基于深度学习的代码审查意见有效性评估
2020-01-07段雨佳
段雨佳,鞠 婷
(杭州电子科技大学 计算机学院,浙江 杭州 310000)
代码审查指通过阅读代码来检查源代码的编码规范以及代码质量和功能是否达到预期的一项活动。代码审查最初在软件审查中提出,主要是为了发现在软件开发初期未发现的错误并进行修正,从而达到提升软件质量和开发者的技术水平的目的。在实际软件开发过程中,许多开源项目和商业软件采用同行代码审查的方式[1]。即由项目中的一名开发者作为代码审查人,对项目中其他开发人员所编写的代码进行审查,在代码通过审查后,再判断代码是否可以并入主代码仓库。然而,在现代大型软件开发中,代码审查的方式通常借助工具进行,以轻量级和非正式的方法为主。比如常见的审查工具:基于git的版本控制系统Gerrit[2]。
Capers Jones通过分析12 000多种软件项目后发现,通过正式的代码审查可以发现项目中60%到65%的潜在缺陷,非正式代码审查可以发现约50%的潜在缺陷,而测试只能发现30%的潜在缺陷[3]。因此,代码审查被认为是提高整体软件质量和降低后期风险的重要保证机制[4]。Remillard J等人的研究表明,为了确保代码审查的有效性,审查时间需要大于开发时间的1/4[5]。此外,代码审查不仅可以提高项目人员的开发经验、项目的熟悉度和业务逻辑能力,还可以促进项目人员之间相互学习。因此,提高代码审查的质量和效率,对于降低软件开发成本和提高软件质量有重要意义。由于代码审查评论是在代码修改提交下一个版本的补丁之前所提供的修改意见,有效的代码评论不仅可以帮助开发人员更好的实施代码审查,而且对于提高代码质量也有着非常重要的意义。有研究表明:约有65%以上的开发人员会根据代码评审人员的评论意见对代码进行修改和完善[6],因此高质量的代码审查意见显得尤为重要。根据Mohammad等人研究调查,在ABC公司的1 116条代码审查意见中,约有44.47%的意见是无用的。
为了实现对代码审查意见的有效性进行分析从而提高代码审查的质量和效率,本文根据代码审查过程中产生的数据,提出一种基于深度学习LSTM(Long-Short Term Memory)[8]的代码评审意见有效性评估方法,从代码审查意见数据中提取与意见有效性相关的语义特征,从而有效的协助开发人员判断评审意见的有效性,以提高代码审查的质量并减少软件开发的时间。本文的主要贡献是:本文提出了一种基于深度学习的代码审查意见语义特征的提取方法,并基于此方法挖掘审查意见中语义的序列关系和空间关系,使用Word2Vec方法[20]对审查意见进行序列化,根据代码审查意见中提取的语义特征,构建基于语义特征的代码审查意见有效性预测模型。为了验证模型的有效性,本文采集了GitHub上352个开源Eclipse项目在Gerrit[8]中的相应的代码审查意见作为实验数据,并进行了广泛的实验。实验结果表明,该模型可有效的评估代码审查意见。
1 相关工作
自代码审查1976年提出以来,许多研究人员都针对减少代码审查工作量进行了不同的探索。Jeong G等人通过预测补丁修复意见是否被采纳来提高代码审查工作效率。Thongtanunam P[9]等人通过建立自动推荐代码审查人模型,从而减少代码审查工作量。Mohammad[10]等人发现代码审查虽然现在被广泛使用,但其中包含大量无意义的审查意见,并基于这种现象提出了RevHelper模型,一种可以帮助开发人员自动的预测审查意见是否有意的模型。这种模型在1 482份代码审查报告中命中率达到66%。因此代码审查意见质量的高低直接影响着代码审查的效果和效率。由于深度学习在图像识别、文本分类等方面表现的十分优异,许多研究人员都采用了深度学习的方法进行了软件工程的研究。比如:Hu Xing等人利用深度学习LSTM模型构建代码缺陷修复人的推荐模型,在单项目中推荐修复准确率达到58%[11]。
2 预备知识
2.1 当代代码审查方法
代码审查是人工手动的对源代码进行评估,主要作用是为识别代码缺陷并提高代码质量。传统的代码审查方式在大型和分布式软件开发中受到了限制,因此MCR(Modern Code Review,现代代码审查)成为了当代代码审查的主要方式。MCR是一种基于工具的代码审查系统,并不像传统代码审查那样正式。本文使用代码审查系统Gerrit中的代码审查意见作为实验数据,Gerrit作为当前比较流行的代码审查工具,在许多开源项目中得到了有效应用。Gerrit的主要审查过程如下:开发人员对一个代码文件修改后将代码提交至Gerrit系统等待审查人员审查,审查人员对待审查文件进行检查,发现问题后将会在评论区给出修改意见,Gerrit将待修改文件和审查意见返回给开发者,开发者根据修改意见进行修改并将修改后的文件进行提交,当审查者审查通过后再合并到主代码库中。
2.2 Word2Vec
