Slope One算法的改进及其在大数据平台的实现
2020-01-06刘佳耀王佳斌
刘佳耀,王佳斌
华侨大学 工学院,福建 泉州362021
1 引言
随着大数据时代的到来,推荐系统[1]在很多领域的作用越来越突出,在一定程度上解决了用户很难获得自己真正需要的商品的问题。而协同过滤[2]技术在推荐系统又得到广泛应用。Slope One 算法[3]是协同过滤算法中的一种,在相同推荐精度下,与其他类型的协同过滤算法相比,其更高效,更易于实现。但随着用户项目数量大规模增长,数据稀疏性、实时性、可扩展性等问题导致推荐质量大幅下降。
由于Slope One 算法只考虑了项目与项目之间的评分偏差,推荐效果不是很理想。文献[4]在原始的Slope One 算法加权已经评过分的用户个数,均衡了其他项目对目标项目的影响,使得推荐效果有所改进。文献[5]利用Weighted Slope One 算法的思想填充用户项目矩阵中未评分的项目,缓解数据稀疏的问题,紧接着在最近邻居集合中产生评分预测,一定程度上提高推荐精度。文献[6]对相关用户运用新改善的K-means 聚类方法进行聚类实验,筛选出相似度高的用户聚为一类,避免相似度低的用户加入计算,提升推荐准确性。在大数据时代,仅仅依靠单机模式很难满足推荐系统的需要,因为单机的内存运算的劣势。文献[7]通过搭建Hadoop[8]大数据集群来迭代推荐算法,可以减少推荐的时间,但是MapReduce[9]框架进行迭代计算时速度缓慢,很大程度影响实时推荐效率。
由于加权Slope One 算法[10-11]仅利用项目评分值来计算项目之间的相关性,如果用户项目数稀疏,则可能导致算法计算的预测评分值有较大误差,推荐准确度低。因此,本文把聚类加权的Slope One算法在Spark[12]平台上并行化,来更好地提高Slope One算法的推荐精度、并行化和效率。
2 相关工作
2.1 用户-项目评分矩阵
在传统的推荐算法中,利用m×n 阶用户项目矩阵来存储用户-项目的具体评分信息。用ri,j来代表具体用户对具体项目产生的评分(i 代表某个用户,j 代表某个项目),n 个项目用集合I={i1,i2,…,in}来表示,m个用户用集合U={u1,u2,…,um}来表示。表1为一个阶用户项目评分矩阵。

表1 评分矩阵
2.2 Slope One算法
原始的Slope One 算法利用一个线性函数f(x)=x+b 的形式进行预测,其中,参数x 代表目标用户对项目形成的评分,参数b 代表项目之间的平均评分偏差。所以在评分预测推荐过程中,首先利用公式(1)计算出目标项目与其他项目之间的平均评分偏差矩阵{Devj,i}(j 代表目标项目,i 代表其他的某个项目),最后利用公式(2)预测对应项目评分Prediction(u)j(j 代表某个项目,u 代表某个用户)。

其中,X 为用户项目评分集,count(rj)表示在rj中的项目总数(j 代表评分项目),ru,i、ru,j分别为用户u 对具体项目i 和j 产生的评分(u 代表某个用户,i 和j 都代表某个项目),rj为同时与j 被评分过的项目集合,Sj,i(X)为在用户项目评分集中都评分过j 和i 的用户集合(j 和i 都代表被评分过的某个项目)。
通过表1 的用户-项目评分矩阵实例来得到项目的预测评分值。因为已知用户u2、u3对项目i2的评分,先用公式(1)计算评分之间的偏差值Dev2,1=[(4-2)+(3-3)]/2=1,Dev2,3=(4-2)/1=1;接着用公式(2)计算用户u1对项目i2的评分值为P(u1)2=[(2+1)+(3+1)]/2=3.5;最后对未评分的项目都进行评分预测并比较评分值大小为相应用户产生项目TOP-N推荐。
2.3 Weighted Slope One算法
