基于RGB和关节点数据融合模型的双人交互行为识别
2019-12-23姬晓飞秦琳琳王扬扬
姬晓飞 秦琳琳 王扬扬


摘 要:基于RGB視频序列的双人交互行为识别已经取得了重大进展,但因缺乏深度信息,对于复杂的交互动作识别不够准确。深度传感器(如微软Kinect)能够有效提高全身各关节点的跟踪精度,得到准确的人体运动及变化的三维关节点数据。依据RGB视频和关节点数据的各自特性,提出一种基于RGB和关节点数据双流信息融合的卷积神经网络(CNN)结构模型。首先,利用Vibe算法获得RGB视频在时间域的感兴趣区域,之后提取关键帧映射到RGB空间,以得到表示视频信息的时空图,并把图送入CNN提取特征; 然后, 在每帧关节点序列中构建矢量,以提取余弦距离(CD)和归一化幅值(NM)特征,将单帧中的余弦距离和关节点特征按照关节点序列的时间顺序连接,馈送入CNN学习更高级的时序特征; 最后,将两种信息源的softmax识别概率矩阵进行融合,得到最终的识别结果。实验结果表明,将RGB视频信息和关节点信息结合可以有效地提高双人交互行为识别结果,在国际公开的SBU Kinect interaction 数据库和NTU RGB+D数据库中分别达到92.55%和80.09%的识别率,证明了提出的模型对双人交互行为识别的有效性。
关键词:RGB视频;关节点数据;卷积神经网路;softmax;融合;双人交互行为识别
中图分类号:TP391
文献标志码:A
Human interaction recognition based on RGB and skeleton data fusion model
JI Xiaofei*, QIN Linlin, WANG Yangyang
College of Automation, Shenyang Aerospace University, Shenyang Liaoning 110136, China
Abstract:
In recent years, significant progress has been made in human interaction recognition based on RGB video sequences. Due to its lack of depth information, it cannot obtain accurate recognition results for complex interactions. The depth sensors (such as Microsoft Kinect) can effectively improve the tracking accuracy of the joint points of the whole body and obtain threedimensional data that can accurately track the movement and changes of the human body. According to the respective characteristics of RGB and joint point data, a convolutional neural network structure model based on RGB and joint point data dualstream information fusion was proposed. Firstly, the region of interest of the RGB video in the time domain was obtained by using the Vibe algorithm, and the key frames were extracted and mapped to the RGB space to obtain the spatialtemporal map representing the video information. The map was sent to the convolutional neural network to extract features. Then, a vector was constructed in each frame of the joint point sequence to extract the Cosine Distance (CD) and Normalized Magnitude (NM) features. The cosine distance and the characteristics of the joint nodes in each frame were connected in time order of the joint point sequence, and were fed into the convolutional neural network to learn more advanced temporal features. Finally, the softmax recognition probability matrixes of the two information sources were fused to obtain the final recognition result. The experimental results show that combining RGB video information with joint point information can effectively improve the recognition result of human interaction behavior, and achieves 92.55% and 80.09% recognition rate on the international public SBU Kinect interaction database and NTU RGB+D database respectively, verifying the effectiveness of the proposed model for the identification of interaction behaviour between two people.
