基于联合注意力机制的篇章级机器翻译
2019-12-30李京谕
李京谕,冯 洋
(1. 中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190;2. 中国科学院大学,北京 100049)
0 引言
神经机器翻译(neural machine translation, NMT)是目前主流的一种机器翻译建模方法[1-3],利用神经网络搭建翻译模型,并采用端到端(end-to-End)的方式进行优化。神经机器翻译提出至今,主要的关注点都在于句子级的翻译,即给定一个段落,翻译模型逐句进行翻译,句子与句子之间是相互独立的,这忽略了篇章上下文信息在翻译过程中的影响。一方面,在翻译一个完整的段落时,句子与句子之间需要保持一致和连贯,如果忽略篇章上下文的信息,则可能造成语义不连贯、语句不通顺的现象。另一方面,篇章上下文信息可以提供给句子一些辅助信息,在翻译的过程中减少句子存在的歧义问题。
神经机器翻译中根据注意力机制对源语言句子中的所有词语生成对齐概率,这种对所有词语进行计算的方式被称为“软关注”(soft attention)。在篇章级别的机器翻译中,篇章中的上下文信息有篇幅长、信息量多的特点,但在实际情况下,对翻译句子有帮助的篇章信息往往十分有限。在篇章信息存在大量冗余的情况下,采用传统的注意力机制在篇章机器翻译中很难从中提取对翻译有实际帮助的信息,这在篇章机器翻译中是一个不可忽视的问题。针对篇章信息冗余的现象,本文提出一种“硬关注”(hard attention)的方式计算注意力,并应用在篇章机器翻译的任务上。“软关注”的方式计算注意力时,每个输入对应的隐状态都参与了权重计算,这种方法便于训练中梯度的反向传播。对应地,我们提出在对篇章信息进行注意力计算时,只赋予0 和1 这两种权重,这也使得模型难以进行梯度更新。因此,我们在篇章翻译中通过强化学习[4]对硬关注模型梯度更新。在这里,引入强化学习有两个目的。其一是由于硬关注机制在离散的信号中梯度无法回传。通过强化学习的方法,我们可以获得注意力机制的奖励信号,从而对模型进行梯度更新。其二是由于求解注意力本身是一个无监督、无标签的问题,所以无法采用有监督的任务中神经网络的损失函数对注意力进行建模,而强化学习的方法可以解决这个问题。
本文提出了一种联合注意力机制,将硬关注和软关注两种注意力机制相结合,共同在篇章级机器翻译模型中对篇章上下文建模。联合注意力机制的关键思想是通过“hard”的方法筛选出对翻译当前句子有帮助的部分篇章上下文的相关状态,在翻译的每一步对候选状态用“soft”的方式进一步提取篇章信息,通过两种注意力模型结合的方式得到每一步的篇章上下文的向量表示。利用在原始的神经机器翻译模型中融入篇章信息,构成一个针对篇章数据的神经机器翻译模型。在两个不同领域数据集上的实验表明,通过联合注意力机制引入篇章信息的方法对机器翻译模型的性能有明显的提升。
1 相关研究
注意力机制被提出以来,已广泛应用到了包括自然语言处理在内的许多研究领域。虽然注意力机制最初是被用在机器翻译领域,但随后在各种任务上都占有一席之地,针对注意力的改进也一直是研究的热点。在机器翻译中,许多研究针对注意力机制提出优化和改进。针对上下文信息较长的情况下注意力机制对齐困难的现象,Luong等[5]提出了局部注意力(local attention)机制,在计算注意力寻找源端对齐信息的时候,局部注意力仅对一个窗口范围内的词进行分布式表示,而不是对整个句子的所有源端表示做加权求和,通过一个位置对齐参数计算当前时刻对应注意力的位置,然后对一个固定大小的窗口范围内所有的隐状态进行权重计算。Vaswani等[3]提出的自注意力(self-attention)和多头注意力(multi-head attention)也是对注意力机制的改进形式。
