远程直接内存访问与检查点相结合的容器迁移*
2019-12-19谢上钦龚青泽冯光升林俊宇
赵 倩,谢上钦,韩 轲,龚青泽,冯光升,林俊宇
1.哈尔滨商业大学 计算机与信息工程学院,哈尔滨 150028
2.哈尔滨工程大学 计算机科学与技术学院,哈尔滨 150001
3.中国科学院 信息工程研究所,北京 100093
1 引言
随着云计算服务的普及,越来越多的任务和服务被部署到云计算集群上,利用虚拟化技术在硬件资源利用率、隔离性等方面的优势为用户提供服务[1]。目前,云计算厂商大都采用完全虚拟化技术[2]、准虚拟化技术[3]或操作系统虚拟化技术[4-5]给服务提供隔离的环境,增加了云计算集群的复杂性,导致集群容错能力难以得到保障。传统情况下,单一结构的集群容错方式难以适应复杂的云计算异构环境,一旦集群中某一结点出现故障,需要将该结点的任务和服务迁移到其他结点上继续运行,难以满足任务恢复的时效性和容错性需求。
Linux容器技术(Linux container,LXC)是容器虚拟化技术的典型代表[6],可以在单个宿主机操作系统上同时运行多个Linux 系统,使用控制组(control groups,CGROUPS)技术实现处理器、硬盘、内存、I/O、网络等设备的隔离。LXC提供了一个拥有自身进程和网络空间的虚拟环境,可以在单一结点上实现多个容器同时运行并保证良好隔离。相比传统虚拟机,LXC只是容器级的虚拟化技术,是一种轻量级技术,启动加载速度快,能够平衡虚拟化程度和对资源消耗。LXC 目前还不支持容器的动态迁移机制,考虑到LXC 是由若干个进程组来实现,因此LXC 容器的热迁移可以借助进程迁移机制来实现。典型的进程迁移方案可通过检查点和重启来实现[7],如CRIU(checkpoint/restore in userspace)[8]、Btrfs[9]等。Docker[10]作为LXC 管理工具的代表,其容错机制则是基于检查点和重启实现的。
目前主流的容错技术都是针对虚拟机和进程,随着容器虚拟化的推广,研究容器容错机制具有非常重要的意义。针对面向用户级容错的容器迁移机制展开探索,结合容器容错资源分配过程,在前期工作的基础上[11],提出一种基于容器容错池的容错迁移机制,利用检查点机制和远程直接内存访问(remote direct memory access,RDMA)技术,在不影响容器虚拟集群正常工作的前提下,为容器虚拟集群容错提供支撑。
2 基于容器容错池的容器迁移机制
随着云计算集群中任务种类的增多,当需要将任务迁移至容错备机时,提供迁移环境的开销增大,管理难度增大。为了提高容错备机的利用效率同时降低容错迁移拒绝率和容错迁移延迟,提出一种基于容器容错池的容器迁移机制,减少任务恢复环境耦合问题对任务迁移造成的影响。
2.1 容器迁移框架和容器容错池框架
2.1.1 容器迁移原理
