基于特征提取偏好与背景色相关性的数据增强算法
2019-12-23余鹰王乐为张应龙
余鹰 王乐为 张应龙


摘 要:深度神经网络具有强大的特征自学习能力,可以通过多层逐步提取的方式获取不同层次的粒度特征, 但当图片目标本体与背景色具有强相关性时,特征提取会存在“惰性”,所提取特征的抽象层次较低,判别性不足。针对此问题,通过实验对深度神经网络特征提取的内在规律进行研究,发现特征提取偏好与图片背景色之间具有相关性,消除该相关性可以帮助深度神经网络忽略背景的干扰,直接学习目标本体的特征,由此提出了数据增强算法,并在自主构建的数据集上进行实验。实验结果表明,所提算法可以降低背景色对目标本体特征提取的干扰,减少过拟合,提高分类效果。
关键词:特征提取;数据增强;深度学习;背景色
中图分类号:TP391.1
文献标志码:A
Data enhancement algorithm based on
feature extraction preference and background color correlation
YU Ying*, WANG Lewei, ZHANG Yinglong
College of Software Engineering, East China Jiaotong University, Nanchang Jiangxi 33001, China
Abstract:
Deep neural network has powerful feature selflearning ability, which can obtain the granularity features of different levels by multilayer stepwise feature extraction. However, when the target subject of an image has strong correlation with the background color, the feature extraction will be “lazy”, the extracted features are difficult to be discriminated with low abstraction level. To solve this problem, the intrinsic law of feature extraction of deep neural network was studied by experiments. It was found that there was correlation between feature extraction preference and background color of the image. Eliminating this correlation was able to help deep neural network ignore background interference and extract the features of the target subject directly. Therefore, a data enhancement algorithm was proposed and experiments were carried out on the selfbuilt dataset. The experimental results show that the proposed algorithm can reduce the interference of background color on the extraction of target features, reduce overfitting and improve classification effect.
Key words:
feature extraction; data enhancement; deep learning; background color
0 引言
近年來,深度学习在目标分类[1]、分割[2]和检测[3]等计算机视觉领域取得了突破性进展,成为最有效的图像特征提取方法之一。在深度学习之前,常用的特征提取方法多为人工设计,如方向梯度直方图(Histogram of Oriented Gradient, HOG)、尺度不变特征变换(ScaleInvariant Feature Transform, SIFT)等,这些特征在特定类型对象中能够达到较好的识别效果,但所提取特征往往层次较低、抽象程度不高、判别力不足。文献[4]将传统的人工设计的特征提取方法与深度学习的方法进行了比较,发现后者提取的特征可以获得更好的图像分类效果。深度学习通过监督或非监督的方式,从大量的数据中逐层自动地学习目标的特征表示,将原始数据经过一系列非线性变换,从中提取由低层到高层、由具体到抽象、由一般到特定语义的特征,生成高层次的抽象表示,避免了手工设计特征的繁琐低效。
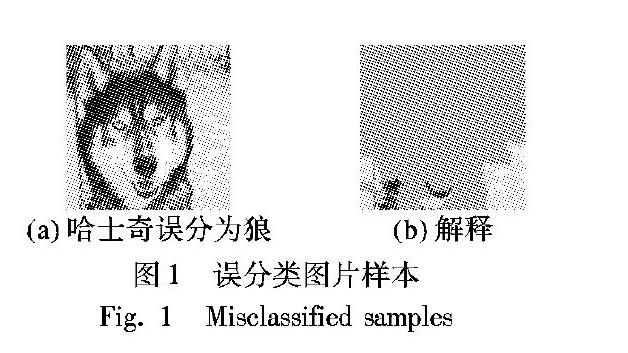
