支持OR语义的高效受限Top-k空间关键字查询技术∗
2020-01-02于启迪孙亚欣郭景峰
潘 晓,于启迪,马 昂,孙亚欣,吴 雷,,郭景峰
1(石家庄铁道大学 经济管理学院,河北 石家庄 050043)
2(燕山大学 信息科学与工程学院,河北 秦皇岛 066004)
随着智能手机和移动终端的普及,越来越多的应用中出现了地理位置与文本信息交融的现象[1,2].一方面,越来越多的场所,例如商店、饭店、游乐场等,都附加了与其地理位置相关的文本描述信息;另一方面,文本信息也通过地名、街道地址等特征与地理信息相关联.研究表明,大约有五分之一的互联网搜索与地理位置相关,包括地名、邮政编码等[3].在同时含有空间信息和文本信息的对象上进行空间文本查询(简称为空间关键字查询)是当前研究的热点问题之一[4],即给定查询点位置和文本信息,从大量空间文本对象中找到符合查询要求的对象.
Top-k空间关键字搜索是空间关键字查询领域中非常重要的操作之一,其根据给定的评分函数在数据集中返回得分最高的k个对象[5-13].现有大部分空间关键字查询工作最先考虑的是满足用户所有文本要求和位置邻近性要求的对象,可称其为基于AND 语义的查询.然而,基于AND 语义的查询结果需完全匹配查询关键字,有时会使用户错失一些较好的选择.以图1 为例,空间中的每个对象(即黑色点o1至o6)均具有地理位置坐标和相应的关键字集合,其中每一个关键字对应一个权值,表示该关键字的重要程度(如用户评分).例如,对象o2是一个电影院,对象o4是一个综合性商场.假设用户初到该城市,在查询点q(红色点)的位置查找一家电影院,并想喝杯咖啡.基于AND 语义的Top-2 查询将返回对象集合{o4,o5},因为仅此两个对象同时包含{cinema,coffee}两个关键字.观察图1 中的对象,很明显,对象o2和o1均部分满足用户要求,且对象o2和o1在对应查询关键字上的权重均大于对象o4和对象o5在相应查询关键字上的权重(设权重越高越好),此外,q到对象集合{o1,o2}的距离较到对象集合{o4,o5}更近.换句话说,如果用户更看重品质,基于AND 语义查询返回的结果将错过更符合用户品质要求的对象(即对象o2和对象o1),并且,该对象距离查询用户位置并不远.本文关注的基于OR 语义的受限Top-k空间关键字查询可解决此类问题.