在计算项目之间的偏差devj,i(j 和i 都代表某个项目)时,没有考虑到加权用户具体个数得到的devj,i,Slope One算法的准确程度是不同的。如果有500个用户同时评分了项目i 和项目k,另外一个只有50个用户同时评分了项目i 和项目j,得到的devi,k肯定比devi,j更精确。所以用评分过的用户数的平均数进行加权,如式(3)所示:

其中,P(u)j代表用户u 对项目j 的预测评分(j 代表某个项目,u 代表某个用户),ui是具体的评分值(i 代表某个项目), ||Cji是相应的用户具体数量的权值(i 和j都代表某个用户)。
3 本文方法
3.1 Slope One算法加权项目的相似性
仅仅在算法的预测评分公式中加权相关用户个数,在进行推荐预测时没有考虑到项目与项目之间的差别,使相关性很低的项目对推荐预测产生干扰,而真正相关性高的项目被忽略。本文先运用文献[11]提出改进的Slope One算法,将项目相似性当作一个有效的权值加权到Slope One算法的评分预测中,相关计算公式如下:
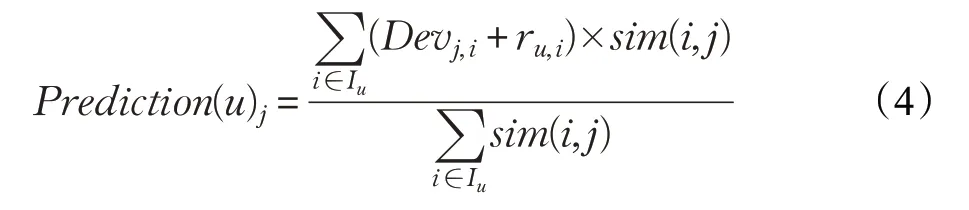
项目之间相似性的计算是推荐系统中的关键部分,可以区分出项目之间的相似程度的高低。最近邻集合的准确性很大程度取决于相似性计算的结果,并也决定了最终评分预测值的准确性。Pearson相关相似性公式利用用户评分值减去对项目的平均评分值,留下了用户的评分偏好,更能体现出各个项目的相关程度,所以用式(5)求得各个项目的相似度大小:
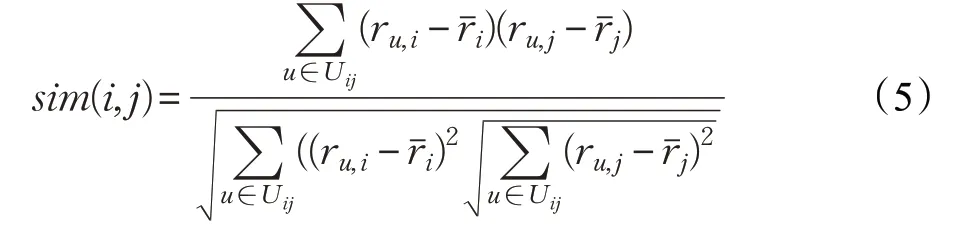
其中,用户对项目j 和i 的评分的均值用rˉj和rˉi(i 和j都代表某个项目)来表示,即评价过j 和i 的用户集合用Ui,j(i 和j 都代表某个项目)来表示。
3.2 结合Canopy和K-medoids的聚类算法
由于用户项目数量规模急速增加,在计算用户偏好矩阵时时间复杂度很高,很难满足实际的推荐场景。Kmeans 聚类算法由于简单,收敛的速度快,有很大的运用优势,但K-means聚类算法也有很大的弊端。然而Kmedoids 聚类算法跟传统的K-means 算法相比,它能快速地找到噪声点,减少聚类结果受噪声点的干扰,而且K-medoids 算法的质心肯定是数据中一个明确的点,聚类效果是比较好的。与传统的聚类算法不同,Canopy聚类最大的特点是对大规模的数据集只需遍历一遍,就能得到簇的个数,不需要事先指定K 值[13],直接用簇的个数当作K值,具有很大的使用价值。所以本文结合两种算法,先运用Canopy[14]算法对数据集进行遍历得到相应的簇的个数和全局的中心点,接着用K-medoids 算法计算到各个中心点的距离,进行划分,可以有效提高聚类效果。选择初始距离阈值时,需要把T1设为大于T2。当T1过大时,会使许多点属于多个Canopy,可能会造成各个簇的中心点间距离较近,各簇间区别不明显;当T2过大时,增加强标记数据点的数量,会减少簇个个数;T2过小,会增加簇的个数,同时增加计算时间。其算法的基本步骤如下。
(1)项目评分向量集I={I1,I2,…,In}按照一定的规则进行排序,Canopy初始距离阈值T1、T2(采用交叉检验方式获得)。
(2)在评分向量集I 中随机挑选一个向量A,使用欧式距离公式快速计算A 和向量集中其他向量之间的距离D。
(3)根据第(2)步中所求的距离D,把距离小于T1的向量分到一个Canopy中,同时把距离小于T2的向量从项目评分向量集中移除。
(4)重复第(2)、(3)步,直到候选中心向量为空,算法结束。
(5)获得项目聚类集合,聚类中心集合C′。
3.3 在单机上改进的Slope One算法
把改进的Slope One算法在单机上运行的相关步骤:
(1)对要进行实验的电影数据集进行预处理,形成项目评分矩阵。
