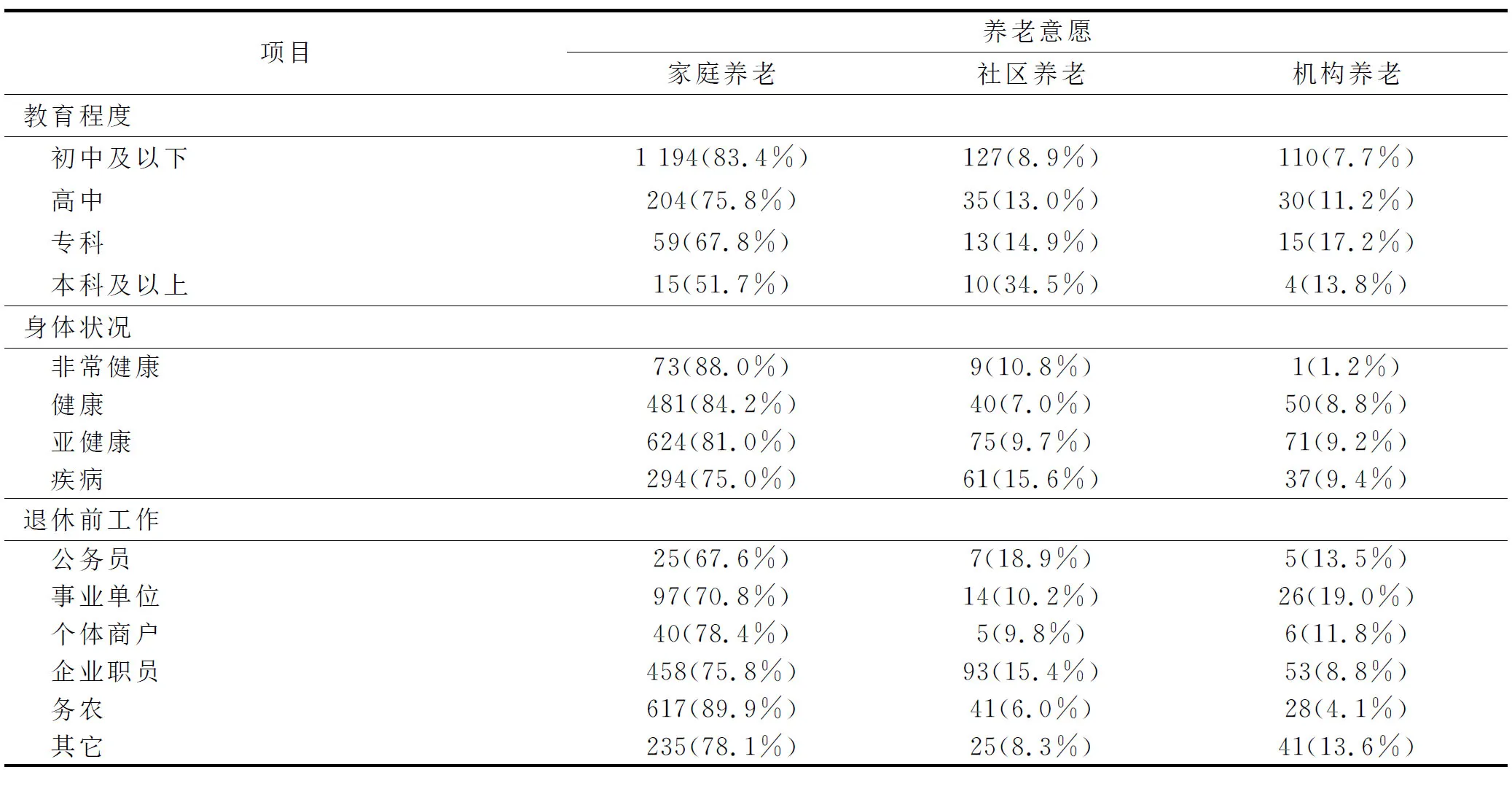
表1 显著因素比例表
续表1
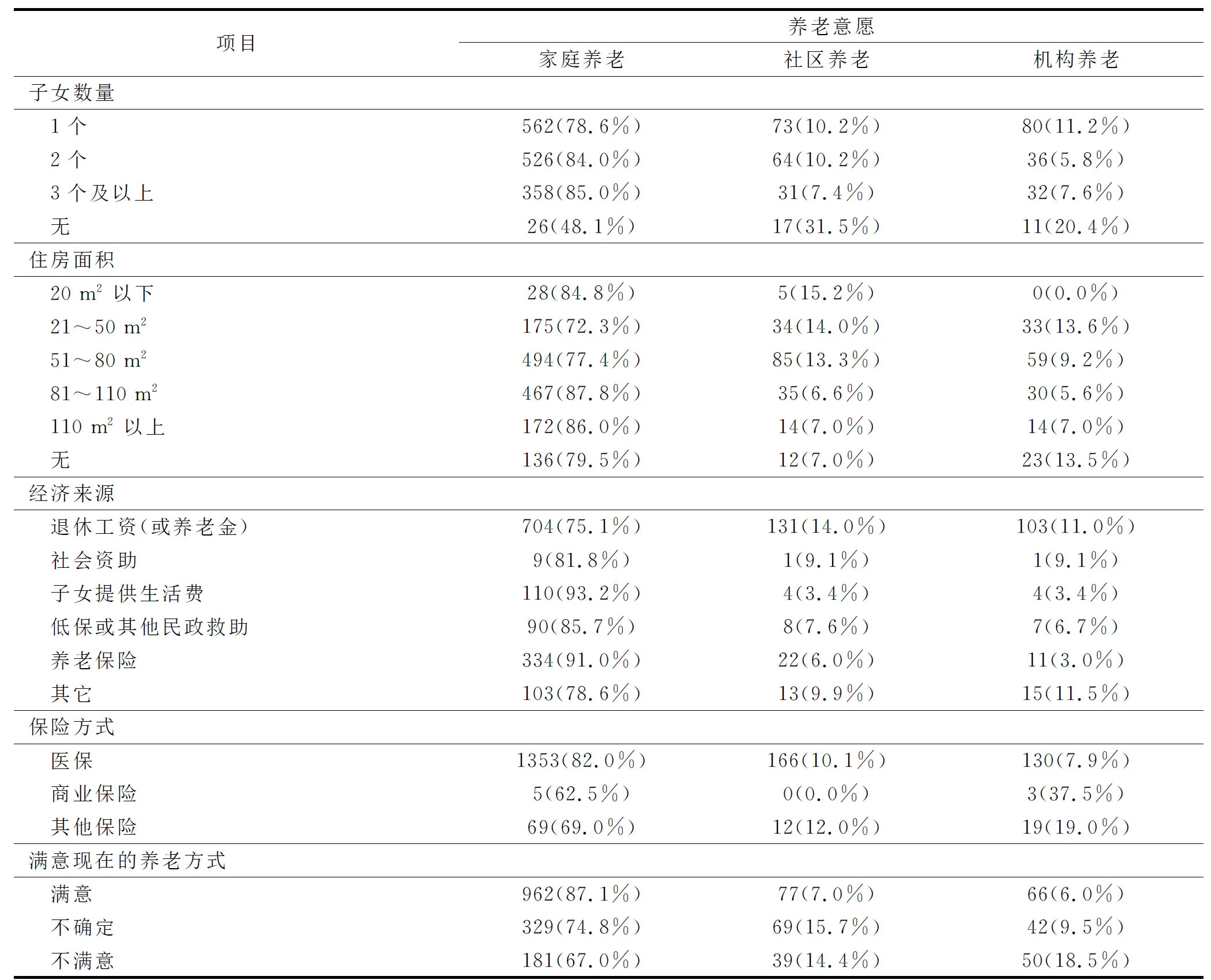
对于社区养老,是否满意现在养老方式、自有住房面积、身体情况、受教育程度对其选择倾向具有较大影响;越不满意现在养老方式的越倾向于选择社区养老,对现在养老方式不存在满意和不满意的占多数,不满意的比例是满意的2倍;自有住房面积越少越倾向于选择社区养老;身体状况越不好越倾向于选择社区养老,其中,相比机构养老,更倾向于选择社区养老,这与胡斌等[3]的研究结果一致.老年人身体状况越差,自理能力越弱,不想成为子女的负担,就更倾向于选择去提供基本生活照料、医疗护理服务等的社区和机构养老;受教育程度越高越倾向于选择社区养老.
对于机构养老,是否满意现在养老方式、保险方式、经济来源、子女数量对其选择倾向具有较大影响.越不满意现在养老方式越倾向于选择机构养老,不满意的比例是满意的3倍;选择非医疗保险的更倾向于选择机构养老;经济来源越独立、子女数量越少越倾向于选择机构养老.这种子女与老年人养老意愿之间的关系跟刘小春等[2-4]的研究结果一致.我国传统的“养儿防老”“孝道”等文化根深蒂固[5],这与认为没有子女才选择机构养老、送老人进养老院是不孝等错误认知有关.
4 结论
根据理论分析所得的结果,以期为解决养老问题提供理论依据.针对传统的、主流的三大养老模式——居家养老、社区养老和机构养老,做了老年人养老意愿的研究.对于倾向于选择不同养老模式的准老人及老年人而言,有不同的显著特征.根据这些显著的特征,可为养老服务或相关政策等提供更好更直接的帮助.由文章分析结果和相关研究成果[1-5],可知随着社会的发展和进步,人们的生活和观念不断发生改变,人们对社区养老和机构养老的认可度和接受度越来越高.在现实生活中,人们的生活水平越来越好,传统的三大养老模式已不能满足人们对养老的需求,居家养老护理服务O2O、居家智慧养老模式、虚拟养老院、“互联网+居家养老”模式、抱团养老 、“候鸟式”养老等不同养老模式相继出现,养老变得更加多元化、层次化.为更好更快更直接地满足老年人的养老需求,政府应制定相关政策,加强养老模式的引导,带动企业积极参与养老服务行业,带领社会力量促进养老的多元化,以满足老年人不同的养老需求.
本文采用支持向量机及其拓展的方法(即支持向量机特征消除算法)对养老意愿进行分析研究,为养老方面的研究提出了一种新的研究方法作为参考.