Key words:
RGB video; skeleton data; Convolutional Neural Network (CNN); softmax; fusion; human interaction recognition
0 引言
基于视频的交互行为识别具有较高的实用价值和广阔的应用前景[1]。根据原始数据的不同,对于双人交互行为识别的分析方法可以分为基于RGB视频和基于关节点数据两类。基于RGB视频的研究开展比较早,Gavrila等[2]提出用时空体来描述人的行为,即利用人体行为的轮廓随时间变化的过程来识别行为的类别。赵海勇等[3]将时变轮廓形状转换为对应的一维距离向量并提取行为序列的关键姿态,将关键姿态编码为行为字符串进行交互行为识别; 韩磊等[4]提出一种基于时空单词的双人交互行为识别方法,该方法从包含双人交互的视频中提取时空兴趣点,并通过投票生成单人原子行为的时空单词,采用条件随机场模型建模单人原子行为模型。在此基础上并训练马尔可夫逻辑网用于双人交互行为的推理。 Li等[5]提出一种多特征结合的描述方法,提取时空兴趣点,并采用一系列描述子对其进行表示,采用时空匹配法和遗传算法训练随机森林实现动作识别。这类基于RGB的算法对于简单的双人交互行为得到了较好的识别效果,但由于缺乏深度信息,对于复杂多变的交互动作识别不够准确。
近几年,随着深度传感器(如微软Kinect)的快速发展,大幅提高了全身各关节点数据的跟踪精度, Kinect相机共包括彩色摄像头、深度摄像头和红外摄像机三个摄像头,其中彩色摄像头拍摄视角范围内的彩色视频图像,同时深度摄像头通过分析红外光谱,创建可视范围内的物体的深度图像,利用深度图转化得到3D关节点数据。基于关节点的双人交互识别获得了越来越多研究者的关注。Yun等[6]利用当前帧中所有关节对的距离、当前帧中关节与前一帧中关节之间的距离以及当前帧中各关节点与中心点之间的距离来描述身体姿态,通过多实例学习方法得到每个动作的姿势描述符。这种特征描述简单易获取,但缺少了上下文时序关系的描述。Slama等[7]将一个动作描述为时间序列中关节点三维坐标的集合,每个动作序列被表示为产生三维关节轨迹的线性动力系统,采用自回归滑动平均模型来表示序列, 最后采用线性支持向量机(Support Vector Machine, SVM)进行分类。这种描述符同时包括时间和空间信息,但是对于相似动作的识别效果较差。
目前基于RGB视频和关节点数据的双人交互行为识别研究中,多数是依赖于低级或中级的手动获取特征,在处理复杂数据时能力有限,适应性不强且动作识别准确率提升空间不大。近几年,随着卷积神经网络(Convolutional Neural Network, CNN)在静态图像分类中获得成功,其已经扩展到用于解决动作识别的研究中[8]。Simonyan等[9]提出基于RGB视频时间空间结合的双流卷积神经网络模型,其中空间流是利用带有视频场景和对象的静态视频帧进行卷积,时间流是利用光流堆积法与轨迹追踪法获得光流图进行卷积,最后将两流做softmax的分数融合。分类结果表明,识别率较传统传统特征明显提升,但基于多帧获得的光流图计算量较大。Li等[10]提出一种新颖的双流卷积网络结构,首先将原始的骨架信息直接送入CNN提取特征,另外将连续两帧的骨架关节运动也送入网络提取特征,将两种特征连接并经过softmax融合获得识别结果。该方法仅使用关节数据进行识别,计算量低,但是没有很好地利用特征的时序关系。为了更好地建模关节点特征的时序关系,Liu 等[11]提出全局感知注意力长短期记忆(Long ShortTerm Memory, LSTM)网络的动作识别方法。该网络包括两个LSTM网络,第一个LSTM层用于编码原始骨架序列并初始化全局存储单元,然后将全局存储单元的表示送入第二LSTM层,以选择性地关注每个帧的信息性关节,经过多次迭代优化全局存储信息,最后将精简的全局信息送入softmax分类器识别动作类。