一种神经网络指令集扩展与代码映射机制∗
2020-01-02
(中国科学技术大学 计算机科学与技术学院,安徽 合肥 230027)
作为现代人工智能的重要分支,人工神经网络(artificial neural network,简称ANN)近年来得到迅速发展.深度学习作为其在大数据时代背景下的延续和进化,通过增加网络模型的深度,有效增强了传统ANN 算法的数据特征提取能力.其中,卷积神经网络(CNN)作为深度学习中广泛采用的算法,被人们实现在如人脸识别[1]、目标检测[2]、语音识别[3]、自然语言理解[4]等应用中,并取得了令人瞩目的成果.得益于其在各类应用场景中的出色表现,CNN 已成为研究人员关注的重点,并广泛部署在数据中心以及边缘嵌入式设备中.
然而,CNN 出色的识别精度背后是不断加深、复杂的网络结构和巨大的计算、访存量.近年来,CNN 模型的参数量达到了百万级别,计算量达到千兆级别[5-7].CNN 密集的计算和访存也给通用处理器带来了巨大的压力.因此,近年来涌现了许多基于FPGA[8-10]、GPU[5]和ASIC[11,12]的加速器,并达到了优于CPU 的性能和能效.在这3 类平台中,相比于动辄消耗数十瓦甚至数百瓦的GPU 平台,FPGA 和ASIC 通常具有更低的功耗.尽管GPU 在CNN 模型的训练阶段具有独特的优势,但离线训练以进行在线预测的模式使得模型推理过程更加关键.而在推理过程中,FPGA、ASIC 的低功耗特性使其具有更广泛的应用领域,如电量受限的嵌入式平台.因此本文主要关注基于这两类平台的CNN 加速器的相关工作.但经观察发现,先前的工作中此类加速器通常仅加速特定的网络结构或特定类型的层,模式相对固定,灵活性较低.
为了解决这一问题,陈云霁团队提出了DianNao[11],一款针对不同机器学习应用的高吞吐量ASIC 芯片,并设计了超长指令字(very long instruction word,简称VLIW)风格的指令,其支持CNN 和多层感知机模型(multilayer perceptrons,简称MLPs).相继提出的DaDianNao[13]则是在DianNao 基础上的SIMD 实现,不同之处在于用于计算的权值矩阵固化到本地的eDRAM 上,减少了读取内存的次数.但两者中VLIW 风格指令对计算过程的抽象较差,若不了解底层硬件,则难以使用.随后,该团队通过对ANN 中的计算进行抽象,设计了专用指令集Cambricon[14],其包含了标量、向量和矩阵等指令,支持多种神经网络且具有比传统ISA 更高的代码密度和性能.然而,该指令集并不专用于CNN,为了通用性牺牲了部分CNN 特定的数据复用和指令中的并行计算.针对CNN应用,Luca 等人[15,16]提出了PULP,一种可扩展的多核计算平台,并在其中增加了硬件卷积引擎以加速卷积操作.该平台中的单个核心均基于RISC-V 开源架构,并扩展了点积和packed-SIMD 等指令,可直接使用指令驱动加速单元,节省了操作系统层面的开销.但是该团队并未针对网络中的其他层设计相应指令.因此,一个高效、灵活且易于实现的CNN 专用指令集仍是需要的.
本文通过研究典型的CNN 模型的计算模式提出了一个小型且易于实现的CNN 专用指令集,称为RVCNN[17],其包含10 条矩阵指令,可以灵活地支持多种CNN 结构的推理过程.随后介绍了由CNN 模型描述文件到专用指令的映射过程.在实现方面,本文将指令集扩展进RISC-V 架构处理器中,并对指令的实现进行了特定的优化.最终,通过典型的案例研究,本文从代码密度、性能和能效方面对该指令集及其实现进行了对比评估.
本文第1 节介绍专用指令集的设计偏好.第2 节详细阐述专用指令的格式、功能以及代码的映射过程,并展示部分代码样例.第3 节将指令集与典型专用指令集作定性比较.第4 节介绍基于RISC-V 核的指令集硬件实现.第5 节展示实验步骤与实验结果.第6 节总结并介绍下一步工作.
1 设计偏好
本节主要展示了为设计一个高效且易于实现的CNN 专用指令集时的一些偏好,基于这些偏好,我们才能设计出具体的指令.
RISC-V 扩展.以往CNN 硬件加速器通常以外设的方式工作,主机端通过驱动对加速器进行读写.考虑到大量数据在用户空间与内核空间的拷贝,这一过程中操作系统层面的时间以及资源开销显然是不可避免的.然而,RISC-V 架构的出现给加速器的工作模式带来了更多选择.该指令集架构由基础指令集和其他可选指令集组成,具有开源性和指令可定制性,为用户提供了定制处理器微架构的可能[18]与设计专用指令的空间.因此,基于RISC-V 架构设计专用指令控制加速单元的执行也更简洁、更高效.基于以上两点分析,我们最终选择RISC-V作为目标ISA,并在保持基本内核和每个标准扩展不变的前提下使用CNN 专用指令对其进行扩展.最终专用指令可以配合RV32 具有的标量和逻辑控制指令完成CNN 的推理过程.
