一种基于MobileNet的火灾烟雾检测方法
2020-01-03徐梓涵张苏沛肖澳文
徐梓涵 ,刘 军*,张苏沛 ,肖澳文 ,杜 壮
1.智能机器人湖北省重点实验室(武汉工程大学),湖北 武汉 430205;
2.武汉工程大学计算机科学与工程学院,湖北 武汉 430205
火灾是现代社会具有毁灭性的重大灾害之一。随着我国社会的快速发展,火灾的发生往往伴随着生命财产的重大损失。2018年,全国火灾情况造成超过2 000人受伤或死亡,直接损失超过30亿元。因此,在火势形成之前进行及时准确的检测具有重要意义。
在早期的火灾监控的技术中,基于传感器实现的火灾烟雾检测装置一般分为感光、感烟和感温三种类型。目前已经有采用多传感器融合识别火灾的方法取得了较好的效果[1]。近年来,图像模式识别技术的发展为解决实际问题提供了理论依据[2]。利用深度学习技术,可以直接接受原始图像输入,通过模拟人类神经细胞建立的卷积神经网络自动提取图像特征。目前深度学习技术在人脸识别[3]、字符识别[4]、图像分类[5]等领域都取得了较好效果,甚至超过了人类识别水平。本文的思路是结合深度学习技术,利用图像识别进行火灾识别,同时利用社会中广泛存在的视频监控设备进行数据采集,可以在火灾形成初期进行识别,从而实现快速、大范围的火灾检测,此外,该方法安装和使用成本适中,有利于进行推广。
随着深度学习的发展,基于计算机视觉并配合智能算法对场景内容进行识别和分析受到了国内外研究者的广泛关注。但相较于其他物体的识别,火灾烟雾检测的难点在于二者在形态上均具有不确定性,其中烟雾还具有透明度,易与图像的背景部分混合。有学者提出依靠对图像中火焰和烟雾的明度、颜色和运动情况等特征进行分析和提取来进行识别的方法[6]。利用稀疏光流算法跟踪运动区域,通过计算平均偏移量以及相位分布对烟雾进行判断,进而检测是否有火灾发生。刘颖等[7]提出基于潜在语义分析(latent semantic analysis,LSA)和支持向量机(support vector machine,SVM)的算法利用帧内特征检测烟雾。近年来,深度学习开始逐渐运用于各个领域。区别于传统框架,深度学习方法基于大量数据提取目标特征,可以进行更准确的判断。如Mao等[8]提出利用多通道卷积神经网络对火焰进行识别。陈俊周等[9]提出利用原始图像作为静态纹理,原始图像的光流序列作为动态纹理,融合两种纹理信息构建级联的卷积神经网络。Yin等[10]提出更深层级的14层卷积神经网络,通过将传统卷积神经网络中的卷积层替换为批规范化卷积层,加速训练过程并避免过拟合等问题。Muhammad等[11]提出类似于GoogleNet的网络结构,利用迁移学习的方法,在提高检测准确率的同时降低了卷积复杂度。