Ke等[12]将骨架序列3D坐标的每个通道转化为一个时空信息的片段,每个骨架序列转换为三个片段,表示整个骨架序列的时间信息和骨架关节之间特定的空间关系,同时提出多任务卷积神经网络(MultiTask Convolutional Neural Network, MTCNN),并行处理每个片段所有帧以学习骨架序列的时间和空间信息。Liu等[13]提出一个关节点序列的时空LSTM网络,将LSTM的学习扩展到时空域,每个关节从相邻关节以及前一帧接受信息编码时空特征,采用树状结构表示关节点之间的相邻特性和运动关系,最后将骨架数据的结果送入LSTM网络进行建模与识别。Li等[14]提出基于骨架端到端的卷积共生特征学习框架,首先对每个关节点的点级信息独立编码,将骨架序列表示为张量,使用卷积和独立学习点级别特征,然后转换卷积层的输出,分层聚合来自关节的全局特征,得到时间和空间域的语义表示,最后送入分层式共现网络(Hierarchical Cooccurrence Network,HCN)学习。利用CNN在关节点和RGB视频的双人交互行为识别中均取得了良好的效果,识别的准确率较手动提取特征有了大幅度的提升。但将CNN应用在两种特征互补的数据源结合中,还处于初始阶段。因此,本文提出了一种RGB视频和关节点数据双流信息融合的CNN识别框架,该框架较好地利用了RGB信息和关节点信息的互补性,进一步提高了对于复杂交互行为识别的准确性。
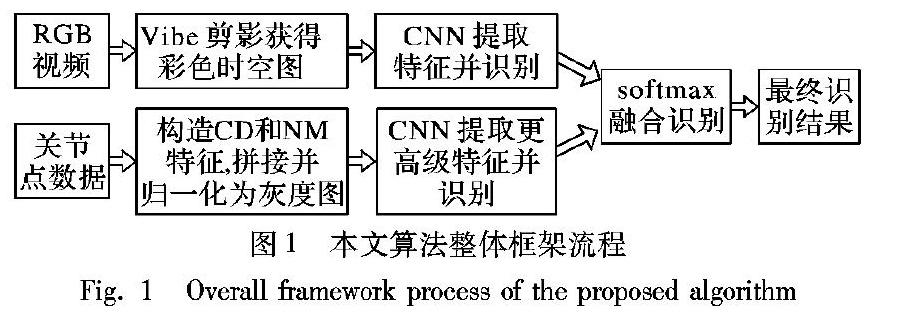
1 算法的整体框架
本文算法的整体框架如图1所示,具体实现步骤如下:
1)基于RGB视频的处理过程:首先判断两个交互个体的质心之间的距離,获取交互帧的执行阶段,从得到的RGB视频帧中等间距选出三帧,利用Vibe算法做背景减除,分别得到三帧不包括背景信息的二值图像,将代表视频的三张图片映射到RGB空间,并对三张图片压缩,得到表示视频信息的时空图。
2)基于关节点数据的处理过程:首先,构造交互个体及交互双方之间的关节点矢量,然后构造基于矢量的具有平移、旋转、缩放不变形的余弦距离(Cosine Distance, CD)和归一化幅值(Normalized Magnitude, NM)特征表示骨架序列的空间结构信息,将两种基础特征分别连接起来并构造成灰度图像,送入CNN用于提取更高级的时序特征和动作识别。
3)基于RGB视频和关节点数据融合的识别过程:将处理好的RGB视频数据和关节点数据分别送入深度学习网络中,将各自得到的识别概率矩阵做权值融合送入softmax分类器得到最后的识别分数。
2 数据预处理
2.1 RGB视频预处理
对于动作序列,一个动作流程可以分为准备、执行和结束阶段,但有的动作如“握手”与“靠近”,在准备和结束有较大的相似性,为增加两个动作的可区分性,通过测量交互动作双方的质心距离D来得到动作视频的执行阶段。
c=1m1∑m1i=1ai,1m1∑m1i=1bi
d=1n1∑n1j=1aj,1n1∑n1j=1bj(1)
L=‖c-d‖-D≥0, 保留帧<0, 去除帧(2)
其中:c、d分别表示交互行为双方的体心;m1和n1分别表示单个个体所包含的像素点个数;(ai,bi)和(aj,bj)表示单人的像素点坐标;D为设定的阈值;L为判别量。通过以上预处理过程得到更为精简的RGB视频信息,利用Vibe算法做背景减除,从去除背景的视频帧中等间距选出三帧,并将这三帧图像映射到RGB空间,得到表示视频信息的时空图。
2.2 关节点数据预处理
在双人交互识别过程中,获得动作序列中完整的空间位置信息和时序关系,对识别结果十分重要。因此,在单帧关节点中构造关节点向量,并提取余弦距离(CD)和归一化幅值(NM)特征,分别按照关节点序列的时间信息连接,关节点序列转换为基于图像的表示,则可以使用CNN学习序列中更高级的时间结构。首先获取具有旋转、缩放、平移不变性的余弦距离和归一化幅值特征,具体算法如图2所示。
关节点向量表示的计算过程如下:
将单帧中的关节点数据定义为:
Ω={Pi∈R3:i= 1,2,…,n}(3)
