Angel+:基于Angel的分布式机器学习平台
2020-01-02张智鹏江佳伟余乐乐崔斌
张智鹏,江佳伟,余乐乐 ,崔斌*
1.北京大学,计算机科学与技术系,高可信软件技术教育部重点实验室,北京100871
2.腾讯公司,北京100193
引言
近年来,随着互联网、通信、电子商务等行业的不断发展,各种类型的数据呈爆炸式增长,大数据已经成为研究界和工业界关注的热点。大数据中往往隐含着小数据量不具备的深度知识和潜在价值,挖掘出这些信息能够提升行业和企业的管理能力、决策水平和经济效益,为社会和个人提供更多智能和便利的服务。大数据分析中,机器学习技术是被广泛应用的工具,在单机上串行或者并行处理的机器学习算法已经有了比较成熟的研究。
但是,当今动辄达到数百TB甚至PB规模的数据以及应用的复杂程度已经远远超过了单机系统的计算和存储能力。数据量的增加通常伴随着更高维的机器学习模型,更多的模型参数以及更为复杂的训练过程。在业界真实的场景中,一个大规模机器学习系统需要有能够对PB量级的训练数据和数百亿维度的模型参数进行训练的能力。
1 分布式机器学习的挑战和解决方法
为了方便大规模机器学习任务的开发和应用,研究人员设计了各种各样的系统来解决大规模机器学习的问题。在大数据的背景下,分布式机器学习系统作为机器学习和分布式系统的交叉领域,有着独特的挑战:
(1) 高维模型。在业界真实的场景中,数据特征的维度往往能够达到十亿甚至百亿的规模。而在训练高维机器学习模型的过程中,各个计算节点需要互相通信以完成分布式的训练。这个过程往往意味着巨大的存储和通信开销,远远超过了单个机器的能力。
(2) 与现有大数据系统的兼容性。训练机器学习模型通常需要大量的训练数据,而这些数据通常由大数据系统(比如Apache Spark[11])通过处理分析得到。现有的机器学习系统都忽略了这一模块,不能很好的与大数据系统兼容,导致了大数据系统与机器学习系统之间昂贵的数据移动的开销。
(3) 通用性。研究人员针对不同模型的特点开发了各种不同的机器学习模型,比如TensorFlow[1],PyTorch,MXNet[2]等专注于深度学习模型,Petuum[3]专注于浅层模型,而XGBoost[4]专注于梯度提升树模型。这导致了人们在使用不同机器学习模型的时候,需要学习并维护新的机器学习系统,有较高的学习和系统维护的成本。
为了解决以上三个挑战,本文提出一个基于参数服务器的大规模机器学习平台Angel+。Angel+的系统架构如图1所示,包含以下三个部分:
(1) 通用的参数服务器模块。为了解决高维模型在训练过程中存储和通信开销大的问题,Angel+使用参数服务器架构[5,6]来存储和管理模型。具体的,Angel+使用多个参数服务器来统一的存储高维机器学习模型。它将机器学习模型按照一定的逻辑切片到不同的服务器上,然后统一的向下层应用提供pull/push等接口,以完成计算节点与参数服务器节点之间的通信。此外,参数服务器模块也负责实现各种不同的同步协议,比如严格同步协议BSP,异步协议ASP以及有限异步协议SSP。
(2) Spark-on-Angel模块。为了更好的兼容现有的大数据生态系统,Angel+在不改变Spark核心代码的情况下,以无入侵的方式实现了Spark-on-Angel模块,从而使得Spark用户能够以较低的成本享受到参数服务器高效的通信模块,并且避免了大数据系统与机器学习系统之间昂贵的数据移动。具体的,Angel+将参数服务器节点和Spark的计算节点分别启动为两个不同的进程:计算节点依赖Spark RDD强大的功能进行数据预处理、模型梯度的计算等;而参数服务器节点负责模型的存储、更新等。Spark计算节点通过PS-Client与参数服务器节点进行高效的通信。
(3) PyTorch-on-Angel模块。Angel+作为一个通用的机器学习平台,也能与现有的机器学习平台进行兼容,这里以PyTorch为例。在PyTorch-on-Angel模块中,我们以native C++的方式将PyTorch运行在Angel+中。如图1所示,用户以native C++加载已经写好的PyTorch模型,然后使用Spark-on-Angel模块向PyTorch模块传入数据进行梯度的计算,并且使用参数服务器模块进行模型的存储和更新。

图1 Angel+系统架构Fig.1 System architecture of Angel+
此外,Angel+还从算法层面对分布式环境下的通信开销和掉队者问题分别做了优化:
Angel+的通信开销。在分布式训练中,不同的计算节点之间要频繁的交换梯度/模型等信息来完成模型的训练。当数据维度较高(业界通常会达到十亿甚至百亿的级别),模型较大时,各个计算节点之前的通信代价变得不可忍受。为了减少计算节点和参数服务器节点之间的通信代价,Angel+从减少单次通信量和减少通信次数两个角度进行了优化。为了减少通信频次,Angel+提出了一种基于模型平均[8]的随机梯度下降训练方法,即通过多次局部更新再进行全局同步,进而大大减少全局通信的次数;为了减少单次通信量的大小,Angel+基于数据草图提出了对稀疏梯度进行压缩的方法SketchML[9].