Word2Vec是Google公司在2013年提供的一种用于词向量训练的软件工具。它可以通过一层神经网络将One-hot(独热编码)形式的词向量[20]通过训练后达到词向量到分布形式词向量的映射。Word2Vec使用一层神经网络将One-hot形式的词向量映射到分布式形式的词向量。使用SGD(随机梯度下降)[13]的优化算法计算损失,最终通过反向传播算法将神经元的权重和偏置进行更新。最终将One-hot形式的词向量转换为包含更多语义关系的Word2Vec形式的词向量。其中主要依赖CBOW模型(Continuous Bag-of-Words Model)和Skip-gram模型[13]。
2.3 深度学习LSTM
深度学习是机器学习的新领域,它的目标在于通过建立模拟人脑的神经网络,运用人脑的学习机制来解释和分析数据,从而达到对数据本质特征更好的提取,提高预测的准确性[14]。LSTM是一种特殊的RNN(Recurrent Neural Network),LSTM的提出是为了解决RNN的缺点,即对于长序列的梯度向量会存在呈指数增长或减少,使用RNN难以学习序列中的长距离的相关性。它通过引入“门”的结构实现对信息的控制和保护,使其能够长时间保存细胞的状态从而解决了RNN学习长期依赖性的问题[8]。
如图1所示,这是一个LSTM的单元结构。它通常包含3个门的结构、3个输入和两个输出。3个门分别为输入门、输出门和遗忘门,3个输入为上一LSTM单元的细胞状态输出、上一层的输出和当前层的输入。门的设置通常包含一个Sigmoid[15]神经网络层和一个点积乘法操作。这些门可以打开或关闭,用于将判断模型网络的记忆态(之前网络的状态)在该层输出的结果是否达到阈值从而加入到当前该层的计算中。每个LSTM单元包含:输入门xt,忘记门ft,输出门ot,存储细胞状态单元ct,门控矢量it。由于遗忘门会根据细胞的输入输出信息对传送的数据信息进行更新,从而达到对训练时梯度此刻的收敛性和保持重要东西的长期记忆的控制能力。
3 方法
本文提出使用深度学习LSTM网络构建代码审查意见价值评估模型,该模型的工作流程如图2所示。该方法主要分为构建模型和评估模型两个阶段。在构建模型阶段主要为3个步骤:(1)获取代码审查意见数据并对其进行清洗和预处理;(2)将预处理后数据转化为词向量形式的数据;(3)通过深度学习LSTM网络将输入的词向量数据进行学习,获取与代码评审意见价值相关的特征并使用这些特征构建代码评审价值评估模型。在评估阶段,使用模型进行质量评估阶段,向模型输入新的代码审查意见,判断审查人所给意见的有效性。
3.1 数据获取与预处理
本文的数据获取主要来源于GitHub开源社区的232个Eclipse项目,通过Gerrit获取这些项目的代码审查报告。在代码审查报告中,本文主要使用代码审查意见和审查报告来源。由于提交的代码在审查时发现问题后,系统将会把代码审查意见返回给代码提交人员,开发人员将会根据审查意见对代码进行二次修改,直到代码评审人同意通过后再将代码归并到代码库中。开发人员对代码进行修改后,代码审查报告会随之产生对应的3种状态。这3种状态分别为:Replay、Quote和Done,它们的含义分别表示:开发人员已查看并回复、已查看但认为无需修改和已查看并按照修改意见进行修改。由于状态为Done的代码为开发人员接受意见并按照审查意见进行了修改,其他状态多为不接受意见或者认为无需修改。因此本文根据代码审查报告中包含修改意见提交代码的不同状态,将状态为Done的代码审查意见当作是质量过关的审查意见并标记为1,其他状态为无效的代码审查意见并标记为0。
本文根据数据集的特点,对数据进行如下处理:
(1)无意义数据的处理。由于每份代码审查报告中的每条审查意见都对应着源代码的某一行信息、代码审查意见的提交时间和所属分支等数据,因此所获取的审查意见数据对于构建审查意见评估模型并不都是有效果的。而这些数据增加了特征提取难度和后期模型训练时间,因此本文选择过滤这些数据;
(2)停用词处理。在数据集中,存在很多对于特征提取无意义的词汇,例如:we,in,on,and等。为降低后期噪声数据对模型的影响,本文选择对这类文本数据进行清洗;
(3)特殊词汇处理。由于在分词时按照空格或逗号划分语句,可能会出现专有词汇被划分成多个词(例如,项目名为:papyrus/org.eclipse.papyrus,分词后为:papyrus、org、eclipse和papyrus)。这样将会导致审查意见特征缺失。针对这种情况,本文对含有特殊意义的词汇使用“[]”进行标记,在分词时不处理被“[]”标记的内容。
3.2 文本建模
由于在使用深度学习方法对数据进行训练时,所输入的数据是机器可识别的序列化数据,因此需要将现有文本数据转化为计算机可识别的数据。本文使用的词向量化方法为Word2Vec的基于Hierarchical Softmax的CBOM模型[14]。在CBOM模型中,根据输入的训练样本数据,通过模型计算输入实验数据中每个词对应的词向量表示,并将此词向量作为构建审查意见评估模型的输入数据。
