基于用户网络嵌入的民宿房源推荐方法
2019-12-23刘彤曾诚何鹏
刘彤 曾诚 何鹏
摘 要:随着民宿行业的迅速发展,在线民宿订房系统开始流行起来。让用户在海量房源信息中快速找到所需房源是订房系统中待解决的问题。针对房源推荐中用户冷启动与数据稀疏性的问题,提出基于网络嵌入法的房源个性化推荐(UNER)方法。首先通过用户在系统中的历史行为数据及标签信息构建两类用户网络;然后基于网络嵌入法将网络映射至低维向量空间中,得到用户节点的向量表示并通过用户向量计算用户相似度矩阵;最后依据该矩阵为用户进行房源推荐。实验数据来源于贵州“水东乡舍”民宿订房系统。实验结果表明,相对于基于用户的协同过滤算法,所提方法的综合评价指标(F1)提升了20个百分点,平均正确率(MAP)提升11个百分点,体现出该方法的优越性。
关键词:网络嵌入;房源推荐;协同过滤;用户行为
中图分类号:TP311.51
文献标志码:A
Housing recommendation method based on user network embedding
LIU Tong1, ZENG Cheng1,2*, HE Peng1,2
1.School of Computer Science and Information Engineering, Hubei University, Wuhan Hubei 430062, China)
2.Hubei Engineering Research Center for Education Informationization, Wuhan Hubei 430062, China
Abstract:
With the rapid development of the hotel industry, the online hotel reservation system has become popular. How to let users quickly find the housing they need from massive housing information is the problem to be solved in the reservation system. Aiming at the cold start and data sparseness of users in the housing recommendation, the User Network Embedding Recommendation (UNER) method based on the network embedding method was proposed. Firstly, two kinds of user networks were constructed by the users historical behavior data and tag information in the system. Then, the network was mapped into the lowdimensional vector space based on the network embedding method, and the vector representation of the user node was obtained and the user similarity matrix was calculated by the user vector. Finally, according to the matrix, the housing recommendation was performed for the user. The experimental data come from the hotel reservation system of “Shuidongxiangshe” in Guizhou. The