(2)通过式(4)计算项目与项目之间的评分相似性。
(3)利用Canopy和K-medoids的聚类算法得到K个聚类,并将目标项目划分到最相似的聚类中。
(4)在目标项目Ij(j 代表某个项目)所属的聚类中,通过步骤(2)的方法得到与Ij相似度高的相关项目,最近邻居集合是从相似度最高的项目中由大到小选取N 个项目组成的。
(5)利用式(3)在目标项目Ij所属的最近邻居集合中进行评分预测,产生Top-N项目。
4 基于聚类的加权Slope One推荐算法及其在大数据平台上的实现
随着用户和项目的数量以惊人的速度增长,执行Slope One 算法时产生的中间结果也会快速增多,内存的压力就越来越大,当内存容量不足时就只能先存储到磁盘中,大大地降低了推荐效率。因此,利用分布式计算Spark平台,让数据只在内存中计算,不在磁盘中来回读取,提高算法的运行速率和推荐效率。
对RDD的处理,实现实际应用的各种计算;RDD抽象形式数据集有两大特点:(1)内存存储,所有数据都放在内存中进行操作,不经过磁盘的读写,提升数据处理速度;(2)较好的容错性,RDD 的容错通过记录日志的方式,可以避免检查点的方法引起的数据冗余问题,而加大网络通信开销。
通常情况下一般的推荐算法训练模型都要进行大量的迭代计算,利用传统的单机或者MapReduce计算框架,已经很难满足海量数据的实时处理,所以基于Spark计算框架能够有效提高推荐效率。
4.1 改进算法的算法描述
对改进的推荐算法标准的算法描述如下:
算法1 Canopy-K-medoids的聚类算法
Input:电影用户-项目向量集I{I1,I2,…,In},Canopy 设置的阈值T1和T2
Outout:K 个最近邻用户聚类集合
1. Converged=false,iteration=0
2. While Converged is false
3. For each Canopy(i) in Canopies
4. For each Ciin CanopyCenterList C(C1,C2,…,Ck)
5. Get the minValue of Wi:Dist(Li,Ci) in Canopy(i)
6. Add Ciinto corresponding Cluster(i)
7. End for
8. End for
9. For each Cluster(i) in Clusters
10. Get the
11. Add L′iinto L′(L′1,L′2,…,L′n)
12.End for
13.For each L′iin L′(L′1,L′2,…,L′n)
14.For each Cjin CanopyCenterList C(C1,C2,…,Ck)
15. If(Dist(L′i,Cj)<=T1)
16. Add L into Canopy(j)
17. End if
18. End for
19.IF(L′i-Li<Converge Dist)
20. Converged=true
21.End IF
End while
算法2 加权的Slope one算法的描述
Input:K 个最近邻用户聚类集合,用户项目评分矩阵
Output:用户u 对项目j 的预测评分ru,j
1. 在所属聚类中得到用户U 评分的项目集合Iu
2. If Iu是个空集或者不存在
3. ru,j=0
4. End if
5. For each item i in Iu
6. If cj,i>0
7. up=up+(ru,i+devj,i)×cj,i
8. Down=down+cj,i
9. End if
10.End for
11.If down>0
13.End if
14.Return ru,j
