基于Python的爬虫技术的网站设计与实现
2020-01-03肖新凤张绛丽邓祖民
肖新凤 张绛丽 邓祖民


摘 要:随着爬虫技术的不断完善,其功能越来越强大,也导致数据窃取问题越来越严重。很多网站都采用了反爬虫技术,因此为了正常获取数据,需要一些反爬虫策略。文章设计和实现面向定向网站的网络爬虫程序,使其能满足不同的性能要求,并阐述了定向网站爬虫的细节和应用环节。爬虫可以针对不同的主题网站分析构造URL并去重,多线程技术让爬虫具备更强大的抓取能力。
关键词:Python;爬虫;数据;豆瓣读书网
Abstract:With the continuous improvement of crawler technology,more and more powerful functions,and more and more serious data theft problems,many websites have adopted anti-crawler technology,so in order to obtain data normally,some anti-crawler technology is needed. This paper designs and implements a web crawler program oriented to the directional website,and meets different performance requirements,including the details and applications of the directional website crawler Link. For different theme websites,analyze and construct URL to remove duplication. The multi-threading technology which makes the crawler have more powerful grasping ability.
Keywords:Python;crawler;data;Douban reading website
0 引 言
網络爬虫一般用于搜索引擎,其中很大的推动力是来自各种个人、中小型爬虫。一些低质量的爬虫主要表现为不遵守Robots协议、爬行策略未优化、分布式的架构。随着大数据应用越来越广泛,很多人想研究大数据但需要充足的数据,因此“互联网+”也变得更有价值。所以,随着大数据应用的发展,爬虫的使用是不可避免的,并且使用范围会越来越广泛。近年来,许多创业公司因其发展需要大量的数据。笔者以某个服务类的公司为例,该公司需要电子商城(如:eBay)的卖家联系方式,这时就需要利用爬虫技术。目前爬虫技术效率较高的就是基于Python的爬虫技术,它不仅爬取速度快,而且Python语言的简洁性大大地提高了完成爬取程序的时间,使其可以随着不同的主题网站分析构造URL并去重。并且网络爬虫采用多线程技术,将具备更强大的抓取能力。
1 爬虫的基本流程及相关技术
爬虫在互联网网站上按一定规则去获取所需要的信息。互联网可以比作一张网,每个Web节点都是存储数据的地方。爬虫程序是向网站发送请求、获取资源、分析和提取有用数据的程序。爬虫爬取数据的基本流程如图1所示。
Python程序类似于蜘蛛,在每个节点上捕捉猎物。通用爬虫暨通用的网络爬虫也可以称为可伸缩的网络爬虫,有两种常见的爬取策略:深度优先策略及广度优先策略。而聚焦爬虫也被称为主题网络爬虫,主要为特定的人群提供服务,可以节省大量的服务器资源和带宽资源;增量爬虫则是指以增量方式更新已下载网页并仅对新生成或更改的网页进行爬取的爬虫程序,可以在一定程度上保证被爬取的页面是尽可能新的。与周期性的抓取和刷新相比,增量爬虫只在需要时对新生成或更改的页面进行抓取,不再下载未更改的页面,可以有效减少数据下载量,及时更新抓取的页面,减少时间和空间消耗,但也增加了爬行算法的复杂度和实现难度。增量爬虫的体系结构包括爬行模块、排序模块、更新模块、本地页面集、要爬行的URL集和本地页面URL集。本文采用的增量网页爬虫进行发送请求、获取响应内容、解析内容及保存数据。
