基于HDFS+Spark的时空大数据存储与处理
2019-12-19贾旖旎周新民曹芳
贾旖旎 周新民 曹芳
摘 要: 海量时空数据的高效存储、读写、处理与分析是当前地理信息科学领域的研究热点。本文对目前主流大数据技术产品进行了选取和融合,开展了基于HDFS+Spark的时空大数据存储、处理分析等方面的研究和探讨,以智慧无锡时空信息云平台为应用对象,搭建了一套时空大数据存储处理的集群平台,并通过具体应用实验,得到了时空数据存储、处理、挖掘的响应时间及可视化展示结果,证实了HDFS+Spark集群计算平台在解决时空大数据存储、处理、挖掘方面的有效性。
关键词: 时空大数据;集群计算;存储处理;数据挖掘
【Abstract】: Efficient storage, reading, writing, processing and analysis of massive spatio-temporal data is a hot research topic in geographic information science. This paper chooses and integrates the mainstream big data technology production, investigates and studies the spatio-temporal big data storage and processing analysis based on HDFS+Spark ,and builds the Cluster platform. And also its applied in the experiment and the results of response time and visual display of storage, processing and mining of the spatio-temporal data are obtained, which proves the effectiveness of HDFS+Spark cluster computing platform in solving spatio-temporal big data storage, processing and mining.
【Key words】: Spatio-temporal big data; Cluster computing; Storage processing; Data mining
0 引言
随着测绘地理信息技术的发展和智慧城市建设的不断推进,时空大数據的种类愈多、覆盖愈广、更新频率愈快,数据量急剧增加,从MB、GB级逐步达到TB、PB级,使得海量时空数据在存储管理、数据检索、处理分析等方面的难度不断提升。同时,大量以分布式存储和并行计算为核心的大数据技术平台及产品随之涌现,如Hadoop、MongoDB、Spark,