4.2 基于Spark平台的聚类加权Slope One算法
在大规模数据背景下,在聚类中形成最近邻集合、搜索最近邻和推荐预测中都需要反复计算平均偏好差异值和项目相似度,这样在单机上进行计算效率低下。所以利用有内存优势的Spark 集群来实现算法的并行化。实验可以分成两步:第一步先实现基于Canopy 和K-medoids[15-16]的聚类算法在Spark 平台上的并行化;第二步再实现加权了项目相似度[17]的Slope One 算法在Spark平台上的并行化[18]。
结合Canopy 和K-medoids 聚类算法并行计算过程中的任务划分和汇聚。
Map 1 过程:计算数据对象到中心点的距离,生成若干个Canopy;Reduce1 汇聚过程:将中心点的数据对象汇聚,生成Canopy中心点的集合。
Map 2 过程:把Canopy 算法快速得到的中心点分发到每个分区当作K-medoids的最初的中心点进行聚类计算,计算数据对象到中心点的距离并且进行归类;Combine 过程:将中心点的数据对象汇聚,计算同一个中心点数据对象之和。Reduce2 汇聚过程:汇聚聚类局部结果,继续计算新的中心点。并判断是否收敛,直到算法结束。
结合Canopy和K-medoids聚类算法伪代码:
1.Val lines=sc.textFile(DataInput)//从HDFS中读取数据生成RDD
2.Val data=lines.map(Vector_)//把文本数据转化成向量形式
3.Val CanopyMapCenterList=new HashSet()//计算对象到中心点的距离
4.Val Centers=datas.map{
X=>(x._1,Canopy_1(x,CanopyMapCenterList,T1))} //当两者距离大于阈值T1,把新的中心点加入Canopy中。
5.for(i<-0 util Center.Size){
Canopy_1(CanopyCenterList,T1)}
Val CanopyT2=datas.map{
Y=>(y._1,Canopy_2(x,CanopyMap,T2))}
While(dist>convergeDist || iteration<Max){
MapCanopyT2=CanopyT2.map //计算每个对象和Canopy中心点的距离,把小于T2的对象加入子集;
6.For((index,value)<-newCentercluster){
Centercluster(index)=Canopy_1(centerList,T2)}//计算各个新中心点的Canopy 子集,计算新旧中心点的平方差,进而更新中心点。
在所属聚类的最近邻集合中进行加权项目相似度的Slope One 算法评分预测的并行计算过程中的任务划分和汇聚。
Map1过程:把电影数据集转化成向量的形式,并分发给各个节点,获得用户-项目的倒排表,一一得到各节点的项目之间共同评分的用户;Reduce1汇聚过程:汇聚所有项目之间的共同评分用户。
Map2过程:计算项目之间的相似性。
Reduce2汇聚过程:汇聚所有项目之间的相似性。
Map3过程:计算各个项目之间的喜好差异值。
Reduce3汇聚过程:汇聚所有的喜好差异值。
Map4过程:把项目相似性和喜好差异值进行加权。
Reduce4汇聚过程:把最终结果汇聚成[(user,item),Dev]的形式,并进行评分预测,完成TOP-N的推荐。
具体的伪代码如下:
1.Parttion=C; //划分为C 个分区并行计算
2.Sc=new SparkContext()//初始化Spark上下文
3.Ratings=sc.textFile().map(split).cache() //格式化评分数据
//并行化实现,得到用户-物品倒排表,数据cache