2 项目分析、设计、测试与实现
2.1 项目分析
2.1.1 项目描述
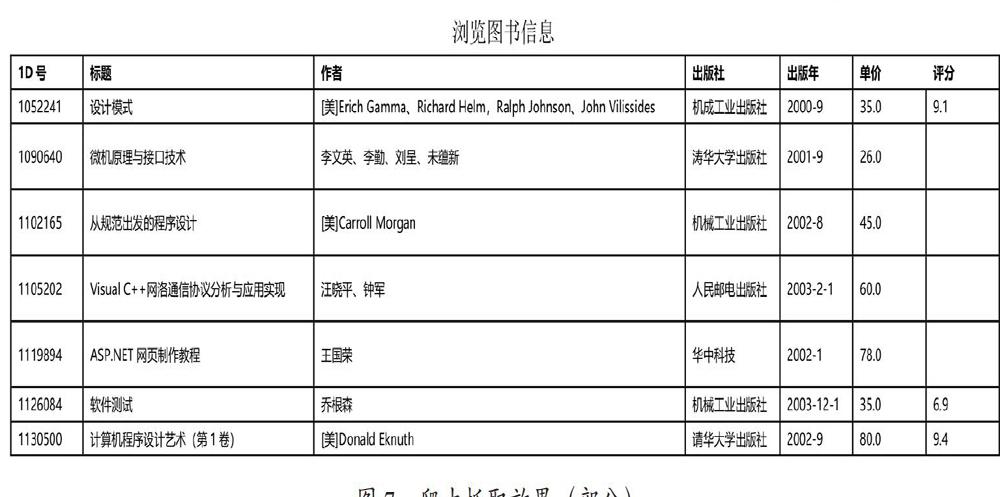
项目为编写一个网站爬虫程序,将豆瓣读书网站上的所有图书信息爬取下来,并保存到MySQL数据库中。爬取的信息字段要求有:ID号、书名、作者、出版社、原作名、译者、出版年、页数、定价、装帧、丛书、ISBN、评分、评论人数,部分信息如图2所示。
2.1.2 爬取网站过程分析
打开豆瓣读书首页https://book.douban.com/,如图3所示;在豆瓣读书首页的右侧点击所有热门标签,会跳到豆瓣图书标签页https://book.douban.com/tag/?view=type&icn= index-sorttags-all。如图4所示,点击豆瓣图书标签页分类中的标签,会展示对应图书列表页,在图书列表页中可以获取每本图书的详细信息,如图5所示。
2.2 项目设计
项目主要分为四大模块。模块一实现对豆瓣图书信息以及所有标签信息的爬取,并将图书的标签信息写入到Redis数据库中,此模块可使用Requests简单实现。模块二负责从Redis中获取每个图书标签,分页式地爬取每本图书的URL信息后,将信息写入到Redis中。模块三负责从Redis中获取每个图书的URL地址,并爬取对应的图书详情,将每本图书详情信息写回到Redis数据库中。模块四负责从Redis中获取每本图书的详情信息,并将信息依次写入到MySQL数据中,作为最终的爬取信息。该项目结构图如图6所示。
2.3 项目部分实现
2.3.1 定义model类
2.3.3 编写视图文件部分代码
2.4 项目测试
启动服务测试,$ python manage.py runserver使用浏览器访问测试,抓取部分信息的效果图如图7所示。本系统的设计和实现面向定向网站的网络爬虫程序,经过测试,能满足不同的性能要求,且抓取效果良好。
3 结 论
文章对互联网网站的信息进行爬取并展示,并对一些网站的反爬技术使用对应的反反爬策略,不仅不增加网站服务器的压力,还提高了爬取的效率和稳定性;并且遵守了网站的Robots协议。在大数据时代,爬虫行业必将风生水起,Python网络爬虫更是独领风骚。基于Python的Web爬虫数据抽取是一种主流技术,Python语言具有跨平台、开发速度快、语言简单等特点。Python语言可以通过第三方请求库获取返回值的内容,然后通过正则、XPath和Beautiful Soup三种Python過滤技术快速匹配和提取网页中的图像和文本数据,这样不仅能精确地找到网页中需要的数据,还能自动化快速地将这些数据保存下来,极大地减少了查找数据的时间。基于Python的网络爬虫不仅爬取速度快,其语言的简洁性也大大地缩短了完成爬取的时间。
参考文献:
[1] 李琳.基于Python的网络爬虫系统的设计与实现 [J].信息通信,2017(9):26-27.
[2] 张誉曜,陈媛媛.基于Python下的爬虫综述及应用 [J].中国新通信,2019,21(6):98.
[3] 王碧瑶.基于Python的网络爬虫技术研究 [J].数字技术与应用,2017(5):76.
[4] 陆树芬.基于Python对网络爬虫系统的设计与实现 [J].电脑编程技巧与维护,2019(2):26-27+51.
[5] 唐琳,董依萌,何天宇.基于Python的网络爬虫技术的关键性问题探索 [J].电子世界,2018(14):32-33.
作者简介:肖新凤(1978—),女,汉族,湖南邵阳人,讲师,研究生,研究方向:软件技术、大数据、数据挖掘。
