基于TF-IDF和互信息的推荐算法研究
2019-12-23张云纯
张云纯
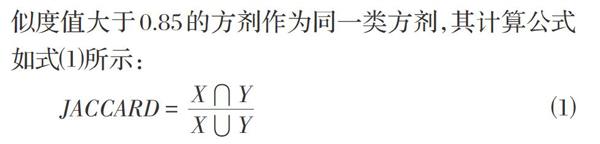
摘 要: 本文提出一种基于TF-IDF和互信息的方剂推荐算法。其核心思想是根据TF-IDF算法的原理,确定核心药物;再计算核心药物和方剂间的互信息来确定二者相关性,以此确定最有效的方剂。对名老中医治疗肺癌的542首方剂,共计342味药物进行数据挖掘,通过该算法获得核心药物71味,推荐方剂126首。采用该算法获得名老中医治疗肺癌的核心方剂的结果表明,该算法通用性强,效率高。由于不仅探索了药物层面的规律,还挖掘了方剂层面的信息,故该算法有较高的实用价值。
关键词: TF–IDF; 有向含权网络; 互信息; 推荐算法; 权重影响因子
中图分类号:TP311 文獻标志码:A 文章编号:1006-8228(2019)12-42-05
Research on recommendation algorithm based on TF-IDF and Mutual-information
Zhang Yunchun
(School of Computer Science and Engineering, Nanjing university of Science and Technology, Nanjing, Jiangsu 210094, China)
Abstract: This paper proposes a prescription recommendation algorithm based on TF-IDF (Term Frequency-Inverse Document Frequency) and Mutual-information. The core idea is to determine the core drug according to the principle of TF-IDF algorithm. Then, the Mutual-information between the core drug and the prescription is calculated to determine the correlation between the two, so as to determine the most effective prescription. Through the data mining of 542 prescriptions of TCM treatment for lung cancer, a total of 342 drugs, 71 core drugs and 126 recommended prescriptions were obtained by this algorithm. The result of obtaining the core prescription of famous herbalist doctors in the treatment of lung cancer with this algorithm shows that the algorithm has strong universality and high efficiency. The algorithm is of high practical value because it not only explores the law of drug level, but also excavates the information of prescription level.
Key words: TF-IDF; directed weighted network; mutual-information; recommendation algorithm; weight factor
0 引言
在自然语言处理中,常见的文本向量化方法为词频-逆向文件频率(term frequency–inverse document frequency,简称TF - IDF)方法。TF - IDF方法的核心思想是:一个词是否是核心词汇,需要从该词汇出现的次数和该词汇在整个文档集合中的代表性这两方面来考虑。在中医领域,方剂和药物的关系与自然语言处理领域中文档和词汇的关系十分类似,同样,要确定某一味药是否是核心药物,也需要同时满足两个条件:⑴该药物是否出现频率足够多;⑵该药物是否仅在某些方剂中出现较多,而在其他方剂中出现较少。