虽然深度学习在图像特征自动提取方面效果很好,但与传统的特征提取算法相比,过于依赖大规模的训练数据,主要是因为当前主流深度网络模型含有的参数一般都是数以百万计,为了保证模型可以正确工作需要大量的数据进行训练,以便不断修正模型的参数,但现实世界中,所获取的数据可能是在有限条件下拍摄的。当训练数据有限,无法表现所有情况时,所提取的特征可能不具备普适性。同时,由于深度学习模型缺乏良好的可解释性,很难理解模型内部的行为,所提取的特征到底来自图片的哪块区域是无法确定的,导致特征提取可能存在偏差。例如,文献[5]曾指出,如图1所示,在样本的刻意选取下,因为图片背景是雪地,哈士奇被识别成了狼,分类模型利用了图片的白色背景,完全忽略了动物本体的特征。此时,需要通过数据增强的方法对输入进行干涉,用变换过的数据来训练深度神经网络,帮助模型学习到本体的特征,以提高泛化能力。
因此,本文对深度神经网络的特征提取偏好进行研究,寻找特征提取偏好与数据集背景色的相关性,并在此基础上提出了相应的数据增强算法,减少过拟合。通过对训练图片进行背景色变换得到泛化能力更强的网络,使得模型在面对目标本体与背景色具有强相关性的数据集时,特征学习能够不受背景色的干扰,能真正地学习到目标本体的特征,提高分类的性能。
1 相关工作
1.1 卷积神经网络
卷积神经网络(Convolutional Neural Network, CNN)是一种深度神经网络模型,主要由卷积层、池化层和全连接层构成。近年来,CNN得到不断的发展,被广泛应用于图像处理领域中。AlexNet采用ReLU(Rectified Linear Unit)、Dropout等技术,降低了模型的计算复杂度,训练速度也提升了几倍,使模型更具有鲁棒性,并减少了全连接层的过拟合。VGG(Visual Geometry Group)[6]模型采用具有小卷积核的多个卷积层替换一个具有较大卷积核的卷积层,这种替换方式减少了参数的数量,而且也能够使决策函数更具有判别性。随后GoogLeNet[7]模型提出了Inception结构,加入了并行传播,使用了3种类型的卷积操作,提升了计算资源的利用率,但是模型的参数仅是AlexNet的1/12。为了利用网络深度对特征提取的影响,He等[8]提出了ResNet网络模型,引入了残差结构,使得深度网络可达到1-000多层,从而提取出更加精确的特征。由于ResNet直接通过“Summation”操作将特征相加,一定程度上阻碍了网络中的信息流,继而又出现了DenseNet[9]。该结构通过连接操作来结合feature map,每一层都与其他层相关,使得信息流可以最大化,提升了网络的鲁棒性并且加快了学习速度。
1.2 特征提取机制
目前已有一些学者对深度神经网络的特征提取机制进行研究,主要是通过可视化的方式,大多是针对第一层,主要是因为第一层比较容易提取到像素级特征,而较高的网络层则难以处理,但仍有一些方法从不同角度进行了尝试,比如:文献[10]通过在图像空间做梯度下降得到每个节点的最大响应,由此推断出节点的活跃性,但没有给出关于节点某种恒定属性的描述。文献[11]受此启发,对文献[12]提出的方法进行改进,通过计算一个节点的Hessian矩阵来观测节点的一些稳定的属性,但对于高层的网络节点,这些属性变量过于复杂。文献[13]通过可视化确定模型中高层节点究竟是被哪一块区域激活,但没有对节点属性进行描述,而是看图像的哪一部分激活了特征。与此类似的是,文献[14]通過在反卷积网络中引入数值解可视化CNN,探究CNN运行良好的机制。
2 基于背景色的数据增强算法
2.1 Mnist数据集转换与处理
由于Mnist数据集的目标本体与背景信息易于区分,如图2所示,有利于分析深度神经网络的特征提取机制,故本文选择对Mnist数据集进行处理与转化,其中主要进行了三种情况的处理。
第一种情况是将原Mnist训练集的图片转换成一种数字对应一种背景色的训练集A,例如将数字1的背景色转换成蓝色、将数字2的背景色转换成红色。对原Mnist测试集进行相同的转换,得到测试集X1;再将原Mnist测试集的每种数字背景色转换成除训练集A对应颜色外的9种颜色,如数字1的背景色除了蓝色可为任意其他9种颜色,数字2除了红色可为任意其他9种颜色,将满足该条件的测试集称作测试集X2;另外将测试集X2的每张图片的标签更换成其背景色在训练集A上所对应的数字类别,得到测试集X3,例如背景色为蓝色的数字标签均为1。使用训练集A训练,分别在测试集X1、X2、X3上进行测试,可以分析模型是否只学习到背景颜色特征。
第二种情况将原Mnist训练集的图片转换成每种数字可对应10种背景色的训练集B,按照同样的转换方法对原测试集进行转换得到测试集Y1。重新搜集10种颜色,这10种颜色与训练集B的10种颜色无交集,根据这10种颜色,按照同样的转换方法得到测试集Y2。通过在训练集B上进行训练,在测试集Y1和Y2上进行测试,可以分析当每种数字背景色复杂时,模型是否会学习到数字的自身特征。
为了便于不同颜色的区分,第三种情况只选择两种数字类别,将原Mnist训练集上的数字0和数字1进行背景色转换得到训练集C,每种数字独享k种背景色,如当k=1时,数字0的背景色为天蓝色,数字1的背景色为粉色,当k=2时,数字0的背景色为天蓝色或者黄色,数字1的背景色为粉色或紫色,按照同样的转换方法对原测试集进行转换得到测试集Z1。交换两类数字的背景色得到测试集Z2,如当k=2时,训练集中数字1的背景色为粉色或紫色,而在测试集Z2中数字0的背景色为粉色或紫色。通过在训练集C上进行训练,在测试集Z1和测试集Z2上进行测试,可以分析模型是否会因为某一类数字对应一定集合范围内的颜色,从而通过“蛮力”的统计方式去记住每种数字对应的颜色信息,而不去学习到数字的形状特征。以上处理方式如图3所示。
