大数据3.0
——后Hadoop时代大数据的核心技术
2020-01-02刘汪根孙元浩
刘汪根,孙元浩
星环信息科技(上海)有限公司,上海 200233
引言
2006年Hadoop[1]项目诞生标志着大数据技术时代的开始,而AWS商用则表明云计算正式开始了改变信息时代的步伐。自此之后,大数据和云计算成为最近十几年最为火热的技术,学术界和工业界都大量投入到相关技术的研发,极大的加速了大数据技术的商业化落地,如UC Berkeley推出了计算引擎Spark[2]。在云计算领域,企业级应用推动了技术的发展,如2014年开始兴起的容器技术和编排系统,最终推进了新一代的原生云平台的快速发展,Docker[3]和Kubernetes[4]技术则成为新一代原生云的事实标准。大数据和云计算技术的融合,加速了数据业务模式的创新,也催生了对大数据技术的底层架构的优化和升级。
1 大数据技术发展回顾与技术挑战
1.1 历史回顾
Doug Cutting参考谷歌在2003年发表的Google File System论文建立了Hadoop开源项目,并于2006年贡献给了Apache基金会,用来构建大规模搜索引擎和解决大规模的数据存储和离线计算的难题。首先诞生的是分布式文件系统HDFS和分布式计算框架MapReduce。随后在2007年,Facebook开发了Hive[5],可以使用类SQL语言查询存放在HDFS上的数据,PowerSet公司开发了分布式NoSQL数据库HBase。从2006到2009年这个阶段,以MapReduce计算框架为代表,大数据技术在大型互联网企业被广泛应用于大规模结构化数据的批处理,具体的应用场景是做日志分析和用户行为分析等。这个阶段我们称之为大数据的1.0时代。
大数据进入2.0时代的标志,是Spark核心计算引擎的出现。由于MapReduce在要求短时间响应的交互式分析场景下表现不好,以Spark和Flink[6]为代表的新计算引擎出现并广泛使用。这个阶段有三个重要变化:一是大数据业务更多转为结构化数据处理等价值密度更高的计算,所有的大数据公司开始在Hadoop之上打造SQL引擎或分布数据库。2012年开始到随后两年中出现20多个基于Hadoop的SQL引擎,包括Impala[7]、Spark SQL[8]等,以及星环的Inceptor[9],以解决结构化数据问题;二是实时数据处理方面,大量的实时数据需要及时处理,到2015年,Flink、Beam、Spark Streaming等开源技术涌现,而商业化的流计算引擎如星环Slipstream[10]的发展也如火如荼,相比开源的流引擎能够提供更多的产品能力,包括数据不丢不重、安全、SQL引擎等能力;此外,非结构化的处理技术随着数据科学技术的发展而兴起,非结构化文档数据处理、图分析技术也逐渐兴起。
1.2 新的技术挑战
随着企业的数据量越来越大,数据业务的多样性和复杂性增加,在数据存储、计算和数据业务打通方面的挑战也越来越大。
