基于分布式的玻璃缺陷检测技术研究及性能优化
2020-01-03
(中北大学 信息与通信工程学院,太原 030051)
0 引言
随着数字图像检测技术在生产领域的广泛应用,很多应用需要及时地分析当前的生产状况,传统的数字图像检测系统难以满足工业生产的需求。以玻璃生产加工业为例,在原料加工、制备、熔化、澄清和冷却等各种生产环节中,由于工艺制度的破坏或操作过程的差错,从退火窑出来的玻璃带往往带有不同类型和大小的缺陷。缺陷检测系统需要及时的控制横切机将包含缺陷过多、不符合国家标准规定的部分切除,从而达到提高整条玻璃生产线玻璃质量的效果。由于玻璃带传输速度的加快,缺陷检测系统短时间会采集大量高分辨率缺陷图像数据,要实现生产线上玻璃带缺陷的及时检测,需要采用与生产速度匹配的,及时不间断的在线检测系统[1]。
MapReduce应用于大规模计算机集群处理海量数据的并行计算中,是一种基于键/值对的数据处理模型[2]。该模型将复杂的分布式计算过程分为Map与Reduce两个阶段。总任务提前被分割成若干个小任务,每个划分的小任务由一个Map任务来计算,Map任务计算完成之后将中间结果传递给Reduce任务,进行全局的结果汇总并计算出最终的结果。
MapReduce的出现在一定程度上缓解了大数据处理的难题。MapReduce由于最初只定义了基于文本的数据类型,在默认设置中无法支持图像数据类型的处理。要实现对大量图像文件的分布式并行化处理,需要实现图像数据到MapReduce分布式计算框架所默认的数据类型转换。目前许多学者针对基于MapReduce实现图像并行化处理做了深入研究。文献[3]利用MapReduce所提供的读写接口来设计所需要的图像数据类型,由此来实现将图像序列化为MapReduce可进行处理的数据类型,达到图像并行化处理的效果。但这种方法存在的缺陷是当面临大量小文件存储的问题,会导致Map任务数量过多,造成系统处理效率低的问题。文献[4]提出了一种新型的图像数据并行处理模型。利用MapReduce模型适合处理大规模文本数据的特性,选择将存储了图像路径的文本文件代替图像数据进行输入,从而避免了设计图像数据类型的麻烦,但同样会面临大量小文件存储导致的存储效率低下的问题。
其次,随着数据处理需求的提高,也暴露出MapReduce这种分布式计算框架一些缺陷。MapReduce有其性能瓶颈:在Map和Reduce之间,隐形设有中间处理部分,比如为了让不同结果分发到对应的处理节点上,需要把所有结果汇总到每个节点上再进行排序,每个节点截取对应区间内的数据[5]。该过程是MapReduce之所以能够正确运算的关键所在,但是其影响了系统处理的速度。
为解決此问题,文献[6]提出本地增强负载均衡算法将MapReduce的流程扩展到,减少与shuffle重叠的计算并充分利用CPU和I/O资源,但开发难度较大且不易于扩展。文献[7]中提出了一种本地感知的reduce任务调度策略,考虑分区的位置和大小,采用默认的hash partitioner使reduce任务尽量本地化,以减少shuffle数据量,提高 MapReduce 的性能,但对大规模数据集性能提升不大。文献[8]提出基于数据本地化和负载均衡的任务分配策略,既减少了Shuffle阶段数据的传输量,同时也避免出现任务分配不均衡的情况。文献[9]中针对shuffle处理策略的不足,采取管道策略,将map生成的数据通过管道直接传输到Reduce,降低了I/O代价,提高了效率,但缺少shuffle会导致计算准确率严重下降,不适用于大规模图像处理。
基于上述背景,本课题以MapReduce并行计算框架为研究基础,针对大量小文件的存储问题进行了存储结构的改进,通过添加流式数据处理模块和数据划分模块,使得计算与存储本地化,加快数据处理的实时性。并以在线所采集的大量玻璃图像为测试对象,通过改进MapReduce计算框架实现对各种玻璃缺陷及时准确的检测。
1 系统检测方案
对玻璃带进行缺陷的在线检测,文献[10]提出一种基于数字光栅投影的浮法玻璃缺陷检测方案,此方法利用位于玻璃带上方的高速CCD相机采集玻璃带表面呈现的图像,再由检测系统的对采集到的缺陷图像进行缺陷检测。由于单位时间内线阵CCD相机获得数据量十分巨大,目前无法采用单一的硬件和软件系统实现,由此本文设计了基于Hadoop集群的多路并行处理的玻璃带缺陷检测方案,如图1所示。