3.3 基于LSTM构建代码审查意见评估模型
代码审查意见评估模型的目标是根据代码评审意见和提交代码过程中的源代码来源信息评估审查人所给出的审查建议是否有价值。本文提出评估模型结构图如图3所示,主要包括3个部分:(1)输入层:将文本建模后得到的数据作为下一层的输入数据;(2)特征提取层:将输入层的输出数据作为LSTM模型的输入,获取与代码审查意见评估标准相关的特征;(3)输出层:根据代码审查意见评估其是否有价值。
在输入层中,输入的数据为训练数据经过文本建模后的词向量数据,由于训练数据的相应的分类标签为1或0,所以对标签数据本文选择直接使用。但由于输入的数据量过大,所以在这一层中,加入了一层Embedding层[16]用于对输入数据进行降维,最终构建词向量矩阵。最终将这一层的输出数据作为特征提取层的输入。
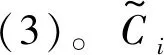
(1)
hi=ot×tanh(Ci)ot=σ(Wo·[hi-1,xi]+bo)
(2)
fi=σ(Wf·[hi-1,xi]+bf)
(3)
(4)
在此过程中,本文设置3个门的激活函数为Sigmoid函数,输出的激活函数为tanh函数,损失函数l为式(5)。根据损失函数和各层的输出使用梯度下降法最终得到最优解、各偏置向量和权重矩阵。词向量数据经过LSTM网络层加工后得到代码审查意见的相关特征。
l(i)=f(h(i),y(i))=‖h(i)-y(i)‖2
(5)
如图3所示,在经过LSTM训练后得到了代码审查意见的特征,为完成特征到审查意见评估标签的转换,本文使用Softmax分类器[18]作为最终的评估结果,此处选用交叉熵作为分类的损失函数,计算方法如式(6)所示。
(6)
其中,y表示期望预测出的评估结果;y′表示实际模型输出的评估结果;x表示词向量数据集;n为数据总量。
通过输入层、特征提取层和输出层后,本文构建了训练阶段的模型。通过对现有代码审查报告审查意见和项目数据进行训练,通过不断调整模型的参数,达到损失函数最小化,从而构建代码审查意见评估模型。本文选用了AdamOptimizer作为参数优化器。同时在训练过程中,为了防止过拟合现象的产生,本文采用Dropout策略[19],设置dropout比率为0.3,即在每次迭代中随机放弃一部分训练好的参数。在预测阶段,模型的输入为一条代码审查意见,评估模型将会评估该审查意见是否有意义。
4 实验
4.1 实验数据
实验采用GitHub上开源的Eclipse项目在Gerrit上相应的代码审查报告作为数据集。在清洗无效数据后,从67 534份代码审查报告中获取了81 414代码审查意见,涵盖352个项目,852个用户,其中被接受即状态为Done的审查意见34 064条,其他状态47 350条。本文将提取代码审查报告中的项目名称和代码审查意见作为实验数据,并根据代码审查评论的状态作为其分类标签。如果审查意见被接受则设置该审查意见的标签为1,否则设置为0。最终,实验对象由代码审查评论、审查报告项目名称和分类标签组成。
4.2 实验参数分析与设置
由于模型评估的准确性与参数的设置有关系,因此需要进行模型参数的调整。在这一步骤中,本文根据实验结果主要考虑了两个参数对实验的影响:(1)batch_size(批大小);(2)max-length(一条代码审查意见的编码长度)。首先在batch_size的选取上,通过实验发现batch_size为60时效果最好。实验结果如图4所示。由于max-length大小相差很大,因此将根据max-length的分布分别设置max-length。实验结果如图5所示,结果显示当max-length设置约为800时评估模型准确性最好。
4.3 实验评估标准与结果
在实验中,为保证实验结果的准确性,本文对每个方法都运行10次,并在运行过程中使用10折交叉验证方法对模型进行测试,最终取10次平均值作为该模型的结果。为研究不同方法对评估模型的影响,本文使用准确率(Accuracy)、召回率(Recall)和F1分数3个指标评估模型,计算方法如式(7)~式(9)所示。
(7)
(8)
(9)
其中,tp为被正确地划分为正例的个数;fp为被错误地划分为正例的个数;fn为被错误地划分为负例的个数;tn为被正确地划分为负例的个数;Precision表示预测的精确度,计算公式如式(10)所示。
(10)
本文的主要目标是根据输入的代码审查意见通过评估模型判断输入的审查意见对软件开发人员是否有意义,从而减少代码审查周期和成本。因此,本文主从以下3个问题探究使用本文方法构建该评估模型的有效性。
RQ1:基于深度学习LSTM的方法构建代码审查意见评估模型是否比其它方法更有效?