首先在存储方面,HDFS的基于Namenode的元数据架构就决定了其不能很好的支持超大量的文件规模,即使是通过Namenode Federation等技术,也只能一定程度上缓解问题而不能根治,因此我们需要设计更好的文件存储系统。而在高可用方面,HDFS、HBase、Elasticsearch等采用了不同的高可用策略,架构设计差异性比较大,在实际生产业务中,HDFS的主备切换、Elasticsearch的主备不一致问题等,都是比较常见的影响业务稳定性的技术问题,因此需要有更好的一致性存储框架来保证存储引擎的稳定性。此外,索引等技术需要能够更好的融入分布式存储技术中,来解决不同应用场景的数据检索和分析需求。
其次在计算方面,除了对结构化数据的计算深入探索以外,需求的焦点转到了非结构化数据处理,特别是图像、视频、语音、文本的处理。因此技术上需要有一个统一计算框架来处理从结构化数据到非结构化数据的所有问题。

图1 大数据技术的价值演进Fig.1 The approach to make value from big data
此外,在数据的价值输出方面也有较大的挑战:一是AI应用与大数据的结合;二是数据应用需要更好的开发和落地;三是需要打破数据的孤岛。因此需要能将大数据这种分布式的架构部署在云平台上,更好的实现数据共享和资源共享,解决数据孤岛和烟囱开发等难题。以往虚拟化技术部署大数据平台存在效率低、稳定性差的问题,需要引入新技术如容器云来解决技术挑战。
2 新一代大数据技术的设计与实现
为了应对新的数据业务化需求,解决原有的技术问题,我们需要重新设计大数据技术栈,建立一个高度统一的数据平台,能够有效的解决大数据的4个V问题,打通大数据价值输出的技术链条,从而加速大数据从持久化、统一化、资产化、业务化到生态化的价值路径(如图1)。
2.1 设计目标
在设计之初,我们定义新一代的大数据技术必须具有以下特点:
(1)统一融合的数据平台,取代混合架构
目前的企业数据业务架构中,往往需要包含数据湖、数据仓库、数据集市、综合搜索等不同数据业务系统,很多企业采用复杂的混合架构,不仅产生庞大的数据冗余,也严重限制了数据应用的时效性。新的大数据平台需要能一站式的满足所有需求,解决大数据的4-V需求,应对从快速响应到海量分析的各层级需求,淘汰混合架构的模式。
(2)开发方式的融合,SQL作为统一接口
SQL作为经过历史检验的结构化查询语言,具有庞大的用户群和灵活性,开发人员无需了解架构细节就能高效开发应用,而以往通过API开发的方式存在应用兼容性差、开发难度高等问题。新一代大数据平台需要使用SQL来支持全部功能,包括数据仓库、OLTP数据库、搜索引擎、实时计算、时空数据库等,降低开发者门槛,加快产品开发与上线速度。
(3)大数据云化,推进大数据普惠化