Fig.1 A simple example图1 查询示例
研究者针对Top-k空间关键字搜索问题提出了许多索引技术和查询算法[14].其中最普遍使用的是IR-tree索引.在该索引中,根据所有对象的地理位置建立一棵R 树,每个节点关联一个倒排文件.当数据量较小时,IRtree 处理效率较高,而当数据量增多时,其查询和更新效率就会下降;此外,由于在空间中只建立了一棵树,树的维护时间较长[15,16].为了解决上述不足,文献[13]提出了一种倒排线性四分树索引结构IL-Quadtree.IL-Quadtree 为每个关键字都建立了一棵线性四分树,快速返回符合查询关键字要求的k个对象.当用户进行查询时,只访问查询关键字所对应的线性四分树,直接忽略掉那些不包含目标关键字的对象.然而,文献[16]仅满足AND 语义要求.本文从查询OR 语义出发,综合考虑用户的地理位置和查询关键字与空间文本对象匹配的情况,返回在用户空间范围要求内的空间文本相似性最高的前k个对象,即支持OR 语义的受限Top-k空间关键字查询.
本文采用倒排聚集线性四分树AIL 索引所有的空间文本对象.即在倒排文件中存储所有关键字,倒排文件中的每个关键字指向包含该关键字的所有对象组成的聚集线性四分树.在AIL 的基础上,本文提出了两种查询处理算法VQuad 和VGrid.受文献[16]的启发,VQuad 算法将整个空间区域看成一个虚拟四分树,基于此,虚拟四分树采用最小最佳优先原则返回同时支持OR 语义与空间距离约束的结果.VQuad 算法是一个自顶向下的空间搜索算法.然而,线性四分树在物理上存储的并不是空间层次型结构,造成了在非空间层次结构上构建层次结构信息时,VQuad 重复遍历线性四分树.我们发现,线性四分树中的空间编码相当于将整个区域划分为虚拟网格,线性四分树中的对象位置与网格单元中的码值具有一一对应的关系.利用该对应关系,在网格中可以通过O(1)的时间复杂度访问任意单元的邻近单元,避免了线性四分树的重复遍历.基于上述想法,本文提出了一种基于虚拟网格的高效查询算法VGrid.
综上所述,本文贡献总结如下.
● 在倒排聚集线性四分树的基础上,提出了一种支持OR 语义的基于虚拟四分树的Top-k空间关键字搜索算法VQuad.
● 从线性四分树中空间位置的编码特点出发,提出了一种基于虚拟网格遍历的高效OR 语义查询的Top-k空间关键字搜索算法VGrid.
● 在真实数据集上进行了大量的实验,验证了所提方法在支持OR 语义和AND 语义上的有效性和高效性.
本文第1 节回顾Top-k空间关键字查询领域的相关工作.第2 节给出问题的形式化描述以及相关定义.第3节阐述聚集倒排线性四分树索引结构AIL,并详细介绍在该树上的相关操作.第4 节提出基于OR 语义的受限Top-k空间关键字查询处理算法VQuad 和VGrid.第5 节阐述在真实数据上进行的一系列实验,并对实验结果进行分析.最后,第6 节对全文进行总结.
1 相关工作
空间关键字查询的文本约束可分为4 种[11]:完全匹配、部分匹配、模糊匹配和布尔约束.文献[8,16-20]属于完全匹配约束(即AND 语义约束),查询完全满足用户关键字要求的对象.适用于用户对文本相似性要求较高的情况.文献[7,12,15,21-24]属于部分匹配约束(即OR 语义约束),查询满足用户部分关键字要求的对象.相较于完全匹配约束,当查询用户对文本相似性要求的严格程度不那么高时,可以采用部分匹配的方式.模糊匹配[25-29]要求对象关键字与查询关键字进行字符串相似度匹配.布尔约束[30-33]是用一个布尔表达式指定必须包含或可包含的关键词以及不包含的关键词.
就查询结果的排序方式而言,排序公式一般为空间距离和文本相关性的某种组合.例如,文献[30,34]仅依据查询对象与被查询对象的空间距离作为排序依据;文献[35]以空间和文本相关性的比值作为排序依据;文献[16,36-39]采用的是空间和文本相关性的线性组合;文献[16,35-39]使用户对于空间距离与文本相关性的重要程度有一定的选择权,但不能完全约束空间距离,导致查询返回的结果有距离用户过远的可能.本文采取空间距离与文本相关性的线性组合排序,并且增加了对空间距离的约束,充分考虑了用户对空间距离与文本重要程度的实际需求.
现有的在空间文本对象上建立的索引结构可分为空间优先和文本优先两类.空间优先的索引是先根据空间划分建立索引,然后在每个节点中存放有关的关键字信息.空间优先的索引中使用最多的是IR-tree[19,22]和IR2-tree[18]等.IR-tree 为R-tree 中的每个节点关联了一个倒排文件.IR2-tree 为R-tree 中的每个节点关联了签名文件,签名文件概括了一个节点所包含的关键字信息.当数据量较小时,IR-tree 和IR2-tree 的处理较为高效,当数据量增大时,这类索引的效率将明显下降,并且剪枝困难,影响到算法效率[15].另一类是文本优先的索引,这类索引是在现有文本索引(如倒排文件)上进行的改进,将每一个关键字映射到一个含有空间信息的数据结构上,如I3[15]、S2I[13]、IL-Quadtree[16]等.I3索引使用四分树(quadtree)将位置空间进行划分,提出关键字单元作为基本存储单元,根据不同关键字在单元格中出现的次数,分为频繁和非频繁的关键字.对于非频繁的关键字,直接用一个页面存储相关对象,通过查找表直接映射到数据文件中的物理位置;对于频繁的关键字,为频繁的关键字设计头文件指向关键字单元格所在磁盘页,其中,头文件是一个类似于四分树的结构,每个节点存储关于频繁关键字的概要信息.IL-Quadtree 针对每个关键字建立一棵线性四分树.通过检测不同树的相同节点,检验该区域是否包含所有的关键字,以实现剪枝.
本文在研究内容上,就文本约束而言,属于部分匹配约束;就排序方式而言,采用空间与文本相似性的线性组合;就索引结构而言,采用文本优先的聚集倒排线性四分树.与现有工作的区别主要体现在以下3 点:第一,本文将整个区域划分为虚拟网格,网格中每一个单元均具有唯一的码值标识,非空网格单元以聚集线性四分树的形式存储.第二,利用单元码唯一并与单元坐标可相互转换的性质,邻近单元可通过O(1)时间复杂度的方法计算来获得,极大地加快了查询速度.第三,空间和文本相关性的线性组合同时考虑了空间距离与文本相关性,并且在此基础上增加了对空间距离的约束,通过对空间距离的约束有效地缩小了可查询的空间范围.
2 问题的形式化定义
空间中任意对象均包含地理位置和文本关键字集合,记为o=(loc,T),其中,空间位置o.loc=(x,y),文本关键字集合o.T={t1,t2,...,tn},ti是文本关键字.任意两个空间文本对象的相似性包括空间相似性和文本相似性两个方面.
定义1(空间相似性).任意两个空间文本对象在空间中的相似程度用空间相似性表示.查询对象q与被查询对象o的空间相似性定义为

其中,δmax表示空间中任意两点的最远距离.fs(q,o)可采用任意两点间的距离公式,本文采用的是欧几里德距离.两个对象空间距离越近,fs(q,o)的值越小,空间相似性越大.
定义2(文本相似性).空间文本对象o中的每个关键字都被赋予一个权重,代表该关键字在对象o中的重要程度.对于任意的关键字t,在对象o中的重要程度记为wt,o.wt,o=tft,o×idft,其中,tft,o是词频,idft表示逆向文件频率.两个对象q和o的文本相似性为

∑t∈q.T wt,o是所有查询关键字在o中的权重加和.maxP是每个关键字在所有对象中的最大权重加和,用以归一化计算.ft(q,o)的值越小,文本相似性越大.定义2 中的文本相似性定义支持查询关键字的OR 语义.具体地,即使查询q.T中的部分关键字不被包含在对象o中(即wt,o=0),其文本相似性也不会为0.
定义3(空间文本相似性).结合定义1 和定义2,任意两个空间文本对象的相似性为

其中,α(α∈[0,1])是一个可调节参数,用以调节空间距离与文本相似性之间的重要程度.f(q,o)的值越小,q与o的空间文本相似性就越大.
本文问题描述如下:设空间文本对象集合O={o1,o2,…,on},用户查询q=(loc,T,d,k).loc是用户查询所在位置,T是由一系列查询关键字组成的集合,d是用户可以接受的最远距离,k即最近邻对象个数,其中,d的优先级比k高.受限Top-k空间关键字查询即从O中查找在距离d范围内空间文本相似性最高的k个被查询对象.其形式化表示见定义4.
定义4(受限Top-k 空间关键字查询).设查询对象q和被查询集合O,一个对象o∈O是查询q的受限Top-k关键字查询结果当且仅当对象o满足