图1 玻璃缺陷在线检测总体方案
该系统由光源、编码器、高速线阵CCD相机、图像处理器和Hadoop集群处理器组成。具体检测方法是由多路独立的图像采集单元和由Hadoop集群构成的图像处理单元组成,采用正透视的背光照射方式的检测光路[11],通过多路高速线阵CCD相机并行采集玻璃表面的光强信号,整个CCD线阵都与Hadoop集群相连接。高速数据采集卡通过双DMA模式连续采集光强度信号,将其转换为灰度图像数据并传输到上位机。任务由客户端提交给资源管理器,CCD摄像机收集的数据传输到Hadoop集群的Master。Master将每路CCD相机数据分配给对应的Slave。然后,运行分配任务的Slave完成分割算法。最后,处理结果返回给Master。一旦缺陷过多,由系统控制的横切机将切除具有缺陷的部分。
2 缺陷图像的分布式处理
2.1 图像存储结构的设计
在缺陷图像处理之前,首先要解决图像数据的存储问题。本文默认的数据块大小为128M,玻璃缺陷图像数据大小远小于默认的数据块大小,直接存储会在NameNode中存储大量文件名称信息,从而严重降低集群的运算性能。同时访问大量小图像回频繁调用I/O接口,也会增加文件寻址时间。因此本文针对图像分片利用HIPI接口的HipiImageBundle类,将本地图片通过文件遍历方法上传,图像分片组成一个包含数据和索引的hib文件存储结构,生成glass.hib和glass.hib.dat。hib文件存储位移及索引信息,hib.dat文件存储图像数据。通过对HIPI接口的调用,减少了大量图像分片对Hadoop性能的影响。
其次,由于MapReduce运算模型的性质,在图像处理过程中会将图像数据随机分块。如果不对图像数据进行预处理,而是由Map任务直接分块处理,在最后的聚合阶段无法将分块后的图像数据进行准确的聚合,从而无法还原到处理之前完整的原始图像。因此,在Map任务进行分块前,本文对玻璃缺陷图像进行预处理,提前将图像处理前的分块顺序和图像分块相对于原始图像的位置坐标存储在数据块的元信息中。在Map任务完成之后,可以将分块后的图像数据与提前存储的元信息进行比对,依照原信息中存储的数据块坐标位置即可快速完成分块图像的准确聚合。本文所采取的图像存储结构如图2所示。
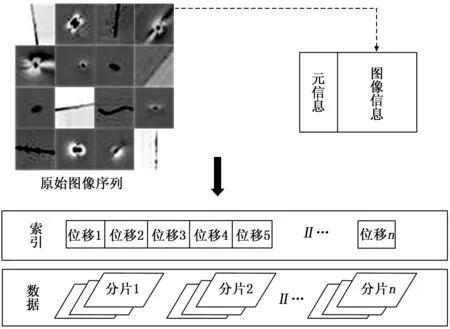
图2 图像存储结构的设计
2.2 MapReduce功能的设计
MapReduce缺陷检测实现过程可分为如下3个阶段:首先,图像序列中每个图像被分割成多个小的图像分片,并将图像分片分配到Hadoop的数据节点上。接着,数据节点上的每个Map过程独自完成图像分片的缺陷分割任务。最后,在Reduce过程中将检测后的图像分片聚合,获得最终检测结果。MapReduce的工作流程如图3所示。

