基于分类算法的网络设备识别方法∗
2019-12-26皮寿熹李富合
皮寿熹 李富合 缪 磊 马 辰
(1.中国船舶工业综合技术经济研究院 北京 100081)(2.中国舰船研究院 北京 100101)
1 引言
随着物联网、IoT以及计算机网络技术的发展,越来越多的新型设备出现在网络中[2]。数量庞大、种类繁多的网络设备暴露出更多的网络安全问题,并给网络管理带来更为严峻的挑战。因此有必要提供一种方法来识别网络设备,用于统计和评估网络空间中设备的分布状况和存在的漏洞,为网络管理工作提供支撑。
目前识别网络设备类型的方法主要通过网络扫描技术来实现。网络扫描技术是指通过计算机网络获取目标主机的相关信息的技术。经过多年的发展,出现了ZMAP、NMAP等功能强大的网络扫描工具,它根据自身的数据和规则维持服务和操作系统等指纹库数据,用于判断网络主机身份信息。其中就包含部分主机的设备类型信息。但它没有专门的指纹库用于设备类型识别,因此该方法在准确度和可靠性上存在一定局限性。
基于“通过网络扫描获得的网络设备信息可以一定程度上确定网络设备类型”的假设,提出一种基于分类技术的网络设备识别方法,集中于解决网络设备类型识别不准确的问题。该方法从网络空间搜索引擎中获取网络设备信息,对网络设备信息进行特征提取,运用决策树、逻辑回归和朴素贝叶斯3种分类算法对网络设备数据进行训练,得到网络设备分类模型。
2 基于分类算法的网络设备识别
网络设备泛指所有连接到计算机网络中的物理设备,根据网络设备在计算机网络中扮演的角色和提供的功能,分为交换机、终端服务器等15种网络设备[3]。
2.1 网络设备数据采集
网络设备数据用于分类模型的训练过程。由于训练分类模型使用有监督的机器学习分类算法,因此网络设备数据需要带有设备类型标签。此外,为了保证分类模型的准确性,需要保证采集数量足够的样本数据。基于以上特点,使用网络空间搜索引擎Shodan采集网络设备数据。Shodan是世界上首个专门搜“主机”的搜索引擎,能够通过城市、国家、GPS坐标、设备类型、域名、操作系统及IP等信息来筛选主机信息。它包含大量的、较为精确的网络设备数据。
2.2 数据预处理