云计算的弹性和随处接入可以让更多的数据业务和开发者使用大数据技术,因此新的大数据技术需要能够提供云化的能力。在硬件层面上,大数据平台对CPU、GPU、网络、存储等资源进行统一管理和调配,基于容器技术实现云上的大数据应用统一部署,平台租户按需申请大数据的技术和产品。此外云化可以极大的降低运维成本,使得单单一个团队就可以同时运维很多的大数据系统软件。
(4)大数据与应用生态的融合,支撑数据业务化和业务数据化
数据业务化是大数据技术最终的价值体现,而在新的架构设计上,我们也把这个要素作为重要的设计考量点。在数据层面上,平台所有数据统一存储,建立统一的数据仓库与数据资产目录,再根据应用场景传输至不同数据集市中,各业务部门根据需求调用,打通数据孤岛,提升数据质量,转化数据价值。在模型层,通过建立模型市场,租户训练好的模型可以选择一键发布至模型市场,其他租户无需重复训练,直接调用。在应用层,平台内用户可将业务验证过的应用发布至企业级应用市场,共享给其他用户,所有运行的应用被统一管理。
2.2 总体架构
为了满足企业对大数据的更高的融合要求,同时能够支撑新型的数据存储和计算要求,星环科技整体上重新设计了大数据技术栈(如图2),同时尽量保证各个层级之间由通用的接口来打通,从而保证后续的可扩展性,避免了Hadoop技术的架构缺点。
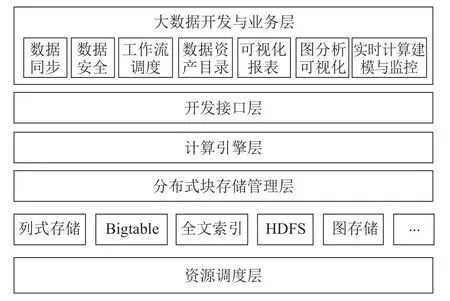
图2 新一代大数据技术栈Fig.2 The new software stack for big data technology
自下而上,最底层是可以管理和调度各种计算任务的资源调度层,我们基于Kubernetes技术来打造。随着数据应用的发展,计算任务不仅仅只是MapReduce,还可能是Spark、深度学习,甚至是MPI类的高性能计算任务,也可以是弹性的数据应用,因此专门为Hadoop设计的YARN[11]就无法满足需求。通过对Kubernetes和大数据底层的创新,我们的资源调度层不仅可以支撑各种计算任务,还可以与云计算底层打通,解决大数据云化的问题。
为了更好的适应未来的数据存储与分析的需求,支撑各种新的存储引擎,我们抽象出了统一存储管理层,能够插拔不同的存储引擎来实现对不同类型的数据的存储、检索和分析的请求。随着深度学习、知识图谱等技术的发展,未来针对某些特定的应用可能都会有专用的分布式存储引擎来支撑,在使用统一的分布式块存储管理层之后,架构师们只需要设计一个单机版本的存储引擎或者文件系统,并接入存储管理层,就可以实现一个分布式存储引擎,支持分布式事务、MVCC、索引、SQL表达式下推等功能,这样可以极大的降低存储开发的复杂度。
在块存储管理层之下就是各个数据库内核或存储,包括用于分析型数据库的列式存储、NoSQL的Bigtable、打造搜索引擎的全文索引、面向图计算的图存储引擎等,这些引擎接收上层的执行计划,然后生成对存储层的scan/put/write/事务等操作,完成特定的处理任务。
在存储层之上就是统一的计算引擎层,我们选择了基于DAG[12]的计算模式来支持大数据的各种计算。相对于MPP模式,DAG计算能够更好的适合大规模集群之间的各种通信和计算任务,并且有更高的可扩展性,能够满足包括图计算、深度学习在内的多迭代的计算特性,同时通过代码生成等技术,也可以将性能优化到非常接近native代码的水平。
