基于区域集中存储的CCN路由策略
2019-12-26李兆玉李朋明朱红梅
李兆玉,陈 翔,李朋明, 朱红梅
(重庆邮电大学 移动通信技术重点实验室,重庆 400065)
0 前 言
互联网的发展速度远远超出了人们最初的预测[1],传统“主机到主机”的通信方式无法满足未来网络对海量内容获取与分发的主要需求。为此,研究者们提出以信息为中心(information centric network, ICN)[2]的未来网络架构。基于ICN思想目前有DONA[3],PURSUIT[4],NetInf[5]和CCN[6]4种典型项目方案。其中,内容中心网络(content-centric networking, CCN)被认为是主流的可行方案之一。CCN区别IP网络的核心特征是以“内容”为中心,基于对内容的统一命名进行定位、路由和传输;另外网络内置缓存[7]减轻网络负载,加速内容分发,将网络打造成内容存储、传输和服务的一体化平台。
内置存储使得网络中缓存有大量内容副本,怎样引导兴趣包的转发,充分发挥路由的优势,寻找到最佳路径快速获取网络副本中的临近资源,提高网内资源利用率,减少用户请求时延,整体提高网络性能,是近几年来CCN研究的热点。
CCN默认采用全转发策略(flooding forwarding, FF),路由节点将兴趣包从所有匹配的转发信息库(forwarding information base, FIB)端口发出。多端口发送有利于网络中动态缓存资源的获取,但是兴趣包泛洪转发及后续多路径的大量返回数据会造成较大冗余流量。随机转发策略(random forwarding, RF)让节点从匹配的FIB端口中随机选择一个进行转发,能有效降低网内冗余流量,但服务质量很难保证。为此最佳转发策略(shortest path forwarding, SPF)采用Dijkstra算法,选取一条从用户到内容源服务器的最短路径转发。后续改进的蚁群转发策略[8]通过发送嗅探报文,选取一个最优端口收敛出一条最佳路径(如时延最短或整体负载最低等),但收敛速度较慢,大量探测包造成冗余的同时增大节点处理负担。文献[9]提出一种网络状态感知的路由机制,通过收集网络状态信息更新各端口的转发概率,实现最优路径选择。文献[10]提出基于CCN的路由优化策略机制,建立控制节点掌握拓扑和资源状况,利用蚁群算法优化传输路径,提高路由效率。