云计算平台中分布着大量不同种类任务,任务负载具有高度的时变性特征,利用容器迁移技术进行负载均衡和提高资源利用率具有可行性;当集群中某一结点出现故障时,也可用容器迁移技术将服务转移到可靠结点运行且不停机,从而为用户提供无感知的服务迁移,满足服务体验要求。容器热迁移是在不中断客户端服务或者用户服务的情况下,在不同主机或云之间迁移服务程序的过程。在迁移过程中,容器的内存、文件系统和网络连接从源主机转移到目的主机,并且一直保持在不停机状态。容器热迁移的基本原理可划分为四个过程(如图1所示)[12]:(1)冻结源结点上的容器,获取容器的内存、进程、文件系统和网络连接等状态;(2)将这些状态复制到目标结点;(3)目标结点恢复状态并在此结点解冻容器;(4)源结点进行快速清理。
值得注意的是,传统的虚拟机热迁移是通过定期将内存页从源主机复制到目的主机来实现,数据中心的管理平台根据源主机和目的主机资源可用性来制定策略以及触发迁移;与传统的虚拟机热迁移不同,容器迁移需要进程迁移技术,与进程相关联的操作系统状态(进程控制块、文件表、套接字等)须与内存页一起捕获和保存,由于容器的内存占用量小于传统虚拟机,可减少迁移时间[13-15]。
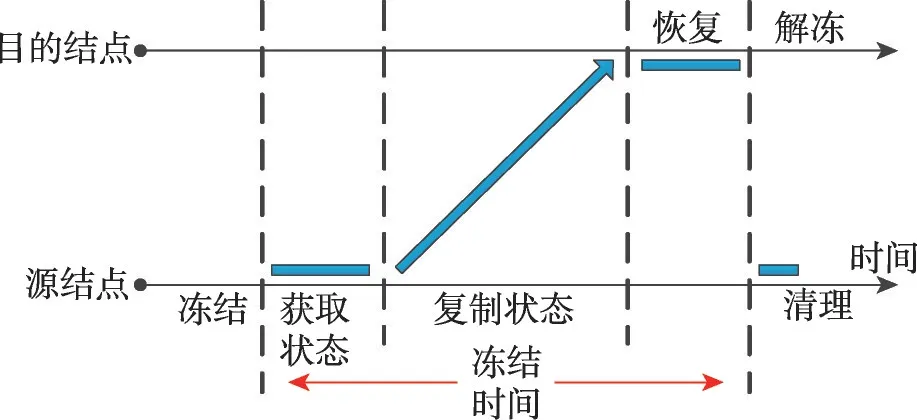
Fig.1 Principle of container migration图1 容器迁移原理
2.1.2 容器迁移框架逻辑结构
基于容器虚拟化技术和容器迁移技术将传统的容错备机虚拟成容器容错池,可以虚拟出大量的迁移环境,从而满足云计算集群异构环境下迁移任务对恢复环境高一致性的要求。为提高容错资源利用率,并减少任务恢复环境耦合问题对任务迁移造成的影响,该小节提出一种具有容错能力和可恢复集群中失效结点上任务的容器迁移框架,所提出的容器迁移框架如图2所示。
管理结点负责任务迁移全局调度和容器容错池的管理。管理结点的全局队列负责接收云计算集群中的任务迁移请求,迁移管理模块负责协调任务迁移,容错池管理模块负责管理容错池中各类型容错备机的类型转换。服务结点是云计算集群中提供服务的主机,服务以容器的方式运行在服务结点上。容错备机是容错池中的物理主机,作为任务恢复的目的结点,云计算集群中的任务迁移最终迁移到容错备机中。容错池是集中管理的容错备机资源,按提供任务恢复环境类型划分为Hot、Warm、Cold 三种类型。每个容错备机上运行着容器资源管理模块,负责本机的容器管理和任务恢复工作。存储系统用于存放检查点文件。容错备机和服务结点上都运行检查点重启代理(checkpoint-restart agent,CRA),CRA负责给容器和任务设置或恢复检查点文件。每个结点上的协调模块负责协调容器迁移过程。存储系统上的I/O Server是检查点文件系统与外界的传输接口,检查点文件系统用于存储任务的检查点文件。
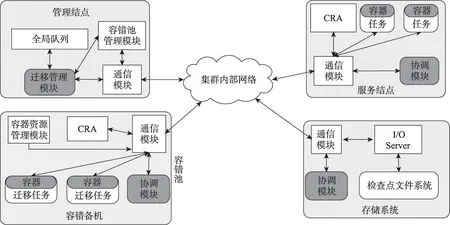
Fig.2 Framework of container migration图2 容器迁移框架
