配电物联数据驱动业务以及边云协同功能研究
2020-01-05葛永高李澄潘诗强王伏亮陆玉军王江彬
葛永高 李澄 潘诗强 王伏亮 陆玉军 王江彬


摘 要:当前配电物联数据驱动业务中数据资源分配均衡性差、规划效率低,影响协同功能的实现。本文改进了配电物联数据驱动业务以及边云协同功能。通过事件驱动收集底层用电数据,经过预处理生成区间数据,将数据统一支配实现数据驱动业务。采用API技术使计算机与具有socket接口的设备保持通信,设计云计算中心与边缘设备的通信功能,设置配电网中控制模块功能,从而实现边云协同功能,保障配电网全局运行。实验结果表明:在相同的测试条件下,与传统的配电物联数据驱动业务及协同功能相比,提出的配电物联数据驱动业务中数据资源分配均衡性较高,有效提高配电物联数据资源规划效率,保证了边云协同功能的正常运行,满足实际应用需求。
关键词:物联网;数据驱动;数据处理;边云协同;
中图分类号:TP391 文献标识码:A
Research on Data-driven Business of Distribution IoT
and Edge Cloud Collaboration
GE Yong-gao1,LI Cheng1,PAN Shi-qiang2,WANG Fu-liang1,LU Yu-jun1,WANG Jiang-bin1
(1. Jiangsu Frontier Electric Power Technology Co.,Ltd.,Nanjing,Jiangsu 211100,China;
2. Jiangsu Hoperun Zhirong Technology Co.,Ltd.,Nanjing,Jiangsu 210012,China)
Abstract:In the current distribution-driven IoT data-driven business,the distribution of data resources is poorly balanced and planning efficiency is low,which affects the realization of collaborative functions. This paper improves the data-driven business of distribution IoT and the collaborative function of edge cloud. Event-driven collection of bottom-level electricity data,pre-processing to generate interval data,and unified data control to achieve data-driven business. The API technology is used to keep the computer in communication with devices with socket interfaces,the communication function between the cloud computing center and the edge devices is designed,and the control module function in the distribution network is set up,so as to realize the collaborative function of the edge cloud and ensure the global operation of the distribution network. The test results show that:under the same test conditions,compared with the traditional distribution IoT data-driven business and collaborative functions,the proposed distribution IoT data-driven business has a higher balance of data resource allocation and effectively improves the distribution of electricity The efficiency of connected data resource planning ensures the normal operation of the edge cloud collaboration function and meets actual application needs.
