基于Spark的海量船舶密度分布计算系统设计与实现∗
2019-12-26陈春旭
王 亮 陈春旭 苏 云
(1.海军参谋部指挥保障大队 北京 100841)(2.江苏自动化研究所 连云港 222061)
1 引言
海上船舶目标的分布情况对海军的航路规划、海上试验区选择等任务具有重要意义。船舶密度是指某一瞬时单位面积水域内的船舶数,它能够反映水域中船舶的密集程度[1]。对于一段比较长的时间间隔,船舶密度可以通过对时间求平均得到。船舶目标的数据量非常庞大,通过传统数据手段和工具,难以对其进行快速有效的处理和分析。例如,渤海湾在2016年的AIS(Automatic Identification System,船舶自动识别系统)动态数据,就多达26亿条。船舶目标数据是一种典型的时空数据,如表1所示。
Spark是一种快速通用的集群计算系统[2]。它以RDD(Resilient Distributed Datasets,弹性分布式数据集)为核心模型,提供转换和行动两种操作,支持Java、Scala、Python和R等版本的高级API,以及支持通用执行图的优化引擎。它还支持一组丰富的高级工具,包括用于SQL和结构化数据处理的Spark SQL,用于机器学习的MLlib,用于图形处理的GraphX和用于流计算的Spark Streaming。

表1 船舶目标的部分属性列表
Spark具有运行速度快、通用性和易用性强等特点[3];与MapReduce不同,Spark可以将中间结果保存在内存中,无需输出到磁盘上[4];Spark采用了事件驱动的方式启动任务,能够显著减少线程启动和切换的开销[5]。
传统计算船舶密度分布的方法,通常将船舶数据存储到Oracle等关系数据库,采用非分布式编程模式实现计算过程,在数据达到海量或计算长时间和大范围的密度分布时面临性能问题[6]。
本文在计算密度分布时,为了提高效率,对空间和时间分别进行了离散化并建立索引。对于空间,采用著名的Geohash编码方案;对于时间,本文提出一种多层次时间编码方案。在此基础上,借助Spark的RDD模型将计算过程在时空两个维度上并行化,有效提高了船舶目标密度分布的计算效率。
2 算法设计
2.1 Geohash编码的使用
Geohash编码方案在需要对空间数据进行索引的场景下得到了广泛的应用[7~12]。它通过特定规则,将地理位置(通常用经度、纬度表示)转换为一个由字母和数字组成的字符串。这个过程实际上是有损的,如表2所示。但是在实际应用中,通过控制Geohash的级别,能够将误差控制在可以接受的范围内。
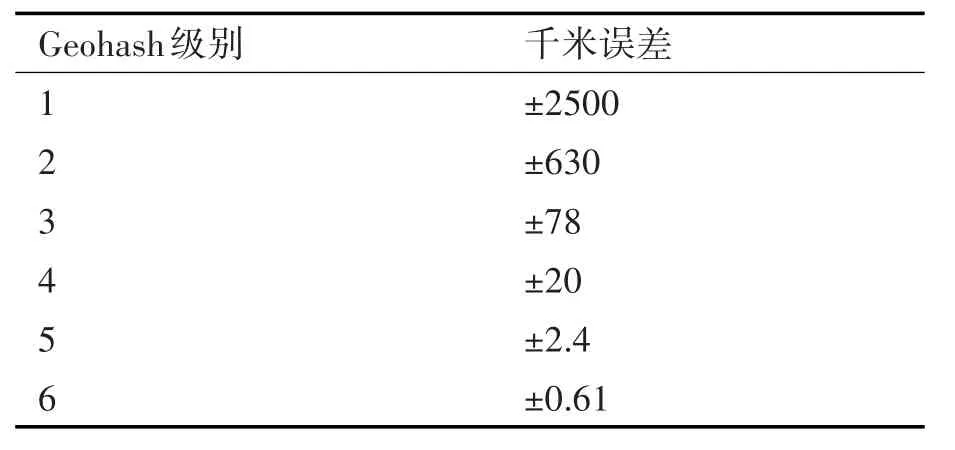
表2 部分级别的Geohash编码的误差
本文中,在对数据预处理时选择了6级Geohash,最大误差为610m;在计算船舶目标分布时,根据所选计算区域的大小,可以选择4~6级Geohash作为计算船舶数的网格。使用Geohash主要为了达到以下几个目的:
一是将经度和纬度两个属性合并为Geohash编码这一个属性,达到数据降维(即维规约)的目的;
二是在误差可接受的情况下,同一个Geohash网格内的数据记录可以规约为一条数据,从而大幅降低数据的规模(即数据记录规约);
三是由于每个Geohash编码实际上代表一个空间网格,可以用这个网格作为密度统计的基本单元;
四是Geohash是一种前缀编码,即具备一个重要性质:如果一个短编码是另一个长编码的前缀,那么后者代表的网格一定是前者代表的网格的子区域。这个性质在船舶目标密度分布的计算过程中具有两个方面的作用:首先,根据用户指定的区域对船舶目标数据进行过滤时,只需要计算出该区域的Geohash编码列表,然后与经过编码的AIS船舶目标动态数据进行连接,连接时只要两个集合中的Geohash编码满足前缀条件即可;其次,在对经过编码的AIS船舶目标动态数据进行分组时,只需要取其Geohash编码的前N位(N根据最终结果选取的Geohash确定),将结果相同的数据归为一组即可。
2.2 多层次时间编码方案
与经纬度类似,船舶目标的时间属性也是连续的,为了降低数据规模,选择小时为最小时间单元,对原始数据进行记录规约。同时为方便按照不同的时间尺度对数据进行统计,采取了月、周、天、时四种尺度对时间进行编码,类似于Geohash的不同级别。时间编码规则,如表3所示。