其中:n表示单帧中所包含的关节点数,Pi=[xi,yi,zi]代表第i关节点的3D坐标。所有帧的关节点按交互行为双方分为两部分,分别表示为:
Ω=∪2k=1Ωk(4)
其中:Ω1代表左侧行为者,Ω2表示右侧行为者。
对于不同的行为者Ω1,2,选择一个初始关节点p(1,2)0,其余关节点定义为一个集合p,本文定义单人内的关节点向量为:
υ(k)w={p-p(k)0:p∈Ωk}(5)
双人之间的关节点向量为:
υ(k)b={p-p(k)0:p∈Ω\Ωk}(6)
选择脊柱根部的关节点作为原点,更能反映其他关节的运动。
余弦距离和归一化幅值特征表示过程如下:
设定v∈υ(k)w,u∈υ(k)w∪υ(k)b,本文定义余弦距离为:
vTu‖v‖‖u‖(7)
单帧中得到的14×28=392维余弦距离特征。
定义归一化幅度为:
‖u‖‖u(k)0‖(8)
其中u0為选择的参考向量,将颈部和脊柱根部构成的向量作为参考向量,得到28维归一化幅值特征。
将所有视频帧的上述特征按照时间关系连接,每个关节点序列共包含n帧,则得到的余弦距离维数为14×28×n,归一化幅值特征维数为28×n,其中每列表示单帧的空间结构特征,初步提取所有帧的信息。然后将得到的余弦距离和归一化幅值矩阵归一化至0~255,成为一幅灰度图像,由于相邻关节点和相邻帧中相同关节点的变化是连续的,因此图像中的像素不会急剧变化。为了减少不同关节点帧数造成的差异,将所有关节点序列得到的灰度图像调整至相同大小。最后馈送入CNN学习更高级的特征,获得最后的识别结果。
3 模型结构
将数据集中每类动作的RGB视频和关节点数据按照8∶2 分为训练集和测试集,在TensorFlow平台下使用Keras框架对深度卷积神经网络VGGNet16[15]模型迁移学习,实现人体动作识别。
3.1 CNN概述
CNN由输入层和输出层及多个隐藏层组成,隐含层包括卷积层、池化层及全连接层。
卷积层(Convolutional layer) 卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取到一些低级的如边缘、线条和角等特征,多层的卷积网络能从低级的特征中迭代提取更复杂的特征。
池化层(Pooling layer) 池化即降采样,目的是减少特征图,主要是通过减少网络的参数来减少计算量,并且在一定程度上能够控制过拟合。
全连接层(FullyConnected layer) 全连接层的每一个节点都与上一层的所有节点相连,把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
CNN与传统的神经网络相比不同之处,主要有局部感知、权值共享和多卷积核三点。局部感知就是卷积核和图像卷积时,每次卷积核所覆盖的像素只是一小部分,感知的是局部特征,CNN是一个从局部到整体的过程。传统的神经网络参数量非常巨大,而卷积层的参数完全取决于滤波器的设置大小,整个图片共享一组滤波器的参数,通过权值共享降低参数量。一种卷积核代表一种特征,为了获取更多不同特征的集合,卷积层会有多个卷积核,来得到不同的特征。
3.2 VGG网络
VGG是牛津大学计算机视觉组和Google DeepMind公司一起研发的深度卷积神经网络,该网络主要是泛化性能很好。VGG探索了CNN的深度与其性能之间的关系,通过反复堆叠3×3的小型卷积核和2×2的最大池化层,成功地构筑了16~19层深的CNN。同时将卷积层提升到卷积块,使网络有更大的感受野同时也降低网络参数,学习能力更强。在训练过程中使用MultiScale 做数据增强,将同一张图片缩放到不同的尺寸,增加数据量。本文选择层数为16的VGG作为CNN模型。如表1所示为VGG网络的结构及参数。
3.3 融合结构