3 倒排聚集线性四分树AIL
本文采用倒排聚集线性四分树索引所有的空间文本对象.倒排聚集线性四分树是倒排表与聚集线性四分树的结合.倒排表中的每一个关键字指向一棵聚集线性四分树.图2 是基于图1 中的空间文本对象建立的倒排聚集线性四分树示例.
一个关键字对应一棵聚集线性四分树.该树由包含该关键字的所有空间文本对象组成,那些不包含该关键字的对象不会在该聚集线性四分树中被索引.“聚集”是指在树中每一个节点中都存储一个聚集值,即该关键字在此节点下的最大权重.如图4 所示,“coffee”对应的线性四分树的根节点中的0.176 表示树下所有的对象{o1,o3,o4,o5}中“coffee”的权重均不大于0.176.线性四分树源于四分树,与四分树不同的是,线性四分树以B+-树的形式存储空间位置的编码值,不是直接存储空间位置(编码方法将在本节后面加以阐述).此外,线性四分树中不存储不包含任何对象的空间码值.若采用四进制Morton 码对图1 所示的空间进行编码,其结果可如图3 所示.包含“coffee”关键字的对象有{o1,o3,o4,o5},将这些对象所在位置对应的Morton 码用B+-树索引起来即形成“coffee”关键字对应的聚集线性四分树,如图4 所示.类似地,“cinema”对应的聚集线性四分树如图5 所示.图4 和图5 中的两棵聚集线性四分树是图2 中“coffee”和“cinema”的关键字对应的聚集线性四分树的详细版.

Fig.2 Aggregate inverted linear quadtree图2 聚集倒排线性四分树

Fig.3 Encoded space图3 空间编码

Fig.4 Aggregate linear quadtree w.r.t.coffee图4 “coffee”对应的聚集线性四分树
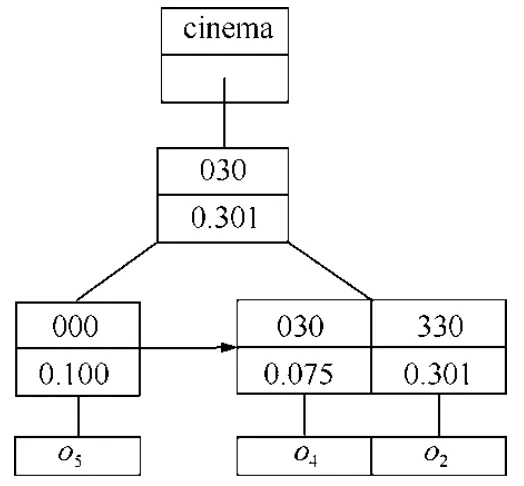
Fig.5 Aggregate linear quadtree w.r.t.cinema图5 “cinema”对应的聚集线性四分树
空间位置可遵循一定的规则进行编码,常用的有四进制或十进制Morton 码,本文采用四进制Morton 码.文献[40]对空间位置编码方法进行了详细阐述,这里仅作简要说明.编码过程需要借助四分树,设四分树最大层次为r.自顶向下地对空间位置进行四等分直至层数r.在任意层次h(h≤r)下,将SW、SE、NW、NE 这4 个方向的等分区域分别标记为0、1、2、3,如图6(a)所示.在空间上建立四分树(如图6(b)所示).四分树上一个h层的空间位置可用一个h位的四进制串表示,称为位置Morton 码.如在图6(b)所示的第3 层,任意一个空间位置都是一个3 位的四进制串.四进制串中从左向右的任意一位表示的是该位置在相应层次的方向.具体地,第3 层的Morton码左侧第1 位数字表示该节点在四分树深度为1 时区域位于的方向.如图6(b)所示的中间4 个区域的编码为120、121、122、123,其中左侧第1 位的“1”表示这4 个区域均处于四分树第1 层的SE 方向.左侧第2 位数字表示深度为2 时该节点所属区域的方向.继续上面的例子,左侧第2 位的“2”表示这4 个区域均处于四分树第2层划分的NW 方向.第3 位的0、1、2、3 表示第3 层上4 个方向的划分.在线性四分树中索引的均是底层(最深层)的Morton 码.因此,采用Morton 码对图1 所示的空间进行编码,图3 和图6(b)所示的最底层叶子节点编码是一致的.

Fig.6 Encoded Morton图6 Morton 编码
线性四分树是将上述非空叶子节点的四进制Morton 码值以数字的形式索引起来.综上所述,聚集线性四分树AIL 的创建算法如算法1 所示.
算法1.构建倒排聚集线性四分树AIL.

4 基于OR 语义的受限Top-k 空间关键字查询算法
本文的研究目标是基于AIL,从带有空间位置和文本信息的对象集合O中,寻找在受限范围内与查询q空间文本相似性最高的k个对象.AIL融合了空间与文本信息,其中的线性四分树实质存储的是空间位置编码,倒排文件中存储了文本信息.所以,基于AIL进行Top-k空间关键字查询有两种思路:(1)将线性四分树转化为空间上的四分树,改进已有经典算法,这是设计VQuad 算法的初衷(详见第4.2 节);(2)从线性四分树的空间编码入手,直接在编码后的空间上进行查询,这是设计VGrid 算法的动机(详见第4.3 节).在介绍具体算法之前,我们先来说明在两种算法中都将用到的定义和定理.
4.1 相关定义
在后续算法中需要计算查询点到一个覆盖多个对象的矩形的空间文本相似性.因此,下面首先定义扩展的空间文本对象,然后说明如何利用定义3 计算查询点到扩展空间文本对象的空间文本相似性.
定义5(扩展的空间文本对象).扩展的空间文本对象R包含地理位置和文本关键字集合两个部分,其形式化的表示为R=(loc,T).该对象的空间位置loc用一个矩形表示,该矩形可覆盖R下的每一个空间文本对象.T为R下的所有覆盖对象的关键字集合的并集,其中,针对每一个属于T的关键字由两个元素组成(t,w),t是关键字本身,w是该关键字在R中的最大权重.
以图7 为例说明定义5.图7 显示了一个扩展的空间文本对象R,其中,R.loc覆盖对象o3和o4.R.T={coffee(0.088),cinema(0.075),library(0.119),swim(0.151)}.

