一种在仿真工具软件内直接调度计算资源的方法
2020-01-03任静

摘 要:仿真工具软件不具备计算资源的调度能力,在高性能计算系统上进行仿真,必须在设计完成后,先保存模型,然后到调度软件上申请计算资源,仿真与设计过程相对分离,过程重复。通过研究MPI并行计算原理及调度软件调度原理,以常用电磁仿真工具软件FEKO为例,研究其并行计算的模式,在FEKO与高性能计算系统调度软件之间,增加一个中间过程,实现在该软件内对计算资源的直接调度。结果表明,可以做到在仿真工具软件内对计算资源直接调度。
关键词:高性能计算;仿真工具;资源调度;FEKO
中图分类号:TP311.5 文献标识码:A 文章编号:2096-4706(2020)16-0016-04
A Method of Scheduling Computing Resources Directly in Simulation Software
REN Jing
(The 29th Research Institute of China Electronics Technology Group Corporation,Chengdu 610036,China)
Abstract:The simulation software does not have the ability of scheduling computing resources. In the simulation of high-performance computing system,the model must be saved after the design is completed,and then switch to the scheduling software interface to apply for computing resources. The process of simulation and design is relatively separated,and the process is repeated. By studying MPI parallel computing principle and scheduling principle of scheduling software,taking the commonly used electromagnetic simulation software FEKO as an example,its parallel computing mode is studied. An intermediate process is added between FEKO and high performance computing system scheduling software to realize the direct scheduling of high performance computing system resources in the tool software. The results show that the system resources can be directly scheduled in the simulation software.
Keywords:HPC;simulation tools;scheduling resources;FEKO
0 引 言
高性能計算(HPC)是指利用大量处理单元的聚合能力来解决复杂问题。随着集群技术的成熟,高性能计算的成本不断下降,催生了建立在并行计算基础之上的大型仿真设计等应用。在高性能计算系统上进行仿真设计,比在单台计算机上仿真设计,不仅能提升数十、数百倍的精度和规模,还获得数十、数百倍的仿真求解速度。