图3 MapReduce图像处理流程
在Map阶段,通过ImageInputFormat接口读入图像分片,ImageRecordReader函数负责输入以及对记录进行读取操作,得到分割记录和产生输入分片[12]。MapReduce程序将输入的
在Reduce阶段,针对key中保存的元数据信息和value中的检测结果,按照元数据中存储的索引号和像素坐标等信息,将检测结果归并,并将检测结果保存到HDFS中的不同文件夹中。在对图片调用执行完毕,再启动reduce程序把执行处理后图像进行合并操作。
3 缺陷检测算法优化
Map阶段数据节点产生的中间数据需要经过网络传输到Reduce阶段的计算节点作为其输入数据,这个中间阶段称为Shuffle[13]。Shuffle阶段的数据传输和Reduce阶段数据存储非常耗时,所以如何减少Map阶段不必要的网络带宽占用,成为提升MapReduce作业执行效率的关键。而Map阶段性能与数据本地化相关,所以提升数据本地化可以有效提升MapReduce作业的执行效率。
Hadoop[14]数据本地化是指数据集无冗余地划分至每个节点,通过划分数据集来并行化数据的处理。如图4所示,在任务调度过程中,如果不考虑数据本地化,就会使得本可以直接从本地读取输入数据的任务需要跨机架通过网络访问来远程读取数据,增加了任务的执行时间。在改进的MapReduce计算模型中,数据本地化使系统能够感知机架。通过数据定位,数据分配可以提高系统的并行度,从而提高系统的处理效率。在本文中,数据块分区被提前到Map阶段,当map完成后,所有数据都被发送到相应的Reduce节点,然后进入Shuffle阶段,这个过程在简化繁琐的中间排序过程的同时也能很好保证运算的准确性,提高了传统MapReduce框架的效率。

图4 MapReduce本地化机制
4 实验
本实验是在局域网内,实验搭建Hadoop集群由一个主节点和4个从节点组成。 Hadoop集群安装在虚拟机上,软件配置和硬件设置如表1,表2所示。实验选取在线采集玻璃缺陷图像作为实验对象,缺陷图像的平均大小约212KB。由于实验在分布式集群上进行,实验中数据块的副本数设置为3,同时集群中默认的数据块大小为128M,MapReduce中Reduce的数目设置为1,实验环境的软件和硬件配置如表1和表2所示。

表1 实验环境软件配置

表2 实验环境硬件配置
在实验环境搭建完成之后,对在线所采集的玻璃缺陷图像进行基于MapReduce的分布式缺陷检测实验,结果如图5所示。图5(a)是一幅含有疥瘤的玻璃缺陷图像,图5(b)是在MapReduce上进行分块缺陷检测的中间结果,图5(c)是将中间结果聚合后,得到的最终检测结果。
将原玻璃缺陷图像和检测后的结果进行对比,如图6所示,分别展现出了划痕、夹杂、污点和疥瘤的阈值分割结果。通过多次的测试可以看出,本文所采取的图像分割算法可以有效完成不同种类玻璃缺陷图像的分割。

图5 MapReduce疥瘤缺陷检测结果

图6 MapReduce图像分割结果
为了验证本文改进的MapReduce框架处理效率和运算性能的提升,将改进的MapReduce框架与原来的运算框架分别运行在三节点和四节点的Hadoop集群,测试所采取的图像数据量分别在200 M、400 M、600 M、800 M和1 000 M的条件下检测两种框架运算的效率。通过图7和图8发现,不同节点Hadoop集群下,随着图像数据量的不断提高,处理时间显著加快,基本呈线性增长。对比三节点和四节点集群的处理时间,图9和图10分别展现出了不同节点下运算性能改进的加速比,从图9和图10的加速比变化可以看出,伴随着节点数的增多,MapReduce的运行效率会有所提高,加速比大约从1.1提高到1.24。集群节点数越多,加速比会适当提高,这体现出改进的算法在多节点集群上加速效果更明显,也可以说明本文改进的算法在数据调度和本地化数据方面改进显著。总之,改进的MapReduce架构改善了数据运算性能,因此本文所做的改进相对于传统的MapReduc框架在性能上有所提高,可以很好的应用于玻璃缺陷图像检测系统中。