Angel+的掉队者问题。在每一轮迭代中,每个计算节点都要进行同步梯度/模型,因此较慢的机器会成为整个系统的运行瓶颈。为了解决掉队者问题,Angel+基于参数服务器提出一种异构感知的分布式梯度下降训练方案[10]。具体的,Angel+通过允许节点之间异步的更新模型,减少了掉队者问题带来的影响。同时,由于掉队者对模型的更新通常是较为陈旧的,Angel+进一步对掉队者的模型更新施加较大的惩罚项,进而保证了问题收敛的正确性。
笔者结合Angel+平台的特性,开发了很多高效、易用的机器学习算法,包括逻辑回归、支持向量机、矩阵分解、KMeans、梯度提升树、因子分解机、主题模型、图嵌入、图卷积神经网络等。本文用实验证明了Angel+平台的高效性。此外,Angel+已经被部署在业界超过2年,运行着数以千计的真实业务。
内容组织:笔者先介绍Angel+的系统结构,包括基于Angel的参数服务器模块,Spark-on-Angel模块以及PyTorch-on-Angel模块。接下来笔者将介绍Angel+分别就通信开销和掉队者问题上提出的优化算法,最后通过实验展示Angel+的高效性。
2 Angel+系统框架
Angel+基于分布式机器学习系统Angel[5]进行了进一步扩展,采用参数服务器架构来统一的管理机器学习模型,并在此基础上提供了一套机器学习训练模块Angel-Worker。此外,Angel+还提供两个子模块Spark-on-Angel和PyTorch-on-Angel,分别兼容了大数据处理系统Apache Spark和机器学习系统PyTorch。接下来笔者将介绍各个模块的主要内容。
2.1 参数服务器模块
Angel+采用通用的参数服务器架构来统一的管理机器学习模型,即使用多个服务器来存储机器学习模型,并向各个子模块提供参数访问、参数更新的接口。接下来,笔者就模型划分策略、模型访问接口和模型同步策略一一介绍。
2.1.1 模型划分策略
在Angel+中,我们将模型参数建模为一个二维矩阵。在此基础上,Angel+使用一个PartitionKey来描述每一个模型分区,包括该分区的起始行、终止行、起始列和终止列。本质来说,每个参数服务器维护的是整个模型的一个矩阵区域。在任务启动阶段,主节点会将模型进行划分,得到所有分区的PartitionKey,然后将PartitionKey分配给不同的服务器节点,每个服务器节点得到PartitionKey以后可以随机初始化自身内容。
2.1.2 模型访问接口
为了方便计算节点的访问,Angel+提供了默认的Pull/Push接口。此外,为了支持服务器端的计算,Angel+还提供了大量的行访问/列访问的算子[7],如表1所示。

表1 Angel+ 中参数服务器的操作算子Table1 PS operators in Angel+