Fig.7 Extended spatio-textual object R图7 扩展的空间文本对象R
在扩展的空间文本对象上,依然可以利用公式(3)计算查询q与扩展空间文本对象R的空间文本相似性.其中,空间相似性采用查询q到矩形R.loc的最小空间距离,文本相似性采用公式(2)即可.
下面的定理1 证明了查询q与扩展的空间文本对象R的空间文本相似性是查询q到R中覆盖的任意对象的空间文本相似性的上限.
定理1.对于R下覆盖的任意对象o,f(q,R)≤f(q,o).
证明:从空间和文本两个角度证明.
从空间的角度,易知对于R中包含的任意对象o,对象o到查询点q的空间距离不小于R到q的空间距离,即δ(q.loc,R.loc)≤δ(q.loc,o.loc).因此,由公式(1)可知f s(q,R)≤f s(q,o).
从文本的角度,易知对于R中的任意对象o,o.t∈R.T,对象o对应于查询q的文本权重不大于R对应于查询q.T的文本权重,即∑t∈q.Twt,o≤∑t∈q.TR.T.Wt,o.因此,由公式(2)可知f t(q,R)≤f t(q,o).
综合上述空间和文本两个角度,由公式(3)可得f(q,R)≤f(q,o).由于f(q,o)的值越小越好,因此查询q与R的文本相似性是查询q到R中覆盖的任意空间文本对象的空间文本相似性的上限. □
4.2 VQuad算法
VQuad 算法的基本思想是采用最小最佳优先原则,利用AIL中存储的空间位置重建虚拟四分树[16],在虚拟四分树上寻找满足OR 语义的空间受限的k最近邻查询结果.文献[16]在虚拟四分树上进行Top-k关键字查询处理,但其仅实现了AND 语义.VQuad 算法改进了文献[16]以支持OR 语义的空间受限查询.下面首先简要介绍线性四分树与虚拟四分树的转换过程.接下来,在虚拟四分树的基础上详细介绍VQuad 查询处理方法.
4.2.1 虚拟四分树
建立虚拟四分树的目的是将查询中不同关键字对应的聚集线性四分树整合起来,通过计算虚拟四分树的节点与查询之间的空间文本相似性,将不满足查询要求的节点较早地剪枝掉.虚拟四分树之所以称为“虚拟”在于其物理上并不真实存在.由于四分树中每个层次在线性四分树的区域编码已知,所以根据树的层次以及区域编码能够建立一棵虚拟四分树.图8 是与图6(b)一样的虚拟四分树.唯一不同的是,这里将每个层次的编码扩展为r(=3)位.空缺位用X 字符补位.虚拟四分树的根节点即整个区域编码为XXX(其中,X 可取{0,1,2,3}中的任意值).第1 层的4 个区域编码分别为0XX、1XX、2XX、3XX(仅左侧第1 位有意义).虚拟四分树的第2 层节点区域编码范围是00X~33X(仅左侧前2 位有意义),虚拟四分树的第3 层节点区域编码范围是000~333.
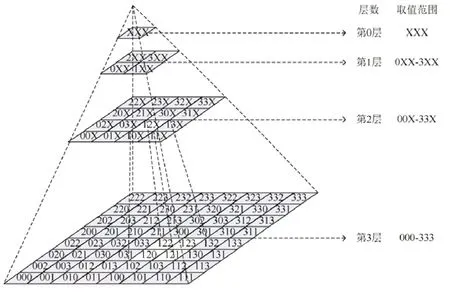
Fig.8 Virtual quadtree图8 虚拟四分树
在查询过程中需要计算虚拟四分树上的一个区域与查询之间的空间文本相似性.然而,虚拟四分树仅是逻辑上的概念,在物理上实际存储的是以B+-树组织起来的码值.因此,在计算空间文本相似性时,在空间方面,用区域中的最大Morton 码值与最小Morton 码值的横纵坐标所围成的区域限定区域范围,表示为(最小Morton 码值,最大Morton 码值).通过区域码值与空间横纵坐标的转换即可确定该区域的空间位置及空间相似性.在文本方面,将区域中所有单元的关键字权重最大值加和作为该区域对应查询的文本权重.由此,可利用公式(3)计算区域与查询间的空间文本相似性.例如,图8 中第2 层编码为12X 的区域,其在B+-树上实际对应的编码为{120,121,122,123}.该区域对应查询要求的文本权重,即4 个单元内对应查询关键字权重最大值的加和.
4.2.2 VQuad 算法流程
VQuad 算法逻辑上将整个空间用四分树进行划分,利用最小最佳优先原则选择符合查询要求的Top-k个空间文本对象.算法2 展示了VQuad 算法的具体过程.在算法2 中,用栈nbs存放从虚拟四分树中取得的节点.栈中元素以节点到查询q之间的空间文本相似性的值升序排序.首先,找到查询q包含的所有关键字对应的聚集线性四分树btset(第2 行),将虚拟四分树的根节点入栈nbs中(第3 行).当栈nbs不为空时,从nbs中取栈顶e(第5行).如果e是空间文本对象,则将该对象存入结果集R中(第8 行~第9 行).如果e是节点,判断e是叶子节点或非叶子节点,如果e是非叶子节点,则将节点e所在区域进行逻辑上四等分,计算e的4 个孩子节点与查询q之间的空间距离,判断该空间距离是否在用户允许范围d内.如果在空间限制范围内,则运用公式(3),计算e的孩子节点与查询q之间的空间文本相似性,并将该孩子节点码值及其空间文本相似性f(q,e′)入栈nbs(第10 行~第16行).如果e为叶子节点,则将e在不同的线性四分树中包含的所有对象取出,判断取出对象空间上是否在用户允许范围d内.如果是,则计算对象与查询q之间的空间文本相似性并入栈nbs中(第18 行~第23 行).最后,当结果集R中的对象个数达到k时,算法终止.
需要说明的是,VQuad 算法不仅可以支持OR 语义,也可以支持AND 语义.即只需在取出线性四分树上某一层次的节点时,判断其是否在所有的聚集线性四分树中存在.如果在所有查询要求的关键字对应的线性四分树中均存在,则执行算法的相关计算,即修改算法2 中的第13 行和第20 行.
4.2.3 运行示例
我们用图1 来说明算法VQuad 的运行过程.设AIL的层数r=3,查询点q={(5.8,5.8),{coffee,cinema},3,1},其中,d=3,k=1.
首先,虚拟四分树根节点的区域码值为(000,333).通过公式(3)计算查询点q与虚拟四分树根节点的空间文本相似性f(q,code)=0.344.将{(000,333),0.344}入栈nbs中.由于nbs不为空,栈顶出栈e=(000,333).计算e的4 个孩子节点的码值,即{(000,033),(100,133),(200,233),(300,333)}.判断4 个孩子均在查询点q的d范围内.计算4 个孩子节点与查询q的空间文本相似性,见表1 中第3 列.将节点码值及其与查询对应的空间文本相似性值按升序存入栈nbs中(见表1 中第4 列).取栈顶e=(300,333),因为单元(300,333)是四分树的中间节点,计算e=(300,333)的4 个孩子节点的码值,即{(300,303),(310,313),(320,323),(330,333)}.计算查询点q到d范围内的孩子节点的空间文本相似性,见表1.将节点码值及其与查询对应的空间文本相似性值按升序存入栈nbs中(见表1 中第2 行).
重复上述操作,直至表1 第4 行,取当前栈顶e=(330,330).因为单元(330,330)是叶子节点.从与查询关键字对应的B+-树中取出330 单元以下的对象,即{o2}.因为o2与查询点q的距离小于d,则计算查询点q到对象o2的空间文本相似性.将对象及其与查询q的空间文本相似性的值入栈nbs中(见表1 中第4 行).第5 行中,取栈顶e=o2,因为o2是空间文本对象,将o2存入结果集.此时k=1,且栈nbs中栈顶元素的空间文本相似性上限小于当前查询结果中最差的空间文本相似性,由定理1 可知,程序停止.输出结果集R={(o2,0.510)}.