但是,在高性能计算系统上进行仿真设计存在一个缺点:用户感觉到不如在单台计算机上操作便捷。区别在于:用户在单台计算机上设计仿真时,全部工作在工具软件内完成,即在工具软件内完成设计建模后,直接在软件界面上点击“求解”命令键,即可启动仿真计算;而在高性能计算系统上,需要用户设计好模型后,先保存起来,然后切换到调度软件界面上申请计算资源,才能进行计算。这造成设计与仿真工作的相对分离,过程重复,导致效率降低,与高性能计算系统仿真设计一体化的发展趋势相背离,是高性能计算系统向科研生产一线推广应用过程中,急需优化的问题之一。产生这个问题的根源在于,仿真工具软件本身不是调度软件,不掌握高性能计算系统中计算资源情况,包括服务器名称、CPU核的数量、忙闲状态等。在其软件内发出起计算资源调度,必然造成多用户、多作业计算资源冲突,计算效率低下,甚至系统崩溃。
本文先是研究了通用MPI并行计算原理,及高性能计算系统中调度软件对计算资源调度的原理。然后以常用的电磁仿真工具软件FEKO为对象,找出FEKO软件与并行计算相关的所有进程,研究其资源申请、调度的内部逻辑。紧接着,设计了一种在FEKO软件内直接调度计算资源的方法:在FEKO的并行计算相关脚本程序和调度管理软件之间,增加一个中间过程,实现了在FEKO软件内,对高性能计算系统计算资源进行申请,并将申请传递给调度软件,由调度软件统一调度资源,效果与通过调度软件申请计算资源完全一致。结果表明,在仿真工具软件内直接调度计算资源完全可行,大大优化了高性能计算系统的使用。目前,该研究成果已经在本文作者所在科研院所的高性能计算系统上成功应用。
1 MPI并行计算
并行计算(Parallel Computing)是指同时使用多个计算单元进行计算。即将被求解的问题分解成若干个部分,各部分均由一个独立的处理单元来计算。目的是加快求解问题的速度,提升求解问题的规模。由于程序的各部分之间需要通过来回传递消息的方式通信,要使得消息传递方式可移植,就必须采用标准的消息传递库。
当前,被广泛采用的消息传递标准是消息传递接口(Message Passing Interface,MPI),它是一种基于消息传递的跨语言的并行编程技术,支持点对点通信和广播通信。MPI是一种编程接口标准,它定义了一组接口函数,使应用程序可以将消息从一个MPI进程送到另一个MPI进程。各个厂商或组织遵循这些标准实现自己的MPI软件包(如链接库等形式),程序员仅需设计好并行算法,使用对应的MPI库就能够实现基于消息传递的并行计算。
Open MPI是一种高性能消息传递库,其中有一个常用进程分配参数(--machinefile),在多机环境中,运行程序前先创建一个machinefile文件,其中列出要使用的节点名和每个节点所用核数(本文中称为“机器与核数配比清单”),然后用mpirun命令在指定的节点上运行程序。
2 高性能计算系统调度软件调度原理
高性能计算系统拥有大规模的并行计算资源,是提供并行计算的强大工具。在高性能计算系统中,由调度软件将分散的、通过网络连接的多台计算机的计算资源整合为整体的计算资源池,根据用户申请,遵循一定的策略,进行调度管理。调度软件调度资源时,会将空闲的资源分配给需要的作业;资源不足时,会依照策略进行排队或优先处理,从而不会出现计算资源的抢占、冲突,实现资源共享与效能提升。
调度软件对于计算资源分配的机制,主要是按照MPI并行的进程分配机制执行的。由于MPI进程在CPU核单元上计算效率最高,因此,调度软件对资源的管理和调度是以CPU核为单位的。其逻辑主要为:随时监控系统中CPU核的状态,根据仿真作业对于CPU核数(等于作业进程数,本文中称为“总核数(进程数)”)的需求,从所有空闲CPU核中分配相应数量的CPU核。这些CPU核有可能分散在不同的计算机中,例如,对于24核的需求,可能在机器A中分配了8核,在机器B中分配了16核。于是就产生了配比清单:
机器A:8
机器B:16
调度软件将配比清单与MPI并行程序的进程分配参数(--machinefile)相对应,启动MPI并行程序:在机器A上启动8个执行并行进程,每个并行进程占据1个CPU核;在机器B上启动16个并行进程,每个并行进程占据1个CPU核。于是,对于调度软件来说,总计24个计算资源,就精准的分配给了仿真作业的24个并行进程。
3 FEKO作业的并行计算机制
3.1 FEKO软件启动并行计算的两种方法