Key words:internet of things;data-driven;data processing;edge cloud collaboration
在現代人类社会中,最不可或缺的能源就是电力能源,该能源是使用最广泛的清洁能源,并且广泛应用在人们赖以生存的各种相关产业及日常生活中[1]。将物联网技术应用在配电网中,将用电设备的各种状态信息以及各项环境参数等数据发送到物联网节点,通过通信传输模块将数据再传送到服务器上,达到对配电设备的全面感知的目的[2]。
目前相关领域不同学者对配电物联数据驱动业务以及边云协同功能进行了研究,并取得了一定的研究成果,文献[3]采用配电物联网技术,构建边云协同、管理传输、感知层终端的配电物联网体系架构,提升了配电网的智能化管控能力,同时形成相应的新型应用模式,依据试点成果,完成配电物联网对电力系统的实施效果。该方法的数据资源分配均衡性较好,但该方法应用于配电物联数据资源规划时间较长,导致数据资源规划效率较低。文献[4]运用边缘计算技术,定义云主站与端侧之间的关系,构建边缘计算的标准架构,完成轻量级数据处理,建立数据中心交互机制,并协同配电自动化,实现边云协同机制。该方法的数据资源规划时间较短,能够有效提高配电物联数据资源规划效率,但该方法的数据资源分配均衡性较差,影响边云协同功能的正常运行。
配电物联网的使用使得对用电设备的各种数据的采集和处理更为方便统一,但是随着配电物联网的逐渐增大,用户数量的增加,感知层收集的数据量越来越多,通过数据驱动业务使用,使其在数据量爆炸的情况也能始终保持稳定状态[5-7]。同时由于现阶段配电网采取的多电源网络管理模式,更加注重跨区域资源间的协同优化配置,向下协调区域内电能分配以及电源资源平衡。但是传统的配电网物联数据驱动业务存在数据资源分配均衡性差、规划效率低的问题,影响后续的跨资源间的协同优化[8-10]。因此,提出配电物联数据驱动业务以及边云协同功能研究,解决传统的数据驱动业务中存在的数据资源分配不平衡的问题。
1 配电物联数据驱动业务以及边云协同功
能研究
1.1 基于事件驱动的数据收集
配电物联数据的收集主要利用物联网智能节点对需要处理的数据进行收集,在配电物联数据驱动业务中,需要根据不同的工作环境,确定不同的数据收集模式[11-13]。常见的收集方式有2种,分别是周期性汇报式数据收集和事件驅动式数据收集。根据配电网的实际需求,事件驱动式是最好的选择。
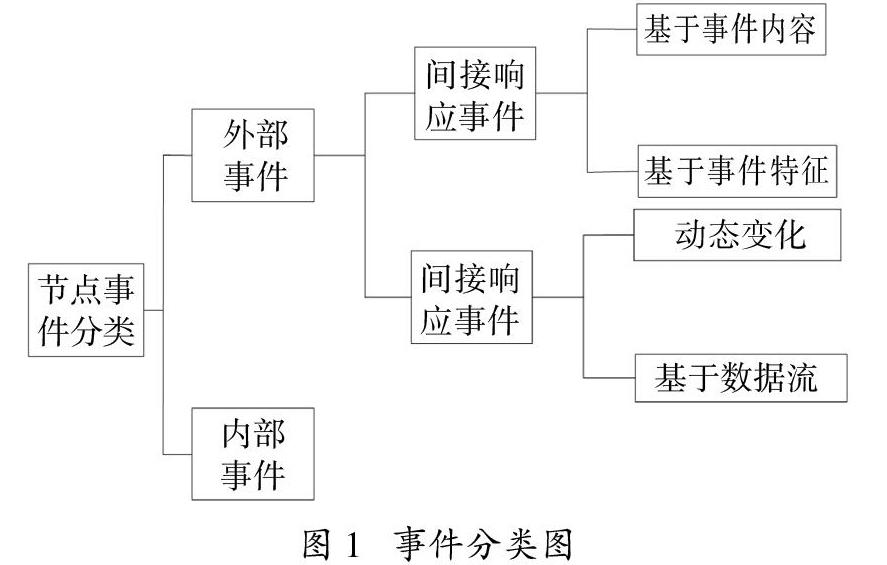
当需要处理的事件发生时,设置在感知层的终端模块主动采集与事件触发时间相关的数据,并通过设置的无线网络传输模块将数据传输至网络节点[14-15]。物联网智能节点对获取的来自感知层终端设备的相关用电数据进行解析,根据事件的性质不同,分类为不同类别的事件。事件分类如图1所示。
根据事件的性质,将其分为外部事件和内部事件。外部事件负责管理传输指令以及数据反馈,内部事件负责从底层终端主动上传数据[16-17]。成功分类后,根据事件不同的类别分类保存事件数据,在确定存储之前,考虑事件内容数据以及基于动态变化的数据,按照不同事件类型所包含的数据格式、时效、数据量以及后续预处理来确定最终的存储命令[18]。
同时考虑物联网节点的空间资源比较小,需要对物联网节点所存储的数据的时效以及存储量进行限制,最有效的手段就是根据不同事件类型的数据采取不同的存储时效及存储数据量,以此来尽可能实现物联网节点空间资源的合理利用[19]。完成数据收集后,利用预处理手段处理数据,并统一数据。
1.2 数据预处理
对于日常状态实时采集配电数据的统计计算,假设需要处理第u天收集的数据,首先计算其样本数据均值wu和样本数据标准差εu分别表示为:
wu = ∑nu v=1■ (1)
εu = ∑nu v=1■ (2)
其中datau,v表示为第u天收集的配电物联网中第 个用电数据,ni表示第u天收集的配电物联网中用电数据总量,。以上收集的数据,需要判断其是否满足下述方程:
datau,v - wu ≤ β*εu (3)
公式中β的取值依据具体问题而定。如果数据datau,v 满足公式3,则接受;否则将被剔除。经过上述过程后,在第u天内的数据将被留下n′u(n′u≤nu)个,则n天内所有留下数据的样本均值w和样本标准差ε:
w = ■ (4)
ε = ■ (5)
在收集的以天为单位的所有数据中,筛选出最大值和最小值组成日常区间,用来映射当日的用电设备数据,通过该区间来表示当日用电设备的实际状态,便于统计分析和处理[20]。则第u天的区间计算为:
[au,bu] = [■datau,v,■datau,v] (6)
其中U表示经过预处理后留下的配电物联网中日常数据数量,au,bu表示第u天的区间。通过上述过程获取的区间数据,其内部往往存在部分异常值、容限值以及不合理数据[21-23]。对于异常值的处理,使用Box和whisker测试,计算au与bu的差值,若差值小于1.0,则保留该区间,否则剔除掉区间。经过异常值处理后,如果被保留的区间个数符合w′≤n,则重新计算au,bu和差值的样本均值和标准差[24]。
对于容限值处理,若经过上述处理过程后,保留的w′个数据区间的端点值满足以下方程且差值小于1.0,则区间被保留,否则区间将被剔除。方程如下:
au∈[wa - εu,wa + εi]bu∈[wa - εu,wa + εi] (7)
经过筛选之后,w″≤n个数据区间被保留,再一次计算au,bu和差值的样本均值和标准差。计算完成后进行合理性处理,在合理性处理过程中,当且仅当数据区间满足下述方程时,区间被保留,否则将区间剔除。方程如下:
γ = ■ (8)
公式中wa和wb分别表示au,bu区间的样本均值,εa和εb分别表示au,bu区间的标准偏差,γ表示中间量,满足wa≤γ≤wb条件。经过合理性区间预处理后,对保留的数据区间重新编号,用于后续的配电物联数据驱动业务。
1.3 实现数据驱动业务
将完成异常值处理、容限值处理和合理性处理的区间数据进行均值、右中心值和不确定度的计算,推导数据驱动业务的统计数据[25]。
计算处理后的区间数据的统计量,分别为:
wl = ∑n u=1dlu/nwr = ∑n u=1dru/n (9)
εl = ■εr = ■ (10)
以上公式中wl表示保留的区间数据的所有左端点的样本均值,wr表示保留的区间数据的所有右端点的样本均值,dlu表示保留的u个数据区间的左端点值,dru表示保留的u个数据区间的右端点值,εl表示保留的数据区间的左端点的标准差,εr表示保留的数据区间的右端点的标准差。基于以上参量,则区间数据的不确定度计算为:
y = ■ (11)
其中Δw是根据实际情况推导出的样本均值。通过上述过程计算出区间数据的均值、右中心值以及不确定度和均值,设置右中心值及不确定度对应相等,构建出2个参数方程,以此实现配电物联数据驱动。方程如下:
w = ■[wl + wr ] (12)
ε = (2■(1 - y)(wr - w))/(3y - 2y2) (13)
配电物联数据驱动业务只是负责将采集的繁杂的用电数据整理统一,为边云协同功能做辅助。
1.4 云计算中心与边缘设备的通信设计
在实现配电物联数据驱动业务后,设置一种或多种网络通信结构做基础,能够保证做边缘计算时更快的将数据准确及时的传输至上层,因此使用TCP/IP协议支持,在此协议中有一个常用的API技术Socket,通过该技术使得计算机与其它具有socket接口的设备保持通信。
TCP/IP协议中到的端口号为16位的数字,客户与服务器只有使用约定的端口,才能保证数据传输安全,设置服务器预留端口作为链接的接口,通过它们之间两两建立链路的方式实现网络中点对点的安全通信,这就是socket。将该技术应用于两个程序间的双向通信,可以完成请求的接受和发送,安全传输数据。socket的通信过程如图2所示。