网络设备数据包括设备的操作系统、开放的端口、开放端口的Banner信息[4]、开放端口上提供的服务等数据项,数据中包括数字、文本、单词、HTML页面源码等。为了使用分类算法,需要对设备数据采集获得的数据进行处理,将之转化为特征数据。
数据预处理包括文本表示和特征提取[5]。文本表示的工作是将设备数据进行分词处理,将文本转化为单词数组;特征处理的工作是将设备数据中的所有单词进行统计分析,过滤掉与设备类型相关度较小的单词,它一方面它可以减小网络常用词对分类模型的影响,另一方面减小了数据样本的维度,减少了工作量。网络设备数据特征提取使用TF-IDF算法。
2.3 分类算法
在分类算法中,分类算法[6]面对一组已经分好类的训练数据集,从中学习如何分类未见过的数据。使用决策树、逻辑回归、朴素贝叶斯对样本数据进行训练。
2.3.1 决策树
决策树使用树形结构来指定决策与结果的序列。决策树的输入值可以是分类的或连续的。决策树的结构有测试点和分支点组成,其中分支表示所作出的决策[7]。没有下一集分支的节点叫做叶子节点。叶子节点返回类别标签。使用CHAID(Chi-squaredAutomatic Interaction Detector)算法构造决策树。CHAID算法的核心是卡方检验[8]。CHAID算法支持字符输入变量并支持多分类,并且具有较高的模型精确度,CHAID决策树的分支策略基于卡方检验。
卡方检验统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,卡方值越大,越不符合,偏差越小;卡方值就越小,越趋于符合;若量值完全相等时,卡方值就为0,表明理论值完全符合。它的计算公式为
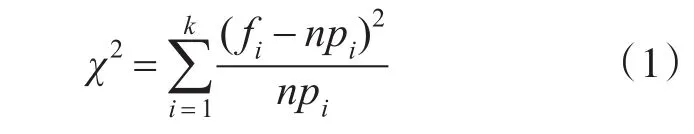
简化为极端情况来说明CHAID决策树的构造过程。讨论设备数据中是否包含camera与设备类型为webcam之间的关系。
这里以10031条数据为例,含有camera和设备类型之间的数据统计见表1。

表1 webcam设备分类与Banner中含有camera的数据统计
先做出假设:设备类型是否是webcam与Banner中是否含有camera没有关系。基于这个假设可以得到表2中的数据统计,括号中是假设成立时的取值。