数据级并行.设计CNN 专用指令集涉及很多因素,但其中涉及性能瓶颈部分才是应该关注的重点.考虑到CNN 逐层堆叠的拓扑结构和不同层权重数据的独立性,设计矩阵指令以利用其操作中的数据级并行性而非挖掘其指令级并行性是更有效的.研究表明,在Intel Xeon 处理器核中用于计算的消耗仅占整个核能量消耗的37%[19],其余的能量消耗为体系结构成本,并不是计算必须的.因此,在设计专用指令时,增加指令的粒度,将指令取指、译码和控制的开销平摊到多个元素的计算上,可以有效提升执行效率.此外,当处理涉及大量数据的计算时,与传统的标量指令相比,矩阵指令可以显式地指定数据块之间的独立性,减少数据依赖检测逻辑的大小.并且,矩阵指令还具有较高的代码密度,因此我们这里主要关注数据级并行.
便签存储器(scratchpad memory).向量寄存器组通常出现在向量体系结构中,其中,每个向量寄存器都包含了一个长度固定的向量,并且允许处理器一次操作向量中的所有元素.便签存储器是在片上用于存储临时计算数据的高速内部存储器,其具有直接寻址访问、代价低以及可变长度数据访问的特性.由于实现便签存储器的代价较低,因此通常部署较大尺寸的便签存储器并集成直接内存访问(DMA)控制器,以便进行快速的数据传输.此外,考虑到密集、连续、可变长度的数据访问经常发生在CNN 中,我们这里选择使用便签存储器来替代传统的向量寄存器组.
2 专用指令设计与映射
本节中,我们首先展示了专用指令集的构成,然后详细介绍了在第1 节中提出的设计偏好下专用指令的功能和格式.在此基础上,我们介绍了从基于深度学习框架的CNN 模型描述文件到专用指令的映射过程,并列举了由专用指令实现的卷积层和池化层的代码.
2.1 专用指令扩展
RV-CNN 指令集的构成见表1,其包含了数据传输指令、逻辑指令和计算指令.配合部分基础的RV-32I 指令集(这里不再描述),该指令集可以完成典型的CNN 类计算.RV-CNN 指令集架构仍然和RISC-V 架构保持一致,属于load-store 架构,仅通过专用的指令进行数据传输.并且,该指令集仍使用RV-32 中的32 个32 位通用寄存器,用于存储标量值以及便签存储器的寄存器间接寻址.另外,我们设置了一个向量长度寄存器(vector-length register,简称VLR)来指定运行时实际处理的向量长度.下面对指令进行详细介绍.

Table 1 An overview of RV-CNN表1 RV-CNN 指令集综述
2.1.1 数据传输指令
为了灵活地支持矩阵运算,数据传输指令可以完成片外主存储器和片上便签存储器之间可变大小的数据块传输.图1 展示了矩阵加载指令(MLOAD)的格式.

Fig.1 Matrix load (MLOAD)instruction format图1 矩阵加载指令格式
图1 中,Reg0 指定片上目标地址.Reg1、Reg2 和Reg3 分别指定矩阵的源地址、矩阵的大小和相邻元素的跨度.具体而言,该指令完成数据从主存向便签存储器的传输,其中,指令的步幅字段可以指定相邻元素的跨度,从而避免了内存中“昂贵的”矩阵转置操作.相对应地,矩阵存储指令(MSTORE)完成便签存储器向主存储器方向的数据传输,其指令格式与MLOAD 相似,不过经常会忽略步幅字段以避免不连续的片外访存.
2.1.2 矩阵计算指令
CNN 主要由卷积层、激励层、池化层和全连接层组成,其中大部分计算都集中在卷积层[20].在卷积层的计算中,卷积核在输入特征图上连续移动,并在重合区域执行点积以生成下一层的输入数据.在此过程中,同一卷积核在特征图的不同区域之间的计算是独立的,不同卷积核在特征图的相同区域的计算也是独立的.为了充分利用卷积计算中的并行性,我们采用Im2col(image to column)算法将2-D 卷积运算转换为矩阵乘法运算(算法示意如图2 所示).

Fig.2 Matrix multiplication version of convolution图2 卷积运算的矩阵乘法版本
将2-D 卷积映射到矩阵乘法操作后,可以很自然地使用MMM(matrix-multiply-matrix)指令执行该操作.其指令格式如图3 所示,其中,Reg0 指定矩阵输出的便签存储器中的目的地址;16~12 位是指令的功能字段,指示矩阵乘运算.Reg1 和Reg2 分别指定矩阵1 和矩阵2 的在便签存储器中的源地址.Reg3 中的4 个字节分别代表矩阵的高(H)、宽(W)、卷积核大小(K)、卷积步长(S).考虑到实际执行中分片技术的使用,这里使用单个字节存储相应的信息是足够的.因此,卷积操作执行时的参数信息被打包成32’b{H,W,K,S},并由Reg3 指定.同时,由于数据分片载入,其产生的中间结果往往需要累加.这里不设置特定的矩阵加法指令而是设计了MMS 指令.该指令在完成矩阵乘法计算后,将部分结果写入目标地址时与该地址原有的值累加后再存储,使得在完成累加的同时减少数据的重新载入.该指令的格式和各字段含义均与MMM 指令一致,由功能字段指定该指令,故不再展示.此外,为了更大程度地利用数据局部性并减少对同一地址的并发读/写请求,我们选择采用专用的MMM 指令执行矩阵乘法,而不是将其分解为更细粒度的指令(例如,矩阵向量乘和矢量点积).