experimental results show that compared with the userbased collaborative filtering algorithm, the proposed method has the comprehensive evaluation index (F1) increased by 20 percentage points and the Mean Average Precision (MAP) increased by 11 percentage points, reflecting the superiority of the method.
Key words:
network embedding; housing recommendation; collaborative filtering; user behavior
0 引言
隨着互联网越发普及和成熟,在线订房系统受到很多人的青睐,为用户提供个性化推荐策略也是订房系统中必不可少的一部分,它可以帮助用户在海量房源中找到所需房源。推荐系统主要是挖掘用户潜在需求,帮助用户进行决策[1],推荐效果的好坏直接影响着用户体验和公司收益。[2]。在民宿房源推荐问题中,协同过滤推荐方法[3-5]无法解决用户冷启动问题[6]及数据稀疏性问题。
针对上述问题,本文通过用户在注册时选择的标签数据与用户行为数据构建两类用户用户网络,并使用网络嵌入(network embedding)法分别得到两种网络中用户节点的向量表示。使用用户标签数据构建的网络来解决系统中用户冷启动问题;同时在构建网络时充分考虑网络中节点的一阶和二阶关系用来解决数据稀疏问题。
1 相关工作
网络结构在现实生活中处处可见, 比如道路将城市之间连接成交通网络,论文中引用关系将论文之间构成学术论文网络。对各种数据网络进行分析时首先要对网络进行表示,常用的方法是用邻接矩阵表示网络,最终将节点用高维稀疏向量表示, 这种方法计算时间长并且消耗大量空间。文献[7]中将由网络表示的邻接矩阵作为奇异值分解(Singular Value Decomposition, SVD)算法的输入参数,将节点用低维表示,但是这种表示在数据挖掘中性能不理想。文献[8]中提出的算法将网络中的信息扩散问题转换为低维空间上的信息扩散问题,并使用低维向量表示节点信息,但是算法的复杂度可以达到立方量级,所以不适合大规模网络分析任务。
网络嵌入法[9]又称网络表示学习,是表示学习技术的一个子集。表示学习是一种对数据广义的特征表示,而网络嵌入法则更加专注于网络的表示,旨在将网络中的节点以更加直观、更加高效的某種方式尽可能地还原原始空间中节点的关系,把网络中的每个节点映射成为一个低维稠密实数向量,不仅可以降低时间和空间上的计算开销,而且可以提高节点向量在各种网络分析任务中的性能。
Xie等[10-11]将网络表示学习应用于地点推荐领域;Ding等[12]在基于位置的社交网络中利用用户的兴趣点来提供更加准确的推荐;He等[13]通过向NCF(Neural Collaborative Filtering)模型中输入用户和商品网络中边的信息,同时使用多层感知机来得到用户和商品间的非线性关系,最终计算用户间相似度来进行推荐;文献[14]中DeepWalk算法在网络中进行随机游走得到节点访问序列,然后将其作为skipgram[15]的输入并得到节点向量。网络嵌入法是近几年快速发展的数据分析技术,但是它在个性推荐领域还处于刚起步的阶段。
2 解决方案
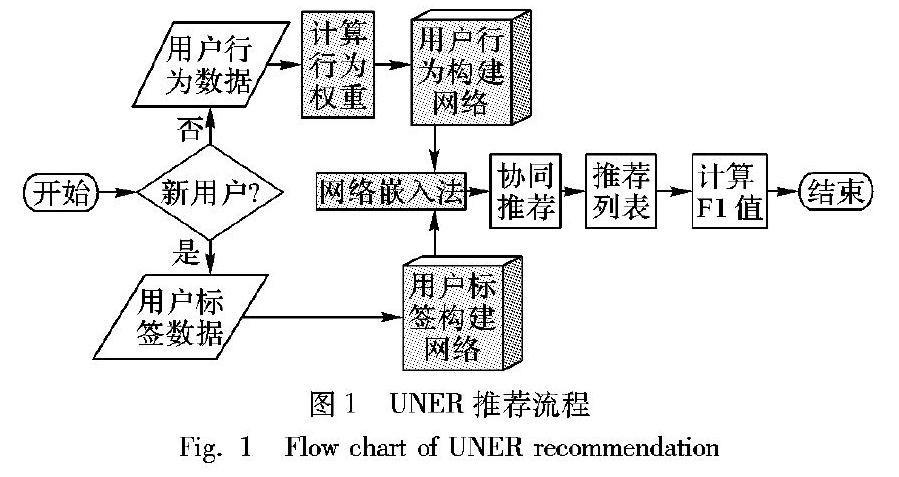
UNER(User Network Embedding Recommendation)方法的整体解决方案如图1所示。
1)通过用户标签数据构建用户用户网络,并通过网络嵌入法计算用户节点向量表示形式,通过该类型网络中用户的向量表示来解决民宿房源推荐问题中用户冷启动问题。
2)使用对比标度权重法计算用户各行为的权重值,并通过用户行为数据构建用户用户网络。