有数据显示,中国癌症新发病例占世界的20%,肺癌位居中国癌症发病率、死亡率的第一位,已与发达国家水平相当[1-2]。针对肺癌的中医方剂有成千上万条,其中起到主要作用的药物数量虽然少,但是对治疗效果起着决定性的作用。如果能够指出方剂中起到主要作用的药物,并依据此推荐方剂,则可有效推动中医的发展。然而,中医医案数据具有数据量大、隐含信息量大、数据非结构化等特性,仅靠人工提取核心药物,不仅效率低下,准确度也不高。因此,学界多采用数据挖掘与复杂网络结合的方式提取核心药物并依此推荐方剂。
复杂网络(Complex Network),是指具有自组织、自相似、吸引子、小世界、无标度中部分或全部性质的网络[3]。近年来,复杂网络广泛应用于社交、自然语言处理及交通领域等。复杂网络在中医药研究领域的应用也十分普遍,常见的有挖掘药物和症候之间的关系,探索药物配伍之间的规律,发现相似的方剂组成等。如Zhou [4]等人利用方剂间的相似度,建立方剂的复杂网络,然后通过网络中节点的度数分析,提取出度数最高的几种方剂,再研究这些方剂中药物的配伍关系。陈澈[5]等利用复杂网络对2型糖尿病的用药规律进行了研究,进而发现了治疗该病的核心药物。韩楠[6]等根据中药方剂特性构建TCM模型,结合TCM网络的小世界特性提出TCM网络的局部适应度模型,分析TCM网络的特性并挖掘TCM网络中配伍关系紧密、相似度较大的药物群。图模型作为复杂网络模型的抽象,也极具研究价值。在中医领域,通过构建网络模型,能够揭示药物之间的结构关系,进而更深层次地分析方剂与病症的关联。
基于上述原理,本文提出一种基于TF-IDF和互信息的方剂推荐算法(Prescription recommendation algorithm based on TF-IDF and Mutual-information,简称PRTM)。首先构建有向含权方剂-药物网络模型(Directed Weighted Prescription-Drug Network,简称[DWPDN]);其次,基于TF-IDF的原理,衡量药物的重要性;再利用互信息来衡量核心药物与方剂的关系,推荐出最具价值的方剂。本研究所采用的数据主要包括来自于中医科研机构、中医院等的临床数据及其内部信息平台上的案例数据,及部分中医药网站的经典医案数据,共计542首。本算法的優点在于:①不仅仅确定了核心药物,还基于互信息的概念,根据核心药物进而确定推荐方剂;②具有较强的通用性,对于任何疾病可采用该模型得到对应的推荐方剂;③算法时间、空间复杂度相对较低,执行效率高。
1 数据预处理
错误的输入会导致错误的输出,如果数据集多源异构,且数据集中的数据存在名称不规范、方剂冗余度大等问题,将直接影响结果的准确性。因此,数据预处理是数据挖掘中一个很重要的步骤。本节将对上述问题提出解决方案。
1.1 多源异构数据集的采集
中医肺癌医案数据的多源异构型主要是指数据具有以下特点:⑴来源广,来自不同的中医高等院校、科研机构、中医院、权威中医药网站等;⑵格式复杂且相互之间不兼容,主要的格式有sql、xls、txt、html等。如何从多源异构数据集中抽取实体关系是重要的研究课题。
针对上述类型的文本,其中,sql、xls文本的结构化程度高,通过简单的数据清洗以及对缺省值的补充和舍去,可达到实体关系抽取的目的。txt通常是非结构化文本,但考虑到此类数据通常数据量不是很大,可采用人工处理和添加特殊符号进行切分的方法来得到实体之间的关系。较txt文本数据、excel和sql,html文件兼有数据量大和非结构化两个特性,如何得到网页数据也是本项研究的核心工作之一。
本研究获取中医药网站信息的流程如图1所示。
1.2 药物名称规范化
部分专家使用的方剂中存在着药物名称不规范的问题,比如板蓝根会被写作板兰根等。本文根据《中华本草》中的标准名称,来对中药的名称做了规范化的处理。
考虑其工作量不是很大,此处采用人工查找替换的模式进行。
1.3 方剂聚类
针对同一疾病,不同专家开出的药方可能完全不同,但也存在着几首方剂中大部分药物相同,只有一两味药不同的情况,亦有专家直接在某药方的基础上标记加减药物。重复方剂会导致算法执行效率低,因此,此处考虑采用计算JACCARD相似度的方式,将相似度值大于0.85的方剂作为同一类方剂,其计算公式如式⑴所示:
⑴
式中的X和Y均表示方剂,分子表示两首方剂中重叠的药物味数,分母表示两首方剂中总共出现的药物味数。
2 研究方法
PRTM算法分三个步骤。第一步,构建有向含权方剂-药物网络模型[DWPDN];第二步,使用基于改进的TF-IDF方法发现核心药物;第三步,在[DWPDN]中根据点互信息对上一步发现的核心药物推荐方剂。
2.1 [DWPDN]模型的构建
方剂学是研究中药方剂的组成、变化和临床运用规律的一门学科,主要包括方剂组成的原则、使用及变化等[7]。方剂药物网络的构建主要有药物-药物网络(Drug-Drug Network,简称[DDN])、方剂-药物网络(Prescription-Drug Network,简称[PDN])及方剂-方剂网络(Prescription-Prescription Network,简称[PPN])三种。