Fig.3 Matrix multiply matirx (MMM)instruction format图3 矩阵乘矩阵指令格式
全连接层通常在整个卷积神经网络的尾部以对之前各层学得的特征进行映射达到分类效果.全连接层的计算可以用矩阵向量乘法表示,而MMM 指令在不同的参数下同样可以表示全连接层的计算,因此卷积层和全连接层可以复用相同的计算单元.
2.1.3 矩阵逻辑指令
融合(fusion)[21]作为目前DNN 加速器设计中常用的技术,通过将部分层加以融合,从而以一次数据的加载、存储替代单独层的数据输入输出操作来最小化带宽限制.融合操作的优势以及目前CNN 中激活层通常紧接在卷积层或全连接层之后的特点,使得设计相应的粗粒度指令将两者融合执行是非常适合的.而且激励层不改变输入张量的尺寸且激活函数逐元素进行激活操作,其需要的参数较少.因此,我们设计了MMMA 指令,使矩阵相乘得到卷积层或全连接层的部分最终结果后可经过激活操作后输出,其指令格式与各字段含义均和MMM 指令一致,由功能字段指定该指令.不过,我们仍然保留了激活指令,以完成对输入的数据进行激活操作,其指令格式如图4 所示,其指令中的31~27 位用来决定激活函数的选择,如ReLU()/sigmoid()/Tanh().

Fig.4 Matrix activation (MACT)instruction format图4 矩阵激活指令格式
池化层通过降采样将输入数据的每个窗口子采样到单个池输出以减小输入图片的尺寸.实际上,卷积神经网络中相较于卷积层和全连接层,其余层包含了很少的计算且被数据访问时间限制.在某些CNN 模型中,对池化层和相邻层采用融合技术同样是有效的.但是,不同于激活层在CNN 中的位置相对固定且按元素操作,池化层仍具有一定的灵活度,如3 个卷积层堆叠后池化.于是,这里我们仍将池化层当作单独的层来处理.用于进行最大值池化的MXPOOL 的指令格式如图5 所示.其中,Reg0、Reg1、Reg2 分别表示输出数据的目标地址、输入数据的源地址和输入数据的长度.借鉴设计MMM 指令的思想,观察到池化窗口通常为2×2、3×3、5×5 等小尺寸而且通常采用分片技术处理输入数据,所以使用单个字节分别表示一次分片可处理的输入矩阵的高(H)、宽(W)、池化窗口大小(K)和步长(S)是足够的.这些必要信息进而被打包为32 位值,由Reg3 指定.

Fig.5 Matrix maximum (MXPOOL)instruction format图5 矩阵池化指令格式
2.2 代码映射机制
RV-CNN 指令生成流程如图6 所示.其中,CNN 模型描述文件可以是深度学习工程师熟悉的Caffe、TensorFlow 或Pytorch 等流行框架下的描述文件.由模型分析器对该描述文件进行解析以生成用于模型构建的参数信息和重排后的权重信息.在此基础上,应根据网络参数信息构建数据流图并提取算子,然后在不同的融合策略下将提取出的算子映射至指令池(RV-CNN 指令集)中的不同指令.由于我们设计的指令均为粗粒度指令,这里应提取粒度适合的算子才能映射至目标指令集.在专用指令提取后,应根据硬件的参数信息,如片上便签存储器的大小和硬件计算资源规模来决定分片大小.同时根据复用策略,如输入复用或权值复用等对指令进行编排以生成最终的代码.其中,应使用RV32 基础指令集将参数信息加载至寄存器并完成循环控制.

Fig.6 RV-CNN instructions generation process图6 RV-CNN 指令生成流程
2.3 代码示例
为了阐述提出的专用指令集的用法,我们列举了使用RV-CNN 构建的CNN 中两个具有代表性的部分,即卷积层和池化层.其中,卷积层的实现通过融合指令包含了激励层的操作.而全连接层的代码实现与卷积层代码类似,仅在配置参数上略有不同,故不作列举.
2.3.1 卷积层代码示例
RV-CNN 实现的卷积层代码如图7 所示,其中,左侧是在Caffe 框架中编写的卷积层代码(用以示意),其完成对输入特征图(14×14×512),使用512 组尺寸为3×3、步幅为1 的卷积核进行特征提取的过程.图中右侧则是使用专用指令完成相同功能的示意代码,其中假设硬件片上资源充足且数据排列顺序合适.