3)为解决用户标签数据和用户行为数据稀疏问题,本文在计算网络中节点向量时不仅考虑节点间的一阶邻近度,同时还考虑节点间的二阶邻近度,即通过增加节点的高阶邻居(如邻居的邻居)来拓展网络中节点的邻居,用以解决用户数据稀少造成的稀疏性问题。
4)通过用户节点的特征向量计算用户间相似性,使用协同推荐得到TopN推荐房源列表。
为方便阅读,介绍算法中用到的结构和定义。
定义1 用户标签。用户在注册时选择兴趣标签,对于用户u而言,用户标签集Tu可以表示一个用户u自身的标签集合〈u,t〉,数据集T={Tu:u∈U}是所有用户的标签记录集合。
定义2 用户行为。用户在使用民宿订房系统时,会产生各种行为,比如浏览、收藏、购买等。一个用户u对房源h产生的行为b可以用三元组〈u,h,b〉来表示,将该三元组称为Bu。数据集B是所有用户对房源产生的行为数据集合。
定义3 用户共现。当两个用户具有相同标签或者对同一房源都具有行为时,那么就称为这两个用户共现。
当给定用户标签数据集后,需要通过用户的标签来统计用户对之间的共现次数来确定两用户之间的权重。若使用用户行为数据,则需要计算用户各行为的权重。最终通过数据集T和B,构建两类用户用户网络。下面介绍用户用户网络的定义。
定义4 用户用户网络。用户用户网络主要是通过抽取用户对之间的共现信息构建获得。可以将用户用户网络表示成G=(V,E)的加权无向图形式,每一个节点代表着一个用户,V表示网络中的节点信息。E表示网络中节点和节点即用户和用户之间的无向边,代表用户之间共现信息。节点Vi和节点Vj之间边的权重Wi, j是由用户标签集合T和用户行为集合B中用户i和用户j之间的共现次数。
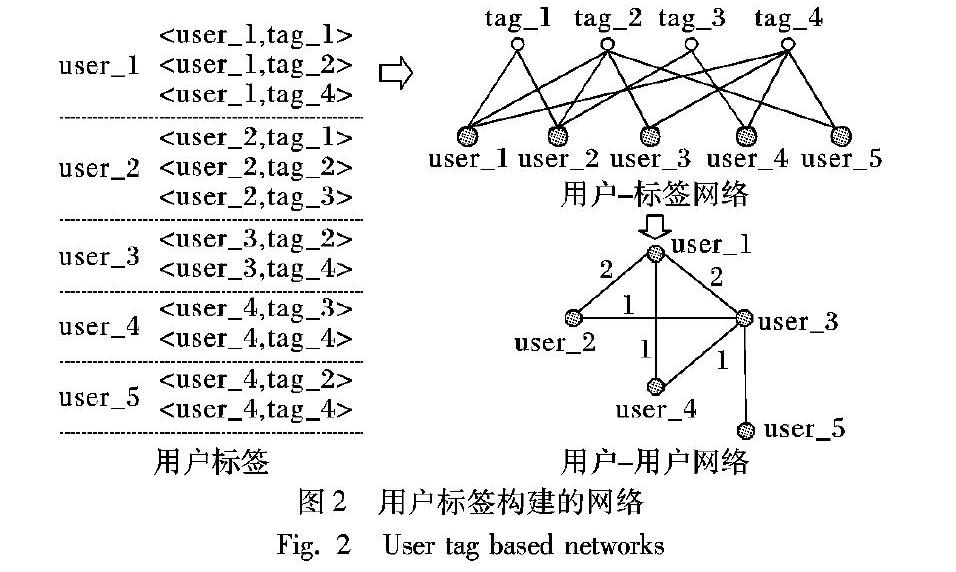
根据以上定义,可以通过用户标签集合T和用户行为集合B构建出两类用户用户网络。图2是基于用户标签的用户用户网络。在通过用户标签构建用户用户网络的过程中,分析用户标签中每个用户和其他用户是否具有相同的标签,从而获得用户用户网络中边的权重。在本例中,用户1和用户2都有标签1和标签2,因此在用户用户网络中,用户1和用户2对应节点的边的权重为2。
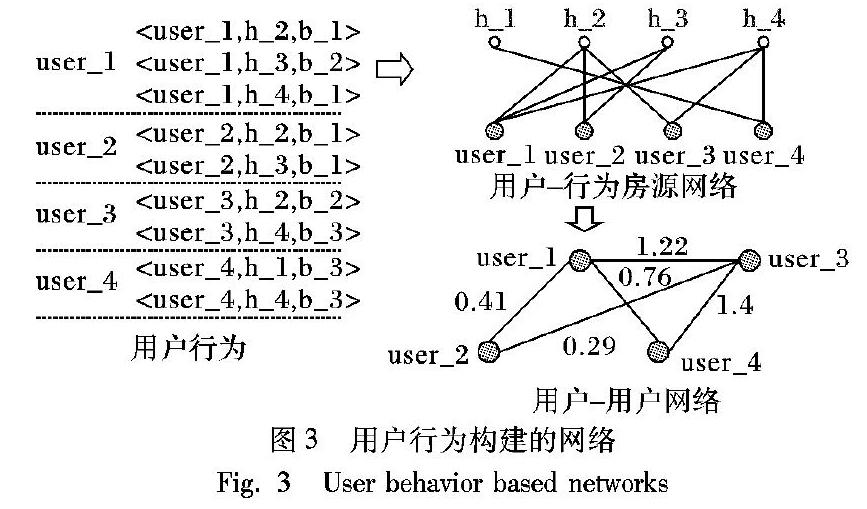
图3是基于用户行为的用户用户网络。在通过用户行为构建用户用户网络的过程中,分析用户和其他用户是否对同一房源产生行为。使用对比标度权重法计算各种行为所对应的权重,网络中两个用户节点间边的权重是这两个用户对同一房源产生的行为权重相加之和。图3中user_1和user_2之间边的权重为user_1对h_2和h_3产生行为的权重加上user_2对h_2和h_3产生行为的权重。
最终,构建两类用户网络后,当系统判定用户为新用户时,则通过用户标签信息来构建用户用户网络并计算用户向量,然后计算用户相似矩阵,最终完成TopN推荐。基于用户标签的网络主要用于解决用户冷启动问题;如果用户不是新用户,那么利用用户在系统中的行为数据来构建网络,然后计算用户相似矩阵,最后为用户提供TopN推荐。
3 研究方法
3.1 网络嵌入法的一阶邻近度和二阶邻近度
一阶邻近度 该模型只适用于无向图,对于用户用户网络中的一条无向边(i, j)定义两个节点vi和vj的共享概率如下:
p1(vi,vj)=11+exp(-uiT,uj)(1)
其中:ui和uj是网络中节点i和j的向量化表示形式,相当于从Embedding的角度来描述节点之间的亲密程度,两个节点亲密程度的度量将由网络的数据结构中获得。
1(vi,vj)=wijW(2)
其中:wij是节点i和j间边的权值;W是指网络中所有边权值的和,即W=∑ (i,j)∈Ewij。为保证一阶邻近度的可靠性,p1和1之间的分布差异越小越好,则将目标函数优化如下:
O1=d(p1,1)(3)
两个概率之间的分布差异由d()函数来衡量,本文中选用KL散度,可以将式(3)优化为:
O1=-∑ (i,j)∈EWijlogp1(vi,vj)(4)