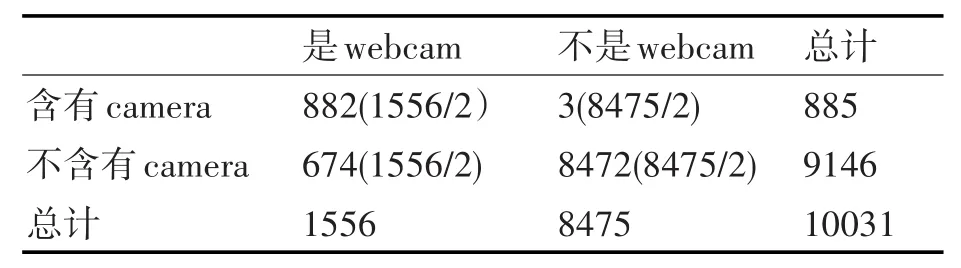
表2 设备类型分类判断(基于假设)
根据表2可以看出表格中的理论值与实际值是存在差距的,接下来的工作是验证这个差距是否可以推翻原假设。
计算使用卡方计算公式计算原假设的卡方值:
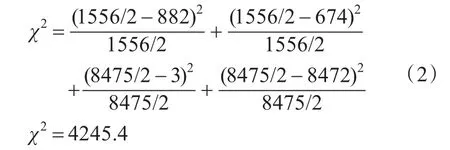
通过查找卡方表[9],自由度为1,显著性水平为0.05的卡方临界值为3.84,远远小于实验计算得到的卡方值。由此判定原假设不成立,由此可以得出Banner中是否含有camera与设备类型是否是webcam是有关系的。
2.3.2 逻辑回归
由于设备识别是一个多分类问题,因此使用多元逻辑回归算法。它作为线性回归问题的另一种形式,使用自变量的线性组合作为预测函数[10]。

这个表达式表示输入数据为xi时,输出为k的概率,其中βM,k是回归参数。在多元逻辑回归的解决方案中,借鉴二分类逻辑回归的思想,将多元逻辑回归看作一系列的二分类逻辑回归:对于K种分类结果,将第i种分类结果看作一类,将剩下的分类结果看成另一类。假设将第K种分类结果看成一类,则剩下的K-1种分类结果可以表示为如下形式:
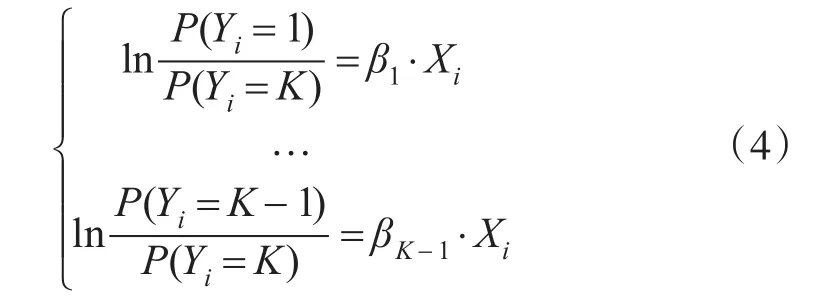
上式经过变换可以得到:

根据各类概率和为1的公式可知:

对于式(7)中的K-1个二分类模型中的模型参数使用最大后验估计来确定。
2.3.3 朴素贝叶斯
朴素贝叶斯[11]是一种按照概率的分类算法,它假设一个属性对给定类的影响独立于其他属性,即特征独立性假设。它基于贝叶斯定理:
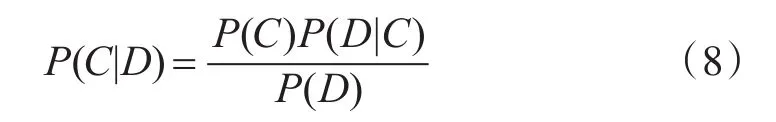
其 中 ,C∈{C1,C2,…,Ck} 表 示 设 备 类 型 ,D={w1,w2,…,wn}表示设备特征数据。P(C|D)称为后验概率,表示特征数据D属于C的概率。P(C)称为先验概率,表示C类样本数量占总样本数量的比例。
在式(8)中,P(D)是一个常数,因此P(C|D)正比于P(C)P(D|C):
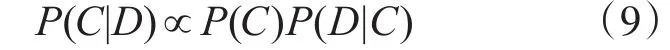
由此得到朴素贝叶斯分类公式:
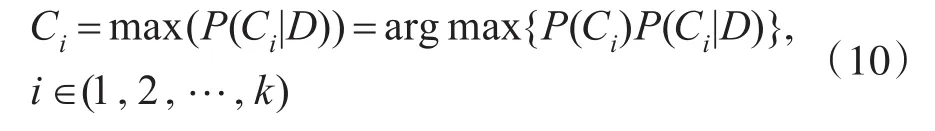
又根据D=(w1,w2,…,wn),并且属性之间是独立的,由此推导出:
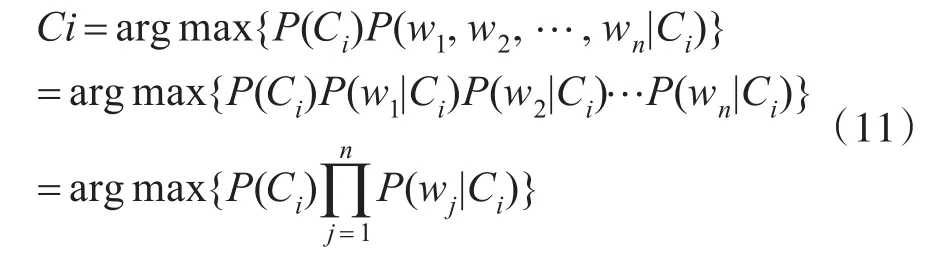
其中P(wj|Ci)是指特征词wj出现在Ci设备中的概率,可以从训练数据中通过计算得出,采用使用wj在Ci中的取值除以类别Ci中所有词的权重之和。得到式(12),weight(wj,Ci)是词wj在属于类别Ci的文本中的权重之和。
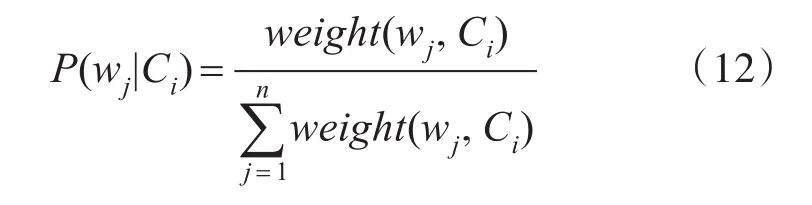
如果训练集中词wj在类别Ci中不存在,则P(wj|Ci)=0,这时另一类将会占据主导位置。特别的,如果在所有类别中都为0,则没有办法再进行分类。为此,使用拉普拉斯转换对计算公式进行调整。
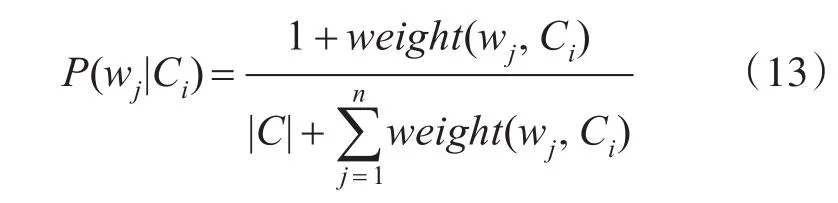
3 实验与分析
3.1 分类模型评价
为了评价分类模型的效果,需要制定评价分类模型性能的一些量化指标,网络设备识别结果的好坏的关键在于分类的精确度,精确度评价使用混淆矩阵[12]。
1)混淆矩阵
混淆矩阵是一种具有特定布局的表格,它用来可视化分类模型的性能。假设TP表示验证集中实际标注和分类模型预测都是类别C的样本数量;TN表示验证集中实际标注和分类模型预测都不是类别C的样本数量;FN表示验证集中实际标注是C,而分类模型预测值不是C的样本数量;FP表示验证集中实际标注不是C而分类模型预测为C的样本数量。
好的分类模型应当有较大的TP和TN值,较小的FP和FN值。表3为混淆矩阵的示例。

表3 混淆矩阵结构
2)精确度
分类模型对类别Ci的精确度计算公式为
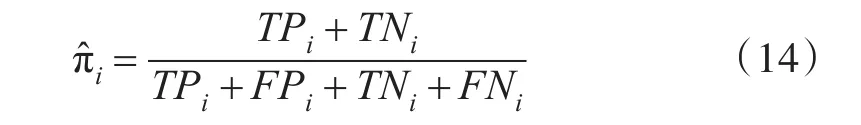
对于多分类,分类算法对所有样本类别的精确度计算公式为

其中n为设备类型数量,wi表示各个设备类型的特征数据占全部特征数据的比例。
3.2 分类模型结果
3.2.1 分类模型模型测试
针对于三种分类算法训练得到的分类模型,对分类模型在同一训练数据集和验证数据集上的分类结果分别进行统计,各分类模型的精确度如图1。

图1 不同分类模型精确度数据图