以上策略都在着力实现用户到内容源服务器的最佳路由,只针对持久稳定的内容源建立了路由条目,而缺少对网内内容副本的关注。文献[11]分析了缓存利用的可行性和重要性,强调通过与节点暂态缓存的结合,使路由效益最大化。文献[12]提出一种结合节点缓存的快捷路由策略(short-cut routing, SCR),通过感知邻居内容副本以获取内容数据。文献[13]提出一种基于差异化缓存通告的混合路由机制,采用建立局部吸引辐射场的方式,实现就近缓存的获取。文献[14]提出一种基于SDN的路由机制,通过SDN全局控制器获取最佳缓存,选取最短路径转发。这些策略考虑了缓存资源的利用,但大多具有较高的算法复杂度。
基于现有研究中存在的问题,本文提出一种轻量级的基于区域集中存储的路由策略(regional centralized storage routing strategy, RCSRS)。本策略提出区域集中存储思想,仅由选取的区域核心节点进行集中存储,以减少普通节点内容查找与缓存操作开销;并设计了基于区域集中存储的路由机制,快速高效地引导请求至核心节点,减少冗余流量,提升缓存系统性能和用户体验。
1 区域集中存储分析
CCN中每个路由节点都具有CS表项,在兴趣包命中路径上的所有节点都会缓存返回的数据,产生大量冗余内容,浪费存储空间的同时降低了缓存利用率。较低的缓存利用率意味着大量节点进行了低效的内容查找和缓存处理开销,影响着网络性能的发挥。为此,本文提出基于区域集中存储的思想,在减少网络开销前提下,保证缓存系统性能。并在图1拓扑中仿真验证集中存储理论。

图1 集中存储验证拓扑
在图1拓扑中,普遍存储时设置8个深色的路由节点缓存容量相同均为M,集中存储时选取节点B进行缓存且容量为τM(τ∈Ν*),其他节点无存储功能。图2验证了M为50,Zipf参数分别为0.7和0.9时,集中存储节点容量与普遍存储单个节点容量比值τ对系统性能的影响(其他参数见第3节)。从图2a中明显看出,集中存储容量仅需2.5M时就可以达到更高的缓存命中率,可以节约5.5M的存储资源和7个节点的内容查找和缓存操作开销。由图2b可以看出,在集中存储需要5M以上才能达到理想的平均获取跳数,但网络设备的线速执行要求限制着节点容量的无限增加,一味扩大缓存容量,也失去理论研究的意义。因此,后文对集中存储节点的选取和路由策略进行设计,以改善网络性能。

图2 性能对比分析
2 RCSRS策略
2.1 核心节点选取