由于指令从寄存器中获取参数信息,因此我们首先需要向寄存器中加载必要的信息.这里首先加载立即数0×0E0E0301 至$5 寄存器,根据第2 节对指令格式的描述,该32 位数据中由高至低的4 个字节分别代表了输入数据的高度(14)、宽度(14)、卷积核尺寸(3)以及步幅(1).之后设置向量寄存器VLR 为16,代表一次处理的向量长度为16.由于采用分片技术,这里设置循环计数器$11、$12 来完成深度方向和不同卷积核的遍历.随后,通过在寄存器$6、$8、$10 中加载数据在片外DDR 中的实际地址,以便通过MLOAD/MSTORE 完成数据传输.以上寄存器中的信息应由指令生成器或者用户根据网络模型以及硬件参数信息生成.在此基础上,开始实际计算过程.首先分别将数据从片外0×30000 和0×50000 处加载至由$1 和$2 指定的片上目的地址.数据加载完毕后,通过执行MMM 指令完成计算.计算过程中的中间结果保存在片上便签存储器中.之后的计算通过使用MMMS 指令完成计算与片上中间结果累加,以减少不必要的片外访存.最终,通过执行MMMSA 指令完成部分最终结果的激活,并由MSTORE 指令将结果传输至片外.

Fig.7 Convolutional layer code example implemented by RV-CNN图7 RV-CNN 实现的卷积层代码示例
2.3.2 池化层代码示例
RV-CNN 实现的池化层代码如图8 所示,左侧仍以Caffe 框架中编写池化层代码作功能示意,其表示对输入特征图(14×14×512),使用2×2、步幅为2 的池化窗口进行最大值采样.图右侧则是使用专用指令完成相同功能的示意代码,其中仍假设硬件片上资源充足且数据排列顺序合适.
由于池化层不包含权重数据且不在深度方向上累积,在输入图片大小合适的情况下,其RV-CNN 实现的代码比卷积层代码要简洁.在向相应寄存器中加载完参数后,利用MLOAD 指令将待处理数据从片外0×10000($6)处加载至片上目的地址$1 处.输入数据加载完毕后,使用MXPOOL 指令进行降采样并将结果存储在片上临时地址$5 处,采样结束后,则由MSTORE 将结果传输至片外地址0×40000($7)处,该过程中输出并不会在片上累加.代码中的循环计数器是为了在输入数据深度方向上遍历,一次载入、池化、载出完成一次分片数据的采样,之后更新载入、载出地址以及计数器值.

Fig.8 Pooling layer code example implemented by RV-CNN图8 RV-CNN 实现的池化层代码示例
3 RV-CNN 和专用指令集对比
目前,在面向神经网络领域的专用指令集中,Cambricon 指令集被认为是最具代表性的指令集之一,而基于RISC-V 架构的向量指令集扩展(RV-V)也被认为是加速神经网络计算的指令集.因此,本节将围绕指令集的适用范围、粗细粒度以及映射机制等方面,将RV-CNN 与以上两种典型指令集进行定性分析和对比.
适用范围.RV-V 指令集的建立旨在利用应用中的数据级并行,其可广泛应用于科学计算、数据信号处理以及机器学习等领域.Cambricon 指令集则是面向神经网络领域,如CNN、循环神经网络(RNN)以及长短期记忆网络(LSTM)等10 余种网络模型而设计的指令集.相比之下,RV-CNN 指令集着重针对神经网络领域中的CNN 而设计,其中涉及的运算类型较少.因此,前两者针对的领域更广泛,设计的难度也更大,这在指令集包含的指令类型和数目上也有所体现.RV-V 指令集已经包含了超过60 条指令(草稿版本0.8),Cambricon 指令集中包含了47条指令,而RV-CNN 指令集仅包含了10 条指令.
粗细粒度.RV-V 和RV-CNN 指令集中分别包含了向量和矩阵指令,而Cambricon 指令集中则包含了标量、向量以及矩阵3 类不同的指令.Cambricon 之所以包含标量指令是因为其在概念上是一个完备的神经网络指令集,但其中用于加速计算的仍是向量和矩阵指令.因此,在指令粒度层面上,RV-CNN 指令集是三者中指令粒度最大的,Cambricon 指令集其次,由于RV-V 指令集中均是向量指令,相比之下粒度最小.这也与指令集的适用范围相关,由于在设计RV-V 指令集时针对的应用领域最为广泛,因此需要从多种计算操作中提取共性部分.考虑到硬件规模及能耗限制,这一过程往往需要结合算法特性,将不同的计算过程不断地向下拆分以寻求计算共性,提高指令集的表达能力,因此相较于前两者RV-V 指令集的指令粒度最小.