近年来,篇章级机器翻译逐渐成为机器翻译领域里的一个研究热点。Wang等[6]首先尝试在神经机器翻译模型中引入篇章信息,在RNNSearch 模型的基础上利用层次化的循环神经网络建模篇章信息,采用两个级别的RNN 分别对词向量和句子向量进行编码,得到代表整个篇章信息的向量表征。Jean等[7]在RNNSearch模型中加入一套额外的编码器和注意力机制,将篇章的前一个句子的信息引入神经机器翻译模型中。Tu等[8]为篇章信息设计了一个类似高速缓存(cache)的结构,Maruf等[9]采用额外的记忆单元(memory networks)存储篇章信息,以扩大对篇章信息的利用范围。在基于自注意力机制的Transformer 模型的基础上,Miculicich等[10]实现了基于多头注意力机制的层次化网络,分别对篇章进行词级别和句子级别的表示。Zhang等[11]在Transformer 模型中加入一个额外的篇章信息编码器,对篇章中源端的历史句子进行编码。Xiong等[12]提出了一种多轮解码方案,将篇章一致性作为强化学习的一个奖励函数来优化模型。
2 基线系统
其中,y 给定一个源端序列x=(x1,x2,…,xI),I表示源端句子的长度。由于注意力机制在建模中丢失了时序信息,在Transformer中采用了一个Positional Encoding层拟合了位置编码函数来模拟词语序列的时序信息,如式(2)~式(3)所示。 通过词向量和Positional Encoding层相加的方式,可以得到源端语言句子x的向量表示Ex=[E(x1);…;E(xl)]∈Rdmodel×l,dmodel表示模型的隐层单元个数大小。 Transformer编码器由Nc层相同的网络结构构成,每一层都由一个多头注意力子层和一个前向神经网络子层组成。多头注意力模块对源语言输入序列之间的依赖关系建模,捕获源语言句子中的内部结构,编码器中第n层计算如式(4)所示。 其中,A(n)∈Rdmodel×l表示第n层多头注意力模块的隐状态,H(n-1)表示第n-1层编码器的隐状态。当n=1时,第一层编码器的输入为H(0)=Ex。MultiHead(Q,K,V)表示多头注意力函数,将输入映射到h个不同的子空间进行注意力的计算,这里Q=K=V用作计算自注意力。由于Transformer模型使用深层次的网络结构,在每两个子层之间都采用残差结构(Add)[13]和对层的规范化(LayerNorm)[14]来提升模型的能力,为简便起见,后文在书写中省略这一过程,如式(5)所示。 第二个子层是前馈网络层FFN(·),加强编码器每个位置的表示能力。形式如式(6)所示。 其中,W1∈Rdmodel×dff、W2∈Rdff×dmodel分别表示可训练的参数矩阵。 对目标端序列y=(y1,y2,…,yJ),J表示目标端句子的长度,通过目标端的词向量和Positional Encoding层,得到的向量表示Ey=[E(y1),…,E(yJ)]∈Rdmodel×J。 解码器由Nc层相同的网络结构构成,每一层都由两个多头注意力子层和一个前馈网络子层组成,如式(8)~式(9)所示。 第一个多头注意力子层计算自注意力,对目标端序列之间的依赖关系建模。解码器的第一层输入为S(0)=Ey。第二个多头注意力子层用于建模目标语言与源端语言之间的依赖关系,多头注意力的输入为编码器最顶层的隐状态(K=V)。最后通过前馈网络子层,加强解码器的表示能力,如式(10)所示。 其中,S(n)∈Rdmodel×J为第n层解码器的隐状态(n=1,…,Nc)。 将解码器顶层的隐状态S(Nc)=(s1,…,sJ)映射到目标端词表的空间,经过softmax函数计算得到对目标端的概率分布,对第j个位置,如式(11)所示。 其中,WO∈R|Vy|×dmodel是一个参数矩阵,Vy表示目标端词表,sj∈Rdmodel×1表示解码器顶层SNc第j个位置的隐状态。 (12) 其中,X 前人的研究工作中[6-7,11],由于目标端依次解码带来的误差累积问题,目标端的篇章信息Y (13) 我们提出的模型如图1所示,这里只示意了模型的编码器结构,模型的解码器与原始Transformer模型中相同,在图中没有给出具体的细节描述。联合注意力机制分为硬关注和软关注两个部分。其中,硬关注是对篇章上下文和源端句子之间的关系建模,相当于从上下文中选择一个子集,能够为翻译当前句子筛选出所有需要的篇章上下文的部分。软关注在源端句子的每一个位置对硬关注选择的集合进行更进一步的计算,从而动态地获得翻译不同位置时篇章信息的向量表示。 图1 基于联合注意力机制的编码器结构 其中,H(doc)∈Rdmodel×L为篇章上下文的向量表示,L表示篇章信息的长度。 联合注意力模型中,根据源语言句子和篇章上下文的向量表示计算注意力,硬关注将注意力作为采样的概率来选择上下文的部分区域,可以用Attentionhard函数表示,如式(16)所示。 其中,D为联合注意力模型得到的篇章上下文的隐状态表示。最后将篇章信息和源语言编码融合起来作为编码器的最终表示,如式(18)所示。 图2 联合注意力中的硬关注模块 如图2所示,采用两个前向网络分别将Hcur和Hdoc映射到不同的空间内,如式(20)~式(21)所示。 其中,Wp∈R2×dmodel为参数矩阵,Pz(zl)表示对zl的概率分布。由此,可以求解整个标签序列z=z1,…,zL的概率,如式(24)所示。 (24) 图3 联合注意力中的软关注模块和上下文门控单元 硬关注模块筛选出与翻译当前句子相关的向量集合,然而,不同的篇章上下文向量在翻译的每一个时间步的作用都占有不同的权重。因此,我们设计了软关注模块,如图3所示,计算上下文表示C和Hcur之间的依赖关系,从而得到翻译的每一个时间步中相关的篇章信息向量。 (25) di=FFN(MultiHead(qi,C,C)) (26) 其中,fq(·)是一个线性变换函数,qi是用于计算多头注意力的Q。MultiHead(·)表示多头注意力函数,FFN(·)表示一个前馈网络。 在翻译当前句的每个位置时,对篇章信息的依赖程度都不相同。因此,获得篇章上下文的向量表示后,通过一个门控单元(gate)[16]学习句子与和篇章信息之间的关联,动态地控制句子信息和篇章信息对翻译的影响,如图3所示。 其中,Wh、Wd分别表示参数矩阵。λi在经过sigmoid函数计算后输出在0到1之间,定义了篇章信息通过的程度。 在本文提出的篇章翻译模型中,参数可以分为两个部分: 硬关注模块的θr和其余所有部分的θs。 由于硬关注模块中存在离散的过程,其目标函数是不可微分的,对参数θr的优化采用策略梯度算法。可以认为硬关注模型为强化学习中的智能体,实际上是一个策略网络,其动作空间的大小为2,每一步可以执行选中或者未选中两种动作。智能体根据全局信号做出决策,在智能体执行一系列动作之后,收到一个环境中得到的反馈信号。这里,我们将翻译模型生成目标译文的翻译概率作为奖励,对待翻译的数据对(x,y)和对应的篇章上文X 参数θr的优化学习被建模为通过策略梯度方法(即REINFORCE算法)解决的强化学习问题。训练硬关注的总体目标是选择部分上下文的同时保留与翻译相关的信息,其目标函数是得到奖励函数的最大期望,通过翻译概率得到,如式(30)所示。 对其余参数θs,采用原始的端到端的方式直接通过反向传播来进行优化。使用交叉熵作为损失函数,其优化目标如式(31)所示。 硬关注模块的训练过程中将翻译模型输出的概率作为其奖励函数,而在翻译模型的其余参数θs的训练中,同样依赖于硬关注模块的输出。因此,参数θr和θs两个部分的优化是彼此依赖的,如何进行有效的训练是本文中的一大难点。 在实际的训练过程中,为了降低训练难度,采用预训练(pre-train)和交替训练(cross-train)的方式。