在复杂网络拓扑中,需要选择更合适的缓存节点位置,以便能服务更多的兴趣包。由于大型网络拓扑下不利于单个缓存节点选取,且单个缓存节点也难以满足大规模网络的数据需求,因此,将网络参照OSPF分成几个自治区域[15],然后,展开核心节点的选取。
假设复杂网络由大量节点和其连接边组成,可以用图G=(V,E)表示,用V={v1,v2,…,vn)}表示G的n个顶点集合,E={e1,e2,…,en}表示G的m条边的集合。在实际网络中,由于不区分节点的出度和入度,一般用无向图来表示。依据区域的拓扑结构特征,选取能反映路由节点对网络用户服务能力的参数指标,以节点度中心性、紧密中心性、介数中心性和凝聚度作为区域核心节点位置选取的区域中心性度量指标。
定义1度中心性:表示与此节点直接相连的链路条数。值越大与其他节点关联度越高。其计算公式为
(1)

定义2紧密中心性:表示节点与网络中其他节点的最短跳数,值越大该节点对网络的影响越大。其计算公式为
(2)
(2)式中,hij为区域中节点i到节点j的最短跳数。
定义3介数中心性:表示网络中经过该节点的最短路径数与所有最短路径总数之比,值越大节点重要度越高。其计算公式为
(3)
(3)式中:∂ik表示节点j到节点k之间的所有路径数;∂ik(i)为节点j到k间经过节点i的路径条数。
定义4凝聚度:表示收缩节点的网络节点数与网络中所有节点对的平均路径长度之积的倒数。表明该节点维护网络连通的能力,值越大节点越重要。其计算公式为
(4)
(4)式中:V-i为删除节点i后本区域的集合;θjk为从节点j到节点k的最短路径所包含的边数。
加入凝聚度这一破坏性因子,是由于区域集中存储需要更多地考虑选取的核心节点对网络拓扑的敏感性,反映节点对此网络的容错抗毁能力。根据指标在整体评价中的相对重要程度,设4个度量值所占权重分别为μ,β,λ和W(i),计算节点的区域中心度W(i)公式为
W(i)=μB(i)+βC(i)+λD(i)+γS(i)
(5)
(5)式中,0≤μ,β,λ,γ≤1,且μ+β+λ+γ=1。
W(i)最大的节点即为此区域核心节点,负责集中存储资源,网络效果如图3。除负责集中存储的核心节点(深色)外,普通节点无缓存功能,即不进行内容查找与缓存处理。
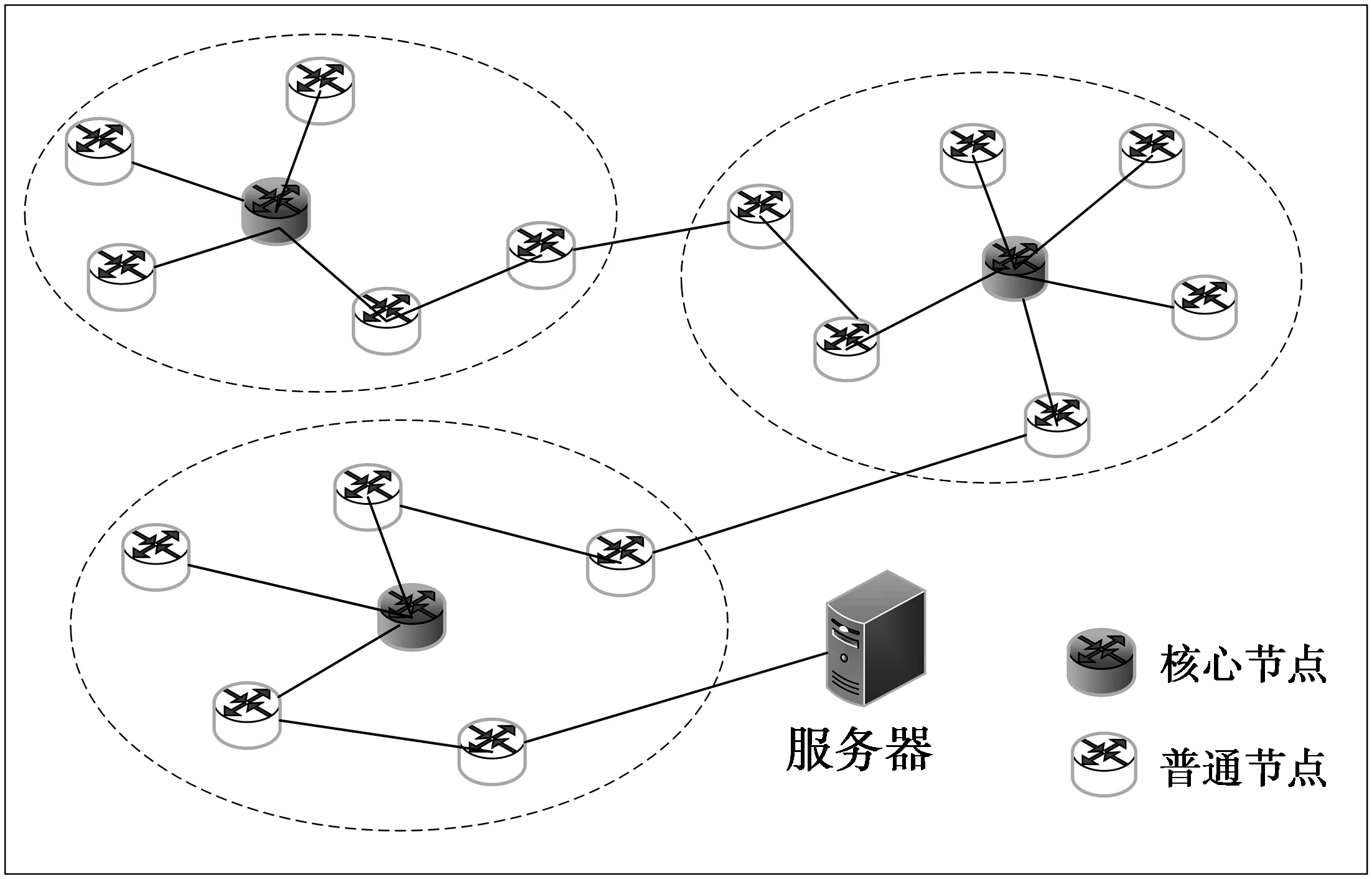
图3 区域系统模型
2.2 路由机制实现
基于集中存储思想选取区域核心节点后,因为核心节点非一定是主干道上所有兴趣包的必经节点,为使兴趣包能直接定位识别本区域核心节点进行缓存查找,减少路由跳数及转发时延,进一步优化网络性能,对路由策略进行了设计。