代码映射机制.Cambricon 指令集的代码映射是基于框架的,其为流行的编程框架提供适配的机器学习高性能库与软件运行时支持,向上为框架提供丰富的算子和计算图方法以构造整个网络,向下通过调用内置驱动产生指令以控制硬件.RV-CNN 指令集的代码映射过程以基于框架的模型描述文件开始,不同于Cambricon 对框架进行修改,RV-CNN 仅对框架下的模型描述文件进行分析,从而提取模型结构及权重信息,进而配合融合策略建立模型中算子和指令间的映射关系,之后根据复用策略进行指令编排,最终经汇编形成可执行文件.RV-V 指令集目前处于正在进行的状态,还未提供可使用的编译器来完成对代码的自动矢量化过程,仍需要用户手写汇编指令.但其中涉及到大量细粒度的向量指令,这给编程过程中寄存器分配以及指令编排增加了难度.
4 RV-CNN 的硬件实现
本节首先介绍了包含RV-CNN 指令扩展的开源处理器核的整体结构,并详细介绍了指令的执行流程.随后讲述了与RV-CNN 指令相对应的矩阵单元的组成及其子单元的功能,其中详细展示了矩阵乘法单元的结构,最后介绍了有关矩阵单元的优化细节.
4.1 整体架构
包含了RV-CNN 扩展的RISC-V 处理器核的主要功能部件以及简化的流水线结构如图9 所示.可见,其包含了基本的5 个流水线阶段:取指、译码、执行、访存和写回.其中,矩阵计算单元处于流水线的执行阶段,用于完成矩阵指令的执行.在取指、译码阶段之后,基础指令集中的指令将进入ALU,然后进入下一个阶段.当译码阶段解析出当前指令是矩阵指令后,译码器从寄存器中获得相应信息并保存,待下一个周期送入矩阵单元.矩阵单元根据接受的指令信息并检测相应功能部件的状态以确定是否执行.由于片上便签寄存器的地址空间用户可见,矩阵单元可以通过矩阵数据传输指令和内存进行交互,因此,矩阵指令进入矩阵单元后不会经过访存和写回两个阶段,而其余指令不通过矩阵单元,其访存仍通过高速缓存(cache).这样可以避免不必要的数据依赖性检测和硬件自动的数据换入换出.此外,由于矩阵单元包含了大量的计算单元,其内部有自己的流水线结构,译码器根据矩阵单元能否接受矩阵指令信息来决定是否停止流水线.鉴于矩阵指令连续、大量的数据访问,我们在便签存储器外集成了DMA 控制器,以便满足矩阵单元的数据访问需求.需要注意的是,矩阵单元完成计算和逻辑类指令所涉及的数据需要已经存在于片上,这需要程序的严格控制.
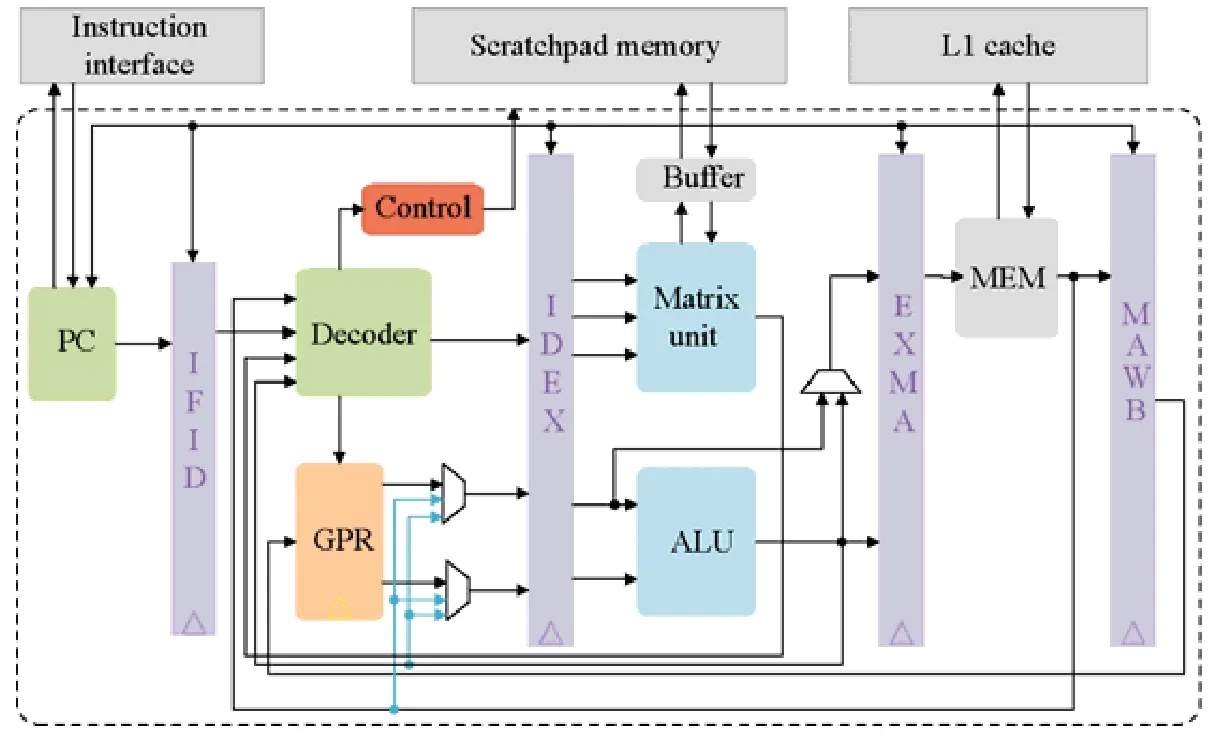
Fig.9 A simplified block diagram of processor core with RV-CNN extension图9 包含RV-CNN 扩展的处理器核简化框图
4.2 矩阵单元
矩阵单元的整体结构如图10 所示,其内部主要包含了输入输出单元、矩阵乘法单元、激活单元、池化单元以及内部控制器,其中,橙色和灰色箭头分别表示控制流和数据流.矩阵单元接收传入的指令信息以及寄存器信息后存储到队列中.内部控制器(作为有限状态机)是矩阵单元的控制中心,其根据控制信息将唤醒子组件(如果可用)以完成相应任务.否则,它将生成一个反馈信号以指示相应的功能单元正忙.缓冲模块本质上是一个片上存储器,矩阵单元中的计算核心从中获取数据并将产生的结果写入.除融合指令会同时启动多个计算核心外,计算单元大致上与粗粒度指令一一对应.最后,输入输出模块则负责根据有效地址在矩阵单元与片上便签存储器之间进行数据传输.