由于实际使用中的嵌入式设备通常无法满足大型卷积神经网络的计算和存储的需求,本文在深度卷积神经网络的基础上,引入更适合嵌入式设备的MobileNetV1网络,并配合运动检测方法,提出一种针对视频的火灾与烟雾检测方法。。
1 检测方法
1.1 检测区域的提取
利用了监控摄像机在空间位置、拍摄角度上的稳定性,以降低额外的计算开销,充分利用设备性能。首先读取视频中单帧图像作为原始图像,如图1(a)所示,将整幅画面以一定大小划分为若干个矩形区域,然后对整幅画面使用K-近邻(K-nearest neighbor,K-NN)背景减除器进行背景减除,提取出前景部分[12]的范围作为动态区域图像,如图1(b)所示。K-NN背景减除器是一种基于K-NN算法进行背景减除的算法[13],其接收若干帧连续的视频图像后,利用K-NN算法预测当前视频帧中的某一像素在当前视频帧中是否属于前景部分。其中判断当前视频帧中某像素是否为背景的计算方法见文献[14]。
在获得经过背景减除的动态区域图像后,需要对其进行阈值处理,将亮度值小于255的像素均归为0,处理后的图像如图1(c)所示。为了消除噪点,减少不必要的计算,本文对动态区域图像进行了腐蚀与膨胀等形态学操作。腐蚀可以描述为:将图像A与核B做卷积,核B有一个锚点,将锚点所指的像素值替换为该核内所指元素的最小值。腐蚀处理后图像如图1(d)所示。在图像A中点(x,y)的像素上,腐蚀后的像素值可以表达为:
利用相似的原理,膨胀可以描述为:将图像A与核C做卷积,核C有一个锚点,将锚点所值的像素值替换为该核内所指元素的最大值。膨胀处理后图像如图1(e)所示。在图像R中点( )x,y的像素上,膨胀后的像素值可以表达为:
经过上述形态学操作后移除了一定噪点,平滑了前景的轮廓,得到了经过处理后的动态区域图像D。为了得到具体的检测区域,本文使用了积分图实现对区域内前景像素的快速统计[15]。积分图E中任意一点(x,y)的值是动态区域图像D中位于(x,y)左上方的所有像素的灰度值之和,即。借助积分图的性质,可以快速得到区域G={(x,y)|x0≤x≤x1,y0≤y≤y1}中前景像素的灰度值之和E(G) ,其中灰度值之和大于0的区域将被标记为需要检测的区域。部分运行示例图如图1所示。
1.2 对检测区域的分类
随着卷积神经网络的飞速发展,已经有实验[16]表明卷积神经网络在图像识别、分类方面具有较好的能力。VGGNet(visual geometry group net-work)和ResNet的出现表明了具有一定深度的卷积神经网络结构能够很好地对图像进行拟合、分类。
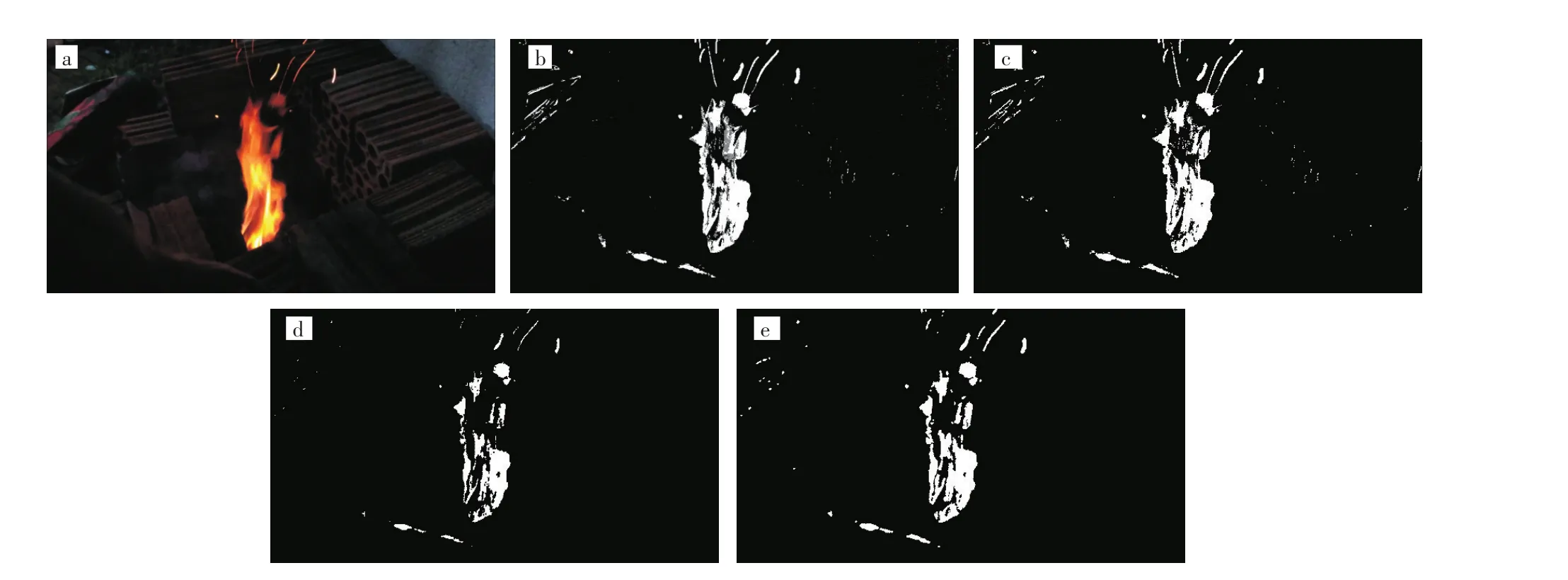