2.2 数据增强算法
设有数据集D,其中图片Xi∈D,ri1,ri2,…,ri100是从图片Xi中随机挑选的100个像素点的RGB值,使用DBSCAN(DensityBased Spatial Clustering of Applications with Noise)[15]算法对这100个像素点进行基于密度的聚类,Centeri1,Centeri2,…,Centerim分别为图片Xi经密度聚类后对应的m个簇中心点的RGB值,Distacncei1,Distacnei2,…,Distacneim分别为每个簇中心点到其他m-1个簇中心点的距离和,如式(1)所示:
Distanceij=∑m-1t=1Euclidean(Centerij,Centerit)(1)
为了避免随机挑选的点过多地出现在目标本体上,且由于目标本体与背景色的RGB值差异较大,故将最大值去掉,剩下的m-1个簇中心点的RGB值作为图片Xi的背景色RGB代表值,分别为:BGi1,BGi2,…,BGi(m-1)。
Pie为图片Xi的像素点RGB值,计算像素点Pie与图片Xi中每个背景色代表值BGiq的RGB差异度Differenceieq,如式(2)所示:
Differenceieq=(RPie-RBGiq)2+(GPie-GBGie)2+
(BPie-BBGiq)2; 1≤q≤m-1(2)
其中:RPie、GPie、BPie分別表示图片Xi的像素点Pie的三个通道值,RBGiq、GBGiq、BBGiq分别表示图片Xi背景色代表值BGiq的三个通道值。采用平方项的方式是由于改变某一通道数值产生的颜色变化效果明显于将改变的数值分布在三个通道产生变化的效果,如图4所示,故使用平方项可将在一个通道改变过多所导致的差异值放大。
C是一组RGB差异性较大的颜色集合,在对每张图片Xi进行转换前,先从集合C中随机选择一种颜色cg,对图片Xi中每个像素点Pie与m-1个RGB差异值进行比较,若存在一个差异值Differenceieq小于阈值1-000,则将该像素点RGB值用cg进行替代,若像素点Pie中m-1个差异值都大于1-000将不做变换,如式(3)所示:
pie=
cg, q∈{1,2,…,m-1},differenceieq≤1-000
pie, q∈{1,2,…,m-1},differenceieq>1-000 (3)
整体算法框架如图5所示。
3 实验与分析
3.1 模型及参数
本文所采用的CNN包含三层卷积池化层和三层全连接层,每层的卷积核大小均为3×3,卷积核的个数分别为64、128、256,池化层均采用最大池化且池化核的大小为2×2,每次池化后都进行比例为0.5的Dropout,三层全连接层的大小分别为128、64、32,最后一层为Softmax层。此外,批大小(batch size)为64,学习率(learning rate)设置为10-4,优化算法选择了随机梯度下降算法。
3.2 基于Mnist数据集的实验分析
3.2.1 第一种情况分析
图6为第一种情况的训练集A和测试集X1背景色信息,图中数字为相应颜色的RGB值。使用训练集A进行训练,并在测试集A进行测试。
图7为测试集X2的背景色信息,每个数字的背景色不使用训练集A中相应数字对应的背景色,如数字0的背景色除RGB值为(230, 189, 128)外,可为其他任意背景色。使用训练集A进行训练,测试集B进行测试,测试准确率如图8所示。
为了进一步验证训练集A是否使模型只学习到背景色特征,而忽略数字的形状等自身特征,构建测试集X3,测试集X3与测试集X2图片相同,但将标签进行更改,每张图片更改后的标签为其背景色在训练集A上所对应的数字,如将背景色RGB值为(21, 182, 18)的数字1的标签视为3,如图9所示。同样使用训练集A进行训练,测试集X3进行测试,测试准确率如图8所示。
从图8中可以看出,测试集X2的准确率始终较低,而测试集X1和测试集X3都在较短的时间内完成收敛并达到较高的准确率。可见使用训练集A并不能让模型学习到数字自身的特征,而是将图片背景色作为分类的依据。
3.2.2 第二种情况分析
图10为第二种情况下的训练集B和测试集Y1背景色信息,其中每个数字的背景色可为10种颜色。使用训练集B进行训练,测试集Y1进行测试。
图11为测试集Y2的背景色信息,每个数字背景色可为10种颜色,但与训练集B中的10种背景色无重复。使用训练集B进行训练,测试集Y2进行测试,准确率如图12所示。
从图12中可以看出,模型经训练集B训练到一定程度时,其在测试集Y1和Y2上准确率较接近,达到了较好的识别效果。可见,当训练集每个数字的背景色变得复杂时,模型能够学习到数字的自身特征。
以上实验表明,使用训练集A可使模型学到背景的颜色特征,使用训练集B可学习到数字的自身特征,其可能原因在于当一种背景色对应一种数字时,背景色可作为数字的主要特征,而当使用训练集B或原Mnist训练集时,每种颜色可对应任意数字,颜色不能作为分类的主要依据,需进一步学习其他特征。但如果每类数字对应一定集合范围内的背景色,且集合无交集时,使用满足这种条件的训练集是否能让模型学习到数字的特征,还是仅能学到每类数字对应的各种颜色信息,具体如图13所示。