由于矩阵乘法单元被卷积层和全连接层共用,其承担了大部分计算,因此该单元的实现对性能至关重要.这里我们采用了脉动阵列结构实现的矩阵乘法,其结构如图10 右侧部分所示.脉动阵列是一种高效且简单的矩阵乘法实现方式,其通过二维网格将MAC(multiply-accumulate)单元绑定在一起,除阵列的最外侧层(这里是最左侧和最上侧)的计算单元直接与片上缓冲相连以获取数据外,其余计算单元均从其邻居中获得输入.这种方式在MAC 阵列规模变大时将显著减少片上缓冲的扇入扇出.同时,数据在MAC 单元之间流动性地传递也增加了数据复用.例如,当MAC 阵列为12×16 时,矩阵B中的元素按行在不同时刻由左至右在阵列中传递,数据输出时复用了16 次;类似地,矩阵A中的元素按列在不同时刻由上至下在阵列中传递,输出时复用了12 次.在这一过程中,配合流水线优化,每周期只需要向阵列输入28 个数,就可以进行192 个MAC 操作.此外,短的局部互连也降低了布局布线的难度,因此,这里我们选择使用脉动阵列作为矩阵乘法的实现方式.

Fig.10 The block diagram of the matrix unit图10 矩阵单元的结构示意图
4.3 优化细节
数据复用.在处理卷积层时,对输入数据进行Im2col 操作将在内存占用和带宽方面带来不菲的开销.例如,当卷积核步幅为1 时,与原始输入数据相比,转换后的输入矩阵消耗的内存约为原始的K×K倍.为了保留Im2col操作带来的好处,同时减少额外的开销,我们实现了片上Im2col 缓冲区,并根据地址在片上对切片数据进行数据重排和展开.设置Im2col 缓冲区可以有效地增加数据复用,虽然并未减少输入数据的访问次数,但使用开销较小的片上访问代替了开销大的片外访问,从而大大减少了该操作造成的额外的数据访问开销和外部带宽压力.
数据量化.传统上,无论是CNN 的训练阶段还是预测阶段,其数据类型均采用32 位单精度浮点数,这主要是因为它是现代GPU 的标准数据格式.但研究发现,CNN 对有限的数值精度具有固有的鲁棒性,在预测阶段使用浮点计算并不是必须的.通过重训练和特定的微调手段,采用定点数进行预测造成的精度损失可以忽略不计(小于1%)[22].对于许多CNN 来说,甚至8 位位宽就可以达到足够的精度.之所以采取量化操作,是因为权重和激活的低位宽表示形式有助于避免昂贵的浮点计算,同时显著减少带宽需求和内存占用.DianNao[11]中显示,在台积电65nm 工艺条件下,实现32 位乘法器的面积和功耗要比16 位乘法器的功耗高一个数量级.在这种权衡之下,本文中矩阵单元的所有计算核心均采用16 位定点数.
5 实验及结果
为了验证所提出的专用指令的有效性,我们在FPGA 平台上构建了包含该指令集扩展的基于RISC-V 架构的处理器核.在此基础上,使用AlexNet、VGG16 两种不同规模的卷积神经网络进行评测,并将该原型系统与Cambricon、CPU、GPU 和其他FPGA 加速器进行对比分析.
5.1 实验方法
(1)原型系统的FPGA 实现
我们使用ZC702 开发板作为实验平台,该平台为嵌入式FPGA 平台,其中,包含了一块XC7Z020 FPGA 芯片和1GB DDR3 板载内存,可提供4.2GB/s 的片外数据存取带宽.RISC-V 基础内核及矩阵单元的控制使用硬件描述语言Verilog 来完成,矩阵单元中的子计算单元设计则通过Xilinx Vivado HLS 2017.4 高层次综合工具完成,完整的硬件工程通过Xilinx Vivado 2017.4 集成开发环境进行综合和实现.