当配电物联网中的服务器启动后,socket技术的调用通过socket()函数来实现,通过该函数建立主机模式,在此基础上,使用bind()函数将本地IP地址和端口号与socket绑定,调用accept函数接收配电用电设备数据。此时,服务器与客户端的连接通过connect()函数建立完成,使用send()和recv()函数达到用电数据接收的目的,最后通过调用close()函数关闭socket()。
对于云计算中心,在配电物联网实际工作时往往需要面对多个边缘设备同时工作的情况,这时为了满足实时通信的需求,建立一个多线程或者多进程的处理程序即可,通过这一手段就可以使每一个边缘设备都能够得到云计算中心的响应,实现云计算中心与边缘设备的通信。
1.5 边云协同功能的实现
在配电网中协同的关键要素旨在深化电网资源管理、促进配电物联网整体的协同发展、提升配电网的智能决策分析能力。在云计算中心与边缘设备的的合作下,将组织部门作为管理的主体,整体采用闭环管理,在配网物资管控模式下,通过组织协同和全寿命周期管理实现配电需求计划管理;在业务流程管理方面,将业务协同和业务标准结合在一起,加强流程之间的衔接连贯性;在物联网技术应用方面,通过信息实时收集和信息共享保证协同功能的实时性和全面性。
在物联网环境下,以协同管理思想为指导,结合电网实际需求,实现配电网的集约化、精益化,实现全面协同。边云协同主要目的是根据配电网的全局优化目标对整个配电网进行统筹、优化,协同的架构以第一子控制模块为全局运行决策服务,实现配电网“全局统筹-分层管理”,利用第一子控制模块,通过其他层次配合采集整个配电网络的各项信息,结合间歇式能源的短期预测,实现配电网全局层面长时间尺度的优化运行計算,以此为基础,配合协同交互控制器和分布式电源控制管理单元实现短时间尺度上的功率平衡跟踪与优化运行。
将负责主动负荷管理的模块作为第二子控制模块,该模块主要负责对单体用户的调节潜力进行评估,分析用电能力,在保证用电需求的同时,生成控制功率值,实现配电的经济性;另外,在控制中第二子控制模块作为柔性负荷的统一管理单元与第一子控制模块进行交互,一方面给第一子控制模块提供负荷调节潜力指标,以供配电网全局运行优化;另一方面响应子模块的控制目标,实现配电网的源-网-荷之间的有机互动。
通过上述内容可知,边云协同功能的实现就是在云计算中心和边缘设备的支持下,从配电网的管理到配电网的运行实现整体的协同,保证配电网高效率的工作质量。
2 仿真测试分析
2.1 配电网测试系统仿真
在配电网物联数据驱动业务以及边云协同功能仿真测试中,采用Multisim 14.0仿真软件作为实验平台,使用IEEE30节点输电网、IEEE33节点配电网和PG&E69节点配电网构成,其中IEEE33配电网网络参数如表1所示。
经过上述过程仿真出用于测试的配电网测试系统,在此基础上,根据配电网实际处理业务情况,设置5种测试中使用的业务,实现数据的交互。具体业务内容如表3所示。
在完成上述内容的设置后,测试提出的数据驱动业务和边云协同功能,同时引入本方法与文献[3]方法、文献[4]方法的数据驱动业务和协同功能,依据测试数据资源分配情况,分析不同方法的数据资源分配均衡性。
2.2 测试结果及分析
采用本方法与文献[3]方法、文献[4]方法的配电物联数据驱动业务及边云协同功能中,对比获取得数据资源分配结果如图3所示。
分析图3可知,使用仿真软件统计的数据资源分配结果中,文献[3]方法的配电物联数据驱动业务及边云协同功能数据资源分配结果中,再分配扁区最差为42,多余数据为1265,再分配事件计数为13,多余数据为2264,根据这些数据可以明显看出,数据资源分配不平衡情况较严重;文献[4]方法的配电物联数据驱动业务及边云协同功能数据资源分配结果中,再分配扁区最差为59,多余数据为1205,再分配事件计数为18,多余数据为2204,根据这些数据可以明显看出,数据资源分配不平衡情况次之;本方法的配电物联数据驱动业务及边云协同功能数据资源分配结果中,再分配扁区最差为7,多余数据为24,再分配事件计数为2,多余数据为104。对比以上两组结果,可以明显看出,数据资源分配不平衡情况较好。由此可知,提出的配电物联数据驱动业务及边云协同功能,在仿真测试中的数据资源分配均衡性高于文献[3]方法和文献[4]方法的数据资源分配均衡性,说明提出的配电物联数据驱动业务及边云协同功能的数据资源分配均衡性较好。因为经过合理性区间预处理后,对保留的数据区间进行重新编号,能够有效提高配电物联数据驱动业务中数据资源分配均衡性。