[PDN]模型可以表示方剂-药物关系。具体地,从某个方剂出发,画出一条有向边指向某味药物,即可以表示该方剂与该药物之间的包含关系。然而,传统的[PDN]模型并不能较为完整的表示这种模糊关系[8]。譬如,用[PDN]模型表示知识“茯神和党参是治疗肺癌的方剂1中的两味药药物”见图2。从图2中可见,茯神和党参都是方剂中的药物,至于药物之间的重要程度却不得而知,这就使得在具体判断哪味药更有效果时带来不便。显然,[PDN]模型不能表示出同一方剂与不同药物之间的模糊对应关系。
针对这些不足,本文引入权值因子(weight factor,简称[WF])来度量方剂和药物关系的模糊性。将传统的[PDN]模型改进为[DWPDN]模型。将上文的两条知识用[DWPDN]进行表示,如图3所示。
本文根据方剂中药物的位置情况以及方剂和药物之间的指向关系来确定[WF],[WF]的定义详见下一小节。
2.2 改进的TF-IDF的核心药物发现算法
本算法基于结合TF-IDF的原理,将其类比于中药领域的方剂-药物关系上,提出一种衡量药物有效性(Drug Efficacy,简称[DE])的标准,其中[DE(dg)]表示药物[dg]在治疗疾病时的有效性,具体公式如式⑵所示。
⑵
式⑵中,[ps[i]]表示第[i]首方剂,[ps_set]表示所有方剂形成的集合,[lenps_set]表示所有方剂的个数,[ps[j]∈ps_setcount(dg∈ps[j])]表示包含[dg]药物的方剂个数。需要指明的是,该小节计算的[DE]值即3.1中方剂与边之间的权重[WF]。
该公式的含义在于,所确定的药物的有效性从两个层面来衡量,即如果一味药物是核心药物,不仅需要确保它在方剂中出现的频次高,还需要保证它不是一味在每首方剂中都会出现的辅佐药物。例如,假设药物A作为甜味剂出现在每首方剂中,则式⑵中[log]部分的值为0,整体的值亦为0,也就是说尽管药物A的频次很高,却是一味十分普通的辅佐药物,不能作为核心药物。
算法将药物有效性大于平均值药物有效性[aveg_de]的药物作为核心药物,具体实现流程如下:
2.3 方剂推荐算法
尽管通过上一步中基于改进的TF-IDF核心药物发现算法,已经确定了浅层知识,即治疗肺癌的核心药物。核心药物分配在各首方剂之中,如何判断哪些方剂才是最有效的也是亟待解决的问题。
本文利用上一步得到的核心药物,从中挖掘一些深层知识,即计算其与方剂的互信息,以确定推荐的方剂。
基于此考虑,本文借鉴互信息的算法思想,将方剂与核心药物的关系的强度用互信息[9-11]([Mutual] [Information],简记为[MI])衡量。互信息其实就是点互信息[PMI]([Mutual][Pointwise][Information],简记为[PMI])的加权和。其中,点互信息的定义如式⑶所示:
⑶
其中,[p(x,y)]表示的是[x,y]同时出现的概率,[p(x)和p(y)]分别表示单独出现[x]和[y]的概率。在本文中,[x]表示某味核心药物,[y]表示某首方剂。[p(x)]为某一味核心药物[x]的在所有方剂中的[WF]值,[p(y)]表示方剂[y]中所有药物的[WF]之和,[p(x,y)]表示方剂[y]中出现核心药物[x]的[WF]值。则互信息的表示如式⑷所示:
⑷
其中,[X]表示核心药物的集合,[Y]表示方剂集合。根据求得的[PMI]值来确定方剂的推荐结果。
3 实验
3.1 实验数据
本研究所采用的数据主共计542首方剂。通过PRTM算法获取核心药物71味,获得推荐方剂126个。
3.2 实验结果与讨论
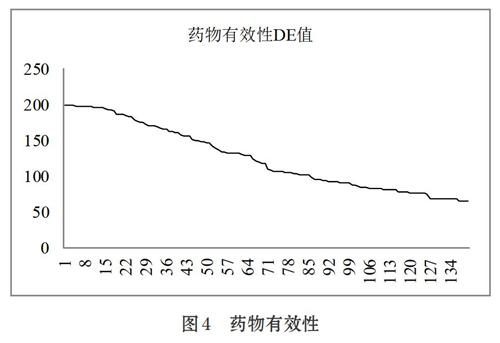
根据核心药物发现算法,在342味中药中,平均药物有效性的值为65.5878,超过该平均值的药物共有140味。其药物有效性情况如图4所示。
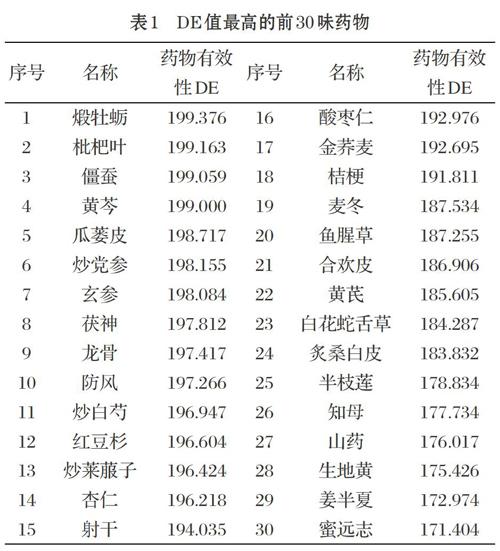
图4显示,药物有效性最高近200,最低在65左右。实验发现,当药物数量大于71,有效性的值变化趋势减缓,因此,实验选取前71味有效性最高的药物作为下一步核心方剂发现算法的输入值。限于篇幅,表1仅展示了有效性最高的前30味药及其有效性。
根据得到的核心药物,进行基于互信息的核心方剂发现算法,得到不同方剂的[PMI]值。542首方剂的[PMI]值如图5所示。
图5显示,[PMI]值最高可达到1,即该首方剂中的药物均为核心药物。根据导数变化情况来看,126首方剂后的[PMI]变化速度减缓。选取前126首方剂作为推荐方剂。限于篇幅,表2仅展示了[PMI]值最高的前5%首(即前6首)方剂的组成。