容器迁移过程主要涉及到容器迁移的全局协调和容器容错池的管理。对于多进程的任务,全局协调有利于提高任务迁移的成功率。同时,通过全局协调优化任务迁移请求在各个环境的等待时间,可以减少任务迁移恢复的延迟。容器容错池的管理是为了提高容错资源的利用率,缩短迁移环境管理对任务迁移的影响,减少任务迁移失效率,减少配置任务迁移环境产生的延迟。
2.1.3 容器容错池框架及自动伸缩策略
根据容错主机与迁移服务所需环境的吻合程度,将容器容错池分为Hot、Warm、Cold三种类型,容错资源的集中管理可以更好地分配容错资源,及时拓展或收缩容错池中的资源,降低能耗。容器迁移过程中,在容错备机中恢复任务不仅需要容器和容器中任务的检查点,还需在容错备机中有相应的容器镜像。将有容器环境且处于关机状态的容错备机放入Cold 池,将有容器环境并处于待机状态的容错备机归入Warm池,将有容器环境和容器镜像并处于运行状态的容错备机归为Hot 池。容器容错池框架如图3所示。
其中,容错资源管理器负责容错备机的管理,管理器由Hot、Warm、Cold 代理组成,分别负责Hot、Warm、Cold 类型主机的资源配置和容错备机类型的转换,如Cold 代理开启Cold 主机并加载容器镜像使其变为Hot 主机。当容器容错池中有容器容错资源请求到来时,容错资源管理器首先将请求发送给Hot代理,如果Hot 池中有合适的备机,即具有容器镜像的备机且备机资源足够恢复任务,则Hot代理直接控制该备机恢复相应的任务迁移请求。如果Hot 类型池中的备机不具备相应的资源来恢复任务,则Hot代理将请求转发给Warm代理,Warm代理在Warm类型池中寻找备机,并通过镜像文件系统中获取相应的容器镜像,将Warm类型备机转变为Hot类型备机,并在该备机中恢复任务之后将该备机交由Hot 代理管理。如果Warm 池中没有备机可用,则Warm 代理将请求转发给Cold 代理,Cold 代理从Cold 池中选取处于关机状态的主机并激活后,从镜像文件系统中获取相应的容器镜像,将Cold类型备机转变为Hot类型备机,在该备机中恢复任务之后,将该备机交由Hot代理管理。
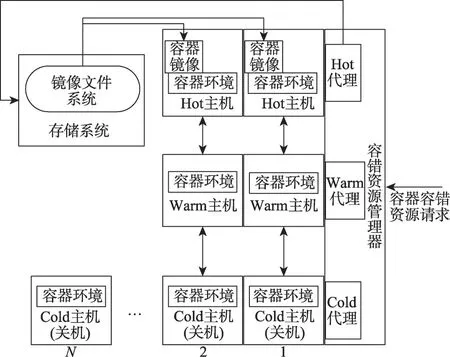
Fig.3 Framework of fault-tolerant pool图3 容器容错池框架
容错池中,每台运行恢复任务的主机要保持主机内存负载在70%以下,带宽负载在30%以下。Hot池中至少保持一台主机内存负载在70%以下,带宽负载在30%以下。Warm 池根据设置维持台主机,剩余容错主机处于关机状态,被Cold池管理。当有Hot型主机上所有服务都运行完毕后,Hot代理将关闭该主机,并交由Cold 代理管理。Warm 代理负责Warm 类型备机的管理,Warm 型备机主要处于待机状态,根据能耗需求可以调整Warm 型备机数量。Cold 代理负责管理Cold 型备机,Cold 备机可以被释放为计算主机,不作为容错资源,从而节约资源,也可以被激活并下载相应容器镜像,成为Hot类型备机。
2.2 检查点和回卷机制
2.2.1 容器检查点重启方法
在Linux操作系统中的命名空间(如图4中的父/子Namespaces)机制给进程层级提供了隔离性和自包含性的资源隔离方案。