最上面是统一的开发接口层,对分析数据库、交易数据库等,我们通过标准的SQL开发接口提供给开发者,降低数据开发和分析的复杂度。此外,通过完善的SQL优化器设计,可以做到无需特殊的优化,SQL业务也能有非常高的性能,甚至比直接API级编程更好,而无需了解底层架构的细节。对于图数据库,我们提供Cypher语言接口,而优化器系统则全部复用SQL优化器。此外,开发接口层还提供了统一的事务处理单元,从而保证数据开发都有完整的事务保证,确保数据的ACID。
2.3 开发接口层
统一的开发接口层的核心是SQL编译器、优化器和事务管理单元,它可以提供给开发者比较好的数据库体验,无需基于底层API来做业务开发,保证对传统业务的支持程度,还可以更好的优化业务(如图3)。
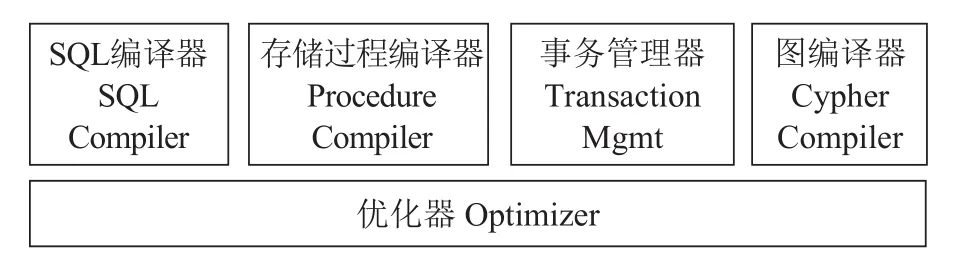
图3 开发接口层逻辑架构Fig.3 The logic view of development layer
不同于传统的大数据SQL引擎(如Hive),我们重新设计了SQL编译器(如图4),它包含了三个Parser,可以从SQL、存储过程或者Cypher语句生成语义表达式,以及一个分布式事务处理单元。一个SQL经过Parser处理后,会再经过4组不同的优化器来生成最佳的执行计划,最终将执行计划推送给向量化的执行引擎层。
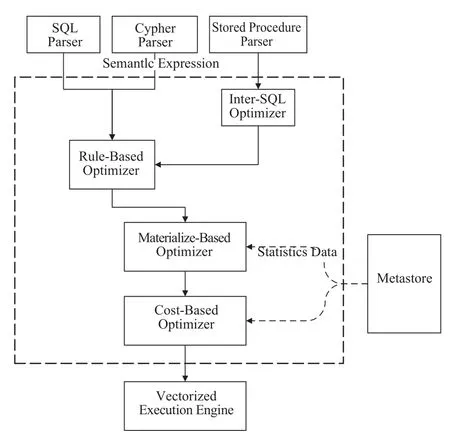
图4 SQL编译器体系Fig.4 The architecture of SQL compiler
● RBO(Rule-Based Optimizer)根据已有的专家规则进行优化,不同的存储引擎或者数据库开发者会提供专门的优化规则,目前我们已经积累了近千条优化规则。
● ISO(Inter SQL Optimizer)用于存储过程内部的优化,当一个存储过程里面有多个SQL存在类似的SQL查询或分析的时候,它可以将这些操作合并在一起,从而减少不必要的计算任务或者SQL操作。
● MBO(Materialize-Based Optimizer)是基于物化视图或Cube的优化器,如果数据库中已经有物化视图或Cube已构建好,而SQL操作能够基于这个物化对象来优化的话,MBO就会生成对相应的物化对象的操作,从而减少计算量。
● CBO(Cost-Based Optimizer)即基于成本的优化器,它会根据多个潜在的执行计划的IO成本、网络成本和计算成本来选择一个最佳的执行计划,而成本的估算则来自元数据服务。在未来,我们还计划引入机器学习的能力,通过对历史执行SQL的统计信息的有效分析,生成更加健壮的执行计划。
2.4 计算引擎层