值得一提的是,利用这些高级算子使得用户能够在服务器端也执行计算,这样可以减少部分模型训练中的通信开销。此外,用户也可以自己定义算子,实现自己需要的执行逻辑。
2.1.3 模型同步策略
模型同步操作决定了执行任务中不同计算节点之间的同步效率,高效的同步操作能够保证计算节点可以尽早知道其他计算节点的状态,从而减少计算节点之间的等待时间。
Angel+支持同步执行协议BSP,异步执行协议ASP和有限异步协议SSP三种同步模式,用户可以通过配置参数从而选择不同的同步方式。在Angel+中,我们以模型分区粒度的向量时钟来实现精准的控制。
2.2 Angel-Worker模块
Angel-Worker模块是计算节点的一种实现方式,它不依赖于已有的大数据系统或者机器学习系统,提供了数据的读取、重划分,以及模型的训练等功能。Angel-Worker作为计算节点,与主节点、参数服务器节点一起完成分布式机器学习的训练,它们的分工如下:
主节点 (master): 主节点负责申请资源,启动/杀死计算节点和服务器节点。同时,主节点也负责调度计算节点和参数服务器节点。
计算节点 (worker): 计算节点负责执行用户提交的任务逻辑。每个计算节点从HDFS读取数据,从服务器节点读取参数,进行模型的更新,并且负责将模型更新发送到参数服务器。
服务器节点 (server): 参数服务器节点负责分布式的存储模型参数。每个参数服务器节点负责存储一部分模型参数,向计算节点提供高效的访问接口,并且利用从计算节点得到的信息来更新模型。
接下来,笔者以逻辑回归为例介绍Angel-Worker模式的执行流程。
(1)任务提交。用户提交逻辑回归任务,并且制定整个任务的配置信息,包括计算节点、参数服务器节点的个数以及资源配置情况;(2)参数服务器启动。主节点将模型参数划分为多个矩阵块,并做好从模型分区到参数服务器节点之间的映射关系,最后申请资源,启动参数服务器节点,并且初始化模型参数;(3)计算节点启动。待参数服务器节点启动后,Angel+继续申请资源,启动计算节点进程;(4)加载训练数据。主节点根据数据的规模和计算节点的数目划分训练数据;然后每个计算节点分别加载各自的训练数据;(5)计算模型更新。每个计算节点去参数服务器节点拉取模型,进行梯度的计算,并且将模型更新推送到参数服务器;(6)更新模型。收集到各个节点的梯度后,参数服务器节点进行模型的更新;然后重复第5步和第6步直至收敛。(7)保存模型。服务器节点将模型存储至外存。
2.3 Spark-on-Angel模块
在Angel-Worker模块中,训练数据往往是通过大数据系统比如Apache Spark[11]预处理产生并通过外存读取,此过程会导致较大的数据移动代价。为了减少分布式环境下数据移动的代价,Angel+提供了Spark-on-Angel模块。