Table 1 A running example of VQuad表1 VQuad 算法运行实例
算法2.基于虚拟四分树的OR 语义查询排序算法VQUAD.


4.3 VGird查询算法
因为VQuad 算法在计算四分树某一层节点与查询点的空间文本相似性时,需要不断重复地访问线性四分树,进行Morton 码与空间位置的转换,从而影响了查询效率.实际上,无需将线性四分树构建成虚拟四分树,可直接从线性四分树上的Morton 码出发,通过二进制的位运算获得单元的邻近区域和区域中的空间文本对象.基于这样的动机,本文提出了基于虚拟网格的VGrid 查询算法.VGrid 将整个空间看成一个虚拟网格,网格中每一个单元均有唯一的Morton 码.利用单元的Morton 码与单元位置坐标可相互转换的性质,邻近单元可通过公式(5)在O(1)时间复杂度下计算获得,提高了查询效率.
(1)VGrid 算法流程
算法的基本思想是以查询q所在位置为中心,从中心单元开始,循环寻找中心单元的邻近8 个单元(如图9中的n0~n7所示)中包含的对象,计算该对象与查询q的空间文本相似性,不断更新查询结果集直至获得满足空间限制的Top-k结果.为了防止空间单元的重复访问,采用visit布尔集合来标识单元是否已被访问.
具体地,首先找到查询点q所在的单元,确定相应的四进制Morton 码,记为code(第2 行).找到查询q包含的所有关键字对应的聚集线性四分树btset(第3 行).根据定义3 计算查询q到单元code的空间文本相似性,以(code,f(q,code))的形式存入栈nbs(第4 行).nbs中的元素以空间文本相似性升序排序.取nbs栈顶nbs_t.若栈顶对应的码值nbs_t.code存在于线性四分树集合btset中的任意一棵树中,则从具有nbs_t.code的线性四分树中取出nbs_t.code单元下的对象组成Oset(第7 行~第8 行).计算Oset中的对象与查询q的空间文本相似性,将满足空间距离约束d的对象放入不断更新的候选结果集RSet中,以查询q到该对象的空间文本相似性为排序关键字(第9 行~第11 行).当Rset中的第k个对象的空间文本相似性值大于栈顶元素的空间文本相似性值时,说明空间中存在比候选集中更符合用户要求的查询结果.此时,利用公式(5)寻找栈顶单元的邻近8 个单元,将8 个单元中满足空间距离约束d并且未被访问的单元的code值及其与查询的空间文本相似性存入nbs,并在visit中将code单元标识为已访问(第12 行~第17 行).重复第6 行~第19 行,直至候选结果集|Rset|=k,且Rset中对象的第k个对象的空间文本相似性值优于nbs中栈顶元素的空间文本相似性值.
算法3.基于虚拟网格的OR 语义查询排序算法VGrid.