针对可视范围内发生的动作,Kinect相机能够同时获取RGB视频和3D关节点数据。将传统RGB数据与3D关节点数据相结合,两者信息互补,经过预处理,RGB获得更精简的信息,3D关节点数据得到具有旋转、平移、缩放不变性的基础特征。分别将处理得到的RGB视频和关节点数据送入VGG16网络模型,最终利用softmax分类器得到基于RGB视频和关节点数据各动作类别的识别分数概率矩阵。然后,针对不同的原始数据流给予不同的权值融合softmax值,将融合得到的结果再次经过softmax分类器,最终得到融合识别结果分数矩阵,实现RGB视频和3D关节点数据的决策集融合。总体流程如图3所示。
4 实验测试与分析
4.1 数据库与测试环境介绍
为证明提出方法的有效性,采用国际标准的SBU Kinect数据库和NTU RGB+D数据库进行验证。SBU Kinect交互数据集共有7名动作行为人,组成21对动作执行者,包括8个动作类别,分别为靠近、离开、踢腿、打、推、拥抱、握手和传递物品。在大多数的互动行为中,一个人做出动作另一个人做出反应动作,且均采用相同的室内背景录制。每个人由15个关节点表示,每帧的关节点数据维度为15×3×2=90。该数据集包含的动作大多为非周期性行为,且包含相似动作,准确实现动作识别具有一定的难度。
NTU RGB+D Dateset数据集是目前包括双人交互的RGB+D视频和关节点数据最大的数据库,包括56-880个视频片段。本数据库共有40名行为动作者,包括60个动作类别,包括日常动作、与健康相关的动作和双人交互行为。本数据库采用三个高度相同但角度不同的摄像机采集图片。动作行为人执行两次动作,一次面向左侧摄像头一次面向右侧摄像头。本数据库提供两种识别评估标准CS和CV, 本文采用CS的评估方式。
本实验基于Tensorflow平台利用keras深度学习库在GPU处理器下进行,操作系统为Ubuntu16.04,内存和硬盘参数分别为32GB、256GB+2TB,编程环境为Python3.6,程序框架Keras2.1.3。
4.2 SBU 数据库实验测试结果
1)RGB视频和关节点数据测试结果分析。
本实验在国际公开的SBU数据集中的RGB视频和关节点数据上分别做了测试,把每个动作按8∶2 的比例划分为训练集和测试集,用80%的数据训练模型,将训练好的模型用20%的视频做测试。本实验共采用200次迭代训练,每次迭代训练中训练数据与测试数据对应的准确率如图4所示。
从图4中可知,随着训练次数增加,准确率不断增加,模型的损失值不断降低。利用RGB视频数据在此模型下测试,得到的最优识别准确率为87.5%,将最终的识别结果用混淆矩阵表示如图5所示。
从图5混淆矩阵分析可知,误识别动作主要为“推”和“握手”两个动作,通过分析可知,这两类动作在视频的阶段帧与帧之间的变化幅度小,导致Vibe背景减除后得到的动作区分性不足,导致模型的误识别。
将关节点数据在构建的模型下进行测试,得到识别准确率为91.87%,把识别结果用归一化混淆矩阵表示,如图6。
从上述混淆矩阵分析可知,应用关节点数据进行识别,8种行为动作中有6种行为能达到准确识别,错误识别主要发生在握手(shaking hand)和传递物品(exchanging),因为关节点数据只对行为人的动作变化作出精确描述,不包含环境中的其他事物,对行为的外观描述信息较少,因此容易造成包含环境中其他事物的动作识别不准确。
从图5和图6的分析可以看出,RGB视频信息与关节点数据具有较好的互补性,為下一步的融合提供了依据。
2)RGB视频和关节点数据信息融合。
本文将RGB视频和关节点数据得到的识别分数作决策级融合,将两种信息源得到的识别概率矩阵加权融合送入softmax分类器得到最终的识别分数,得到最终比较理想的识别结果,识别率为92.55%。
为验证本文提出模型的有效性,本文将同样在SBU Kinect interaction 数据库上进行算法测试的结果与本文所得的实验结果相比较,如表2所示。