表3 时间编码规则及示例
该时间编码的优点如下:1)编码和解码规则简单,容易高效实现;2)时间编码是连续的整数,可以直接进行加减,易于通过SQL或其他编程语言进行操作。例如,对2018年6月份的数据进行筛选时,可以简单地表示为[581,582)。
时间编码的算法如下:

其中,TS是时间戳,即从1970年01月01日00时00分00秒开始算起的毫秒数;HOUR_MIL是一小时的毫秒数;HOUR_DIFF是当前时区与零时区的小时差,例如东八区为-8;中括号表示向下取整;HourId、DayId、WeekId和MonthId分别是时、天、周和月四种级别的时间编码。
2.3 船舶目标密度分布算法
船舶目标密度分布算法的关键在于将计算过程利用Spark模型进行并行化。具体的算法流程如图1所示。
第一步,将原始AIS船舶目标动态数据,进行空间离散化和时间离散化。这一步实际是数据的预处理工作,是一个一次性过程。空间离散化采用Geohash编码算法,级别选择6级;时间离散化采用多层次时间编码方案,级别选择小时。处理结束后形成中间结果表,原始数据中的LON和LAT合并为ZONEID,TIME转化为TIMEID。由于进行了数据规约,中间结果表与原始数据相比,记录数大大减少。后续过程从这个中间结果表开始。此过程在Spark中是一个Map操作,用伪代码表示为
rdd.map(r->geohash(r,6))
rdd.map(r->toHourId(r))
第二步,根据用户指定的时间段period(例如从某天开始连续的10天)和空间范围zone(例如整个渤海湾或某个较小海域),对舰船目标进行筛选。目的是根据用户的具体需求降低计算量,从而减少计算时间。此过程在Spark中是一个Filter操作,用伪代码表示为
rdd.filter(r->inZone(r,zone)&&
inPeriod(r,period))
第三步,将同一个时间单元(例如同一天)和同一个空间网格(例如Geohash 5级)内的数据分为一组、去重、计数。此过程在Spark中是一个GroupBy操作,同时进行了Distinct和Count操作,用伪代码表示为:
rdd.groupBy(r->(substr(r.zoneId,5),toTime(r,DAY))).distinct(r->r.mmsi).count()