由图1可见,决策树训练出的分类模型在训练数据集合验证数据集中都有着相对较高的精确度。与之相比,逻辑回归算法得到的分类模型则有着较低的精确度,朴素贝叶斯分类模型虽然在训练数据集上有着很好的模拟结果,但在验证数据集上的精确度相对偏低。实验证明决策树分类模型具有较高的精确度。
3.2.2 分类模型准确性测试
分类模型的准确性是最关键的指标。为了验证基于决策树算法的网络设备分类模型性能,将训练特征数据的10%预留出来作为验证数据集,用它来评估决策树的分类效果。在测试中,分别使用5000条、10000条、20000条设备数据训练决策树模型,并在训练数据集中预留出10%的数据对决策树模型进行评估。表4是不同样本量下分类模型在训练数据中的精确度统计数据。
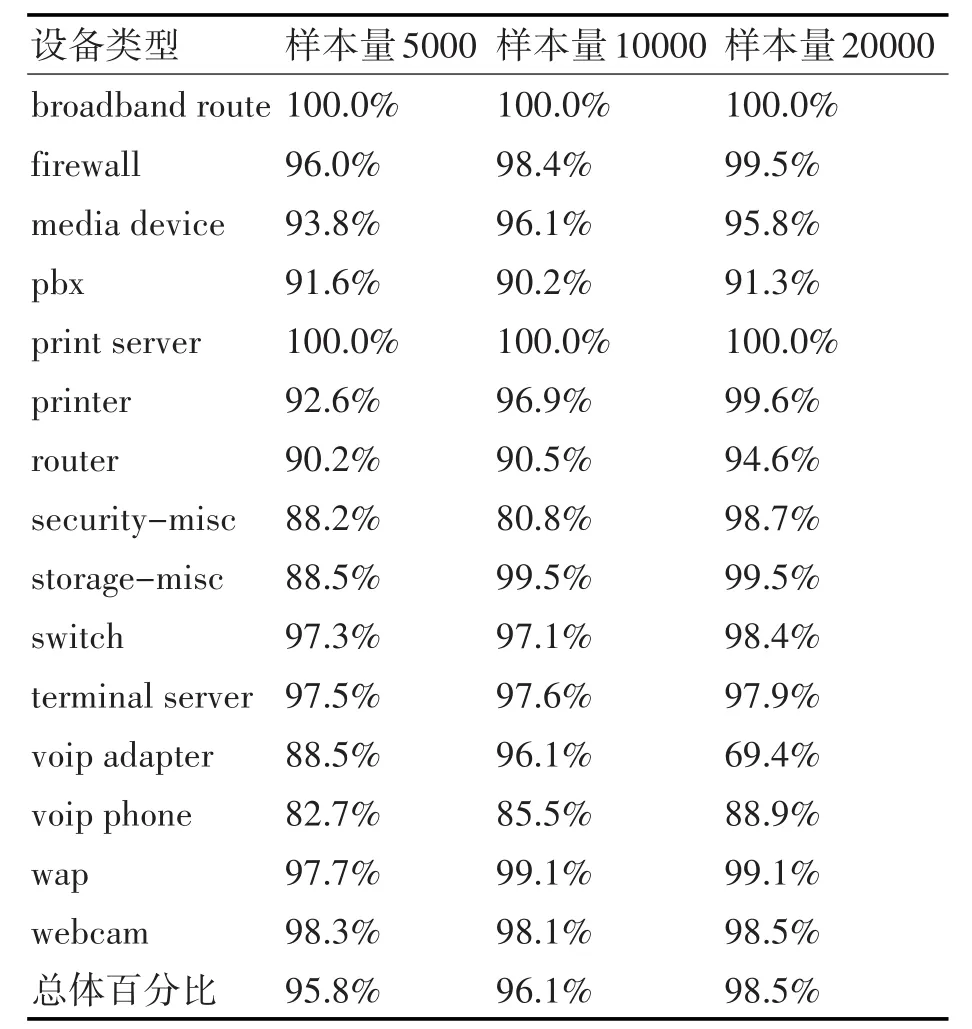
表4 分类模型精确度数据(训练数据部分)
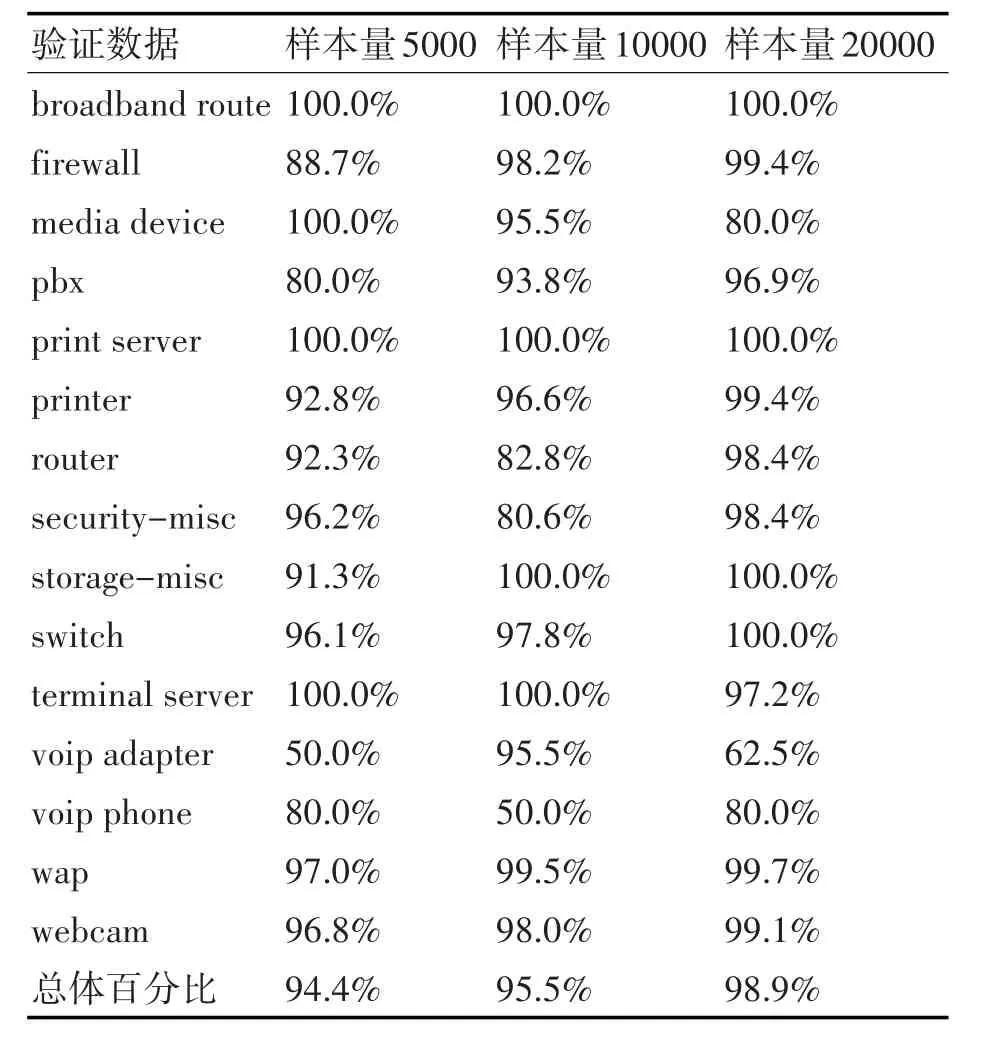
表5 分类模型精确度数据(验证数据部分)
当数据样本分别是5000、10000、20000的时候,分类模型在验证数据集中的精确度在整体上是逐步提高的,这说明随着样本数据量的增加,分类模型的精确度也变高,当数据量为20000时,分类模型达到了一个较高的精度(98.5%)。值得注意的是,在VoIP Adapter和VoIP server两种设备中存在着较大分类误差,这是因为VoIP数据在整体样本中所占的比例较少导致的(实验采集的VoIP设备数据占比较少,导致VoIP设备的特征词的特征值偏低于其他特征词)。
表5是分类模型在验证数据集上的测试结果。可以看出,随着训练数据集的规模的增长,分类模型的精确度在验证数据集上的分类误差也变得越来越小,当数据样本量为20000时,分类模型在验证集上的总体精确度达到98.9%,并在各类设备的中的分类精确度也达到了较高水平。
4 结语
当前计算机网络技术飞速发展,大数据技术也日趋成熟,从海量的网络中获取数据并用数据挖掘技术进行统计分析的应用案例层出不穷,大数据技术已成为分析网络数据的一种常规手段。为了解决网络设备类型识别不准确的问题,基于CHAID决策树算法,得到一个基本可用的网络设备分类模型。