从表2中可知,本文提出的基于CNN的RGB和关节点数据融合的双人交互行为识别框架获得了良好的识别结果。与文献[5]和文献[6]中利用单一数据源和手动提取特征相结合的处理方法相比较,识别准确率得到了大幅度的提升。本文的识别结果与文献[13]相当,但文献[13]中引入一个信任门消除关节点数据的噪声,而本文的方法对原始含有噪声的数据没有作任何处理,采用原始的关节点数据构造基础特征。文献[12]是将每个关节点序列转化为三个片段,采用多任务卷积神经网络识别分类,但训练多任务并行的CNN模型复杂度高,训练过程复杂,而本实验中采用16层的卷积网络,迭代一次的训练时长仅为2s,识别过程中处理一帧数据的时间约为27ms, 具有较好的实时性。本文采用的方法避免对原始的关节点数据进行处理,算法相对简单,具有一定的实际应用前景。
4.3 NTU 数据库实验测试结果
1)RGB视频和关节点数据测试结果分析。
本实验在NTU RGB+D数据库的RGB视频和关节点数据上进行分别训练与测试,采用原数据库提供的CrossSubject测试模式,将动作行为人分为两组,得到的行为动作分别作为训练集和测试集。针对不同的数据源,RGB视频数据采用100次的迭代训练,关节点数据采用200次迭代训练每次迭代训练中训练数据与测试数据对应的准确率和模型损失值如图7所示。
从图7中可知,随着训练次数增加,准确率增加,由于NTU数据库很大且相机的变化角度和参与动作的人数较多,且在训练时利用batch size调整一次学习的信息量,导致模型存在一些震荡。利用RGB视频数据在此模型下测试,得到的最优识别准确率为75.82%。利用关节点数据在此模型下得到的最优识别结果为74.37%。
3)RGB视频和关节点数据信息融合。
单独利用RGB视频和关节点数据分别进行测试,结果发现“摸口袋”这个动作,在RGB视频识别过程中得到的结果较差,而在关节点数据识别过程中得到了较为理想的识别结果。本文将RGB视频和关节点数据得到的识别分数作决策级融合,将两种信息源得到的识别概率矩阵加权融合送入softmax分类器得到最终的识别分数,得到的正确识别率为80.09%,较单一数据源的结果有了较大的提升。
为验证本文提出模型的有效性,本文将同样在NTU RGB+D数据库CrossSubject测试模式下验证的其他文献得到的测试结果与本文所得的实验结果相比较,如表3所示。
由表3可知,本文提出的RGB视频和关节点数据融合并与CNN结合的网络模型结构,比文献[11]和文献[13]中采用的方法得到的识别结果大幅度提高。文献[10]采用双流并行的CNN,模型复杂度高且训练时间长; 文献[14]使用CNN模型学习共生特征,并设计一种端到端的分层式学习网络,获得了较高的识别结果,但它将骨架表示为张量的过程计算量较大,同时使用卷积层独立地为每个关节学习点层面的特征,卷积网络设计复杂; 本文采用16层卷积结构,网络模型简单且参数较少,模型训练时间短,每帧的处理时间约为27ms,同时也得到了较为理想的实验结果。
5 结语
本文根据RGB视频和关节点数据各自的优缺点,提出将RGB视频和关节点数据在决策级中有效结合起来的双人交互行为识别算法。本文充分地利用RGB视频和关节点数据互补的特性,在对两种原始数据作出合理的預处理的前提下,采用CNN的框架,进行更高级的特征提取与分类。本文采用国际公认的SBU Kinect深度数据库和NTU RGB+D数据库进行训练与测试,结果表明识别结果良好,同时避免了复杂的预处理。下一步研究重点是在当前模型的基础上引入时序建模,将两种数据源更好地结合,进一步提高双人交互行为识别的准确性。
参考文献 (References)
[1]王世刚,孙爱朦,赵文婷,等. 基于时空兴趣点的单人行为及交互行为识别[J]. 吉林大学学报(工学版), 2015, 45(1):304-308.(WANG S G, SUN A M, ZHAO W T, et al. Single and interactive human behavior recognition algorithm based on spatiotemporal interest point [J]. Journal of Jilin University (Engineering and Technology Edition), 2015, 45(1):304-308.)