FEKO作为电磁领域常用的仿真软件,采用通用的MPI并行计算机制。本文作者研究了FEKO提供的两种常用的啟动并发计算的方法:
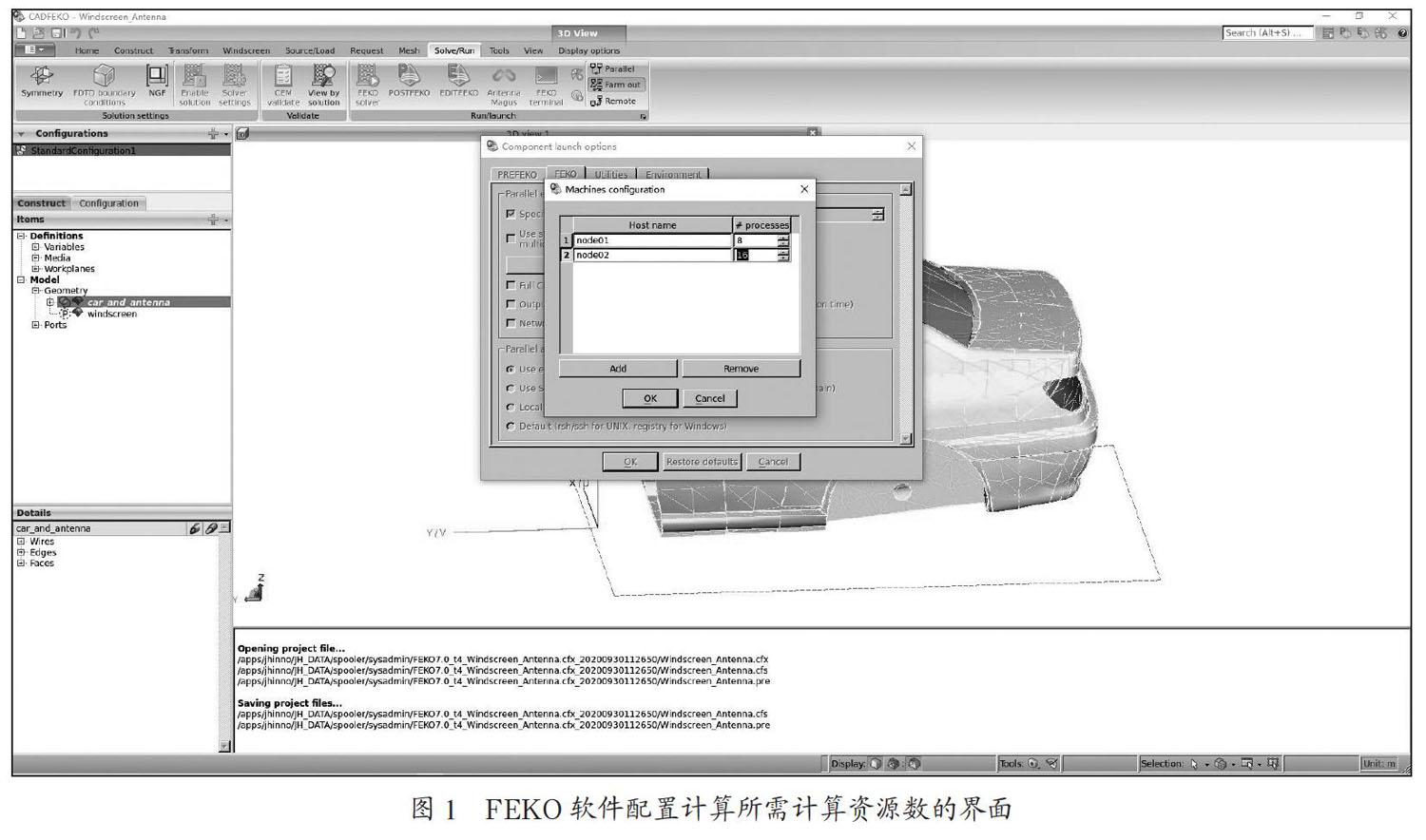
方法一:FEKO软件界面上有一个“Solver/Run”按键,在其弹出界面上,用户可配置所需核数及机器名,如图1所示。
当用户完成配置后,点击“OK”,FEKO软件将触发求解命令,在配置的计算资源上进行求解。
图1的配置界面只能用于用户在单台计算机上仿真的资源申请,此种情况下,用户清楚自己所使用的机器的名称。即便在单台计算机上,这样的资源调度也是不安全的,因为用户可能申请超过该机空闲核数的资源,可能造成计算停顿甚至崩溃。
在多用户共享使用的高性能计算系统中,这样的申请操作则完全不可行:用户不清楚集群中空闲机器的名称、核数,在多作业排队使用资源时,用户更不可能清楚哪些资源可以最快释放出来供计算使用。针对系统显示的空闲机器及核数进行配置,如果多人配置了相同的机器,会造成资源争抢和冲突。由用户配置申请计算资源,而未通过任何统一的资源管理与分配系统,不能避免多用户、多作业的资源争抢与冲突。因此,传统的高性能计算系统不允许用户在FEKO软件内直接向高性能计算系统提交作业、申请计算资源。
方法二:在命令行模式下,FEKO软件提供了并行计算的命令接口(Command Line)runfeko。接口格式:
runfeko算例文件 --machines-file 机器与核数配比清单- np总核数(进程数)
其中“总核数(进程数)”为需求的总的核数(进程数),也是“机器与核数配比清单”中各机器所分配核数的总和。
FEKO利用这个接口,完成在命令行模式下对计算资源的申请,并在所申请的计算资源上启动计算。但是,这也是不考虑计算资源的忙闲状态,与方法一实际上是同一逻辑原理不同形式的方法。因而也是高性能计算系统禁止使用的。
在对使用FEKO提供的仿真计算的两种常用方法的研究中,发现无论是方法一或者方法二,FEKO都只是在对自身作业的并行进程进行划分、触发计算,而不是对计算资源进行安全合理的调度。在多用户共享的高性能计算环境中,唯有调度软件掌握着集群中所有机器的名称、核数,持续收集资源使用情况,避免资源争抢和冲突,实现负载均衡。因此要实现在FEKO软件内向高性能计算系统提交作业、申请计算资源,需要将FEKO软件中申请的计算资源信息传导给调度软件,由调度软件完成调度工作。
3.2 FEKO并行计算内部算法
分析FEKO并行计算的接口,本文作者发现FEKO并行计算遵循Open MPI的接口规范:采用--machines-file和-np参数,同时接口的格式要求也一致。而高性能计算系统调度软件作为支持MPI并行计算的通用软件,也建立两个重要输出:--machinefile 机器与核数配比清单和-np 总核数(进程数),内容与MPI接口的同名参数相对应。
再对FEKO并行计算的真实进程进行进一步的分析。如图2所示,运行Pstree -ua sysadmin命令,可以查看FEKO并行计算有关进程树,其中含有很多进程,例如:runfeko、adaptfeko、feko_parallel、feko_parallel_r、mpirun。研究其中的相互关系,追踪FEKO并行计算中所申请的计算资源参数的传递方式。
分析发现,FEKO在并行计算的时候,会调用一个脚本文件run_feko。run_feko中调用了FEKO的计算接口runfeko,在执行的时候会传递类似于机器与核数配比清单和总核数(进程数)的参数,而这些参数值的来源则来自前文中,用户在FEKO界面中设置的并行机器和核数。然后runfeko将这些参数转化为并行的进程数,在相应的节点上开展并行计算。
4 增加中间过程实现FEKO软件内对计算资源的直接调度
通过上述分析,确定了FEKO并行计算时,利用run_feko执行脚本对用户申请的计算资源进行采集。本文作者以run_feko脚本作为桥梁,创建中间过程,将FEKO软件原始的并行资源创建与传递过程与高性能计算系统的调度过程结合起来,在FEKO并行计算时所需的计算资源置换为调度软件分配的资源,使得FEKO作业的并行计算采用调度软件所分配的资源进行,解决多用户手动指定计算资源造成的计算资源的冲突问题。