如图1所示,在Spark-on-Angel模块中,Angel+利用Spark的计算节点来预处理数据以及计算模型更新,并且利用参数服务器来管理、更新模型参数。Angel+将参数服务器节点和Spark计算节点启动为两个独立的应用,并且为Spark计算节点访问参数服务器节点提供了丰富、易用的的访问接口。
Spark-on-Angel模块没有破坏Spark的核心代码,因此Spark用户能够以几乎透明的方式使用直接利用Spark进行高维机器学习模型的训练,从而避免了大数据系统和机器学习系统之间数据移动的代价。
2.4 PyTorch-on-Angel模块
研究人员针对不同的机器学习模型开发了很多高效系统。比如TensorFlow、PyTorch、MXNet专注于深度学习模型,XGBoost专注于梯度提升树模型,而Petuum专注于逻辑回归、矩阵分解、主题模型等传统机器学习模型。因此人们为了使用不同的机器学习模型通常需要使用不同的机器学习系统。为了减少使用不同机器学习系统的学习和系统维护成本,Angel+也尝试支持这些系统在参数服务器上的运行,这里以PyTorch为例。
在PyTorch-on-Angel模块中,用户通过python编写PyTorch代码,然后通过C++ native的方式将序列化后的PyTorch模型加载到Spark 计算节点中,从而无缝的使用运行在Angel+上,享受参数服务器带来的处理高维模型的能力。
3 通信开销
在分布式环境中,计算节点与参数服务器节点需要频繁的交换梯度/模型信息。当模型维度较高时,会带来较大的通信开销。本章首先介绍分布式随机梯度下降(SGD)的背景,然后介绍Angel+支持的两种通信优化算法。

图2 分布式SGD算法实现Fig.2 Implementation of distributed SGD
3.1 预备知识:分布式随机梯度下降算法
分布式SGD的执行逻辑如图2所示。其中T是迭代轮数,η是学习率,w是模型参数,X是训练数据,m是计算节点个数。
分布式SGD是一个迭代的过程,在这个过程中主节点迭代的调度计算节点和服务器节点进行梯度的计算和模型的更新(第2-4行)。在计算节点上,计算节点首先从参数服务器拉取最新的模型(第7行),然后采样小批量的训练数据计算梯度(第8,9行),最后将梯度推送给参数服务器(第10行)。在参数服务器上,参数服务器从各个计算节点收取梯度,并且进行模型的更新(第13,14行)。
在上述过程中,模型的拉取(第7行)和梯度的推送(第10,13行)通常会带来比较大的通信开销。因此,Angel分别从减少通信次数和减少单次通信量这两个方面,提出对应的优化技术来减少通信开销。
3.2 梯度压缩
为了减少单次通信中通信开销,笔者提出了SketchML[9],利用数据草图机制来对(键-值)表达的梯度进行压缩,从而在不影响模型收敛的情况下,减少每次网络的传输量。