我们的执行引擎选择了基于DAG的模式,此外为了有更好的执行效率,我们使用量化执行引擎技术来加速数据处理。量化执行引擎即每次计算对批量的数据进行处理,而不是逐个记录。对列式的数据存储,向量执行引擎有非常高的提速效果。另外与学术界很多研究进展相似,星环也采用的是同一个计算引擎支持实时计算和离线计算,从而更好支持流批统一的业务场景。
2.4.1 计算框架
在解决数据库的计算性能的可扩展性的方法上,目前主流的计算框架有两种,一种是基于MPP(Massive Parallel Processing)的加速方式,另一种是基于DAG(Directed Acyclic Graph)。整体上来看,基于MPP的方式在容错性、可扩展性和对业务的适配上灵活性不足,不能满足我们对未来多样化的数据服务支撑的需求,因此我们选择了基于DAG的计算模式,同时在它的基础上深度优化执行性能,既能支持更多样化的数据计算需求,也能够获得极致的性能(如表1)。
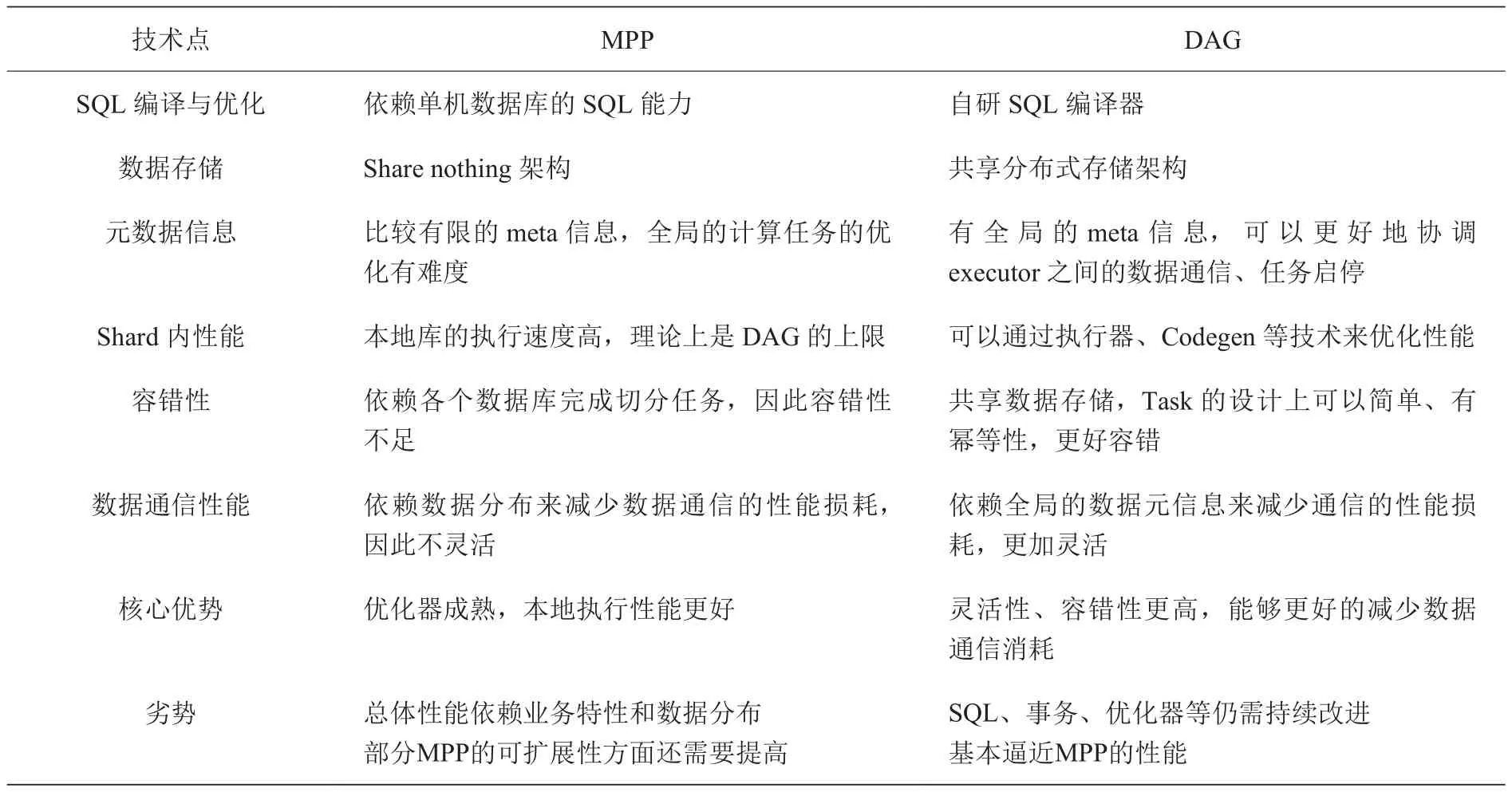
表1 MPP与DAG计算架构对比Table1 The architecture comparison of MPP and DAG
2.4.2 实时计算
从2018年开始,企业对实时计算的需求的增长非常迅速,此外由于实时计算多是生产系统,相对于分析系统在技术上也有更高的要求,包括:
● 高并发:瞬间高并发的数据操作或者分析
● 低延时:要求毫秒级的处理响应时间
● 准确性:数据不丢不重、业务高可用
● 业务连续性:在线对接生产的数据业务
为了能够系统的适应业务需求,我们放弃了对Spark或者Flink等开源方案,而是完整的设计了整个的实时计算产品(如图5)。首先,我们重新设计了流计算引擎的计算模式,保证其对数据流的计算延时能够低至5毫秒级别,同时必要完整的设计了整个数据通路,确保其数据的不丢不重,以及整个链路的安全性。
此外,在计算模式上,流数据不仅可以跟其他时间窗口的数据进行复杂计算,还需要跟历史数据(持久化在各种数据库中的数据)进行计算,因此我们引入了CEP[13]引擎(Complex Event Processing Engine),能够对多个输入事件进行计算,执行包括复杂模式的匹配和聚合计算等,也支持各种滑动窗口类计算,同时也可以与历史数据或持久化数据进行关联计算。
另外对于复杂的应用业务,我们也设计了规则引擎[14](Rule Engine)来处理业务规则,并且可以兼容其他规则引擎设计的业务规则,从而可以实现复杂的业务规则。
最后为了更好的应对业务指标,我们也在流引擎中增加了基于内存的分布式缓存,用于加速数据指标的高速存储和读取,同时支持数据的订阅与发布。
2.4.3 流批统一的架构设计
星环从2014年就开始研究如何实现流批统一的计算模式,经过2年左右的研发形成了比较有效的模式,主要包括SQL模型、优化器和计算引擎层三个方面。
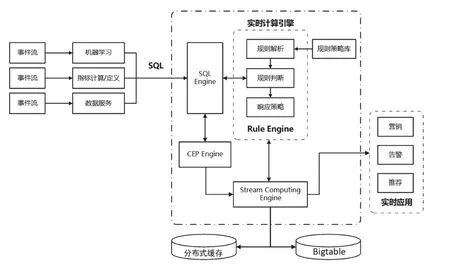