首先基于最大似然估计的标准训练Transformer模型直至收敛,如式(32)所示。 这样,模型能具有相对完整的表示能力。在此基础上,对我们提出的模型采用交替训练的方式,对两个部分的参数分别进行训练,训练中需要把另一部分参数固定。对于θs的优化,硬关注模型生成完整的序列之后,才能得到在翻译中使用的篇章信息,从而通过翻译概率计算其奖励,因此在采用式更新中,通过蒙特卡洛搜索(Monte-Carlo search)的方式得到选择动作序列。对参数θs进行优化时,也需要通过硬关注生成完整的选择序列,采用柱搜索(beam search)的方法得到完整序列,与机器翻译中柱搜索方式略微不同之处在于,这里生成一个定长的决策序列z=(z1,…,zL),其长度与篇章上下文相同。由于硬关注模型的动作空间非常小(选择/不选择),这里柱搜索的窗口设置为2。 我们在中英机器翻译任务上验证提出的模型,分别使用了两个不同领域的篇章机器翻译语料训练模型,统计信息如表1所示。其中,TED演讲数据集(TED Talks),来自于IWSLT(international workshop on spoken language translation)国际口语机器翻译评测大赛2014年的评测活动(1)https://wit3.fbk.eu,数据集收录了TED大会中的演讲稿。我们使用dev2010作为开发集验证模型,tst2010—2013作为测试集检验模型最终的效果。第二个数据集是中英字幕数据集(TVSUB)[17],适用于研究多轮对话、篇章翻译等具有篇章上下文的任务,由影视剧的字幕汇编而成(2)数据来源于以下两个字幕网站: http://www.zimuzu.tv, http://assrt.net。。在测试集中,每一句原文都有三句对应的参考译文。 对于译文的质量评估,使用大小写不敏感的BLEU-4[18]作为评价指标,本文采用multi-bleu脚本进行计算。 表1 数据集统计信息 对训练数据,在汉语端使用ICTCLAS(3)http://ictclas.nlpir.org进行了分词预处理,英语端进行了词法预处理和小写化。针对神经翻译面对的词汇数据稀疏问题,在实验中分别采用词和字节对编码[19](byte pair encoding,BPE)作为基本的翻译单元。以词为翻译单元的实验,汉语端和英文端都采用30K的词表大小,在TED演讲数据集上分别覆盖98.6%和99.3%的源端和目标端文本,在TVSUB字幕数据集上分别覆盖98.2%和99.4%的源端和目标端文本。以字节对编码为翻译单元的实验,BPE单元的词汇表设置为16K,在两个数据集上的训练数据中文本覆盖率均为100%。 我们采用了Transformer Base模型的配置,词向量维度和注意力计算的隐层单元个数都是512,前馈网络的中间层单元为2 048,多头注意力的层数为8。为了避免过拟合,我们在模型中使用了Dropout方法,分别在编码器和解码器每一层的前馈网络上加入,Dropout的比率设置为0.1。参数的优化使用了批量的随机梯度下降方法,根据数据的长度对数据进行批处理,批处理的大小限制为1 024个token以内,学习率采用自适应的Adam算法[20]进行调整学习(σ=10-9,β1=0.9,β2=0.98)。 我们使用与基线系统相同的预热(warm up)和衰减(decay)策略,设置warm-up的步长为4 000。 在模型测试的过程中,柱搜索的窗口大小设置为10,为了减小候选译文的长度对序列得分的影响,设置长度惩罚(length penalty)的系数α=0.6对候选译文进行重排序,选择得分最大的作为最终输出的译文。 实验结果参照表2,展示了TED Talks和TVSUB两个中英文数据集上的BLEU-4指标结果。 