SketchML算法主要分为三个模块,分别是分位数据草图-桶排序量化模块 (Quantile-Bucket Quantification)、最小-最大数据草图模块(MinMaxSketch)和二进制增量编码模块(Delta-Binary Coding)。前两个模块共同压缩梯度值,第三个模块用来压缩梯度键。SketchML算法框架主要包括编码和解码两部分。
编码部分:(1) 扫描一遍所有梯度值,建立一个分位数据草图,产生候选的分位值,然后用这些分位值来对梯度值进行桶排序;(2) 每个梯度的值用对应桶内所有梯度值得平均值代替;(3) 用哈希函数计算梯度键的哈希值,把对应桶的索引插入到最小-最大数据草图中;(4) 将梯度键转换为增量存储,并且用二进制编码来将增量键压缩为较少的字节。
解码部分:(1) 将增量键恢复为原始的梯度键,然后用恢复的梯度键查询最小-最大数据草图,得到梯度值对应的桶索引;(2) 用桶索引来查询得到对应桶的平均值作为梯度值。
3.3 模型平均
另一个减少通信开销的方法是减少通信的频率。基于此想法,Angel+提供了基于模型平均[3]的解法。模型平均直观的想法是在每次迭代的过程中,我们在局部多次更新模型,然后将多次更新的模型一起推送到参数服务器上,最后由参数服务器对这些模型的更新取平均值,并且更新全局模型。
通过发送模型,而不是发送梯度的方式,Angel+允许了计算节点在本地多次更新模型。这样带来的好处是,尽管单次通信的代价没有发生变化,全局通信的次数却可以大大减少。
4 掉队者问题
在真实异构的环境中,常常会存在掉队者问题,即较慢的计算节点会制约整个系统的运行速度。在图2算法中,我们发现参数服务器需要集齐所有计算节点的梯度才能更新模型(第13行),即当一个计算节点速度很慢时,所有的计算节点和参数服务器节点都只能等待这个计算节点。因此在分布式SGD中,掉队者问题是亟需解决的。
4.1 预备知识:同步协议
为了减缓掉队者问题的影响,已有的研究通过各种同步协议放宽了对同步的要求。
严格同步协议(BSP):在严格同步协议中,每轮迭代之后,所有计算节点都要停止运行,等待其他计算节点完成本轮迭代,才能开始下一轮训练。严格同步协议保证算法的正确性,但是由于计算节点之间需要互相等待,掉队者问题严重。
异步协议(ASP):异步协议完全不限制计算节点的速度,每个计算节点完全独立的产生对于模型参数的更新,不用等待其他计算节点就可以开始下一轮,最大化系统的性能。但是异步协议不能保证算法的正确性,有时候模型甚至不会收敛。
有限异步协议(SSP):有限异步协议是为了权衡严格同步协议和异步协议而提出。有限异步协议规定最快的计算节点和最慢的计算节点的迭代轮数之间的差距不能超过一个阈值。通过限制这个阈值,从而避免出现模型发散的情况,同时缓解掉队者问题带来的影响。
4.2 异构感知的分布式SGD算法
尽管SSP-SGD和ASP-SGD缓解了掉队者带来的系统性能的损失,但是他们将计算节点的局部更新直接累加到全局模型参数上,而没有考虑到掉队者产生的更新具有较大的延迟,而此时的更新对于全局模型参数是异常的,可能会导致不稳定的收敛。