图1 船舶目标密度分布算法流程
最终得到的结果是一个二维数组的序列,表示在某个时间段内(例如一天或一小时)、在某个空间网格内的船舶目标数。计算结果可以利用适当的UI组件进行可视化,以更加直观地向用户呈现船舶的分布情况,例如网格图或热力图等。
3 系统实现
系统总体架构分为三层:物理层、服务层和应用层,如图2所示。
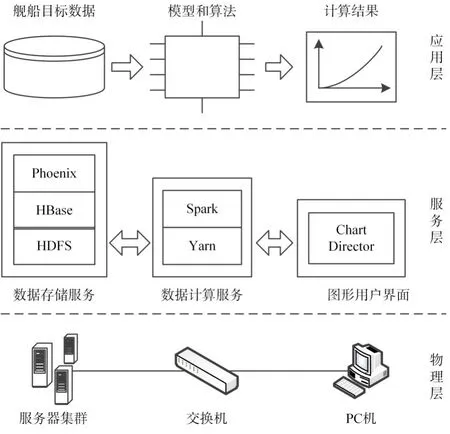
图2 系统总体架构
物理层:由服务器集群和客户端组成,通过一台千兆交换机相连。集群由3台联想服务器(Lenovo System x3650 M5)组成。每台机器的配置:CPU为双路14核,主频2.6GHz;内存为256G;硬盘为1.2TB SAS盘,每台7块。客户端为戴尔PC机,内存为8G,硬盘为500GB固态盘。
服务层:主要提供数据存储服务、数据计算服务和图形用户界面。其中的服务组件主要包括Hadoop Yarn 2.7.1、HBase 1.1.6、Phoenix 4.7.0 和Spark 1.6.2等。
数据存储服务由Phoenix提供,它是一个构建于HBase之上的开源数据库,既继承了HBase分布式和列式存储等优点,又提供了对标准SQL的支持,利用它可以简化对海量数据的操作。同时,Phoenix提供了一个符合Spark Data Sources API标准的数据接口,使Spark能够高效地从Phoenix中分布式地读写数据。
数据计算服务由Spark提供,它是整个系统的核心,用以实现船舶目标密度分布的算法。它支持三种部署模式:独立调度器模式、使用Yarn部署以及使用Mesos部署。本文采用了Yarn Cluster模式部署,可以最大程度地利用服务器集群的资源,以提升计算性能。
图像用户界面为用户提供可视化的操作界面,便于用户提交计算任务、接收和显示计算结果。其中使用了ChartDirector组件绘制密度分布的热力图。
应用层:在服务层的基础上,原始数据、中间数据和结果数据存放于Phoenix数据表中。Spark中运行的代码,负责从Phoenix读取舰船目标原始数据、进行空间和时间离散化处理以及完成密度分布计算,最终将计算结果存储到Phoenix中。客户端代码负责从Phoenix中获取结果,然后通过可视化组件将结果呈现给用户。
4 测试结果与分析
以渤海湾区域2016年的AIS船舶目标为原始数据,在上述的服务器集群上进行了实测。典型地,以2016年8月份为例,得到的密度分布热力图如图3所示。直观地看,图中的船舶情况是与实际相符的。从图中可以明显地观察到港口(例如大连港、天津港、东营港等)和航道(例如从营口港经大连附近出海的航道)。
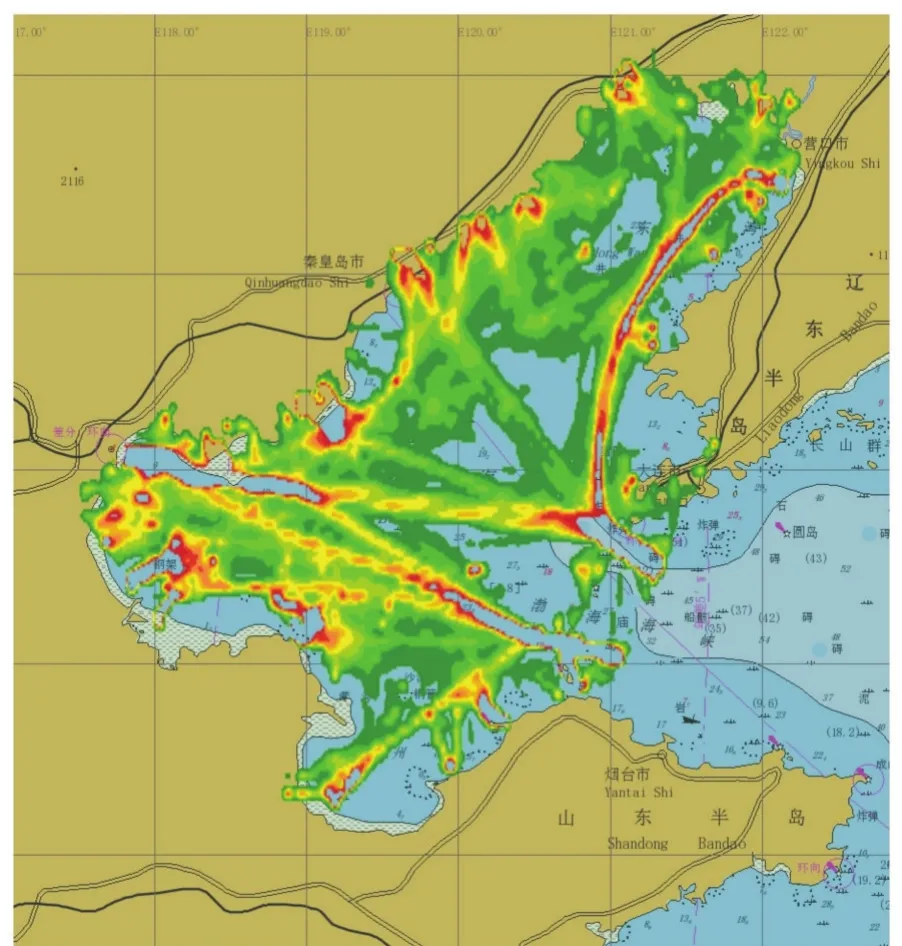
图3 渤海湾2016年8月AIS密度分布热力图
另外,为了验证本文中方案的高效性,同时采取了另外两种方式计算船舶目标密度分布,并将结果进行了对比,如表4所示。其中,方式一即本文采取的方式;方式二与方式一相比,既没有使用Geohash进行空间编码,也没有使用时间编码;方式三与方式一相比,没有使用Spark集群,而是使用了传统的单节点计算方式。从三种方式的耗时可以明显看出,本文采用基于时空编码对数据进行离散化以及采用Spark分布式计算的方式,大大提升了密度分布计算的效率。

表4 不同方式下密度分布计算耗时对比
5 结语
对水面船舶目标的密度、流量和航道等特征进行分析计算时,在传统的单机模式下,当数据量极大时,计算时间会大大延长。本文采用基于HBase的分布式存储Phoenix和Spark分布式计算引擎,辅以Geohash编码和多层次时间编码技术,实现了船舶目标密度计算的并行化。经实测,计算效率显著提升。
另外需要指出的是,虽然本文着重讨论了船舶目标密度分布的计算过程,但是在此基础上做适当的调整,很容易实现对船舶目标其他特征和规律的分析挖掘,例如航迹分布、异常发现和航道挖掘等。