图 1 提取图像:(a)原始,(b)动态区域,(c)阈值处理后,(d)腐蚀处理后,(e)膨胀处理Fig.1 Foreground extraction:(a)original image,(b)motion area image,(c)image after thresholding,(d)image after erosion,(e)image after dilation
常见的深度神经网络参数量如表1所示,由于这些网络结构相对庞大,需要运算的参数数量较多,导致此类动辄需要高性能图形卡计算的卷积神经网络的加载和前向计算需要更多的时间以及更多的内存空间。而诸如监控摄像头这一类嵌入式设备计算能力与存储空间有限,通常无法满足这些网络运行的需要。为解决这一问题,引入了MobileNet V1卷积神经网络。

表1 常见深度神经网络参数量Tab.1 Number of parameters of common deep neural network
2017年Google提出轻量卷积神经网络MobileNet V1。其核心方法是利用depthwise separate convolution将传统的卷积拆分为depthwise convolution与pointwise convolution两种卷积方式的组合,其运算原理如图2所示。在depthwise convolution中,3个卷积核分别对3个通道进行卷积,分别得到3个通道的特征。pointwise convolution为对输入矩阵进行1×1的卷积。实验表明,拆分后depthwise convolution和pointwise convolution的效果接近传统卷积[17]。同时,相比于传统的卷积方式,depthwise convolution与pointwise convolution两种卷积方式组合的参数量与计算量大大减少。理论上,在进行k个h×w卷积核的卷积时,depthwise separate convolution与传统卷积的运算量之比为。这使得MobileNet V1比其他传统卷积神经网络更适合在计算能力有限的设备上使用。本文所使用的MobileNet V1卷积神经网络结构如表2所示。
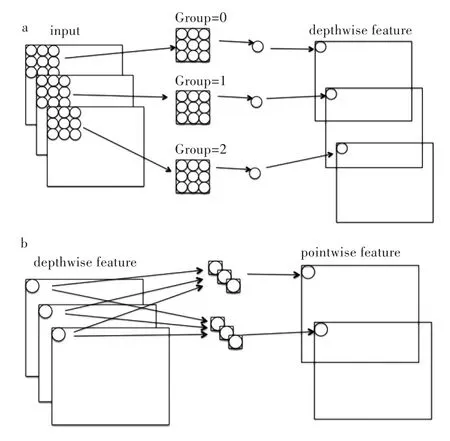
图2 深度可分离卷积:(a)深度卷积,(b)点卷积Fig.2 Depthwise separable convolutions:(a)depthwise convolution,(b)pointwise convolution

表2 MobileNet V1网络结构Tab.2 Architecture of MobileNet V1
2 火灾烟雾场景目标检测实验
2.1 实验数据
在卷积神经网络的训练过程中,由于烟雾火灾识别领域没有公开的数据集,本实验数据来自ImageNet等网络图片平台,包含1 864张火灾图片、1 625张烟雾图片、1 818张正常景象图片。在每个类别中分别选出25%的图片作为测试集,其余为训练集,并保证训练集与测试集的图片均不重复。训练集与测试集中图片样例如图3所示。