4.Item_user=lines1.parallenlize(0 until
P).map(parseVectorOnItem).groupByKey().map(
Lambda x:sampleInteractions(x[0].x[1])).cache()
//计算项目之间的相似性
5.Item_sims=pairwise_users.map(
Lambda x:calcSim(x[0],x[1])).map(
Lambda x:keyOnFirstUser(x[0],x[1])).groupByKey().map(
Lambda x:nearestNeighbors(x[0],x[1],10));//预测评分
6.Val predict=(rat+Dev)*item_sims/SumSimW
//根据相似度的大小,为用户推荐最感兴趣的前N个项目
7.Val recommendations=bestModel.get
.predict(candidates.map((0,_))).collect()
.sortBy(-_.rating).take(N)
4.3 改进算法在Spark 中Map 和Reduce 的 实现代码
在spark 平台中实现的Map 和Reduce 主要代码如下:
Val data=lines.map(parseVector_).persist(StorageLevel.MEMORY_ONLY_SER)//map代码
Val CanopyMapCenterList=new HashSet()
Val crudeCenters=data.map{ //map代码
X=>(x._1,Canopy_1(x,CanopyMapCenterList,T1))}
.filter(y=>y._2!=null).collect().toList
//reduce代码
Val ClusterCenterList=new Hashset(CanopyList)
While(tempDist>ConvergeDist||iteration<maxIteration)
{
MapCanopyT2=CanopyT2.map //map代码
{do=>(closestCenter(do,ClusterCenterList),(do,1))}
Val newClusterCenterList=mapCanopyT2.reduceByKey
{Case((s1,c1),(s2,c2))=>(s1+s2,c1+c2)}.map
{case(index,(s,c))=>(index,s/c)}.collect()
//reduce代码
For((index,value)<-newClusterCenterList){
tempDist+=ClusterCenterList.get(index).get.SquaredDist(value)
ClusterCenterList(index)=Canopy_2(value,CanopyCenterList,T2)}
Val path=”hdfs://hadoop1:9000//m1_100k/ratings.dat”
Val lines=sc.textFile(path,20)
Val ratings=lines.map{line=>//map代码
Val fields=line.split(“::”)
(fields(3).toLong%100,Rating(fields(0).toInt,fields(1).toInt,fields(2).toDouble))
}.filter(_._2.rating>0.0)//map代码
Val numRatings=ratings.count()//reduce代码