3.2.3 第三种情况分析
为了进一步分析模型所学特征与数据集背景色的关系,进行了第三种情况的实验,让每种数字对应一个背景色集合,且集合间无交集。目的是验证此种情况下是否能让模型学习到数字的特征,而不是每种数字对应的背景色信息,如图14所示,分别给出了k=1和k=10时,训练集C和测试集Z1以及测试集Z2所对应的背景色信息。
当k取值从1逐渐增大到10时,使用训练集C进行训练,并在测试集Z1和Z2上测试,k取值和对应的准确率情况如图15(a)至(j)所示。
由图15可见,Z1由于训练集和测试集颜色一致,所以准确率始终保持良好。当k的值较小时,Z2的准确率很低,这主要是因为这此时将背景色作为判断依据,但是由于训练集和测试集背景色不一致,导致分类性能很差。随着k的增大,Z2的准确率在逐渐提高,说明随着背景色越来越多,区分能力越来越弱,分类模型已经开始学习数字本体的特征进行判别。
3.3 数据增强实验分析
通过以上的实验,本文发现了深度学习模型的特征提取能力与数据集的背景色具有一定的关系,故本文搜集了猫头鹰与海鸥这一类背景色有特点的图片构建数据集,由于猫头鹰大多在晚上出现,海鸥多数出现在海上或蓝天上飞行,所以猫头鹰的图片的背景大多以黑色系为主,海鸥主要以蓝色系为主。
如图16所示,训练集共有600张,背景色信息主要为猫头鹰对应黑色、海鸥对应蓝色。
如图17所示,测试集分为T1和T2两种情况,分别为200张与100張,T1与训练集背景色信息相同,T2则与其相反,即海鸥对应黑色背景和猫头鹰对应蓝色背景。由于满足T2条件的图片较少,故T1与T2图片数量分别为200和100张。使用训练集进行训练,分别对测试集T1和T2进行测试,准确率如图18所示。
由图18可以看出,模型在测试集T1上很快完成收敛,并达到较高准确率,而在测试集T2上则表现较差,且在T2上准确率随着在T1上准确率的升高而下降,可以看出模型并没有学习到猫头鹰和海鸥的自身特征信息,而只是简单地将背景色作为分类依据。
使用上文基于背景色的数据增强算法,对训练集数据进行增强,增强后的训练集部分样本如图19所示。用数据增强后的训练集进行训练,并在测试集T1、T2上进行测试,准确率如图20所示。
从图20中可以看出,经过对训练集使用基于背景色的数据增强,可在测试集T1和T2上得到较好的效果,模型不再受背景色信息的干扰,从而学习更高层次的特征信息,最终能对物体进行较好识别。通过该实验,可以发现通过基于背景色的数据增强,可以有效避免数据集中因某一背景色大量出现从而导致模型只学习背景颜色特征的“惰性”现象。
4 结语
本文通过将Mnist灰度图数据集转换成具有背景色的数据集,发现了深度学习模型特征提取偏好与背景色之间的关系,并在此基础上提出了基于背景色的数据增强算法,在猫头鹰与海鸥这类背景色有特点的数据集上进行实验,表明了本文的方法在一些目标本体与背景色具有强相关性的图像处理任务上具有一定的适用性。在未来工作中,将继续研究深度学习模型特征提取机制的内在规律,例如轮廓、纹理之间的关系,以及数据集大小对模型性能的影响,进一步分析其特征提取机制对分类性能的影响。
参考文献 (References)
[1]唐贤伦,杜一铭,刘雨微,等.基于条件深度卷积生成对抗网络的图像识别方法[J].自动化学报,2018,44(5):855-864.(TANG X L, DU Y M, LIU Y W, et al. Recognition with conditional deep convolutional generative adversarial networks[J]. Acta Automatica Sinica,2018,44(5):855-864.)
[2]PINHEIRO P O, COLLOBERT R, DOLLAR P. Learning to segment object candidates[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. New York: ACM, 2015: 1990-1998.
[3]REN S, HE K, GIRSHICK R, et al. Faster RCNN: towards realtime object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(6): 1137-1149.
[4]GONG Y, JIA Y, LEUNG T, et al. Deep convolutional ranking for multilabel image annotation[EB/OL].[2018-04-14]. https://pdfs.semanticscholar.org/3b04/9d8cfea6c3bed377090e0e7fa677d2 82a361.pdf.
[5]RIBEIRO M T, SINGH S, GUESTRIN C. “Why should I trust you?”: Explaining the predictions of any classifier[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016:1135-1144.