Fig.4 Theory of PID-Namespaces图4 进程编号-命名空间原理
由图4可以看出容器及容器中任务在物理主机上经过Namespaces 机制划分的结果,容器内部1号进程为容器中所有进程的父进程,容器内1号进程和容器内其他进程在宿主机中都与相应的进程编号一一映射,容器内所有进程组成了任务进程层级。通过检查点操作可以给容器及其内部的任务设置检查点,通过重启操作可以恢复容器和容器内部的任务。
检查点操作设置检查点需要以下步骤:
(1)冻结迁移任务进程层级下所有进程,确保检查点的全局一致性;
(2)记录全局数据,包括配置信息和容器的全局状态;
(3)记录迁移任务的进程层级关系;
(4)记录单个进程的状态,包括资源描述符、阻塞和挂起信号、CPU 寄存器数据、打开的文件、虚拟内存等;
(5)解冻任务层级下的所有进程使任务继续运行,或者终止所有进程以便进行任务迁移工作。
检查点设置由CRA 完成,从用户的角度不需要更改用户任务的代码,不需要用户任务与CRA 建立联系,CRA对于用户任务是透明的。以Linux系统为例,CRA需要存储以下文件信息:
(1)存储Linux 系统/proc/pid/smaps 文件和/proc/pid/map_files/目录连接用来确定迁移任务使用的内存空间,迁移任务映射的文件,迁移任务分割MAP_SHARED区域的共享内存标识符;
(2)/proc/pid/pagemap文件中重要的标识符;
(3)当前显示的物理页面,匿名MAP_FILE |MAP_PRIVATE映射。
恢复检查点过程如下:
(1)创建一个新的容器环境并配置成迁移任务的运行环境;
(2)根据检查点文件创建迁移任务的进程层级;
(3)根据检查点文件的设置顺序恢复所有进程的状态;
(4)运行所迁移任务进程层级下的所有进程继续运行。
任务恢复过程由容错备机的容器资源管理模块协助,容器资源管理模块负责创建和配置容器运行所需的环境,并在容器中生成迁移任务的进程层级。一旦进程层级完成所有的进程将执行系统调用重启函数恢复运行。保证容器恢复后容器内任务的完整性,生成的进程层级结构需要保持进程之间的依赖关系,例如父子进程关系、线程、进程组和会话等。因为进程层级是在用户空间生成的,进程之间的依赖关系必须在恢复过程中建立,因此任务恢复过程必须依据检查点文件中存储的进程层级关系。进程恢复的过程是非常重要的,而且一些依赖关系没有直接在进程层级结构中反映,如孤儿进程必须在正确的会话组中恢复。
一旦进程层级被恢复,所有的进程通过重启系统,根据检查点顺序在内核中恢复。在CRA 的协助下,迁移任务进程层级下的子进程依次恢复。内核中,重启函数被外部调用触发。首先,CRA创建通用恢复数据结构,所有进程将状态写入各自的恢复数据结构以达到完全的恢复初始化状态。然后,CRA让第一个进程开始恢复,并等待所有进程都被恢复。最后,CRA通知任务恢复正常运行,并从系统调用中返回。
