神经网络在统计中的应用初探
2020-01-07陈卫华
□ 陈卫华
机器学习是人工智能及模式识别领域的研究热点,其理论和方法被广泛应用于工程应用和科学领域中解决复杂问题,决策树、K-均值聚类、朴素贝叶斯、支持向量机、随机森林、神经网络等算法对数据深度分析和挖掘有着重要的作用。学习数据挖掘算法是新时代统计工作者一项必备的能力,缺少这种能力就无法驾驭统计大数,也很难在浩瀚的数据中获取真正的价值。
神经网络作为机器学习的一种算法在人工智能方面有着广泛的应用,神经网络不但可以作为分类器,也可以解决回归问题。R 语言中neuralnet 包提供了神经网络建模函数和可视化函数使用起来非常方便。下面通过一个实例来介绍一下神经网络在统计中的应用。
目的和数据准备
实例的目的用国内生产相关指标运用神经网络构建回归模型。指标有国内生产总值(y)、全社会固定资产投资(x1)、进出口总额(x2)、农林牧渔业总产值(x3)、工业企业主营业务收入(x4)、建筑业企业建筑业总产值(x5)、货物周转量(x6)、社会消费品零售总额(x7)、居民消费价格指数(x8),报告期为1987 年-2018 年度,如表1。
数据导入和模型构建
1.软件环境。R 语言3.4.3版,RSudio 1.1.383 版,这是文章中代码使用的软件版本情况。
2.数据导入。数据为CSV 格式,名称为data2,存在桌面上。
由于数据是CSV 格式,要用到readr包,下面代码是在RStudio 控制台键入的命令,用于导入数据。


表1 国内生产总值及相关指标
3.构建神经网络模型。主要工作有:一是对数据标准化,构造训练集和测试集。数据一共有32条记录,我们用20 条作为训练集,12 条作为测试集。用sample 随机函数从1-32 个数字中抽取20 个数字来抽取训练集trains 和测试集tests。用scale 函数来对data2 数据标准化,结果放在scaled 中,再构造标准化后的训练集(train_)和测试集(test_),用于建立神经网络模型。二是构建神经网络模型。神经网络模型函数neuralnet 主要参数有数据变量的函数关系、数据、隐含层向量和一个表示回归的逻辑变量。隐含层向量格式用一个向量表示,如c(5,3)表示隐含层有两层,节点分别是5 个和3 个;c(10,5,3)表示隐含层有3 层,节点分别有10 个、5 个和3 个。本实例中由于变量数只有7 个隐含层只设了1层,5 个节点。通过neuralnet 函数构造出的神经网络结果存放在nn对象中。具体代码如下:


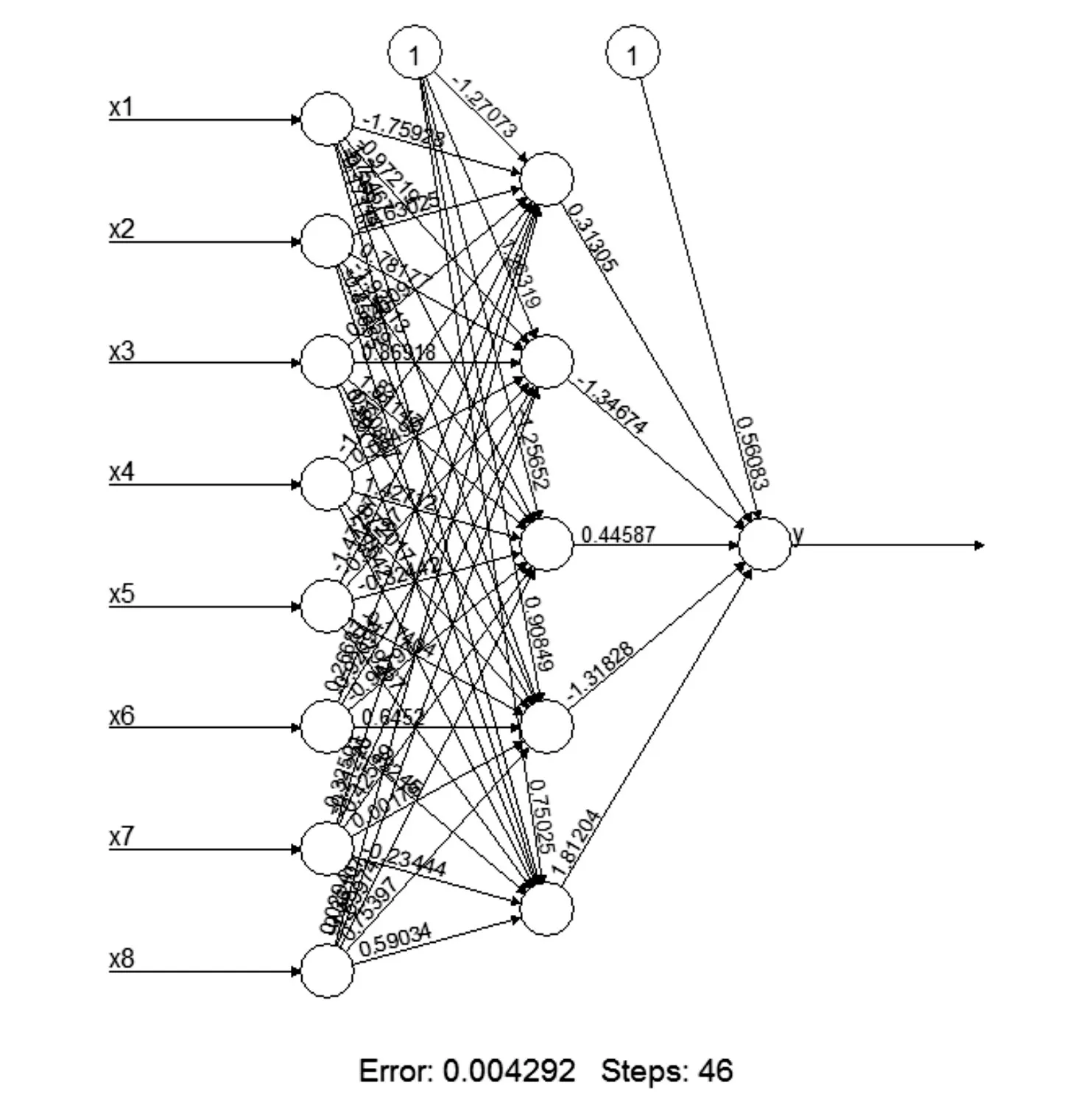
图1
4.绘制神经网络图。neuralnet包中提供了plot()函数可以方便的绘制神经网络图。
模型检验和预测
模型检验可以用交叉检验来检验模型可靠性和性能,这里用简单的图形检验模型情况,用测试集数据通过神经网络模型计算出预测数,然后与实际数比较。预测结果放在pr.nn变量中,折算后得结果放在test.r 中。代码如下:

2.作图
输出图形如下,Y 轴为测试集中的实际数,X 轴为预测数,直线为经过原点斜率为1 的直线。从图可以看出12 个点均匀分布在直线两侧,偏差不大,神经网络回归模型效果还是比较好的。
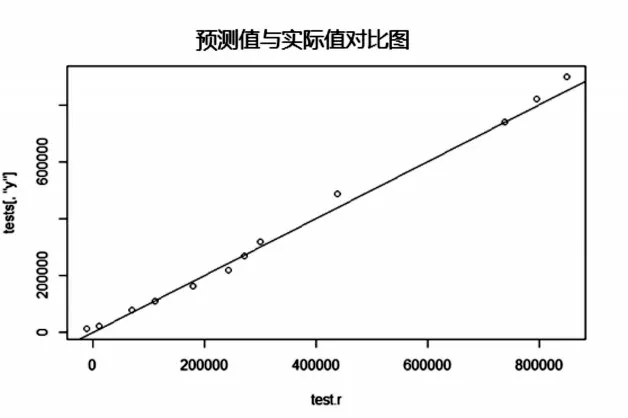
图2
以上只是神经网络模型的简单实例,由于实例中在构建模型时对数据进行了标准化处理,在预测远期数据时存在缺陷,同时没有给出模型严谨的论证,仅供学习参考。机器学习在诸多领域都有广泛的应用,相信随着大数据技术的发展也会在政府统计中发挥出越来越重要的作用。