图5 实时计算引擎架构Fig.5 The architecture of stream computing engine
在SQL模型层,我们定义了StreamSQL的SQL语言扩展,新增了Stream、Stream Application和Stream Job等对象。一个Stream用于接收从一个数据源传来的数据,可以是直接接收,也可以对数据进行一定的转换操作。一个Stream Job定义了具体的流上的数据操作逻辑,如规则匹配逻辑、实时ETL逻辑等。一个Stream Application是一组业务逻辑相关的Stream Job的组合。

表2 Transwarp StreamSQL示例Table2 A Sample of Transwarp StreamSQL
在SQL层完成了统一之后,我们接下来就能够在执行计划层对相应的StreamSQL(如表2)进行编译和优化。因为我们在设计的时候充分考虑其和ANSI SQL 2003的兼容性,这部分工作对编译器团队基本上只需要增加对流表结构的处理就可以。
在计算执行层,为了支持低延时模式,我们引入了新的执行模式,通过轮询数据变化来驱动实时计算,而上层也是通过类似RDD的计算编程接口来提供。编译器层最终生成的执行计划就是对计算编程接口的操作集合。另外需要说明的是,因为流式计算的低延时特点,我们目前没有对其开启向量化计算,因为无法确定批量数据达到的时间是否满足计算延时的需要。
2.5 分布式块存储管理层
统一的分布式块存储管理层,是我们对新一代大数据技术做的重大的改造。数据的一致性是分布式系统的根基,Paxos[15]协议的出现在理论上保证其可行性,而之后更加简洁的Raft[16]协议在工程的实现上更加高效。原来大数据系统的设计很多在数据的一致性上不够完整,因此很难实现对分布式事务的支持。而工程上多个开源分布式存储在实现数据高可用和数据一致性的方式上也有不少的不足。譬如Cassandra在架构上能够保证高可用,但是它会存在Replica数据不一致的问题,此外也无法支持事务性操作;HBase底层使用HDFS保证数据持久化和一致性,但是HMaster采用了主备的方式,切换过程可能比较长,因此有单点故障问题,不能保证可用性;Elasticsearch也类似,分区内数据的一致性在生产中也是一个问题。
随着企业数据业务发展的深入,更多的专用存储引擎的需求会被引入,譬如专门面向地理信息的数据存储与分析、图数据、高维度特征的存储与计算等专用场景,再加上对现有的4大类NoSQL存储的需求,针对每个场景去实现单独的存储引擎工作量非常大,也有重复造轮子问题。
为了解决这个问题,我们将各个分布式存储的通用的部分抽象出来放在存储管理层(如图6),包括数据的一致性、存储引擎的优化接口、事务的操作接口、MVCC接口、分布式的元数据管理、数据分区策略、容错与灾备策略等功能,通过自研的基于Raft的分布式控制层来协同各个角色。各个存储引擎只需要实现其单机的存储引擎,然后接入统一的存储管理层就可以成为一个高可用的分布式存储系统。