图3 数据集部分样例Fig.3 Samples of dataset
2.2 算法实现
算法使用跨平台编程语言Python编写,共有检测模型训练、视频读取、区域选择、检测分类四个部分。运用Tensorflow深度学习框架构建和训练网络模型,并提供运行支持。Tensorflow是开源的跨平台深度学习库,其中提供了常用的机器学习算法,可以方便地构建卷积神经网络并高效地利用GPU对训练和运行过程进行加速。在处理视频的输入和输出方面,实验采用跨平台的计算机视觉库OpenCV对视频输入输出、图像处理、结果预览提供支持。在检测模型的迭代训练阶段,主要利用GPU对训练过程加速。在部署阶段则使用CPU进行前向计算。
在对卷积神经网络进行训练前,需要对数据集进行正则化处理。首先将所有的图片统一调整到224×224以便于作为矩阵输入到卷积神经网络。另外,为了使卷积神经网络更易收敛,应对数据集中的图像进行去均值和标准化处理。去均值处理中,对于每一个图像通道中的像素,在其红、绿、蓝3个分量上应分别减去对应的通道均值。一个通道的通道均值是通过计算训练集中每张图像的所有像素在该通道的平均值并取平均得到的常量。标准化处理中,对于图像A中每一通道中的每个像素将被缩放为一个0到1之间的浮点数,即
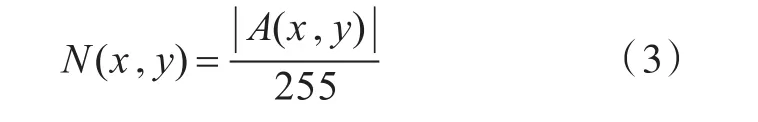
迭代训练过程中,所有数据集中的图像在经过上述正则化处理后将被读取为224×224×3的矩阵并依次输入到卷积神经网络中,再根据卷积神经网络的输出更新卷积神经网络的参数。在进行20 000次迭代训练后,得到的测试集准确度如图4(a)所示,损失函数值如图4(b)所示。
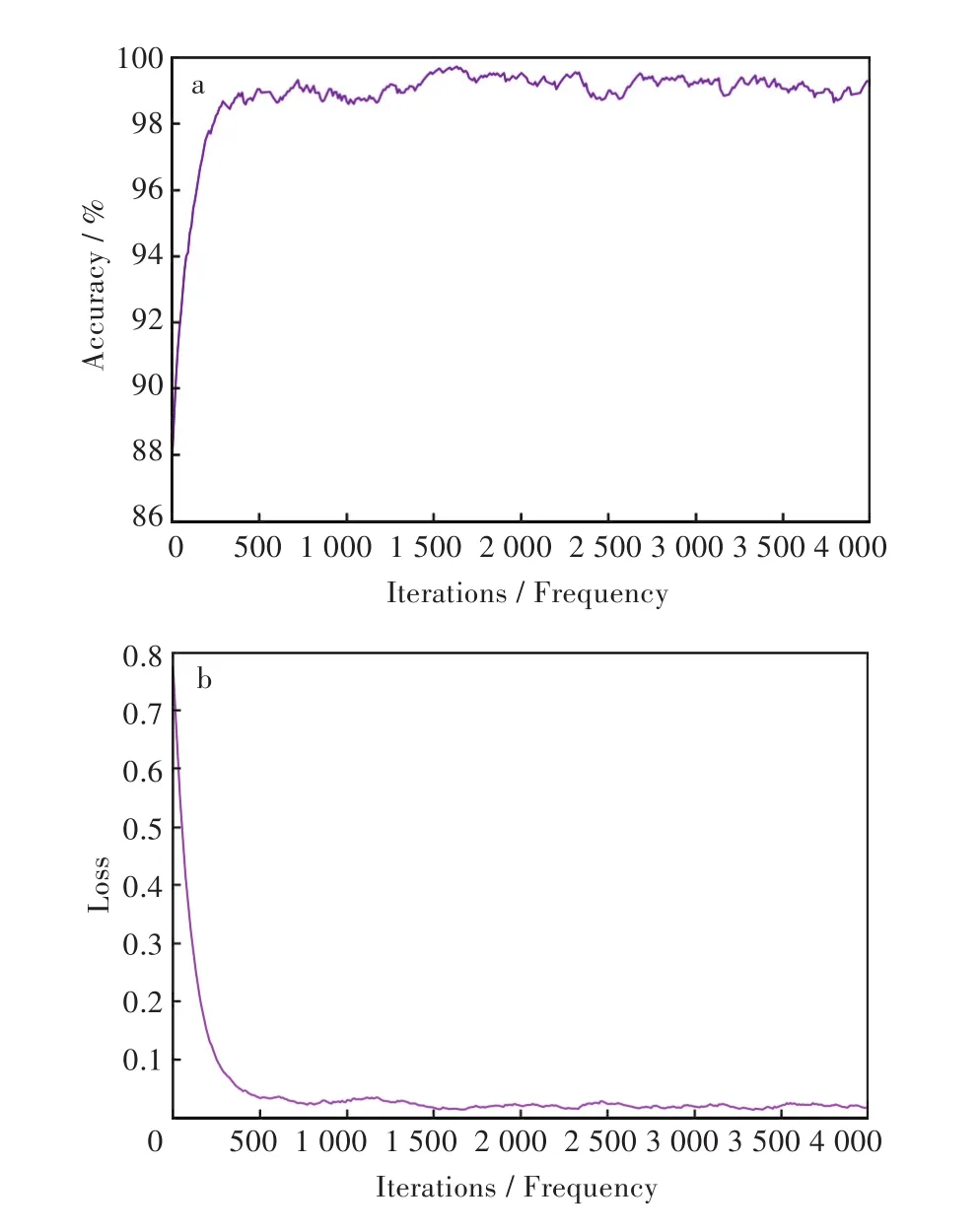
图4 (a)测试集准确度,(b)测试集损失函数值Fig.4 (a)Accuracy on validation set,(b)Loss Function value on validation set
在视频读取阶段与区域选择阶段,算法依次从视频中读取每一帧的图像。对于每一帧图像,算法首先使用K-NN背景减除器提取出前景部分,再进行腐蚀、膨胀等形态学处理消除噪点、平滑边缘,然后利用积分图快速地筛选出有可能出现烟火的区域。
在检测分类部分,首先对当前帧以及筛选得到的区域内的图像依次进行正则化处理,分别输入到检测分类的卷积神经网络中。通过卷积神经网络进行前向计算分别得到该帧或该区域属于火焰、烟雾和正常3种情况的概率,从而对图像的状态做出预测。在这一过程中,通过对当前视频帧状态的预测可以得到当前场景的基本状态。通过对动态区域内的图像进行检测可以得到火灾或烟雾的大致位置。