这里需要说明两点:(1)为保证算法的正确性,在算法3 的第15 行中计算虚拟网格中的一个单元到查询q的空间文本相似性时,单元格关键字权重采用的是该关键字在空间中的全局最大值;(2)VGrid 算法可同时支持OR 语义和AND 语义.在完成AND 语义查询时仅需将算法3 中的第7 行修改为被查询单元或对象是否存在于查询关键字对应的所有线性四分树即可.
(2)运行实例
继续以图1 和查询点q={(5.8,5.8),{coffee,cinema},3,1}的例子说明算法3(VGrid)的运行过程.首先找到查询点q所在的单元,确定相应的code值为303.在visit中将303 标记为已访问.通过公式(3)计算查询点q到303 单元的空间文本相似性f(q,303)=0.700.将(303,0.700)入栈nbs中.设关键字coffee、cinema 分别对应的线性四分树为bt1和bt2(即图3 和图4).栈顶元素303 出栈.虽然单元303 到查询点q的距离小于d,但303 没有在bt1和bt2中,说明303 中没有对应查询文本的对象.利用公式(5)计算303 的相邻8 个单元,即{300,301,310,312,330,321,320,302}.计算查询q到每一个单元的空间文本相似性,见表2 的第1 行.将单元Morton 码值及其与查询对应的空间文本相似性值按升序存入栈nbs中,并在visit中将这些单元标记为已访问.
从栈nbs中取栈顶330.因为330 到查询点q的距离小于d,取出树bt1和bt2中330 单元对应的对象,去重后得h={o2}.计算o2与查询q的空间文本相似性f=0.510,并存入结果集R={(o2,0.510)}.此时,结果集R中对象o2的空间文本相似性大于栈顶元素与查询q的空间相似性(即0.510>0.485).根据公式(4)计算栈顶330 相邻8 个单元,即{303,312,313,331,333,332,323,321}.其中,{303,312,321}均已被访问,因此将剩余单元到查询点q的距离小于d的单元,即{313,331,333,332,323}入栈,见表2 第2 行.将{313,331,333,332,323}标记为已访问.由于此时结果集R中o2与查询q空间文本相似性小于栈顶元素对应的空间文本相似性(即0.510<0.576).所以,程序终止.输出的结果集R={(o2,0.510)}.

Table 2 Running instance of VGRID表2 VGRID 算法运行实例
(3)邻近8 个单元的计算方法
Morton 码[23]是空间网格划分后每一个单元(cell)的唯一标识,与单元的空间坐标可进行相互转换.利用这个性质,通过二进制位运算很容易获得某单元周围邻近8 个单元的码值乃至位置坐标.下面首先说明Morton 码与空间坐标的相互转换方法,接下来说明如何通过二进制的位运算在O(1)时间内获得邻近单元的码值.
已知某单元的十进制坐标为(x,y),其Morton 码的具体计算方法如下.先将单元位置坐标(x,y)的值转化为二进制形式,令x=xr-1...x1x0,y=yr-1...y1y0,其中,xi,yi∈{0,1},r为线性四分树划分的深度.该单元对应的二进制编码为n=yr-1xr-1...y1x1y0x0.例如,图3 中单元303 的坐标为(5,5),将两个坐标转化为二进制,分别是x=110,y=110,则该单元对应的编码为n=110011,转化为四进制后即Morton 码为303.
在算法3 的第13 行需要查找中心单元邻近的8 个单元,如图9 所示.其中,任意单元的8 个邻近单元的计算方法如公式(5)[36].设中心单元的Morton 码值为code,则有:

Fig.9 The eight neighbor cells for the cell 303图9 303 单元的8 个邻近单元

在公式(5)中,mq是邻近单元Morton 码的二进制表示.nq是中心单元code的二进制表示.tx和ty是两个二进制常数:tx=01...0101 表示“01”重复r次,ty=10...1010 表示“10”重复r次.Δni是基本方向增量之一,即计算中心单元任意方向的单元码值时坐标的变化量,8 个方位的基本增量即Δn0=(-1,-1),Δn1=(0,-1),Δn2=(1,-1),Δn3=(1,0),Δn4=(1,1),Δn5=(0,1),Δn6=(-1,1),Δn7=(-1,0).采用上文单元码值的计算方法,将∆ni由坐标值转换为Morton 码(见表3 第2 列).公式(5)采用的是位运算:“+”表示相加;“|”表示OR;“^”表示AND.设线性四分树划分深度r=3,计算中心单元303(转换成二进制为110011)的邻近8 个单元码值的过程见表3.

Table 3 Increment of direction表3 方向增量
5 实 验
5.1 实验设置
实验采用Foursquare 上真实的签到数据集[41,42],包括纽约(NYC)和洛杉矶(LA)两个城市用户的签到数据.图10 和图11 展示了将两个数据集导入QGIS 后,签到兴趣点POI(point of interests)的分布情况.表4 列出了数据集的统计信息,包括POI 数量、键字数量以及每个POI 上的平均关键字数.实验中的所有算法用Java 实现.运行于Intel(R)i5 2.30GHzCPU 处理器、4GB 内存的Windows 8 计算机上.实验中,所有的POI 组成被查询点集合.查询点集合从POI 集合中随机抽取10 000 个.随机抽取的点位置即查询点位置信息.查询点的文本关键字按照不同等级的词频随机分配.文本关键字的等级是根据关键字词频的上四分位、中位数划分的3 个等级(即高频、中频和低频词).实验默认设置见表5.
文献[16]是第1 篇在线性四分树上进行Top-k关键字查询的代表性工作,但其仅支持AND 语义.本文提出的VQuad 算法是在文献[16]中提出的基于虚拟四分树算法基础上的改进,所以在支持OR 语义方面,实验仅对比了VQuad 算法和VGrid 算法在两个不同数据集上平均查询时间的变化情况(见第5.2 节).为了验证两种算法在AND 语义方面的有效性,第5.3 节对两种算法支持AND 语义的实验结果进行了对比分析.实验变动参数有关键字个数(l)、返回结果数(k)、数据集大小等.由于文献[16]已验证了倒排线性四分树与经典索引结构的对比情况,这里没有再对索引结构大小等进行赘述.
Fig.10 LA check-in datasets图10 LA 签到数据集
Fig.11 NYC check-in datasets图11 NYC 签到数据集