Val Users=ratings.map(_._2.user).distinct().count()//reduce代码
Val Item=ratings.map(_._2.product).distinct().count()//reduce代码
Val ratings2=ratings1.flatMap{x=>//map代码
For(user<-x._2)
Yield{(user._1,(x._1,user._2))}
}.groupByKey()
.map{x=>
Val b=x._2.toBuffer.sorted
(x._1,b)
}
Val sumSimW=userItems.map{x=>//map代码
Val sim=x._2._3.toInt
Val numUser=x._2._2._2
Sim*numUser
}.reduce(_+_)//reduce代码
Val pre=userItems.map{x=>//map代码
Var b=-1 000 000.0
If(x._2._1._1==0)b=-x._2._2._1
Else b=x._2._2._1
Val rat=x._2._1._2
Val sim=x._2._3
Val predict=(rat+b)*sim/sumSim
Predict
}.reduce(_+_)//reduce代码
Val myRatedMovieIds=myRatings.map(_.product).toSet//map代码
Val recommendations=bestModel.get.predict(candidates.map((0,_))).collect().sortBy(-_.rating).take(10)//reduce
代码
5 平台搭建与实验结果分析
搭建大数据Spark 平台,在VMware 中创建三台虚拟机,把其中一台设为主节点,另外两台设为从节点。操作系统版本均为Centos7,在操作系统上采用Scala-2.11.4,Spark-1.6.0,JAVA-JDK1.8 和Hadoop-2.6.1 等来创建集群环境。
实验运用的是MovieLens 数据集,包括ml-100k、ml-1M和ml-10M三个不同大小规模的数据集。其中数据集ml-100k用相应评分值大小来代表用户对电影的满意程度,评分值(1~5 的整数)越高,用户对该电影越满意。实验采用五折交叉验证法进行验证,将ml-100k的数据集[19]随机划分为不相交的五份,随机抽取一份当作测试集,留下来的四份作为训练集,需要反复实验五次,最终结果是反复实验五次数值的均值。实验从运行时间、并行化加速比和推荐指标(MAE)这三个角度来分析实验结果。
5.1 大数据平台下改进算法程序流程图
大数据平台的加权Slope One和Canopy-K-medoids聚类推荐算法[20]并行化具体流程,如图1所示。
算法具体步骤描述如下:

图1 算法流程图
(1)用maPartition()函数对RDD的每个分片进行筛选,找到canopies。接着用reduceByKey(_+_)的形式得出每个分片的canopies,产生总的canopies[21]。并把canopy centers 分发到各个分片中,成为K-medoids 的最初的中心点。然后开始不断对改进的聚类算法进行迭代,等到生成相应数据的聚类完成,再把聚类结果用Reduce()进行汇总,最后分发到各Slave节点中。
(2)先把相应的数据集上传到HDFS 上,把用户项目评分数据集预处理成key-value 键值对,并将键值对转化为RDD的形式。接着根据相应的各个键值生成用户—项目对应倒排表,在倒排表中项目和项目的评分用reduceByKey(_+_)的形式得出。然后调用Similaritymap()函数计算项目评分相似性。