相应的,待恢复的进程等待CRA 通知恢复数据结构已经准备完毕,然后待恢复进程开始初始化它们的状态。然后各个进程按照进程恢复层级的顺序依次运行,从检查点文件中获取状态,并通知下一个进程开始恢复,并等待CRA的正常运行通知。当所有进程成功地恢复相应状态后,迁移任务可以成功运行。
2.2.2 容器迁移回卷机制
云计算中心中可以运行各种各样的服务。针对科学计算程序,如消息传递接口(message passing interface,MPI)程序,对服务的持续性要求较高,周期性设置检查点就可以满足保存服务状态,减少系统崩溃对服务造成的损失。对于Web 服务等实时服务,一旦服务回卷,将会降低用户体验。同时,Web服务通常通过cookie 和session 机制保存用户状态,并结合服务集群的方式进行服务容错。每个Web请求只有几秒中的时间,不适用检查点文件来保存服务器程序的状态。可以看出,回卷机制主要针对耗时较长的计算程序,对这类程序可进行有效的检查点设置。
如图5所示,服务程序在T1时刻的服务状态是t1,此时通过C/R管理器对任务设置检查点保存t1状态。设置检查点后系统得到保存服务状态t1的检查点文件。完成检查点设置后时刻为T2,服务继续运行。在T3时刻,服务的状态为t3。此时由于系统故障或者其他因素需要将服务从源主机迁移到容错主机上,C/R 管理器通过T1时刻设置的检查点文件t1在容错主机上恢复了服务,此时服务的状态是t1,源主机上的服务被主动或被迫终止。此时服务的状态为t1,服务发生回卷,回卷过程中服务丢失了T3时刻到T2时刻之间的状态。如果服务只由一个进程组成,这种回卷对服务结果没有影响,如果服务与其他服务协同工作,回卷很可能给前序服务程序造成数据污染。因此在给服务设置检查点的时候,需要考虑服务程序在云环境中的关联性。
服务回卷对服务组的影响可根据其他服务对回卷服务产生数据的依赖程度采用不同的应对策略。采用划分服务组协同回卷机制,管理结点上的迁移管理模块会将有关联的服务列入一个同步表中,当给处在某一关联中的一个服务设置检查点时,迁移管理模块向同步表中所有服务发送控制信息,同步检查点的设置。当恢复服务时,同步表中的服务同时恢复。
2.3 容器迁移流程
容器迁移可以通过用户请求或故障预测机制触发。图6描绘了基于容器的任务迁移——容器迁移期间不同组件之间的交互情况。
第一阶段为容器冻结及检查点设置阶段。云计算集群中每个结点上都运行CRA,用于给容器及其任务设置检查点文件。云计算集群中部署任务的时候,管理结点会将有关联的任务部署到一个计算结点中,并记录一个任务关联表,当云计算集群中某一结点触发任务迁移时,由该结点的CRA 向管理结点上的检查点恢复控制代理(checkpoint restart control agent,CRCA)发送任务迁移请求。CRCA 会根据该任务的任务关联表向相应的CRA发送设置检查点命令,将设置检查点命令分为容器记录当前容器的全局状态和设置检查点文件两部分组成。设置检查点命令的命令头由任务关联列表组成,接收到设置检查点命令的CRA 遍历任务关联列表,将相应的容器冻结并保存容器的全局状态,并根据容器内任务的进程层级关系给相应进程设置检查点文件。