[6]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for largescale image recognition[EB/OL]. [2018-04-10]. http://www.cs.virginia.edu/~vicente/recognition/slides/lecture07/iclr2015.pdf.
[7]SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1-9.
[8]HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[9]HUANG G, LIU Z, LAURENS V D M, et al. Densely connected convolutional networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269.
[10]ERHAN D, BENGIO Y, COURVILLE A, et al. Visualizing higherlayer features of a deep network[C]// Proceedings of the 26th Annual International Conference on Machine Learning. New York: ACM, 2009: 1341-1349.
[11]NGIAM J, CHEN Z, CHIA D, et al. Tiled convolutional neural networks[C]// Proceedings of the 2010 Conference on Natural Information Processing System. Columbia: MIT Press, 2010: 1279-1287.
[12]BERKES P, WISKOTT L. On the analysis and interpretation of inhomogeneous quadratic forms as receptive fields[J]. Neural Computation, 2006, 18(8): 1868-1895.
[13]DONAHUE J, JIA Y, VINYALS O, et al. DeCAF: a deep convolutional activation feature for generic visual recognition[C]// Proceedings of the 31st International Conference on International Conference on Machine Learning. [S. l.]: JMLR.org, 2014: I647-I655.
[14]俞海寶,沈琦,冯国灿.在反卷积网络中引入数值解可视化卷积神经网络[J].计算机科学,2017,44(S1):146-150.(YU H B, SHEN Q, FENG G C. Introduce numerical solution to visualize convolutional neuron networks based on numerical solution[J]. Computer Science, 2017, 44(S1):146-150.)
[15]WANG X, HAMILTON H J. DBRS: a densitybased spatial clustering method with random sampling[C]// Proceedings of the 7th PacificAsia Conference on Advances in Knowledge Discovery and Data Mining. Berlin: SpringerVerlag, 2003: 563-575.
This work is partially supported by the National Natural Science Foundation of China (61563016, 61762036), the Natural Science Foundation of Jiangxi Province (20181BAB202023, 20171BAB202012).
YU Ying, born in 1979, Ph. D., associate professor. Her research interests include machine learning, computer vision.
WANG Lewei, born in 1993, M. S. candidate. His research interests include deep learning, computer vision.
ZHANG Yinglong, born in 1979, Ph. D., associate professor. His research interests include data mining, network analysis.