修改后兴趣包格式如图4。策略在兴趣包中增添区域节点标识表字段(core node, CN)以标识本域的核心节点。初始时CN字段值为空,当开始路由转发时,由与用户直接相连的接入节点添入本区域核心节点标识,接入节点保存本区域唯一的核心节点标识。同时为了使兴趣包能快速路由到本区域核心节点进行缓存资源的查找,而不是被盲目转发,在各普通路由节点保留待定兴趣表(pending interest table, PIT)以及FIB结构的基础上,添加一个路由表项(routing table, RT)如图5。此路由表项存储的是此路由节点到核心节点的最短下一跳转发端口号,以使路由节点能根据兴趣包中的节点标识按本节点RT表项快速路由到区域核心节点进行缓存查找。为减小链路故障造成的影响,每个RT项保存2个到核心节点的下一跳端口,默认最短路径中的下一跳端口为保留的第一端口。

图4修改后兴趣包格式
Fig.4Modifiedinterestpacketformat
2.3 路由策略过程描述
当运行本路由机制时,内容请求过程的兴趣包处理流程如下。
1)与用户直接相连的接入节点接收到兴趣包后首先查找PIT,如果已存有相同的内容请求表项,则丢弃兴趣包,并在相应表项添加此兴趣包的进入端口号,等待相应内容返回,否则执行2);
2)由接入节点在兴趣包中的CN字段写入本区域的核心节点标识(初始状态下兴趣包中的CN字段为空),并根据添加的本节点RT进行下一跳转发;
3) 当下一跳为普通节点时,首先查找PIT,有则添加兴趣包进入端口号,没有则根据兴趣包中的CN标识按本节点RT快速路由到下一跳;
4)当下一跳为核心节点时,首先查找内容存储器(content store, CS),有则返回数据,没有则查找PIT中是否有相应条目,有则添加进入端口,无则进行FIB最长前缀匹配到内容源服务器获取内容,同时将区域核心节点标识项置为空;
5)后续节点对已通过区域核心节点的兴趣包,首先查找PIT,有则添加兴趣包进入端口号,否则根据FIB最长前缀匹配到内容源服务器获取内容(此时区域节点标识项已为空,非依据路由表项路由);
6)当到达下一个域时,则重复上述处理步骤,直到在某一区域核心节点命中或是内容源服务器命中。
兴趣包命中后,相应数据包返回时根据各节点PIT匹配转发直到发送给请求者,沿途经过的核心节点执行默认缓存策略。