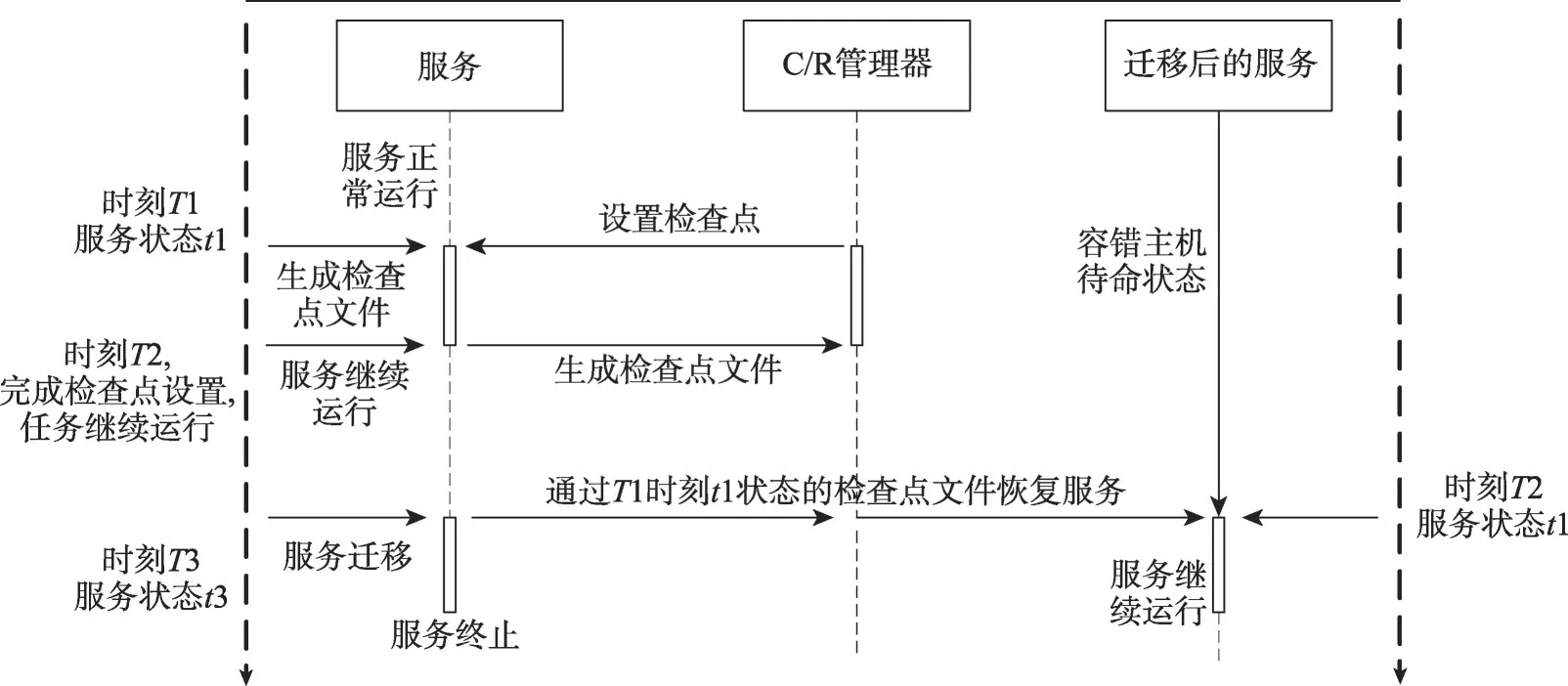
Fig.5 Process of task migration图5 任务迁移过程
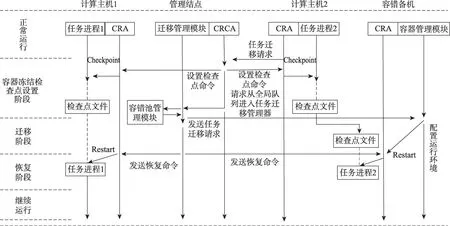
Fig.6 Process of container migration图6 容器迁移过程
第三阶段是在迁移目的结点上的容器及任务恢复阶段。容器资源管理模块对本机资源进行分配,给检查点文件恢复划分资源,并向CRA 发送重启命令,CRA收到重启命令后,同步任务关联列表中的其他任务以及容器检查点文件,根据检查点文件内容同时恢复容器及相应服务。
2.4 检查点文件传输方法优化
采用InfiniBand 模型的RDMA 技术来缩短检查点文件的传输时间。基于RDMA的检查点传输过程如图7所示。其中虚线箭头为传统网络传输过程中检查点文件的传输恢复过程。I/O Server为检查点文件系统的数据传输接口服务器,用于检查点文件的传输和接收。当有服务需要回卷恢复时,系统选取相应容错主机作为服务迁移的目的结点,随后容错主机上的检查点恢复模块调用系统内核的read函数,系统内核向内核模块发送数据请求。内核模块向I/O Server 发送检查点请求,I/O Server将检查点文件加载到缓存(如图7中的Buffer模块所示),通过网络传输给容错主机内核模块的缓存中。随后容错主机的内核模块将检查点文件从内核缓存中拷贝到虚拟文件系统(virtual file system,VFS)的缓存页面中(如图7中的cache 所示),当系统内核将VFS cache 中的检查点文件拷贝给检查点恢复模块的缓存中后,检查点文件的传输过程结束,服务将被检查点恢复模块恢复。
传统网络传输过程中,检查点文件传输和拷贝在文件读取之前完成。传输时间包括:
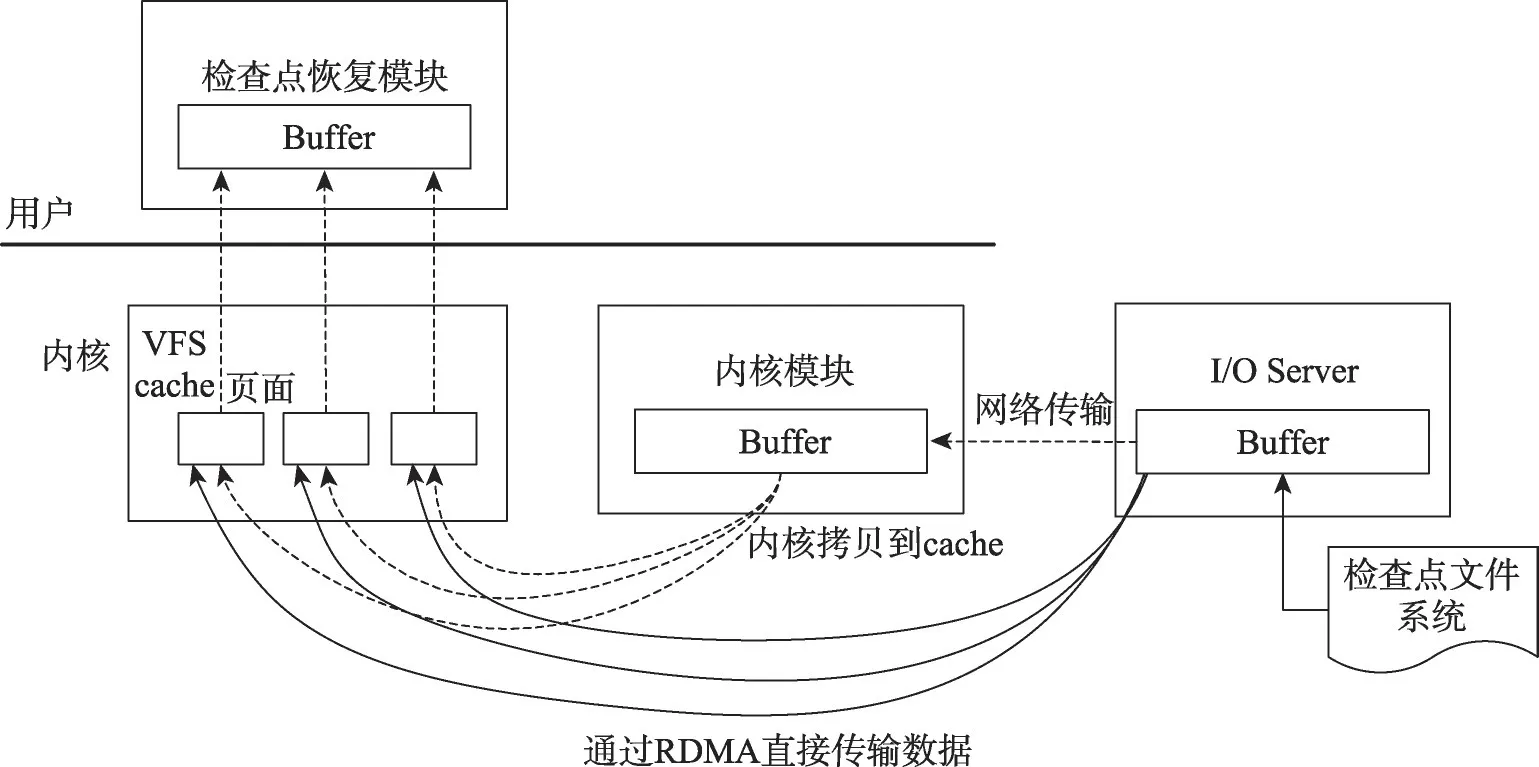
Fig.7 Transport process of checkpoint based on RDMA图7 基于RDMA的检查点传输过程
(1)检查点文件在内核模块Buffer 和I/O Server Buffer;
(2)内存拷贝,从内核模块Buffer 拷贝到VFS cache页面;
(3)内存拷贝,从VFS cache 页面传输到检查点恢复模块的Buffer中,其中第二个传输操作可以通过RDMA技术削减。
图7中实线箭头为采用RDMA 技术的检查点文件传输方式,通过RDMA 技术可以消除冗余的内存拷贝过程,节约了时间。通过RDMA技术,使文件传输像Linux内核预读功能一样,在I/O Server Buffer与VFS cache页面之间异步传输数据。
3 实验测试与方法分析
面向用户级容错的容器迁移机制研究过程主要包括容错池的构建、管理过程,容错资源的分发过程,容错备机资源分配过程,容器迁移和恢复的全局协调过程。在实验室环境下,对提出的容器迁移机制进行了过程验证,在容器环境下接收任务迁移请求的拒绝率和平均延迟,验证容器迁移框架及相关方法的有效性和可用性。