图7 三节点Hadoop集群处理结果
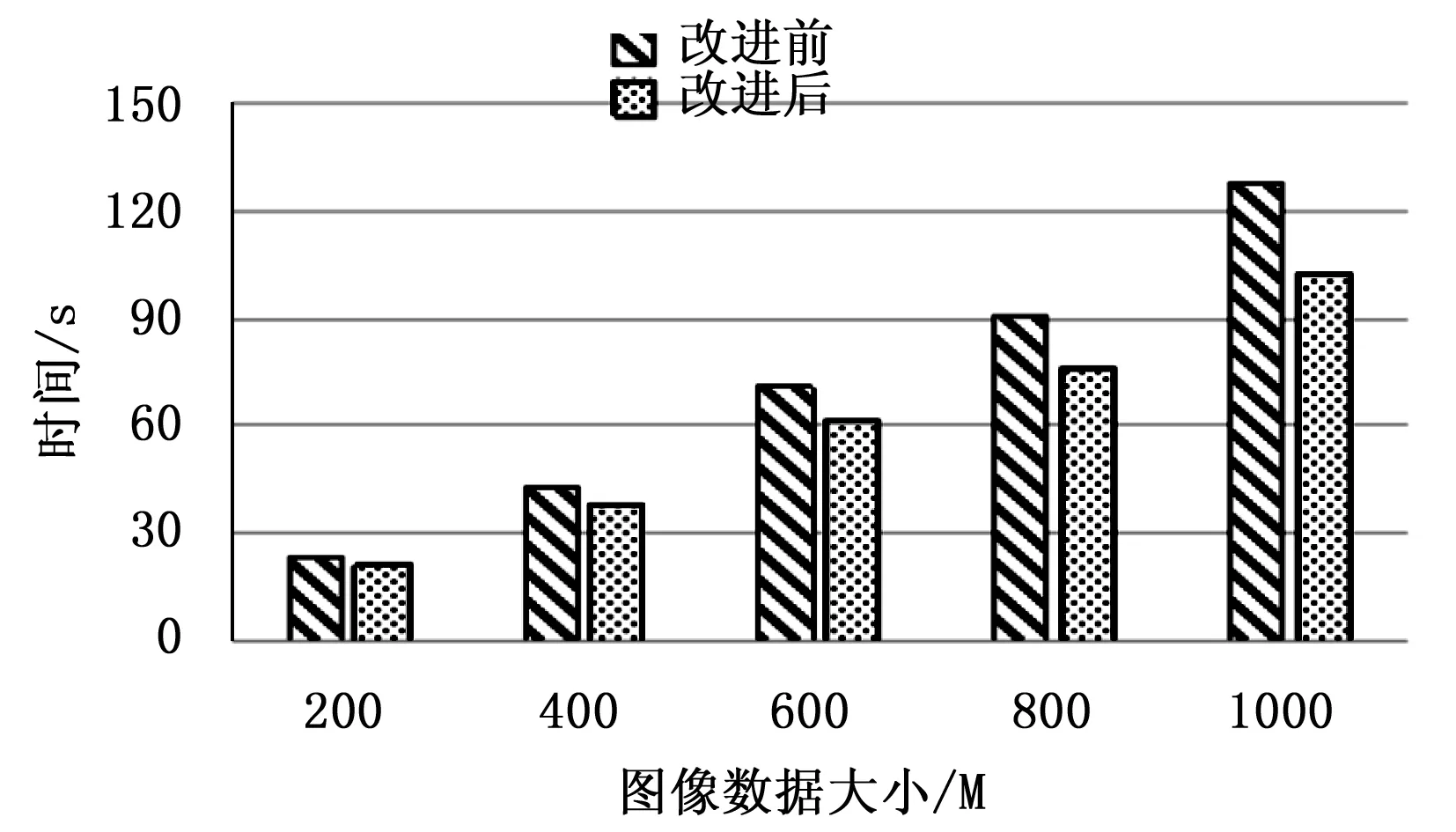
图8 四节点Hadoop集群处理结果
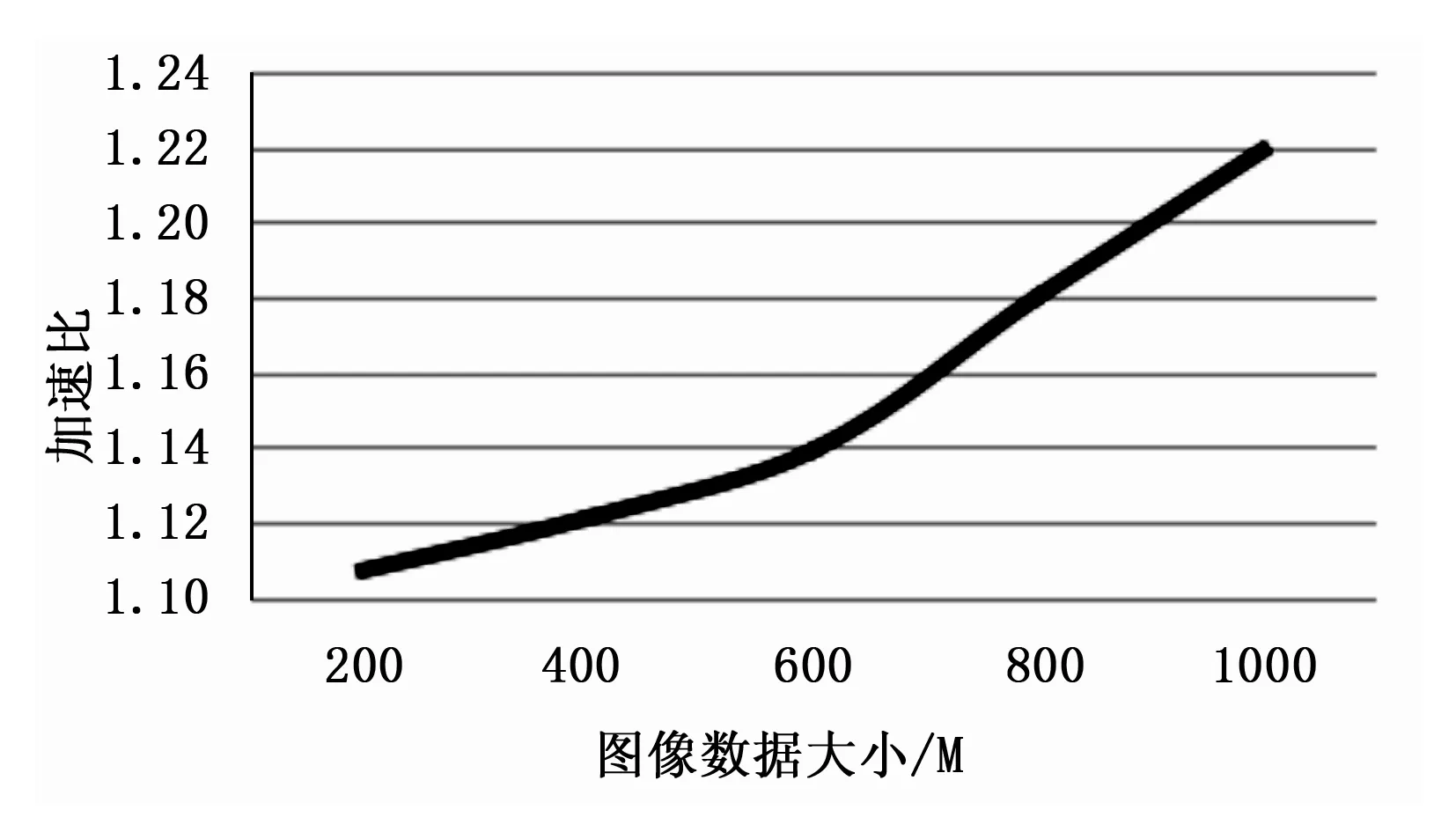
图9 三节点Hadoop集群加速比

图10 四节点Hadoop集群加速比
5 结论
本文针对目前玻璃检测系统无法满足及时性的问题,将MapReduce分布式计算框架应用于海量玻璃缺陷图像检测中。通过对存储结构的改进,解决大量小文件存储导致效率低下的问题,完成基于MapReduce的并行化玻璃缺陷图像阈值分割算法。此外,在原有的MapReduce计算框架基础上,对中间处理过程Shuffle做了进一步改进,通过数据本地化改善运算性能。实验表明,改进的MapReduce并行计算框架数据处理速度得到显著提高,保证了系统的准确性和及时性,为玻璃缺陷检测后续的打标和切割工序提供了有效信息。