通过学习训练,我们可以得到每个用户节点的特征向量{ui}i=1,2,…,|U|,并且满足使式(4)最小化。
二阶邻近度 二阶邻近度是认为网络中与其他节点具有相同邻居节点的两个节点彼此相似。在该情况下,每个节点也被认为是一个特定的“上下文”,并假设在“上下文”上具有相似分布的节点是相似的。因此每个节点都具有两种角色:节点本身和其他节点的特定“上下文”。引入两个向量ui和ui′,当vi被处理为节点时,ui是vi的表示;当vi被当作“上下文”处理时,ui′是vi的表示。对于边(i,j),将节点vi生成“上下文”vj的概率定义为:
p(vj|vi)=exp(ui′T·ui)∑|V|k=1exp(uK′T·ui)(5)
其中|V|是顶点或“上下文”的数量。为了保证节点间二阶相似度信息,则应该使降维之后上下文的概率p(·|vi)尽可能地接近实际概率(·|vi)。表示为:
O2=∑ i∈Vaid((·|vi),p(·|vi))(6)
由于网络节点的重要性可能不同,所以式(6)中的ai表示网络中节点i的重要程度。实际概率定义为(vj|vi)=wij∑ k∈N(i)wik,其中wij是边(i,j)的权重,N(i)是节点vi邻近的节点集。这里采用KL散度作为距离函数:
O2=-∑ (i,j)∈EWijlogp2(vj|vi)(7)
通过模型的学习训练,可以得到使式(7)最小化{ui}i=1,2,…,|U|,就能通过一个d维的向量的ui′表示每个顶点ui。最后,每个用户节点ui的嵌入向量表示ui为一级邻近度下的向量ui1与二阶邻近度下向量ui2的线性组合,即:
ui=γui1+(1-γ)ui2(8)
3.2 基于用户网络嵌入的推荐
基于用户网络嵌入法的推荐是通过用户用户网络得到用户相似矩阵,使用相似用户进行房源推荐。通过上述方法计算,可得到每个用户的特征向量ui,本文中采用余弦相似度[16]来计算用户间相似度,并获得相似用户集合S(u)。
sim(ui,uj)=cos(ui,uj)(9)
对于用户u是否选择房源h,根据其相似用户集中的用户选择情况进行判断。对于房源h,用户u选择它的概率的计算公式如下:
p(u,h)=∑ v∈S(u)∩N(h)sim(u,v)·rvh(10)
其中:rvh表示用戶u的相似用户v对房源h的喜欢程度,N(h)是已选择了房源h的用户集。最后得到用户u对未曾关注过的房源感兴趣的概率列表,并且将概率大的房源进行优先推荐。
3.3 对比标度权重法
民宿订房系统中的用户行为包括浏览、收藏和购买。本文利用对比标度权重法[17]来确定不同行为下用户对该房源的喜爱程度。它是指事物与离散变量各类之间有一定的联系,所以就可将权重的概念使用到分类变量上,数量化赋值的标准将由对指标各分类的不同权重来确定。首先按层次分析法的原则将某个分类变量依据一定的规则进行赋值,然后根据各个类之间的重要程度,最后按照从1~9的标度方法,如表1所示,一一对比标度,构造如下判断矩阵:
D1D2 … Dn
D1D2Dn-1Dnd11d12…d1n
d21d22…d2n
d(n-1)1d(n-1)2…d(n-1)n
dn1dn2…dnn
4 实验分析
4.1 数据获取
实验数据主要来自于贵州“水东乡舍”项目2018年5月—2019年2月 200位用户的标签数据和行为数据以及150间民宿房源数据。“水东乡舍”是我们团队为贵州某公司实施的精准扶贫项目,拟在开阳县试点,成功后在贵阳市及贵州省推广。
1)用户标签数据。民宿订房系统中的用户注册页面设计了用户选择兴趣标签的功能。用户在注册时选择的标签数据就是用户标签数据集。
2)用户行为数据。民宿订房系统中定义了三种用户行为,分别为浏览、收藏和购买。用户对商品的收藏和购买行为是在系统中明确产生的行为,很容易获取。系统中获取用户浏览房间的记录主要是通过页面中的JavaScript代码来实现。
4.2 计算用户各行为权重
用户行为(浏览、收藏、购买)是用户对该房源是否有兴趣的体现,不同的行为表示了用户对该房源的喜好程度。用户各行为的权重计算分为下面三步。