打好污染防治攻坚战时间紧、任务重、难度大,是一场大仗、硬仗、苦仗,离不开坚强有力的领导和纪律保障。今年以来,盐城市纪检监察机关认真贯彻习近平生态文明思想,按照中央纪委和省纪委部署,积极投身污染防治攻坚战,持续强化环保领域监督执纪问责,有力推动全市经济社会实现绿色转型、绿色跨越。
3.1 实验环境设置
基于InfiniBand构建了8个结点的网络通信的小型集群模拟云计算集群。实验拓扑图如图8所示。
3.2 实验过程与性能分析
为了测试基于容器容错池的容器迁移机制的性能,对任务迁移请求的拒绝率和平均延迟进行了测量。分析了基于容器容错池的容器迁移机制的实验过程及实验结果,通过对结果性能分析,验证所提迁移机制的有效性和可靠性。
3.2.1 实验过程及参数设置
实验在不同的配置和参数设置下,测试任务迁移请求的拒绝率和总的任务恢复响应延迟。实验结果展示了改变任务迁移请求到达率、任务迁移后的剩余服务时间、容错池中每个类型备机的数量、每个物理主机中容器数量和检查点文件尺寸等条件取得的效果,并获得了每个池中物理主机的稳态分布。实验参数范围如表1所示。
通过脚本控制迁移源结点发送任务迁移请求来控制任务迁移请求到达率,根据容错池的规模,将其控制为40~100之间。平均剩余服务时间为迁移任务在容错池中的剩余运行时间,通过控制任务检查点的设置时间和冻结容错池中的容器的手段来改变平均剩余服务时间,控制其范围在30~80 min。Hot、Warm、Cold 池组成了容错池,其中Hot 池中1~3台物理主机,Warm池中1~2台主机,Cold池1台主机。物理主机中容器数量为0~30个,尽管物理主机可以根据其性能容纳更多的容器,但出于实验的角度给其设置上限。Hot、Warm 池的平均查找率为各池查找空闲主机的频率。Warm物理主机转为Hot类型的时间为1~2 min,Cold 物理主机转为Hot 类型的时间为2~4 min,根据实际情况而定。物理主机上容器镜像部署时间为20~120 s,根据容器镜像的大小变化。全局队列可以容纳20~100个任务请求。物理主机的任务队列可以容纳2~10个恢复请求。
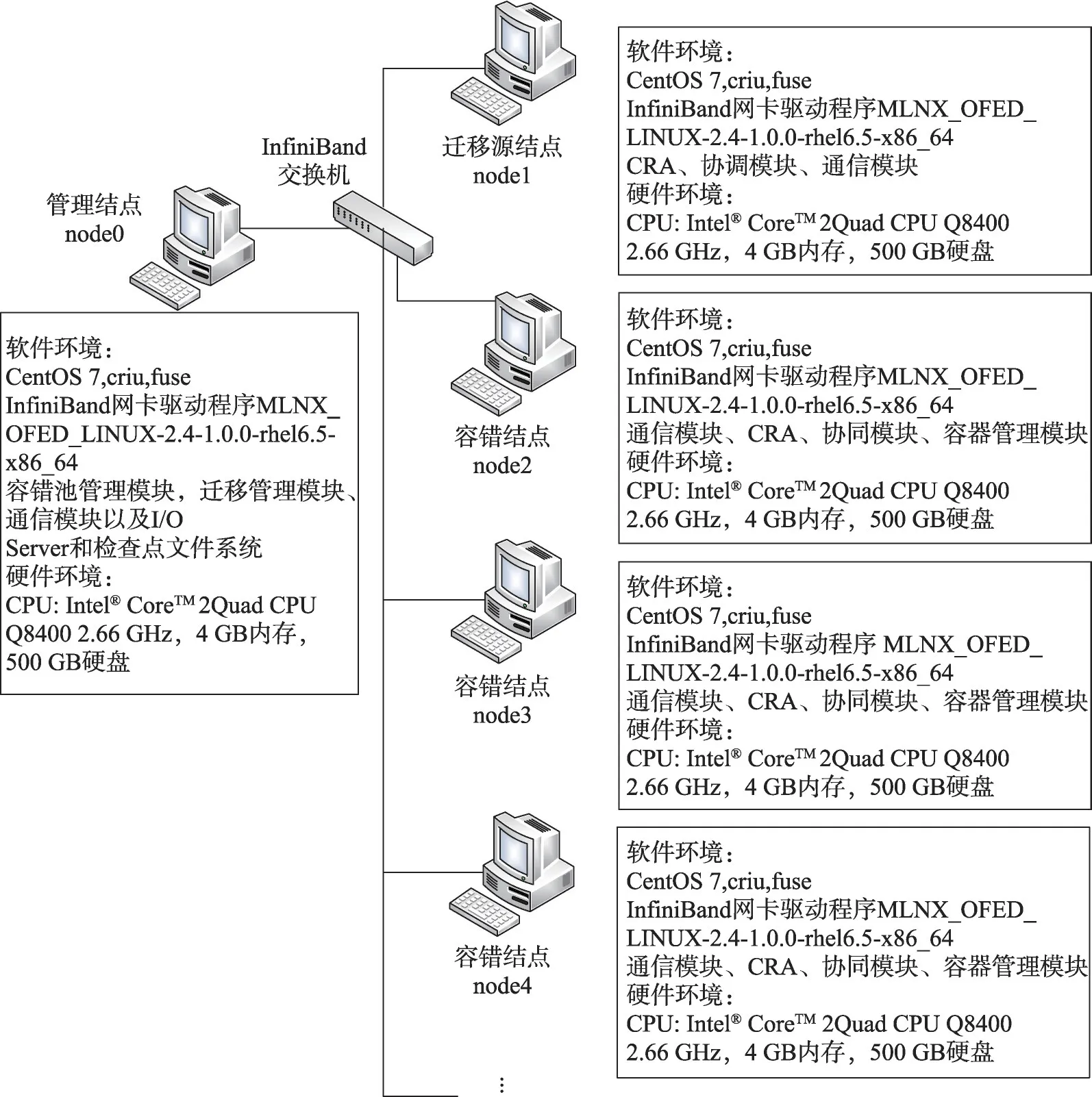
Fig.8 Topological graph of InfiniBand cluster experiment in laboratory environment图8 实验室环境下InfiniBand集群实验拓扑图
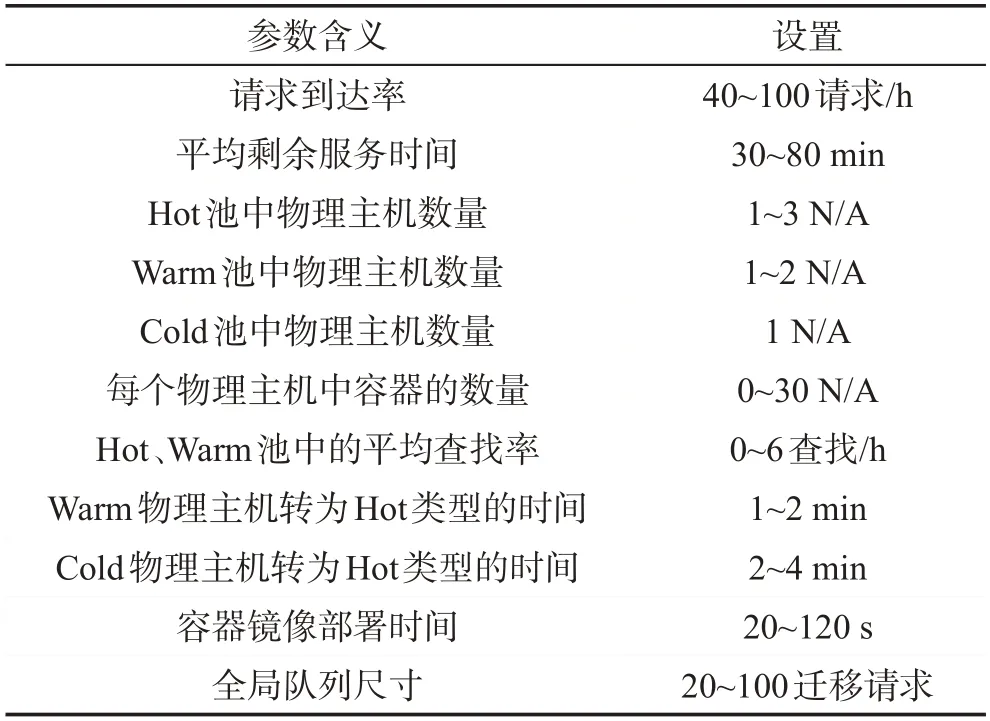
Table 1 Range of experimental parameters表1 实验参数范围
迁移源结点通过Docker 容器启动任务,并选择所需要的进程数,实验中设置为两个进程,组成任务的进程层级;实验室环境下,通过事件注入的方式让迁移源结点触发任务迁移请求,管理结点的全局队列接收到任务迁移请求,管理结点中的各个模块协同工作,完成容器迁移工作。