Angel+考虑了掉队者带来的陈旧更新的影响,提出了两个异构感知的SGD训练算法,分别是ConSGD和DynSGD[10]。ConSGD借鉴了BSP的思想,对每个计算节点的模型更新统一的施加了1/W的惩罚项,从而削弱了掉队者带来的影响,这里W是计算节点的个数。DynSGD利用陈旧度(staleness)进一步的考虑了掉队者速度的影响,使得最慢的计算节点的模型更新得到最大的惩罚项,进一步加速了分布式SGD的训练过程。
5 机器学习算法实例
为了增强Angel+系统的可用性,我们结合参数服务器和机器学习算法二者的特点,开发了很多高效、易用的机器学习算法,包括逻辑回归、支持向量机、矩阵分解、KMeans、梯度提升树、因子分解机、主题模型、图嵌入、图卷积神经网络等。在本节中,我们以逻辑回归,主题模型以及梯度提升树为例,比较Angel+与其他机器学习系统的性能,参见表2。

表2 本文中对比的机器学习任务Table2 ML workloads in this paper.
为保证实验的公平性,在每个机器学习模型中,笔者给各个系统设置相同的超参数。实验环境为一个共享的yarn集群,网络带宽为10Gbps.
5.1 逻辑回归
逻辑回归(LR)是一种线性分类模型。由于其简单高效,并且可解释性较强,因此被广泛应用于推荐系统中。
在Angel+分布式逻辑回归的实现中,我们将数据切分到各个计算节点上,而将模型向量切分到多个参数服务器节点上。在进行模型训练的过程中,每个计算节点从各个参数服务器拉取模型,计算梯度并且对梯度进行压缩[9],然后将梯度推送回参数服务器。
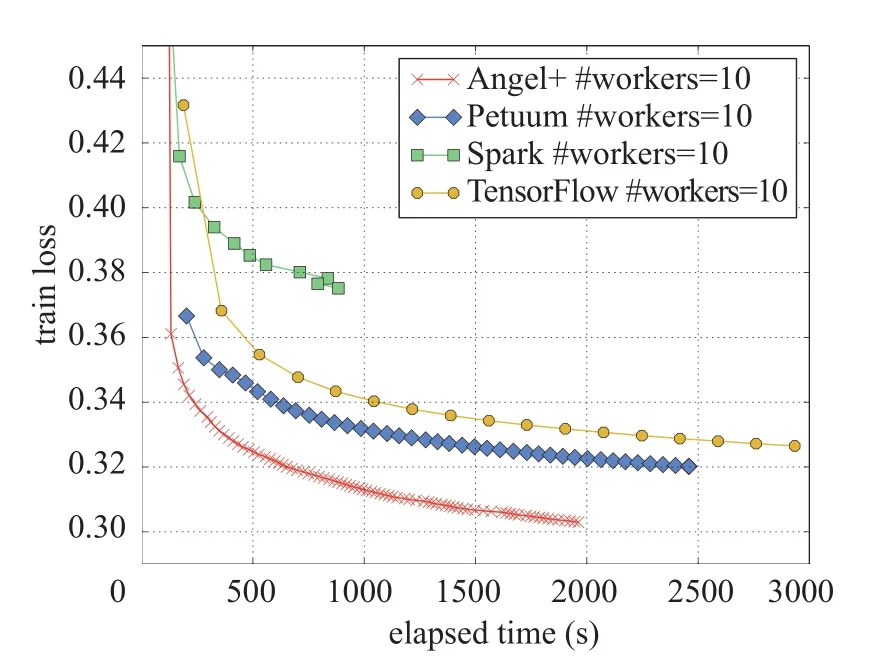
图3 逻辑回归中,Angel+ 与Petuum,Spark以及TensorFlow在KDD2010数据集上的对比Fig.3 Angel+ vs.Petuum,Spark,and TensorFlow on logistic regression on KDD2010 dataset
图3展示了Angel+与Spark,Petuum以及TensorFlow在kdd2010数据集上的表现。我们可以发现Angel+的性能远远超过了这些基线系统。
5.2 主题模型
主题模型(LDA)是一个应用于语料集合或者离散数据集合的概率生成模型,通常被用来作为文本挖掘。
在分布式LDA的实现中,我们将文档-话题矩阵Cd存储于计算节点上,而将词-话题矩阵Cw存储于参数服务器上。在已有的分布式实现中,计算节点从参数服务器拉取Cw,并将Cw的更新推送至参数服务器。在Angel+中,我们利用服务器端计算的能力(参见表1),设计了一个高效分布式LDA实现,LDA*[12]。LDA*综合考虑了各种采样方法的优劣性,提出了一个高效的混合采样器;LDA*也考虑了自然语言长尾的特性,通过将部分长尾词的计算推送到参数服务器上直接进行运算,进而减小计算节点与参数服务器之间的通信开销。