这些平台及产品有望解决当前大数据在存储和处理中存在的问题。本文围绕如何应用主流大数据技术及产品更好地为时空大数据服务,结合智慧无锡时空大数据的应用需求,搭建了一套时空大数据存储处理的集群平台,并以实验验证了该平台在时空大数据的存储、处理与挖掘中的性能与效率。
1 时空大数据集群计算平台选型
HDFS分布式文件系统是Hadoop核心技术之一,提供了开源的存储框架,是一个实现数据分布式存储的文件系统[1]。该系统通过高效的分布式算法集成多集群节点,对大数据量的数据进行分布式存储和有效备份,当其中一个节点宕机时,系统可以读取其他有效节点的数据,并且系统对每个节点的物理性能要求并不高。因此,HDFS具备了容错性高、成本低、通用性好等特点。HDFS采用主/从架构,包括客户端、主控节点(NameNode)[2]和数据节点(DataNode)[3]。其中,NameNode主要负责管理文件系统的命名空间、元数据信息及客户端对文件的访问;DataNode主要负责接收并处理客户端的读写请求和NameNode的调度,存储并检索HDFS的数据块,是文件存储的实际位置,并通过周期性的心跳报文将所有数据块信息发送给NameNode。HDFS的这种主/从设计结构使得用户数据不会流经主控节点,从而提高了系统性能和效率[4]。
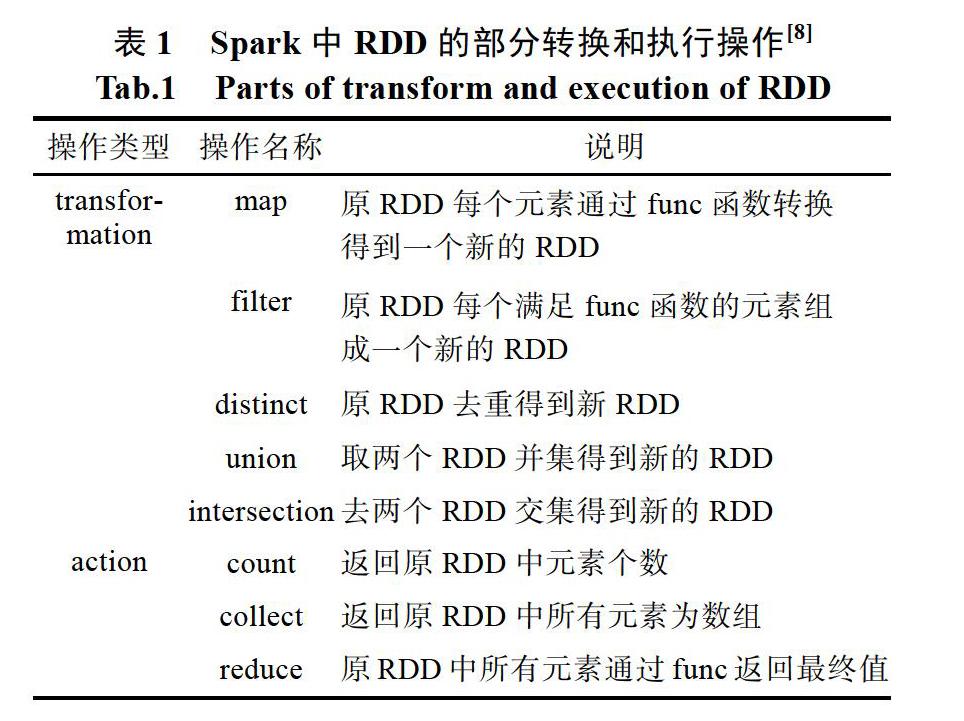
Hadoop的MapReduce和Spark是当前最流行的大数据处理平台。Hadoop MapReduce在处理分析数据时,首先从集群磁盘中读取数据到内存并执行计算,再将计算结果从内存写到集群磁盘,作为下次计算的输入数据。每次都要从磁盘读取数据到内存的计算过程,使其面临I/O消耗过大的问题,因而无法满足用户对海量空间数据开展实时分析的效率要求。而Spark作为新兴的集群计算框架,不仅提供了丰富的Scala、Java、和Python调用API接口,方便用户操作,且其基于内存迭代计算的处理方式,使其可从内存中直接读取计算数据,从而避免了磁盘I/O的高消耗。通过扩展Spark对空间数据的分布式查询处理操作,形成了GeoSpark、SpatialSpark等先进系统,可实现对海量空间数据的快速处理和分析。
由于HDFS 的高容错性、高可扩展性、高吞吐量等特点,为海量时空数据提供了可靠、安全的存储,而Spark的内存迭代计算比MapReduce更为高效[5],更适合进行交互式处理和运行复杂算法,且可以与HDFS组件进行完美融合,因此本文选择使用HDFS+Spark的存储计算框架来进行时空大数据的存储与计算处理应用。
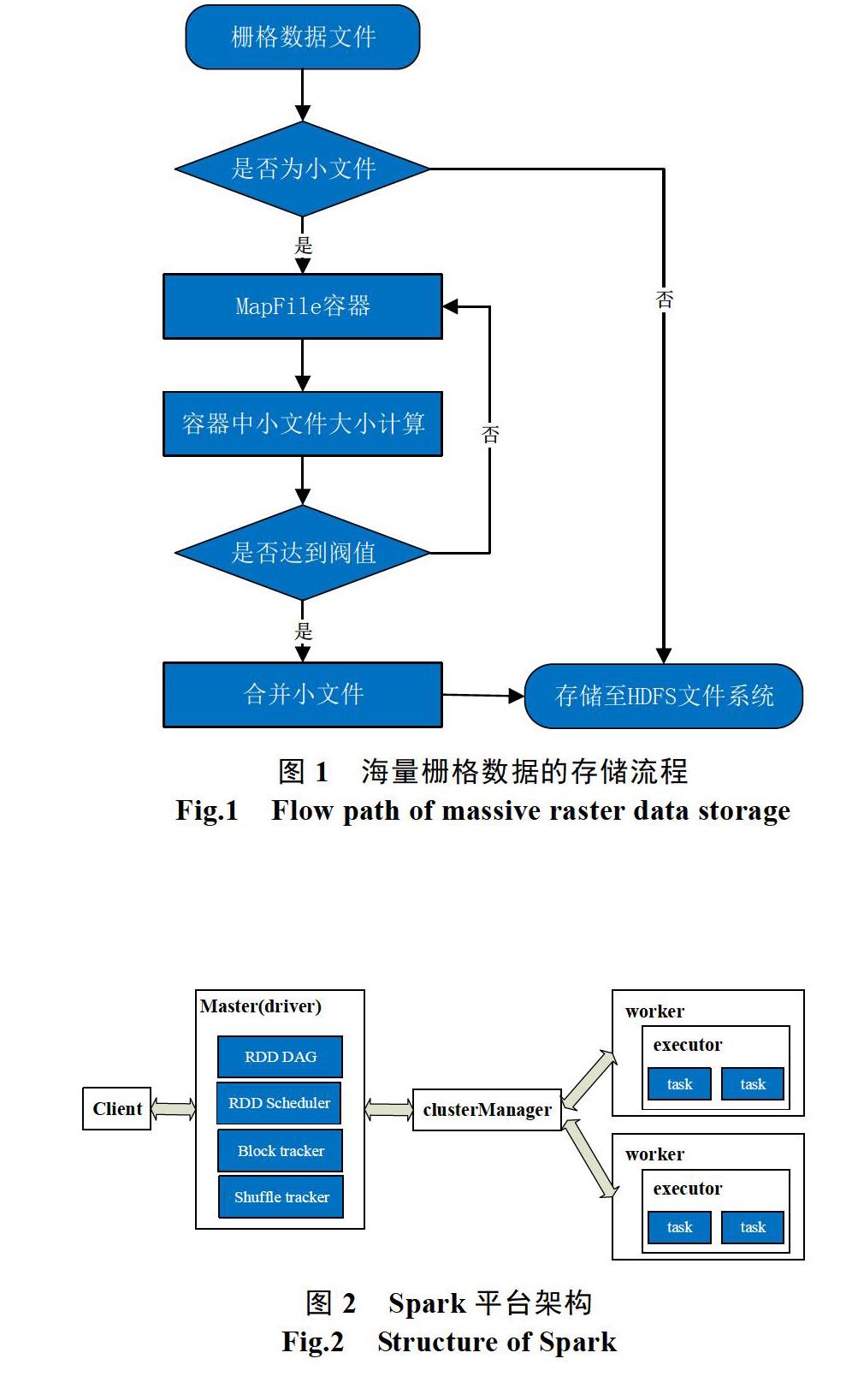
2 基于HDFS的时空大数据存储模式