(3)各个项目的平均评分偏差Dev 可以通过group-ByKey()函数一一得到,然后通过读取上述聚完类的结果,在生成的各个聚类中形成相应的K 近邻集合。最后通过Predict()函数在最近邻集合中生成预测评分。最后利用recommendations()函数为用户推荐相似度高的Top-10个项目,并将结果存进HDFS中。
5.2 运行时间
根据不同大小电影数据集在Spark平台下推荐模型的运行训练时间,如图2、3所示。
从图2 中可以看出,用同一个电影数据集在Spark集群中进行实验,增加集群中节点数可以大大减少数据的处理时间,从而加快算法的执行速度而且Spark 集群节点数越多优势越显著。从图3 看出随着集群中节点的增加,处理大数据集的速度越来越快。
5.3 加速比

图3 大数据集运行时间
实验根据加速比参数的大小来判断并行化算法的性能,加速比Speedup根据单节点串行时间与多节点并行时间之比来判断算法的并行化性能好坏,加速比越大则代表并行化越好,其计算方式如公式(6)所示:

其中Tp为多个并行节点运行的时间,T1为单个节点运行的时间,实验结果如图4所示。

图4 加速比对比
从图4可以看出Spark集群中的机器节点从一个节点增加到三个节点,加速比也随之升高,并且电影数据集由小到大,加速比增长变快。
5.4 运行效率
在Spark平台和单机环境下对比本文优化算法的运行效率,以具体改进算法完成的运行时间长短来比较运行效率的高低,如表2所示。
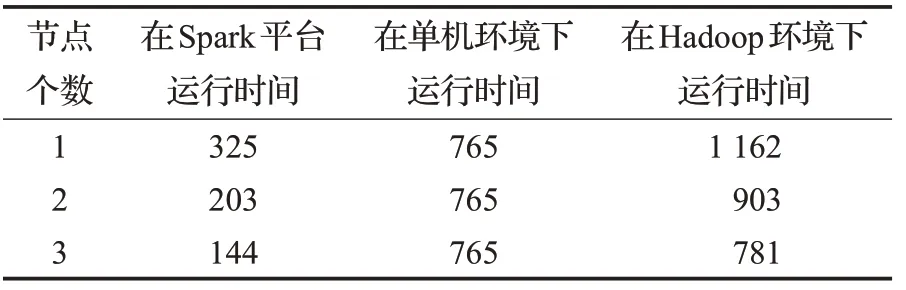
表2 本文优化算法运行时间 s
从表2 看出,与单机耗时为765 s 相比,相同的改进算法在Spark 平台上的运行时间更短,在实际推荐过程中可以大大减少推荐的时间,提高效率。主要是算法在Spark平台上进行迭代时,计算的中间结果可以缓存,进而减少数据交换的传输时间,RDD 算子之间的转换也是延迟的,只有到action 时,才会触发运算。而Hadoop集群,需要先用map函数把数据写到磁盘上,在reduce函数去磁盘上读取,增加了数据传输时间。从图5可以更加直观地对比出本文优化算法在Spark平台上的运行效率比单机环境下的高。

图5 运行效率对比
从图5 中可以得出,随着Spark 集群中的节点数增加,运行时间也降低了,而且仅包含一台节点的集群的运行效率也比单机环境的运行效率高。
5.5 平均绝对误差
在评测推荐系统质量好坏时,推荐质量的好坏常用平均绝对误差(MAE)来作为评价指标。MAE的指标是用来计算推荐过程中得到的实际评分和预测评分的评分之间的差异,通过具体数值的大小来代表推荐的准确性,计算公式如下:

其中,N 为测试集中的总个数,pi为用户对物品i 预测评分值,qi为对应的用户对物品i 的实际评分值。因此,MAE越小代表预测值与实际值越接近,推荐结果越准确。
为了比较改进的算法(单机版)、改进算法在Spark平台的并行化和原始的Slope One 算法之间的推荐准确性的高低,使用的数据集是ml-100k电影数据集,通过比对不同邻居个数下,MAE 值的变化来确定推荐性能的好坏,如表3所示。
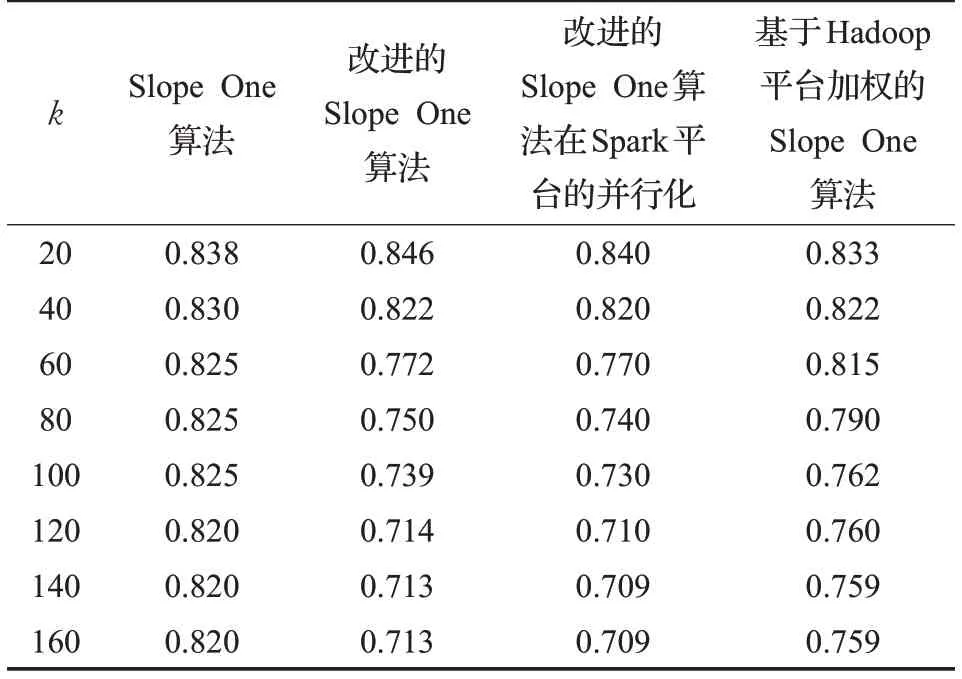
表3 对比算法的MAE值变化
从表3 中看出,随着最近邻居的个数不断增加,每个算法的MAE 值都呈下降趋势:当最近邻个数k >40时,该优化算法的推荐精度已经慢慢优于传统的Slope One算法;当最近邻个数k≥120 时,各算法的MAE值都趋向平稳。最后,在Spark集群下该优化算法MAE值和单机下优化算法的MAE 值基本持平,这表明该优化算法不仅能保证推荐预测的准确性,而且能在大数据场景下能够减少算法迭代的时间,减少推荐时间,提高效率。然而没有结合聚类算法的加权Slope One 算法的MAE值明显高于本文优化的算法。