由于本文目标是建立合适的代码审查意见评估模型,因此训练模型的选取对于构建合适的评估模型十分重要。因此本文也选取了其它训练方法用于构建评估模型用于验证现有模型的有效性。本文分别选取了以下3个机器学习方法:朴素贝叶斯(Bayes)、支持向量机(SVM)和LSTM模型非常相近的循环神经网络(RNN)。实验结果如表1所示,结果显示使用LSTM方法构建评估模型准确率最高,分别比Bayes方法、SVM方法和RNN方法高出了。因此,使用LSTM方法构建代码审查意见评估模型是十分有效的。
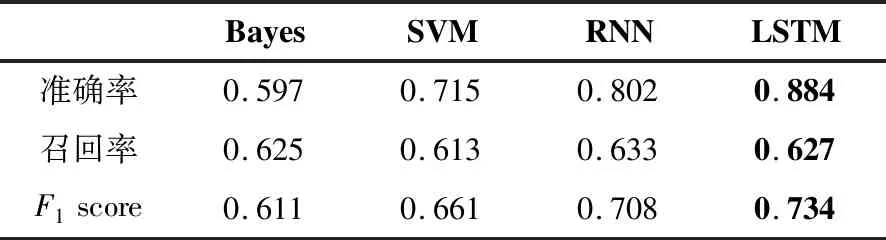
表1 LSTM方法与其他方法比较结果
RQ2:实验数据集的选取是否对评估模型有影响?
由于本文实验数据来自352个项目,共有800多位人员给出了代码意见。因此存在对同一个项目,代码审查意见可能有很大的相似性。这导致了训练模型难以提取代码审查意见的评估特征。 因此本文根据每个项目包含的审查意见数据量,分别选取了项目数据量约为50、100、200、500、1 000、2 000、4 000的7个项目作为实验对象,实验结果如图6所示。结果表明,对于同一个项目的代码审查意见,评估模型准确率最高达到92.1 %,最低为83.8 %,这可能是由于代码审查意见的相似性和审查人的选取导致了评估模型的准确率发生了浮动。
RQ3:在构建模型时,如果使用其他文本建模方法是否对实验结果有影响?
由于文本建模目的是将代码审查意见转化为包含更多语义信息的序列化数据,因此文本模型的选取对于包含更多原始数据信息十分重要。针对本文选取的Word2Vec词向量模型是否比其他构建词向量方法更有意义问题,本文分别选取了One-hot编码[20]、Skip模型和Word2Vec模型分别进行了实验。实验结果如表2所示。结果显示,采用One-hot的训练后的词向量方法表现的很差,Skip模型表现一般,而Word2Vec方法表现的最好。因此本文选取的Word2Vec方法对于本文数据构建词向量化是十分有用的。

表2 不同文本建模方法在训练模型后结果
5 结束语
本文使用深度学习LSTM方法,通过对开源Eclipse项目的代码审查报告中的审查意见进行训练学习,得到了代码审查意见评估模型。通过实验,结果显示该模型的准确率在352项目下为88.4%,比其它机器学习方法(贝叶斯分类法、支持向量机分类法和循环神经网络等方法)有很大的提高。在接下来的研究中,由于审查意见的长度相差较大,期望可以使用混合模型的方法对篇幅较长和极短的审查意见进行进一步的划分,从而达到提高该评估模型的准确性。