1)根据表1构建判断矩阵,两两行为进行对比,得出行为之间的相对重要性,如表2所示。
2)计算特征向量。从表3中的数值可以计算浏览、收藏和购买行为的特征向量值。计算方法在4.3节详细讲述。计算过程如下所示:
浏览=31×1/5×1/9=0.28;收藏=35×1×1/4=1.08;购买=39×4×1=3.30。
3)对特征向量值作归一化处理,确定权重系数。计算过程如下:
浏览=0.28/4.66=0.06;收藏=1.08/4.66=0.23;购买=3.30/4.66=0.70。通过计算,可以得到三种行为的权重系数。
4.3 构建网络
本节以用户行为数据集为例,构建基于用户行为的用户用户网络。图4为用户行为的部分数据集,该数据集主要由用户编号、房源编号和行为编号构成。
图5为将图4中数据转换为带权无向图后的数据形式。
将图5中的数据经过网络嵌入法计算其一阶与二阶邻近度,并将两种近邻度下的用户特征向量进行线性组合就可得到每个用户节点的向量表示形式,如图6所示。
4.4 参数影响分析
本文所提算法采用综合评价指标(F1值)和平均正确率(Mean Average Precision,MAP)来衡量。F1计算公式为:
F1@K=2PRP+R
其中:P为精确率,R为召回率。
MAP的计算公式为:
MAP@K=∑Nn=1Avep(n)N
其中Avep(n)=∑nq=1(p(q)×rel(q))number of relevant documents;N表示为N个用户推荐;对于已排序好的推荐列表,q代表推荐列表中房源的排名,当q为已推荐成功房源时rel(k)为1,否则为0;p(q)是q前面房源的精确度。
将用户行为数据集随机抽出25%的数据作为测试集,剩余数据作为训练集。用户向量维度的设置为LINE方法中的默认值128维,在优化过程中取负采用数为5,学习率的初始值设置为ρ0=0.025,且ρτ=ρ0(1-t/T),其中T为网络中边的数量。对于式(8)参数γ值的确定,采用变量固定措施。保持UNER方法中相似用户集S(u)=5,参数γ按照每次增加0.1的方式从0到1变化,分别为用户推荐4、6和8个房源,结果如图7所示,当γ值取0.7时,实验结果最佳。
4.5 实验结果
为了验证本文实验的有效性,将UNER方法的推荐结果与基于用户的协同过滤算法(Userbased Collaborative Filtering,UserCF)的结果再进行对比。当γ=0.7,目标用户的相似数据集S(u)长度取5时,分别推荐6~10个房源,然后计算F1值和MAP值,两种算法得到的结果,如表3所示。
当目标用户的相似数据集S(u)长度取10时,分别推荐6~10个房源,然后计算F1值,分别得到两种算法的F1值和MAP值,如表4所示。
将表4与表5转换为图表形式,如图8和图9所示,可以看出在两种情况下UNER的综合评价指标和平均正确率均比UserCF高,即UNER的推荐结果比UserCF更优。
5 结语
从实验结果中可看出,基于用户网络嵌入法的民宿房源推荐方法要比协同过滤算法在综合评价指标上更优。相对基于用户的协同过滤算法,UNER方法的推荐综合评价指标(F1值)和平均正确率(MAP)均比基于用户的协同过滤算法更优。由于本文的研究主要是針对民宿房源的推荐,所以数据集采用贵州“水东乡舍”项目中的用户标签数据和用户行为数据。
另外,在后期研究中应加入用户的社交网络数据,来提高推荐的精准度。同时,应结合更多用户的隐性行为数据,比如用户在页面的停留时间、用户对房源的评价信息以及用户行为产生的时间,并考虑多方面因素确定行为权重,从而更加精准为用户推荐房源信息。
参考文献 (References)
[1]DESHPANDE M, KARRYPIS G. Itembased TopNrecommendation algorithms[J]. ACM Transactions on Information Systems, 2004, 22(1):143-177.