本算法的时间、空间复杂度不高,542首方剂在实验平台上实际运行时间为58.372秒。算法通用性强,针对其他疾病的临床或医案数据,亦能够采取该种方法得到核心药物并挖掘核心方剂。
对实验结果分析可以发现:
⑴ 基于TF-IDF的原理,对方剂中药物的权重进行调整,确保药物的有效性同时与药物出现频次和代表性相关,可以更准确地发现核心药物;
⑵ 在传统的药物方剂网络中增加了[WF]后,推荐方剂中所包含的核心药物的味数增加了,即所推荐方剂的效果更加完善;
⑶ 使用互信息的思想可以有效地发现与核心药物关联性大的方剂。
4 结束语
本文提出的PRTM算法从中医方剂中确定核心药物,再根据核心药物来推荐方剂,是由浅层知识发现的层面进入到深层知识发现的层面的过程,这提升了研究层次。需要承认的是,中药方剂中发挥作用的因素较多,今后的研究应该进一步考虑多种影响因子的复合作用来设置复合权重。
参考文献(References):
[1] 本刊编辑部. 2017年中国最新癌症数据[J]. 中国肿瘤临床与康复,2017.5:68.
[2] Rebecca L,Siegel M P H,Kimberly D,et al.Cancer statistics[J].CA Cancer J Clin,2018,68(1):7-30
[3] S.Boccaletti,V. Latora, Y.Moreno,M.Chavez, D.-U. Hwang.Complex networks:Structure and dynamics[J]. Physics Reports,2006.4.
[4] Zhou X, Liu B.Network analysis system for traditional Chinese medicine clinical data[C]Biomedical Engineering and Informatics,2009.BMEI09. 2nd International Conference on,IEEE,2009:1-5
[5] 陈澈. 基于复杂网络的2型糖尿病中医核心用药挖掘及其机制研究[D].北京中医药大学,2018.
[6] Han nan,Qiao Shaojie, Li Tianrui,et al. Algorithm for mining the compatibility law of traditional Chinese medicine prescriptions for complex networks[J].Computer science and exploration,2017.11(7):1159-1165
[7] Luo J,Xu h,Zhou x z, et al. Study on the compatibility and application rules of unstable angina pectoris based on complex network[J].Chinese journal of integrated traditional Chinese and western medicine,2014,34(12):1420-1424. (in Chinese with English abstract)
[8] Li Xin,Wang Tianfang,Xue Xiaolin,et al. Application of complex network to analyze the drug law of traditional Chinese medicine in the treatment of hepatitis cirrhosis [J].Chinese journal of traditional Chinese medicine,2013. 28(5):1495-1499
[9] 韓楠,乔少杰,李天瑞,等.面向复杂网络的中药方剂配伍规律挖掘算法[J].计算机科学与探索,2017.11(7):1159-1165
[10] 罗静,徐浩,周雪忠,等.基于复杂网络的不稳定型心绞痛中药配伍应用规律研究[J].中国中西医结合杂志,2014.34(12): 1420-1424
[11] Eirola,e.,Lendasse,a.,Karhunen,J.Variable selection for regression problems using Gaussian mixture models to estimate mutual information[P].Neural Networks (IJCNN), 2014 International Joint Conference on,2014.