Table 4 Statistics for the dataset表4 数据集的统计信息

Table 5 Default setting表5 实验默认设置
5.2 支持OR语义的算法性能对比
图12 对比展示了VQuad 和VGird 算法在两个不同真实数据集上的查询平均处理时间.从图12 观察到两种算法在LA 和NYC 数据集上的性能表现类似.从图10 和图11 可以看出,两个签到数据集POI 分布类似且POI个数接近.无论是在LA 的数据集上还是在NYC 的数据集上,VGird 的平均处理时间均优于VQuad.其原因在于,VQuad 算法需要多次访问查询关键字对应的线性四分树.具体地,VQuad 查询过程中采用的虚拟四分树是一个逻辑概念上的结构,物理上并不存在.因此,每次访问到某一个层次的四分树节点时,需要进行物理上线性四分树存储的Morton 码到虚拟四分树的转换(见第4.2.1 节).同时,VQuad 算法在计算非叶子节点与查询点的空间文本相似性时,需要该节点下覆盖对象的查询关键字的最大权重.然而,线性四分树上存储的是虚拟四分树上叶子节点中所有对象在对应关键字的最大权重.因此,虚拟四分树的非叶子节点的关键字最大权重需要从该节点下的所有叶子节点获得,导致线性四分树的重复访问,影响了查询效率.相比之下,在空间方面,VGird 算法中通过二进制的位运算(见公式(5))直接获得附近单元位置,利用visit布尔数组防止了单元的重复访问;在文本关键字方面,VGird 直接运用的是聚集线性四分树中存储的每个关键字的最大权重.因此,查询效率得到了明显提高.
图13 对比展示了查询平均处理时间在不同查询关键字个数l下的变化情况.这里用LVQuad 和LVGrid 分别表示在LA 数据集运行VQuad 算法和VGrid 算法.NVQuad 和NVGrid 分别表示在NYC 数据集上运行VQuad算法和VGrid 算法.查询关键字数量从1 增加到5.随着查询关键字个数的增加,VQuad 和VGrid 均需要访问更多的关键字对应的线性四分树,因此查询平均处理时间会随着关键字个数的增加而增加.图13 印证了我们的想法,两种算法的查询平均处理时间均随着查询关键字个数的增加亦在增长.然而,两种算法的增加幅度是逐渐降低的.这是因为在OR 语义环境下,更多的查询关键字意味着用户对查询需求的放松.线性四分树中会有更多的候选结果供选择.在k确定的前提下,一定程度地舒缓了查询时间的增长幅度.通过对比图13 中的4 条曲线可以发现,无论是在LA 数据集还是在NYC 数据集下,VGrid 算法的查询效率均比VQuad 算法要好,由图13 可以看出,VGrid 比VQuad 平均快2.5 倍.

Fig.12 Performance on different datasets图12 不同数据集上的查询平均处理时间

Fig.13 Performance on different number of query keywords图13 不同查询关键字数量上的查询平均处理时间
图14 对比展示了查询平均处理时间在不同查询返回结果个数k下的变化情况.观察图14 发现,两种算法的平均处理时间均随着查询返回结果的个数k的增加而增加.显而易见,由于用户提高了查询要求,两种算法均需要更多的时间在空间中寻找满足查询要求的结果.同时,从图14 还可以发现,随着k的增大,在相同的数据集上,VQuad 算法的增长幅度比VGrid 平均要大0.05ms.这是因为,随着查询返回结果个数的增加,VQuad 算法访问了虚拟四分树上更多的非叶子节点,增加了对关键字权重的计算次数,而VGrid 算法可直接在线性四分树上获取关键字权重,相比之下提高了查询的效率.最终,从图14 可以看出,VGrid 算法在两个数据集的查询平均处理时间相差不大(约差0.07ms).
我们从原始数据集中随机抽取50 000、100 000、150 000、200 000 个POI 对象组成了不同的被查询对象集合.从图10 和图11 可以看出,两个数据集中的POI 不是均匀分布的.所以,不同大小的数据集不是在整个空间上均匀增长,而是随着POI 分布的密集程度而增长.图15 对比显示了查询平均处理时间在不同POI 数据集大小下的变化情况.可以看出,整体上来看,两种算法的性能均随着数据集数量的增加而下降.平均而言,随着POI 数量的增加,在四分树上一个节点或网格单元下覆盖的POI 数量会增多.这就造成了从一个四分树节点或网格单元下需要抽取更多的POI 对象进行检验.但无论在哪个数据集上,VGrid 的性能都是优于VQuad 的.我们发现,两种算法在数据从150 000 增长到200 000 时,NYC 数据集上的增长幅度高于LA 数据集.通过分析图10 和图11 后发现,在相同的POI 集合大小下,NYC 数据集比LA 的数据集分布得更为分散.整体上来看,两种算法在处理时间上是高效的,VQuad 在1.1ms 以下,VGrid 在0.43ms 以下.
图16 对比展示了查询平均处理时间在不同α值下的变化.α是一个可调节参数,用来调节空间相似性与文本相似性的重要程度.α越大表示空间相似性的重要程度越大,反之,文本相似性的重要程度越大.由图16 可以看出,当α从0.1 变到0.9 时,两种算法在LA 数据集和NYC 数据集上的平均查询处理时间均保持平稳,两种算法的性能始终保持大约0.5ms 的差距.
由于VGrid 中递归计算邻近8 个单元,为了验证算法在空间搜索方面的效率,图17 对比展示了VGrid 算法在两个数据集上的空间搜索占比的变化情况.空间搜索占比即查找到用户要求的k个最近邻结果,算法遍历过的空间与整个空间面积比值.k从10 增加到50.此时,d被设置为无穷大.由图17 可以看出,查询搜索空间占比会随着查询返回结果个数的增加而增加.这是比较自然的现象,因为满足要求的结果分布在更远的单元.有趣的是,相同k值设置下NVGrid 要找到查询结果,比LYGrid 搜索的空间更广.这从另一方面验证了在NYC 上的查询平均处理时间比在LA 上要更长.即使k增长到50,搜索空间的占比也低于4.5%.
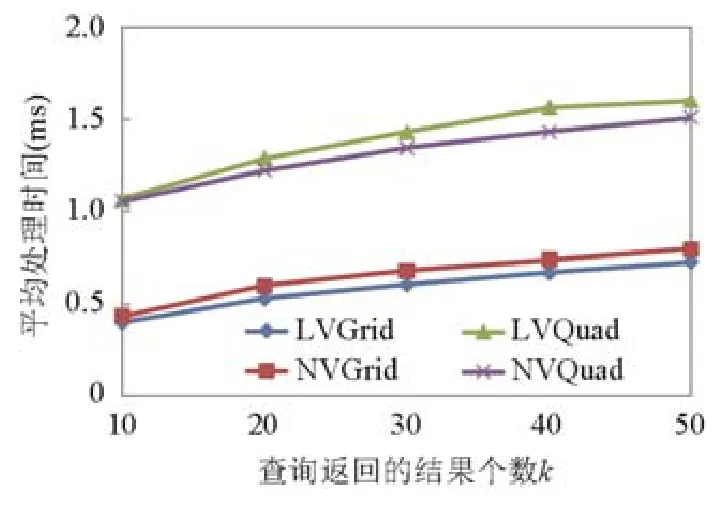
Fig.14 Performance on different k图14 不同查询结果数量上的查询平均处理时间