此策略设计仅核心节点进行内容查询与缓存操作,大大减少网络开销。以较少存储资源实现了更高的缓存系统性能。
3 仿真实现
3.1 实验设置
本文采用基于NS-3的开源ndnSIM[16]平台,对提出的策略进行仿真。实验采用GT-ITM下的locality模型,随机生成32个路由节点,其中设置8个内容请求者,1个原始内容服务器,将拓扑划分为平均16个CCN节点组成的2个区域。内容总数为N=4 000,传统路由节点CS设为50,核心节点的缓存容量设置为传统单个路由节点容量的4倍,每个内容大小相等且为10 KByte,网络带宽为100 Mbit/s,链路时延设置为10 ms。内容请求到达服从V=20个/s的泊松过程,即请求时间服从指数分布,内容请求概率服从Zipf分布[17],仿真时间为200 s,统计周期为10 s。在取节点权重时,由于破坏性因子凝聚度属于网络中少量突发因素,所以为减小凝聚度变化对节点选取的影响,将其权重系数设置的较小,而其他指标为给定拓扑下计算的恒定度量值,将增大其权重系数。通过多次仿真发现,当μ=β=λ=0.3,γ=0.1时仿真性能最好。路由节点初始缓存状态为空,缓存策略采用处处缓存,缓存替换策略默认为LFU。
3.2 性能评价指标
将本策略与常见的4种路由机制:RF,SPF,SCR,SoCCoR进行对比分析,从以下几个指标进行比较和分析。
1)平均命中率(average cache hit ratio, ACHR)。定义为被缓存节点响应的兴趣包总数与各路由节点接收兴趣包总数的比值,体现了对源服务器负载的改善程度,ACHR越高,策略的效果越好。
2)平均跳数减少率(average hop reduction ratio, AHRR)。定义为相比于采用某种路由策略后,部分内容从中间节点获取响应,平均命中跳数减少的程度,体现了对系统带宽的节省能力,AHRR越大,策略的效果越好。
3)平均请求时延(average request delay, ARD)。定义为节点从发出兴趣包到收到应答数据包之间的平均延迟,体现了对用户体验的提升效果,ARD越小,策略的效果越好。
3.3 结果与分析
3.3.1 平均命中率