具体实现方法为:
将FEKO软件原始的run_feko脚本进行重载,原脚本实现的是获取用户在FEKO软件界面内配置的计算资源,新的脚本实现将获取到的计算资源传递给调度软件,并通过调度软件来分配计算资源。步骤为:
(1)编辑run_feko脚本文件,获得FEKO软件界面内配置的总核数(进程数),并将核数转换为通过调度软件生成的机器与核数配比清单。
np=`awk -F\= '$1=="NumberOfParallelProcesses"{print $2}' feko.ini`
上述语句用以获得单节点并行的核数设置,其中np是总核数(进程数)。
np=`awk -F\: 'BEGIN{a=0}{a+=$2}END{print a}' machines.feko`
上述语句用以获得多节点并行的核数设置,其中np是总核数(进程数)。
(2)执行命令:jsub -q feko_queue -n $np $*,将用户在FEKO软件内配置的总核数(进程数)转换为调度软件分配的核数,并启动计算。其中,jsub是仿真作业提交命令,feko_queue是feko调度队列,$np是从上文中获得的总核数(进程数),$*是FEKO仿真求解算例及参数。
(3)在调度软件中创建一个新的FEKO作业求解脚本run_feko_orig,将调度软件分配的机器与核数配比清单和总核数(进程数)作为参数通过FEKO作业求解脚本回传FEKO的Solver命令中,驱动FEKO利用调度软件分配的资源进行仿真求解:
run_feko_orig $1 --run-from-gui -np $np --machines-file $hostfile
该命令将调度软件分配的资源回传FEKO的Solver命令中,驱动FEKO利用调度软件分配的资源进行仿真求解。其中run_feko_orig是FEKO求解脚本,包含FEKO的Solver命令;$1是FEKO仿真求解算例及参数;$np是调度软件分配的总核数(进程数);$hostfile是调度软件分配的机器与核数配比清单。
通过测试,上述脚本运行后,调用FEKO的Solver命令,利用用户在FEKO软件界面上配置的计算资源数创建Solver进程,但是实际按照调度软件的机器与核数配比清单分配,实现了在FEKO软件内申请计算资源,借调度软件提交作业、申请计算资源,按照调度软件的统一调度策略完成FEKO并行计算的资源分配,并在集群模式下完成仿真计算的目标。
5 结 论
本研究实现了在FEKO软件内直接调度计算资源,启动并行计算,使得高性能计算系统上实现仿真和设计一体化,简化了工作过程。本文作者所使用的方法,是通过对并行计算和调度原理的研究,在调度软件和工具软件之间增加一个中间过程,实现工具软件内的参数向调度软件的传递。由于支持高性能计算的仿真工具软件均遵循MPI标准,调度软件具有通用性,所以对于在其他仿真工具软件内直接调度高性能计算系统上的计算资源的方法的实现,具有普适性。但本文中的原代码及命令是以FEKO为例,并非所有仿真软件都可以直接套用。某特定的工具軟件,还需依照本文的思路,研究其并行进程的命令接口、参数,并做类似重载,以实现文中提到的直接调度功能。
参考文献:
[1] SPI.mpirun(1)man page (version 4.0.5) [EB/OL].[2020-05-30].https://www.open-mpi.org/doc/v4.0/man1/mpirun.1.php.
[2] 卧龙小三.实战Linux Shell编程与服务器管理 [M].北京:电子工业出版社,2010.
[3] tomctx.并行计算与MPI [EB/OL].(2019-06-01).https: //blog.csdn.net/tomjchan/article/details/90730497.
作者简介:任静(1974.05—),女,汉族,四川夹江人,工程师,工程硕士,研究方向:高性能计算及人工智能。