5.6 单机的算法对比
为了对比改进后算法与其他算法的推荐效果,在单机上对同一个数据集ml-100K 进行了算法推荐精确度的比较,对比的算法分别为加权项目相似性的Slope One 算法、传统的Slope One[22]算法以及本文的优化算法,采用评价指标MAE,如图6所示。
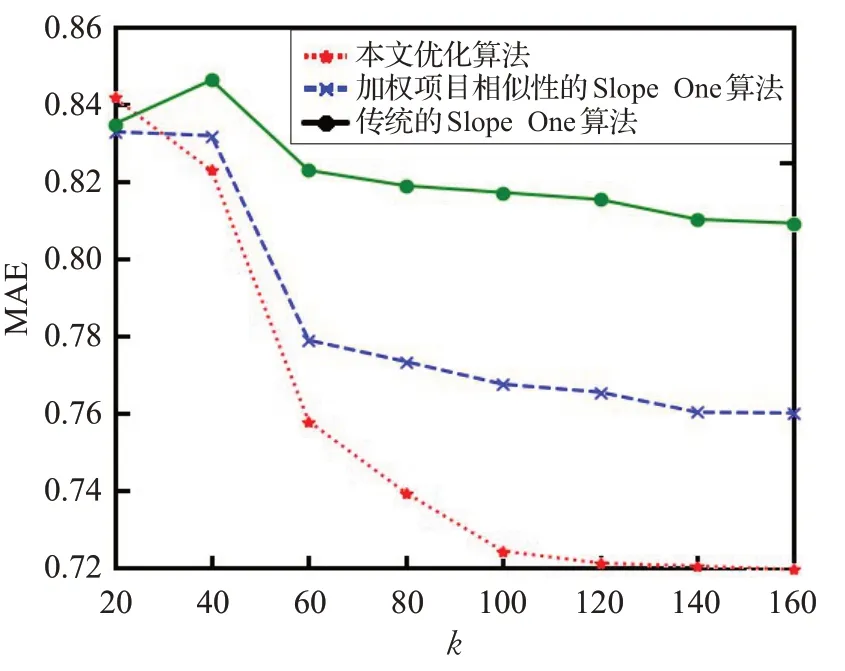
图6 在单机上算法推荐精度对比
从图6 中可以得出,随着最近邻居个数的不断增加,三种算法的MAE值都呈明显的下降趋势,也表明了推荐精度在上升。在k >40 后,本文优化算法的MAE值整体低于原始的Slope One算法和加权的Slope One算法。当k >60 后,MAE 下降的趋势渐渐趋于平缓。在k=150 时,各个算法的MAE 的值最小,此时推荐效果最好。这很好地说明在算法中加权项目相似度和引入聚类后,有效提高了推荐预测准确性。
5.7 单机上和Spark平台上的优化算法对比
为了对比改进后的算法在Spark平台上和单机上的推荐效果,对同一个数据集ml-100k和ml-1M进行了实验,评价指标为MAE,如图7、8所示。

图7 本文算法在单机环境下和Spark平台的MAE值对比
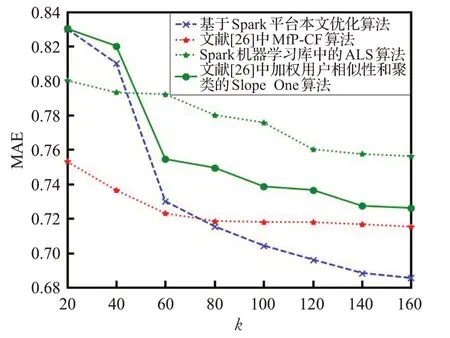
图8 在Spark平台上算法推荐效果对比
从图7中可以得出,当最近邻个数k <60 时,与单机环境下相比,基于Spark 平台的本文优化算法推荐精度优势不大,但随着k >60 后,基于Spark平台的本文优化算法的推荐精度慢慢提高并开始略优于在单机环境下的本文优化算法的精度。这说明在Spark 平台下,可以稍微提升精确度,并能保持精确度不降低的情况下,还能提升算法迭代的效率。
5.8 集群环境下的算法对比
为了对比改进后算法与其他算法在Spark平台上推荐效果,对同一个数据集ml-100k进行了实验,选用的算法分别是Spark ML 库中的ALS 机器学习算法[23]、文献[24]中加权项目相似性的Slope One算法以及本文优化算法,评价指标为MAE,如图8所示。
从图8中可以得出,在Spark集群环境下,随着最近邻居个数的不断增加,在k >40 后,本文优化算法明显优于Spark ML 库中的ALS 推荐算法和文献中加权项目相似性的Slope One算法,与MfP-CF推荐算法相比,在k <80 时,MfP-CF[25]推荐算法的推荐准确性是明显优于本文改进算法的,但当80 <k <160 时,随着最近邻个数的增加,本文优化算法明显优于MfP-CF推荐算法,而MfP-CF推荐算法的MAE值渐渐趋于平缓,本文优化算法随着最近邻的增加,MAE 的值还在继续减少,推荐精度逐渐变高。说明加入canopy 和K-medoids的聚类的并行算法能够明显提升推荐的精度,与图7的单机环境下的MAE 值相对比也说明了在Spark 集群环境下,推荐的精确度差别不大的情况下,可以提升算法的迭代速度。
6 结论
由于原始Slope One 算法单机环境下算法迭代速度慢和在大数据集下推荐精确度较低的缺点,在Slope One算法的评分预测公式上加权项目相似度,尽量避免相似度低的噪声点混入评分预测计算,然后通过Canopy和K-medoids结合的聚类并行化算法形成相似项目的聚类以缩短搜索最近邻的时间,使Slope One算法的推荐精度有了一定程度的提高。并且,把本文优化算法基于Spark 平台实现并行化,得到的推荐精度要略优于单机环境下的优化算法,进一步的提高了推荐准确性。对比单机的效率低下,采用内存优势的Spark平台,使算法的可扩展性明显提高,并能较好地处理大规模数据集,加快算法的迭代效率。