在具体实现上,我们使用Raft协议来做各个存储之间的一致性保证,主要包括:
● 各个单机存储组成的tablet副本之间的状态机同步
● Master的选主和状态机同步
● 事务协同组的选主和状态机同步
● 存储服务的恢复服务能力
● 其他管理运维能力
基于一个单机存储来实现一个分布式存储,我们只需要完成这几个工作:
● 定义各个单机服务协同的状态机。举个例子,假如要实现一个分布式KV,采用单机的KV引擎如RocksDB。分布式存储管理层会接收来自客户端的put和delete请求,在相应请求被commit之后写入RocksDB,并将结果返回给客户端。这部分逻辑就是相应的状态机。
● 状态机定义好后,需要实现相应的回调函数。如上文例子,我们的块存储管理层预留了OnExecute,OnProposeFailed等相关的接口,只需要在相关的接口中实现状态机操作逻辑即可(如put和delete方法RPC调用)。
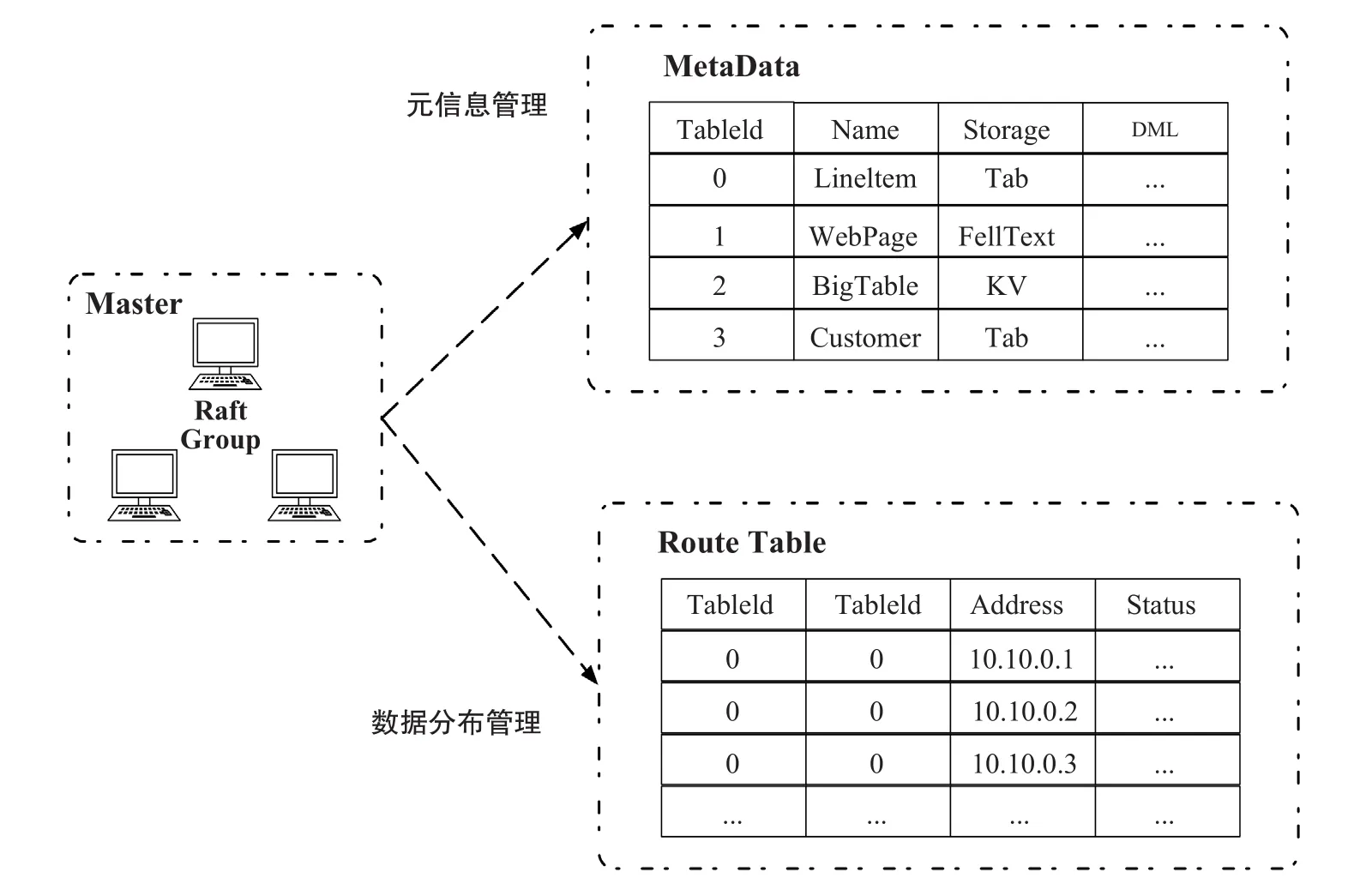
图6 存储抽象层的逻辑视图Fig.6 The logic view of the storage management layer
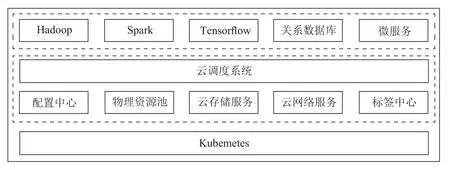
图7 调度系统的总体架构Fig.7 The architecture of the scheduling system
● 对于分布式服务关键的增删节点和数据重分布,我们也需要通过定义一个相关的状态机来实现。以增加节点为例,待添加节点创建一个state machine和raft instance,然后Leader会收到相应的add member请求并创建snapshot,同时向该节点发送metadata、WAL日志和其他状态机;新节点依次恢复相关的状态机的数据,在完成后调用相应的回调函数完成整体状态恢复的确认。至此分布式管理层即确认这个新节点加入分布式存储中。
● 实现recovery相关逻辑,形成具备整体服务恢复的能力。
● 实现事务层相关的接口。块存储管理层中包含一个raft group用于发放严格递增的timestamp并保证全集群唯一,Leader提供时间戳服务并定期同步当前最大时间戳,Follower切换为Leader时通过加一个delta保证timestamp的严格递增。单机存储需要只需要实现一些关键的语义就可以实现分布式事务,包括prepare、commit、abort等原子操作,以及为了满足各种事务隔离性的技术保证等。
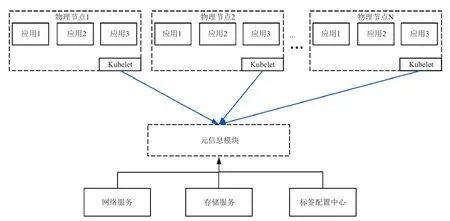
图8 应用感知数据拓扑的方式Fig.8 How the application getting aware of the data topology
2.6 资源调度层