[2]JUNG K Y, HWANG H J, KANG U G. Constructing full matrix through Naive Bayesian for collaborative filtering[C]// Proceedings of the 2006 International Conference on Intelligent Computing, LNCS 4114. Berlin: Springer, 2006:1210-1215.
[3]GOLDBERG D, NICHOLS D, OKI B M, et al. Using collaborative filtering to weave an information tapestry[J]. Communications of the ACM, 1992, 35(12): 61-70.
[4]BREESE B J S, HECKERMAN D, KADIE C. Empirical analysis of predictive algorithms for collaborative filtering[C]// Proceedings of the 4th Conference on Uncertainty in Artificial Intelligence, 1998:43-52.
[5]邓爱林,朱扬勇,施伯乐. 基于项目评分预测的协同过滤推荐算法[J]. 软件学报, 2003, 14(9):1621-1628. (DENG A L, ZHU Y Y, SHI B L. A collaborative filtering recommendation algorithm based on item rating prediction [J]. Journal of Software, 2003, 14(9): 1621-1628.)
[6]邵煜,谢颖华. 协同过滤算法中冷启动问题研究[J]. 计算机系统应用, 2019, 28(2):246-252. (SHAO Y, XIE Y H. Research on coldstart problem of collaborative filtering algorithm[J]. Computer Systems & Applications, 2019, 28(2):246-252.)
[7]LE T M V, LAUW H W. Probabilistic latent document network embedding[C]// Proceedings of the 2014 IEEE International Conference on Data Mining. Piscataway: IEEE, 2014: 270-279.
[8]BOURIGAULT S, LAGNIER C, LAMPRIER S, et al. Learning social network embeddings for predicting information diffusion[C]// Proceedings of the 2014 IEEE International Conference on Data Mining. Piscataway: IEEE, 2014: 393-402.
[9]PEROZZI B, ALRFOU R, SKIENA S. DeepWalk: online learning of social representations[C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014:701-710.
[10]XIE M, YIN H, XU F, et al. Graphbased metric embedding for next POI recommendation[C]// Proceedings of the 2016 International Conference on Web Information Systems Engineering, LNCS 10042. Berlin: Springer, 2016: 207-222.
[11]XIE M, YIN H, WANG H, et al. Learning graphbased POI embedding for locationbased recommendation[C]// Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. New York: ACM, 2016:15-24.
[12]DING R, CHEN Z. RecNet: a deep neural network for personalized POI recommendation in locationbased social networks[J]. International Journal of Geographical Information Science, 2018, 32(8): 1631-1648.
[13]HE X, LIAO L, ZHANG H, et al. Neural collaborative filtering[J]. Proceedings of the 26th International Conference on World Wide Web. Republic and Canton of Geneva, Switzerland: International World Wide Web Conferences Steering Committee, 2017:173-182.
[14]WANG D, CUI P, ZHU W. Structural deep network embedding[C]// Proceedings of the 22nd ACM SIGKDD International Conference. New York: ACM, 2016:1225-1234.
[15]MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]// Advances in Neural Information Processing Systems 26. Cambridge, MA: MIT Press, 2013:3111-3119.
[16]LUO C, ZHAN J, WANG L, et al. Cosine normalization: using cosine similarity instead of dot product in neural networks[EB/OL]. [2019-03-20]. https://arxiv.org/pdf/1702.05870.pdf.
[17]高陽,余建伟. 判断矩阵标度扩展法在不同标度下的比较[J]. 统计与决策, 2007(20):152-154. (GAO Y, YU J W. Comparison of judgment matrix scale expansion method under different scales[J]. Statistics and Decision, 2007(20):152-154.)
This work is partially supported by the National Natural Science Foundation of China (61902114), the Hubei Province Major Technological Innovation Project (2016CFB309).
LIU Tong, born in 1993, M. S. candidate. His research interests include big data processing, recommendation algorithm.
ZENG Cheng, born in 1976, Ph. D., professor. His research interests include big data processing, domain software engineering, service recommendation.
HE Peng, born in 1988, Ph. D., associate professor. His research interests include big data processing, software metrics, complex network.