3 结果与讨论
在视频上进行测试。实验运行结果如图5所示,图5左上角方框内表示了当前视频帧位置、判定结果以及不同状态下的概率。图5中部的方框标记了当前的动态区域,方框颜色代表该动态区域的判定结果,蓝色代表烟雾、绿色代表正常、红色代表火焰。由图5可以看出,本文算法能够基本确定视频帧中烟雾与火焰的范围和位置。
为了更加客观准确地衡量模型效果,实验阶段设置ResNet-50卷积神经网络模型作为对照组。ResNet-50是由何凯明提出的一种卷积神经网络模型,其核心思想是引入identity shortcut connection直接跳过一个或多个层来解决当卷积神经网络层数增加时产生的梯度消失问题,在图像识别领域取得较好效果[18]。本文使用ResNet-50模型与MobileNet V1模型在相同的训练数据集下进行实验。实验结果如表3所示,由实验结果可知处理1 128个视频帧,MobileNet V1模型总处理时间为535.935 5 s,平均每帧图像耗时0.415 1 s,ResNet-50卷积神经网络模型总处理时间为966.132 5 s,平均每帧图像耗时0.856 5 s,本文模型处理图像的速度相比ResNet-50卷积神经网络快51.5%。而MobileNet V1的模型文件大小为12.3 MB,ResNet-50的模型文件大小为90.0 MB,本文模型的模型文件大小相比ResNet-50卷积神经网络小86.3%。通过比较,本文模型在略微损失准确率的情况下,大幅提升运行速度,同时缩减模型体积。
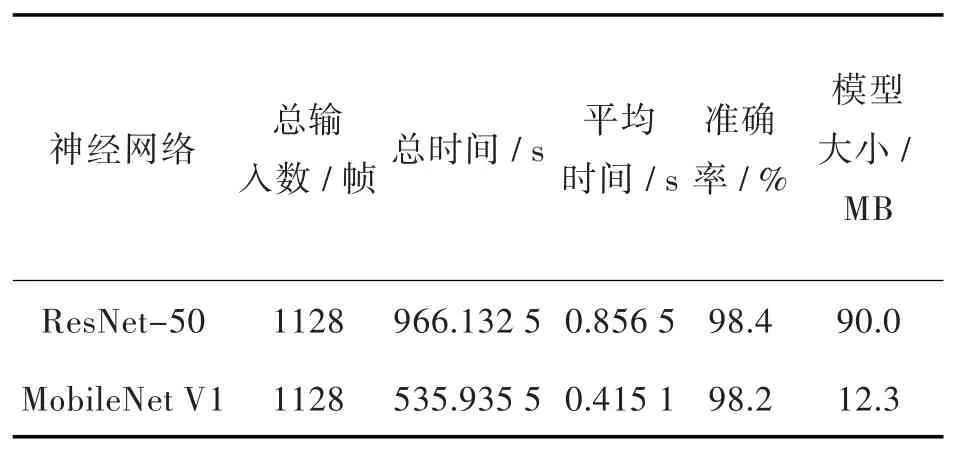
表3 不同模型的实验结果对比Fig.3 Comparison of experimental results of different models
4 结 语
在使用深度学习技术对火灾烟雾检测分类的基础上,解决了传统卷积神经网络计算量大,占用存储空间大,计算时间长的问题。由于火焰与烟雾在画面中通常处于运动状态,利用监控设备的稳定性,首先对视频中单帧图像采用K-NN背景减除器进行背景减除,再使用腐蚀与膨胀等操作进行降噪,可以较准确地选择出可能出现火焰或烟雾的范围。同时因为缩小了检测目标的查找范围,加快了检测速度。其次,引入了一种适合嵌入式设备等CPU计算能力有限的计算设备的卷积神经网络MobileNet V1对目标区域进行检测,该网络使用depthwise separate convolution将传统的卷积操作拆分为depthwise convolution和pointwise convolution,大大降低了卷积运算的参数量,提高了计算速度,降低了内存占用。实验结果表明,相比于传统的火灾烟雾检测方法,本文在保持较高识别准确率的基础上,实现了可在嵌入式设备上运行的火灾烟雾检测算法。