时空数据一般来说包括时间、空间和专题属性三个维度的信息,有着多源、海量、更新快速的特点[6]。从数据格式上来说,时空数据通常以矢量数据或栅格数据的形式进行存储管理。
通过实验,得出单机环境与3个节点、6个节点的集群环境下不同数据量的时空数据存入时间对比表如下所示。
从实验结果可以看出,当时空数据集大小为500 M时,单机环境下数据存储时间为8秒,耗时最少,相比之下存储性能效率最高。这是因为数据量较少时,Hadoop集群中涉及到多个节点之间的数据交换,并且会自动进行数据备份,存在较为固定的数据传输时间和数据备份时间消耗。随着数据量增加到1.8 G、10 G,集群环境下的存储效率优势得到了明显的体现。尤其当时空数据增加到10 G时,单机环境下的耗时明显增加,为500 M数据耗时的103倍。这是由于单机环境的硬件配置受限所导致的,而在集群环境下,随着存储量增大,而其固定的时间消耗占比逐渐减小至可忽略不计,这时才能体现出集群环境下时空大数据存储的优势。
4.3.2 数据处理性能实验
本文将以无锡市区的地理范围划分为6497个500米×500米的格网,对每个格网内1天的出租车点位数量(约800万条数据)进行空间包含运算,以验证单机环境下与不同节点集群环境下的空间处理效率。
通过实验得出单机环境与3个节点、6个节点的集群环境下时空数据处理的时间对比表如下所示。
将无锡市6497个格网的1天的出租车点位数量空间统计的结果,在前端通过可视化界面进行展示,如图3所示。
从实验结果可以看出,由于单机环境中计算机处理器及内存的限制,1000个格网和10000個点进行空间包含运算,时间稳定在6分钟左右,效率非常低下。当数据量增加到一定程度后,单机处理能力超出界限,导致处理失败,而集群模式处理的运算效率远高于单机模式。因此处理海量数据,必须依靠Spark这种集群模式的并行处理框架,并且随着集群节点个数的增加,处理效率也会随之提高,集群环境可解决单机环境无法处理的问题。
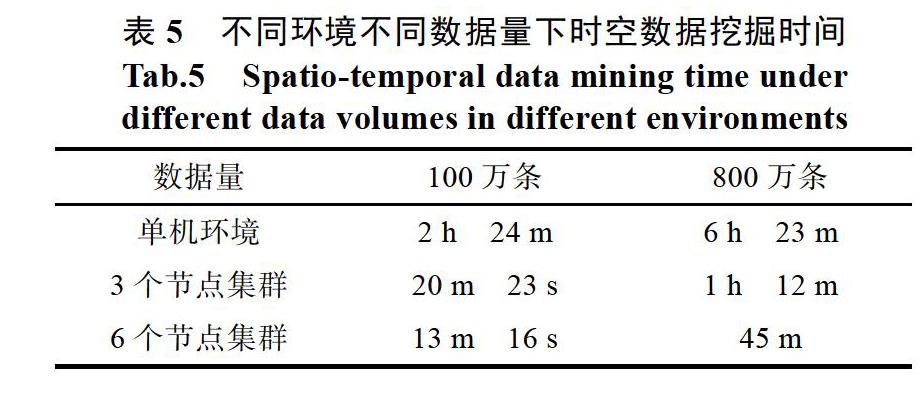
4.3.3 数据挖掘性能实验
基于K-means空间聚类算法分别对无锡市1天的出租车实时位置数据进行挖掘分析,形成出租车热点分布图,以验证单机环境下与不同节点集群环境下的时空数据挖掘效率。
通过实验得出单机环境与3个节点、6个节点的集群环境下时空数据挖掘的时间对比表如下所示。
基于无锡市某天的出租车实时位置数据进行K-means空间聚类,得到无锡市的出租车热力分布图5所示。
从实验结果可以看出,随着数据量的增大,基于集群的Spark mllib分布式机器学习框架的并行计算效率明显占优势。当数据量增加到一定程度时,单机将无法胜任此工作。
5 结论
本文通过对主流的大数据技术平台进行调研和分析研究后,搭建了一套基于HDFS+Spark的时空大数据存储计算的集群平台,并用于进行了时空大数据存储、处理与挖掘的性能实验,得出如下结论:
(1)时空数据量较少时,数据存储性能在单机环境下效率较高,而随着数据量的不断增大,集群环境的存储效率明显提升,是海量时空数据存储的理想选择。
(2)由于单机环境下硬件配置的限制和集群环境下并行计算处理的优势,时空大数据处理、挖掘的效率明显优于单机环境,并且集群节点数量越多,数据处理、挖掘的效率越高,即使当数据量超过了单机环境可处理阀值,集群环境也可以轻松处理。
参考文献
[1]Aisha SIDDIQA, Ahmad KARIM, Abdullah GANI. Big data storage technologies: a survey[C]. Siddiqa et al. / Front Inform Technol Electron Eng, 2017 18(8):1040-1070.
[2]Name Node. [EB/OL] http://hadoop.apache.org/docs/stable/ hdfs_design.html#Name Node+and+Data Nodes.
[3]Data Node.[EB/OL] http://hadoop.apache.org/docs/stable/ hdfs_design. html#Name Node+and+Data Nodes.
[4]王磊, 一种高性能HDFS存储平台的研究与实现[D]. 西安电子科技大学, 2013.
[5]Suthipong D, PeeraponV. Applying One-Versus-One SVMs to Classify MultiLabel Data with Large Labels Using Spark[C]. Knowledge and Smart Technology. IEEE, 2017: 1-4.
[6]施志林, 时空数据分布式存储研究[D]. 江西理工大学, 2015.
[7]何涛, 面向海量空间数据并行高效处理的存储模式设计与研究[D]. 电子科技大学, 2014.
[8]Zaharia M, Chowdhury M, Das T, Dave A, Ma J, McCauley M, Franklin MJ, Shenker S, Stoica I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In: Proc. of the 9th USENIX Conf. on Networked Systems Design and Implementation. San Jose: USENIX Association Berkeley, 2012. 1-14.
[9]高彦杰. Spark大数据处理[M]. 北京: 机械工业出版社, 2014.