图6给出了在不同条件下5种路由策略对应的命中率变化趋势。由图6a可以看出,随着Zipf参数增大,5种策略的命中率都随之增加,因为Zipf参数越大,对请求内容的集中程度越高,更有利于路由策略发挥作用,各种路由策略在平均命中率上都有明显的改善。由图6b看出,随着内容总量的增大,命中率呈下降趋势,因为内容总数的增加使内容的局部性特征相对减弱,因此,路由的效果也逐渐降低。RCSRS优势在于,其他4种策略路由节点内容相似性很高,SCR策略也只获取临近节点资源信息,在前面几跳无法命中时,后面几乎难以命中,只能在内容源服务器获取;而RCSRS设置的集中存储核心节点CS容量是其他路由策略单个节点的4倍,均为不重复资源能满足更多的兴趣包,使得平均命中率性能得到进一步提升。

图6 平均命中率比较
3.3.2 平均跳数减少率
图7给出了Zipf参数和内容总量变化对AHRR的影响。由图7看出,随着Zipf参数的增大,AHRR也不断增大,而随内容总量的增大却减小。这是由于随着Zipf参数的增大用户内容请求的相似性更高,网内缓存利用率更高,因此,AHRR增大。而随着内容总量的增大,用户请求的内容的范围和不确定性越大,对应的AHRR逐渐减小。RCSRS仍高于其他4种策略,因为其他4种策略有可能在前几跳命中,虽然请求近,但因为缓存容量关系能满足的请求包数量少,而选取的核心节点虽然不一定离用户最近,但是缓存容量大,综合而论,本文所提策略好于其他策略。
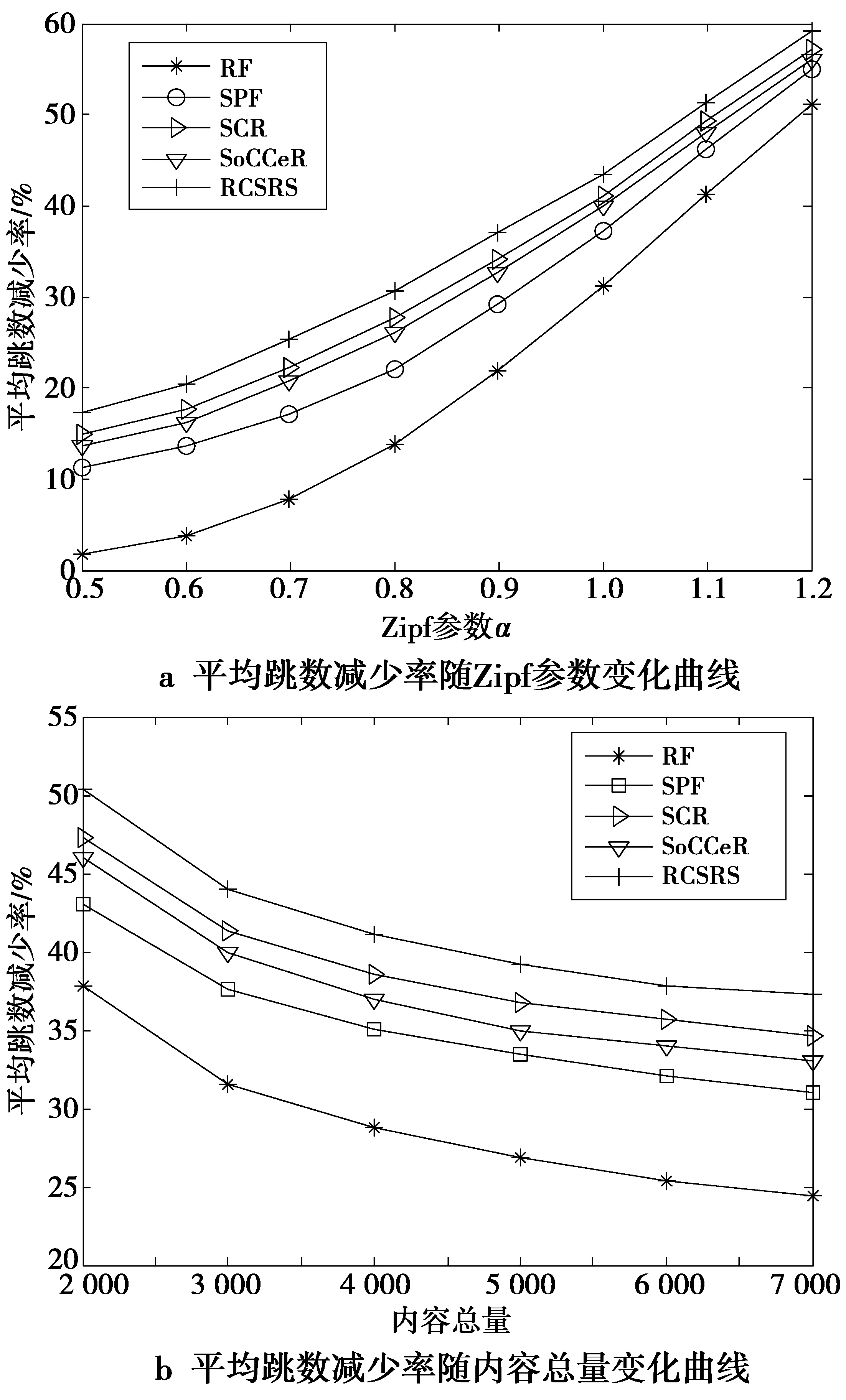
图7 平均跳数减少比较
3.3.3 平均请求时延
图8给出了Zipf参数和内容总量变化对ARD的影响。可以看出,随着Zipf参数α的增大,各路由策略的请求时延呈下降趋势,这是由于内容请求的集中性和局域性不断增强,更多的兴趣包被网内缓存满足,不必到源服务器获取资源,减少了请求时延。而随着内容总量增多,用户请求的内容更分散,更多请求需要到源服务器获取资源,增大了请求时延。而RCSRS有明显优势的原因是因为减少了非缓存节点的内容查找和部分节点进行FIB最长前缀匹配的时延。普通节点只负责将兴趣包高速路由到核心节点查找数据,且核心节点的缓存容量高于其他策略单个节点容量,能满足更多的兴趣包。

图8 平均请求时延比较
4 结 论
为了有效结合缓存资源提高路由效率,优化网络性能,提出了一种轻量级的基于区域集中存储的路由策略。提出区域集中存储思想,并设计了基于区域集中存储的路由策略。仿真证明RCSRS能用较少缓存资源实现更高的缓存系统性能,仅以核心节点进行内容查询与缓存操作减少网络开销。由于默认缓存策略限制着集中存储机制性能进一步提高。下一步研究,将考虑路由策略与缓存决策机制结合,进一步提高网络性能。