类似于操作系统的调度模块,资源调度层是整个大数据平台能够有效运行的关键技术。图7是资源调度层的总体架构,最底层是Kubernetes服务,在其上层运行着我们自研的产品或服务。其中配置中心用于实时的收集和管理云平台内运行的服务的配置参数;物理资源池是通过各个资源池化后的逻辑资源;云存储服务是基于本地存储开发的分布式存储服务,会持久化有状态服务的数据,保证应用数据的最终持久化和系统灾备能力;云网络是自研的网络服务,提供应用和租户类似VPC的网络能力。在此之上是云调度系统,它接收应用的输入,从配置中心、标签中心、云存储和网络服务中获取实时的运行指标,从资源池中获取资源的使用情况,从而根据运行时的信息进行精确的调度决策。调度系统之上就是各类的应用服务,包括大数据、AI、数据库类,以及各种微服务,也就是云平台可以良好支撑的各种应用。
在容器云计算环境下,分布式网络中的各个主机可以为一个或多个独立的网络,每一个网络都可以包括一个或多个子网络。如图8所示,当容器中的数据应用如Spark需要启动计算任务时,调度器会首先根据该服务的依赖找到其需要的数据应用的容器(如HDFS Data node),然后通过元信息模块查询其对应所在的物理节点的网络和存储信息。一般情况下分布式存储有多个存储副本,通过调度器的反亲和性保证都调度在不同的物理节点上,因此调度器会得到一个物理节点的列表。然后调度器会根据这几个节点的实际资源使用负载情况选择当前资源最低的节点来启动对应的计算服务容器。由于两个容器都在一个主机上,计算服务可以与存储服务通过本地网络进行数据传输,或者创建domain socket等机制来加速数据读取速度,提高性能。
2.7 大数据开发与业务层
在我们定义的大数据技术栈的最上层是大数据的开发工具和数据业务价值层,它覆盖包括从数据安全、ETL开发、工作流调度、可视化分析、图分析与可视化、实时计算建模与监控、数据资产目录等在内的一整套数据开发和管理生命周期的工具,同时能够支持数据的业务化发布,因此可以更有效率的构建企业内部的数据服务层,加速数据业务的创新。
3 结论与展望
随着对企业数据业务需求的理解不断深入,星环技术团队发现了Hadoop技术架构的很多问题,并且从2016年开始设计新一代的技术栈,从原来的由相互割裂的20多个服务组成的复杂的项目生态,逐渐演变成为有效关联和协同的6层技术栈。在2017年星环率先实现了大数据组件全部统一到Kubernetes层进行调度;在2018年完成了分布式存储层的开发工作,并基于其实现了新的分布式数据库(ArgoDB)和搜索引擎(Search),另外正在其基础上研发下一代的文件系统TDFS。而2019年,基于新一代存储引擎开发的ArgoDB刚刚通过TPC-DS的基准测试,性能大幅领先于其他的分析型数据库,也说明了这个新架构设计的高效性。
未来我们将继续完善这个新的大数据架构体系,增加更多的新型数据存储与计算能力,同时完善数据业务化的技术拼图,包括基于机器学习的数据治理、数据服务发布等能力,进一步夯实数据与业务之间的技术缺口,让大数据技术更好的发挥出价值。
利益冲突声明
所有作者声明不存在利益冲突关系。