Fig.16 Performance on different α图16 不同参数值α上的查询平均处理时间

Fig.17 Percentage on different k图17 不同查询结果数量上的搜索空间占比
5.3 支持AND语义的算法性能对比
本文提出的VGrid 算法和VQuad 算法可同时支持OR 语义和AND 语义.为了全面验证算法的性能,本节对比展示了两种算法在支持AND 语义方面的性能.
图18 对比展示了VQuad 和VGrid 算法在支持AND 语义时在两个真实数据集上的平均查询处理时间.与支持OR 语义的情况相比,其相同之处是,在两个数据集上,算法VGrid 的平均处理时间依然均优于VQuad;不同之处在于,从整体上来讲,VQuad 在OR 语义上运行的时间比AND 语义长0.2ms,而VGrid 在AND 和OR 语义上的运行时间很近,平均都是0.49ms.这是因为,VQuad 算法的处理单位是虚拟四分树上的节点,而VGrid 的处理单位是网格单元.基于虚拟四分树的VQuad 本质上是一种自顶向下的算法,在支持AND 语义时,节点剪枝效果更明显,而VGird 本质上是基于中心单元的遍历,所以AND 语义与OR 语义差别不大.
图19 对比展示了查询平均处理时间在查询关键字数量从1 增加到5 的变化情况.随着查询关键字个数的增加,VQuad 和VGrid 的查询平均处理时间均有所增加,其原因与支持OR 语义的原因相同,这里不再赘述.在l=1时,AND 语义与OR 语义无差异.当l继续增加时,4 条线均在l增加到3 时发生了陡变.当l增加到4、5 时,增长速率减缓.图20 对比展示了AND 语义下两种算法在不同返回结果个数k下的变化情况.从图20 不难发现,两种算法的平均处理时间大体上均随着查询返回结果的个数k的增加而增加.从两组数据来看,VGrid 较VQuad 性能更稳定.平均来讲,在不同数据集上,VQuad 的平均查询处理时间为1.25ms,VGrid 的平均查询处理时间是0.69ms.图21 和图22 对比展示了POI 数据集大小、参数α值变化时算法的性能.两者的变化趋势与图15、图16 类似,这里也不再赘述.

Fig.18 Performance on different datasets w.r.t AND constraints图18 不同数据集上支持AND 语义的查询效率

Fig.19 Performance on different number of query keywords w.r.t AND constraints图19 不同查询关键字数量上支持AND 语义的查询效率

Fig.20 Performance on different number results w.r.t AND constraints图20 不同查询结果数量上支持AND 语义的查询效率
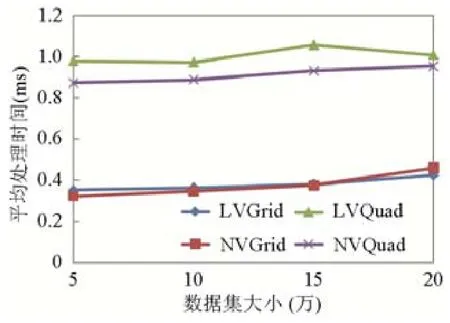
Fig.21 Performanceon different size of query datasets w.r.t AND constraints图21 不同大小的数据集上支持AND语义的查询查询效率

Fig.22 Performance on different α图22 不同参数值α上支持AND 语义的查询效率
6 总结
基于位置的地理信息服务在人们的生活中发挥着越来越重要的作用,针对空间文本对象查询的研究成为工业界和学术界关注的研究热点问题之一.为了给用户提供更多高品质的选择结果,本文针对基于聚集倒排线性四分树的高效OR 语义的受限Top-k空间关键字查询的问题进行了研究.综合考虑空间距离、空间文本相似程度的需求,基于聚集倒排线性四分树,分别提出基于虚拟四分树的VQuad 和基于虚拟网格的VGrid 算法.两种算法均可同时支持AND 语义和OR 语义.通过一系列的实验发现,由于VGrid 直接利用了线性四分树上空间编码的特点,在所有的实验设置中其性能均优于VQuad 且算法性能更稳定.未来考虑将此技术思想应用到在道路网络上的查询研究中.