(2)CPU 测试基准
我们使用Caffe 深度学习框架(CPU-only)在CPU 平台上部署了两种目标网络模型.CPU 配置为Intel i7-4790K,其中包含了4 物理核心,最大线程数为8,工作频率为4GHz,并配有16GB DDR3 内存.
(3)GPU 测试基准
GPU 版本的测试仍然通过Caffe 深度学习框架(GPU-only)并通过CuDNN5.1 加速库在GPU 平台上部署两种目标网络模型.GPU 配置为NVIDIA Tesla K40C,其最大可支持2 880 个硬件线程,工作频率为745~875MHz,并配有12GB GDDR5 显存.
5.2 实验结果
在本节中,我们首先报告了原型系统在FPGA 平台上的资源消耗和功耗,然后围绕代码密度、性能及能效3个方面将该设计与Cambricon、CPU、GPU 以及以往基于FPGA 的加速器进行对比分析.
通过查看原型系统在Vivado 工具中的部署报告,我们获得了其在目标平台的各项资源消耗以及FPGA 的功耗,见表2.
(1)与Cambricon、CPU、GPU 平台的代码密度、性能及能效对比
代码密度.本文提出的专用指令不仅适用于加速CNN 应用,而且还为具有类似计算模式的其他深度学习算法(如MLPs)提供支持.通过使用RV-CNN、C 和CUDA-C 实现流行的CNN 模型并测量其代码长度,我们对比了RV-CNN 指令与基础RV32、ARM、x86 和GPU 的代码密度,结果如图11 所示,其中,以RV-CNN 指令集实现的代码长度为基准.可见,相比于原本的RV32(IMF)指令集,扩展RV-CNN 后代码长度减少了10.10 倍.相比于GPU、x86 与ARM 指令集,RV-CNN 的代码长度分别减少了1.95 倍、8.91 倍和10.97 倍.以x86 指令的代码长度为基准,RV-CNN 的代码长度相比于Cambricon 减少了1.51 倍.
性能及能效.图12 展示了在两种神经网络(AlexNet 和VGG16)的推理过程测试下,该设计与CPU 和GPU的性能、能效对比,其中,所有数值均可归一化到CPU 的实验结果上.可见,在Xilinx ZC702 平台上,该设计在执行两种网络的性能上均优于CPU,分别达到2.64 倍和4.23 倍的加速效果.但是由于该平台是嵌入式平台,用于计算的硬件资源DSP(使用91%)成为主要的性能瓶颈,因此在执行两种网络的性能上均落后于GPU.在能效方面,以每瓦特性能(GOPS/w)为基准,该设计在AlexNet 和VGG-16 的推理上,相较于CPU 分别提升了101.49 倍和167.62 倍;相较于GPU 分别提升了1.06 倍和1.40 倍.由于Cambricon 加速器为ASIC 设计,因此我们这里对比了性能密度(op/multiplier/cycle),即每周期乘法器完成的操作数.以GPU 的测试数据为基准,RV-CNN 相比于Cambricon 有1.16 倍的提升.
(2)与其他FPGA 加速器的对比
表3 列出了本设计与已有的典型FPGA 加速器的对比结果.由于不同的工作采用了不同的量化策略和不同的硬件进行部署,因此很难选择出一种有效且精确的比较方法.若以每秒千兆操作数(GOPS)作为性能评估标准,以前的工作可以实现比我们更好的性能.但是,更高的性能背后是更多的资源消耗,例如DSP 和LUT 资源,因而功耗也会相应增加.若以每瓦特的性能(GOPS/w)作为能效评估标准,与以往的加速器相比,我们的设计在保持灵活性下仍具有较高的能效.