[2]GAVRILA D M, DAVIS L S. 3D modelbased tracking of humans in action: a multiview approach[C]// Proceedings of the 1996 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 1996: 73-80.
[3]赵海勇,刘志镜,张浩. 基于轮廓特征的人体行为识别[J]. 光电子·激光, 2010, 21(10):1547-1551. (ZHAO H Y, LIU Z J, ZHANG H. Human action recognition based on image contour [J]. Journal of Photoelectron·Laser, 2010, 21(10):1547-1551)
[4]韩磊,李军峰,贾云得. 基于时空单词的双人交互行为识别方法[J].计算机学报, 2010, 33(4):776-784. (HAN L, LI J F, JIA Y D. Human interaction recognition method using spatiotemporal words[J]. Chinese Journal of Computers, 2010, 33(4):776-784.)
[5]LI N, CHENG X, GUO H, et al. Recognizing human interactions by genetic algorithmbased random forest spatiotemporal correlation[J]. Pattern Analysis and Applications, 2016, 19(1):267-282.
[6]YUN K, HONORIO J, CHATTOPADHYAY D, et al. Twoperson interaction detection using bodypose features and multiple instance learning[C]// Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2012:28-35.
[7]SLAMA R, WANNOUS H, DAOUDI M, et al. Accurate 3D action recognition using learning on the Grassmann manifold[J]. Pattern Recognition, 2015, 48(2):556-567.
[8]GHORBEL E, BOUTTEAU R, BOONAERT J, et al. 3D realtime human action recognition using a spline interpolation approach[C]// Proceedings of the 2015 International Conference on Image Processing Theory, Tools and Applications. Piscataway: IEEE, 2015:61-66.
[9]SIMONYAN K, ZISSERMAN A. Twostream convolutional networks for action recognition in videos[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014:568-576.
[10]LI C, ZHONG Q, XIE D, et al. Skeletonbased action recognition with convolutional neural networks[C]// Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops. Piscataway: IEEE, 2017:597-600.
[11]LIU J, WANG G, DUAN L, et al. Skeletonbased human action recognition with global contextaware attention LSTM networks[J]. IEEE Transactions on Image Processing, 2018, 27(4):1586-1599.
[12]KE Q, BENNAMOUN M, AN S, et al. Learning clip representations for skeletonbased 3D action recognition[J]. IEEE Transactions on Image Processing, 2018, 27(6):2842-2855.
[13]LIU J, SHAHROUDY A, XU D, et al. Spatiotemporal LSTM with trust gates for 3D human act in recognition[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9907. Berlin: Springer, 2016:816-833.
[14]LI C, ZHONG Q, XIE D, et al. Cooccurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation[EB/OL].[2019-03-20].http://arxiv.org/pdf/1804.06055.
[15]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for largescale image recognition[EB/OL]. [2019-01-10].https://arxiv.org/pdf/1409.1556.pdf.
This work is partially supported by National Natural Science Foundation of China (61602321), the Local Project of Scientific Research Service of Liaoning Education Department (L201708), the Scientific Research Youth Project of Liaoning Education Department (L201745).
JI Xiaofei, born in 1978, Ph. D., associate professor. Her research interests include video analysis and processing, pattern recognition.
QIN Linlin, born in 1994, M. S. candidate. Her research interests include video analysis and processing, biological characteristics and behavior analysis.
WANG Yangyang, born in 1979, Ph. D., engineer. Her research interests include video analysis and processing.