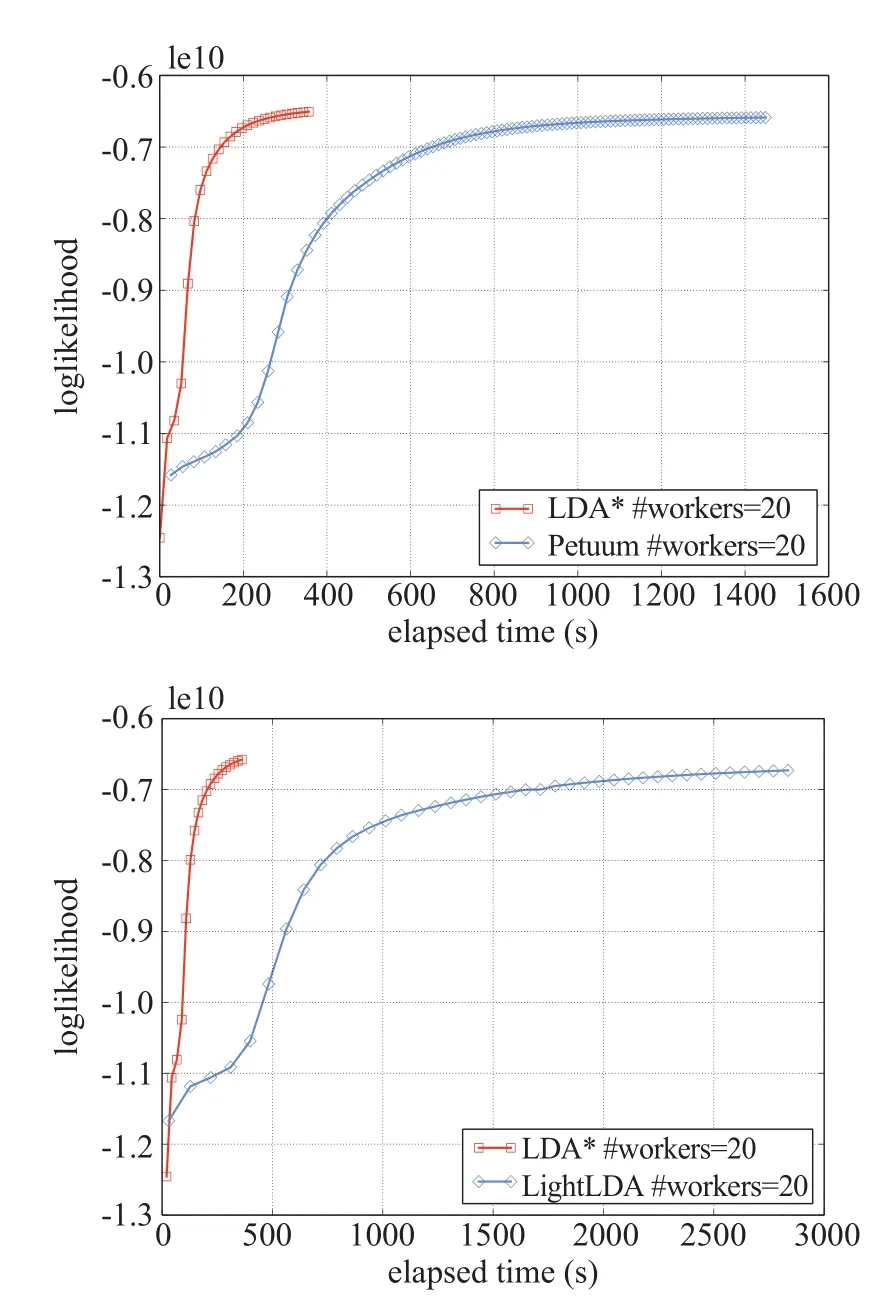
图4 LDA*与LightLDA以及Petuum在PubMed数据集上的对比Fig.4 LDA* vs.LightLDA and Petuum on PubMed dataset
图4展示了LDA*和Petuum以及LightLDA[13]在PubMed数据集上的比较,可以发现LDA*相比于LightLDA和Petuum在性能上有较大的提升。
5.3 梯度提升树
梯度提升树(GBDT)[14,15,16]是一种常用的机器学习模型,该模型不仅能达到高准确率,还具有较好的可解释性。
在分布式GBDT的实现中,我们通常需要汇聚不同计算节点上的梯度直方图。随着数据特征维度的增加,同步梯度直方图的通信代价成为了整个系统运行时的瓶颈。为了减少单点通信带来的瓶颈,Angel+设计了一个基于参数服务器的分布式梯度提升树算法实现DimBoost[14]。DimBoost通过参数服务器实现梯度直方图的同步,从而大大减少了网络的通信代价。DimBoost还提出了一系列的优化策略,包括两阶段分裂点搜索法,梯度直方图量化压缩,高效地样本-树结点索引等,从而提升分布式梯度提升树算法的性能。
图5 展示了 DimBoost,LightGBM[17],XGBoost在RCV1数据集上的比较,可以发现DimBoost在RCV1上能取得最好的性能。
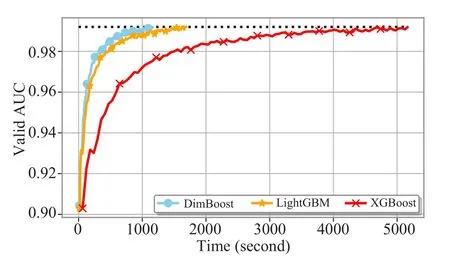
图5 DimBoost与XGBoost,LightGBM在RCV1数据集上的比较Fig.5 DimBoost vs.XGBoost,LightGBM,on RCV1 dataset
6 总结与展望
本文介绍了Angel+,一个基于参数服务器的大规模机器学习平台。Angel+高效的兼容了已有的大数据处理系统比如Apache Spark和机器学习系统,比如PyTorch,使得用户能在统一的平台下高效的使用已有的大数据处理系统和机器学习系统。此外,Angel+还针对分布式机器学习系统中通信开销大和掉队者问题分别提出了算法上的优化。为了增强平台的可用性,Angel+提供了很多常见机器学习模型的高效实现。
此外,除了机器学习模型的训练,训练数据的特征选择,模型超参数的选择,机器学习模型的选择,模型的集成等也都是机器学习必不可少的部分。因此,我们未来也将在Angel+上层搭建一个AutoML系统,方便的帮助用户更好的使用机器学习技术。机器学习平台Angel+的代码已在Github开源,也欢迎读者一起使用改进 https://github.com/Angel-ML。
利益冲突声明
所有作者声明不存在利益冲突关系。