表2 不同数据集上的BLEU-4指标 对比基于联合注意力机制的篇章机器翻译模型和基线系统Transformer模型,可以看出该文提出的模型在TED Talks数据集上BLEU值提升了+0.80,在TVSUB数据集上提升了+0.49个BLEU。对数据分别采用字节对编码进行处理后,我们的模型在TED Talks数据集和TVSUB数据集上比Transformer系统分别提升了+0.47和+0.36个BLEU,表明基于联合注意力机制的篇章机器翻译模型在针对不同粒度的语言表示方法上都能够提升机器翻译模型的效果。 本文提出的模型和Transformer模型中采用字节对编码(BPE)的方式对语料进行处理,翻译模型的性能均有提升,这说明字节对编码可以增加词汇表覆盖率,改善神经机器翻译中数据稀疏的问题。在模型中采用字节对编码处理后,本文提出模型的提升没有对原始Transformer模型的提升明显,表明模型融合篇章信息后提升了原始Transformer模型的表达能力,与字节对编码缓解词汇数据稀疏问题有所重合。 表3列出的实验结果为TED数据集上各系统的BLEU-4指标。从中可以看出,基于RNNSearch的三个篇章级机器翻译系统[6-8]BLEU值明显低于基于Transformer模型改进的篇章级翻译系统[10]。 表3 与前人工作的实验结果对比 我们的模型在TED数据集上输出的译文BLEU值最高,在引入篇章信息的机器翻译模型中超过了所有现有系统的表现,达到了最优效果。在这里,通过与这些篇章级机器翻译系统的性能对比,进一步证明了本文提出的基于联合注意力机制的篇章机器翻译模型的有效性。 在实验所用的TED和TVSUB数据集中,一个完整的篇章通常由上百个句子构成,将所有的句子都作为篇章信息在建模的过程中对计算能力的要求非常高,而且在翻译的过程中考虑所有的篇章信息也并不符合直觉。因此,我们需要探究篇章信息的长度对实验结果的影响。为了探索篇章信息的长度对所提出模型的影响,我们对不同长度的篇章信息做对比实验。这里,篇章信息的长度指篇章翻译模型中建模篇章上下文句子的数量。 表4列出结果为TED数据集上不同篇章信息长度下翻译模型的BLEU-4指标。可以看出,在Transformer模型中引入篇章信息后,翻译模型的性能均有提升。当加入篇章句子数量为1时,模型的性能明显低于篇章长度大的系统。随着篇章长度的增加,翻译的性能基本稳定,加入句子数量为3和5的两个系统基本没有差异。当句子数量为7时,系统的性能相比句子数量为3和5的系统略微有下降。总体上,我们的模型可以在篇章信息较长的情况下依然维持比较好的性能,证明了我们的方法处理大量冗余信息的有效性。 表4 不同篇章长度下的实验结果 针对篇章级机器翻译中篇幅长、信息冗余的问题,本文提出了一种将硬关注和软关注两种注意力相结合的联合注意力机制对篇章信息建模,并将其应用在篇章级别的神经机器翻译模型中。在两个不同领域的公开数据集上的实验结果表明,基于联合注意力机制引入篇章信息的方法对机器翻译模型的翻译效果均有明显的提升。不同篇章长度下的实验结果表明,本文提出的模型在处理长篇章时依然能维持其翻译的性能,证明本文提出的联合注意力机制可以有效地处理冗余的篇章信息。 在篇章结构的数据中,远距离的语义依赖关系是广泛存在的。如何挖掘篇章中更多潜在语义信息以及语句之间的递进关系,为篇章翻译提供更加准确的语境信息,是一个值得我们在未来的工作中进一步探索的问题。2.1 编码器

2.2 解码器
3 基于联合注意力的篇章机器翻译
3.1 问题定义






3.2 基于强化学习的硬关注模块




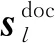



3.3 基于多头注意力的软关注模块


3.4 上下文门控单元

3.5 模型的训练
4 实验与分析
4.1 实验数据和指标

4.2 实验细节
4.3 主要实验结果

4.4 与现有工作的对比

4.5 篇章长度的影响

5 总结与展望