Fig.11 The reduction of code length against Cambricon,GPU,x86,RV32,and ARM图11 RV-CNN 相对于Cambricon、GPU、x86、RV32 以及ARM 的代码长度减少
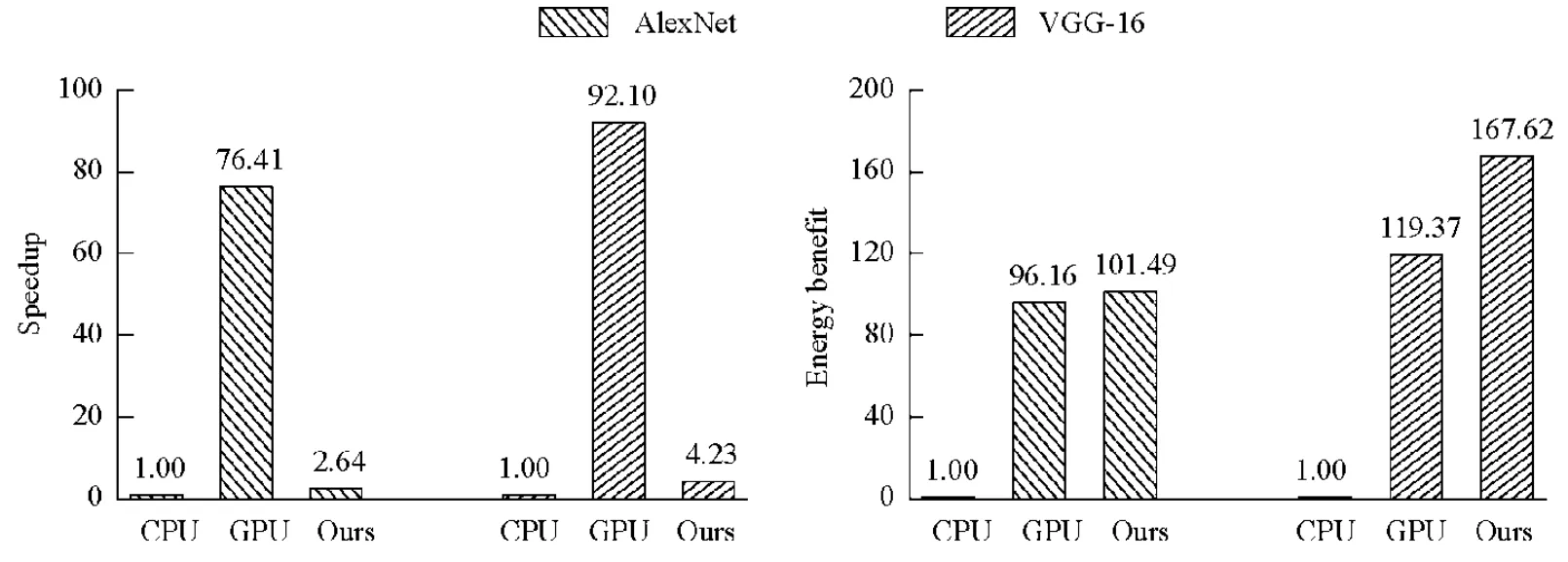
Fig.12 Performance and energy efficiency comparison between prototype system and CPU and GPU图12 原型系统与CPU、GPU 的性能、能效对比
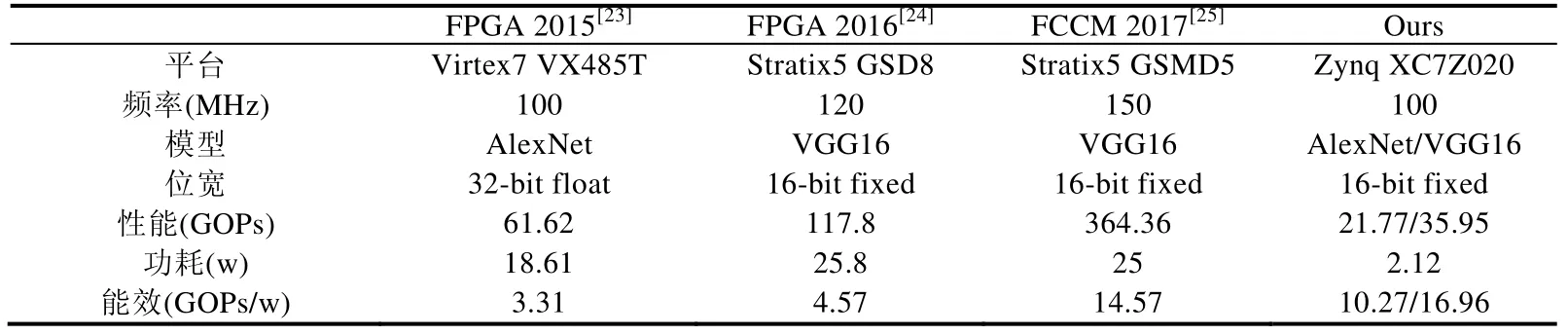
Table 3 Comparison of the prototype system and previous FPGA-based accelerator deployment表3 原型系统与以往基于FPGA 的加速器部署对比
6 结束语
CNN 在图像识别、目标检测领域的广泛应用使其性能至关重要.本文通过分析典型CNN 的计算模式,提出了一种高效且易于实现的专用指令集RV-CNN,其包含了10 条粗粒度的矩阵指令,可以灵活地为典型CNN 模型推理过程提供支持.在此基础上,我们介绍了CNN 模型描述文件到RV-CNN 指令的映射过程.随后通过定性分析,从不同方面将RV-CNN 与典型专用指令集进行比较.在指令实现方面,我们将该指令集扩展进了基于开源架构RISC-V 的处理器核,并以相对紧耦合的方式将对应的矩阵单元嵌入经典的5 级流水线中.最后,本设计在Xilinx ZC702 平台对上进行综合实现,并以典型的神经网络进行测试.结果显示,相比于Intel i7-4790K 处理器和Tesla k40c GPU,该原型系统具有最高的能效和代码密度.此外,与先前的加速器相比,该原型系统在保持灵活性的同时也展现了不错的能效.
目前新型CNN 网络层出不穷,还需考虑对其中诸如深度可分离卷积等操作进行指令优化以提高执行效率.此外,扩展指令的设计与实现应针对RISC-V 特点做出协同优化.最后,根据模型及硬件信息执行的代码映射过程还未自动化,未来,计划在以上方面加以改进.