3.2.2 任务平均剩余服务时间对系统性能的影响
第一组实验研究容错池中任务平均剩余服务时间对任务拒绝率和总延迟的影响。每个容错备机最多可以运行30个容器。使用脚本自动发出任务迁移请求,将任务迁移请求率控制在100个请求/h,并通过挂冻结恢复任务容器的方法模拟增加任务平均剩余服务时间,恢复的任务由一个进程组成。任务迁移请求拒绝率与任务平均剩余服务时间的关系如图9所示。
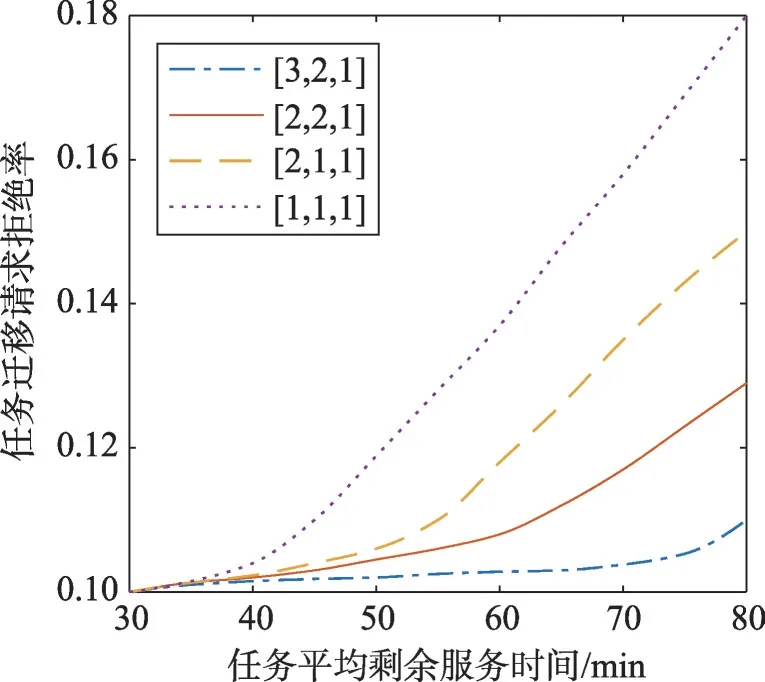
Fig.9 Variation of rejection rate with remaining service time图9 拒绝率随剩余服务时间变化
图9中4条曲线分别代表容错池中Hot、Warm、Cold类型主机的数量,如[3,2,1]代表有3个Hot主机,2个Warm主机和1个Cold主机。随着任务平均剩余时间的增长,任务迁移请求拒绝率成线性增长。随着容错池中主机数量增加,任务迁移请求拒绝率降低。无论哪种规模的容错池,在超出其处理范围的迁移请求到来时,经过一定时间的处理,都会出现满负荷运转的情况,因此都会出现拒绝率上升的情况。但是容量大的容错池明显比容量小的容错池拒绝率低。因此容错池中容错主机数量越大,容错池的性能越强,受任务剩余服务时间影响越小。
任务恢复延迟随任务平均剩余服务时间的关系如图10所示。图10中4条曲线分别代表容错池中Hot、Warm、Cold 类型主机的数量,如[3,2,1]代表有3个Hot 主机,2个Warm 主机和1个Cold 主机。对容错池管理来说,因为剩余服务时间直接影响队列中检查点文件恢复的等待时间,所以导致容错池中任务剩余服务时间越长,容错池中其他任务的恢复延迟时间就越长。在[1,1,1]这种容错池配置下,随着任务剩余服务时间增加,容错池中其他任务的恢复延迟时间明显增加,而增加容错池中主机数量使其变为[3,2,1]的话,任务剩余时间的增加对任务恢复延迟增加的影响不太明显。
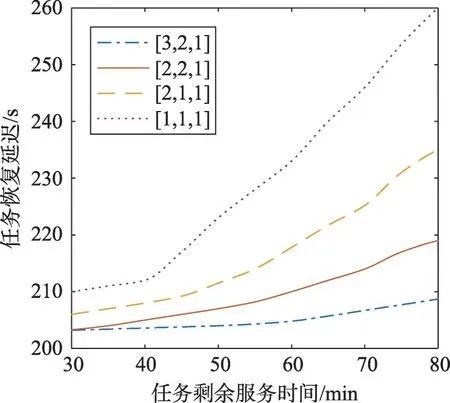
Fig.10 Variation of latency with remaining service time图10 延迟随剩余服务时间变化
3.2.3 任务迁移请求对系统性能的影响
实验将任务剩余服务时间固定在40 min,并将任务迁移请求的到达率作为变量,结果如图11所示。
当任务迁移请求到达率达到一定程度之后,拒绝率明显提升,这主要是由于全局队列不足引起的。
在较低任务迁移请求到达率下任务恢复延迟急剧增加,但当拒绝率达到一定程度之后,延迟变得平坦。这是因为高拒绝率的情况下任务恢复数量减少,因此可以通过增加全局队列的大小的方式在高延迟情况下减少拒绝率。通过本次实验可以看出,如果要增加云计算集群容错的性能,减少任务恢复等待时间和任务迁移拒绝率,可以采取以下措施:(1)增加容错池的容量,即增加容错备机的数量来减少任务恢复等待时间。(2)根据延迟情况增加全局队列大小来减少拒绝率。如图12所示。
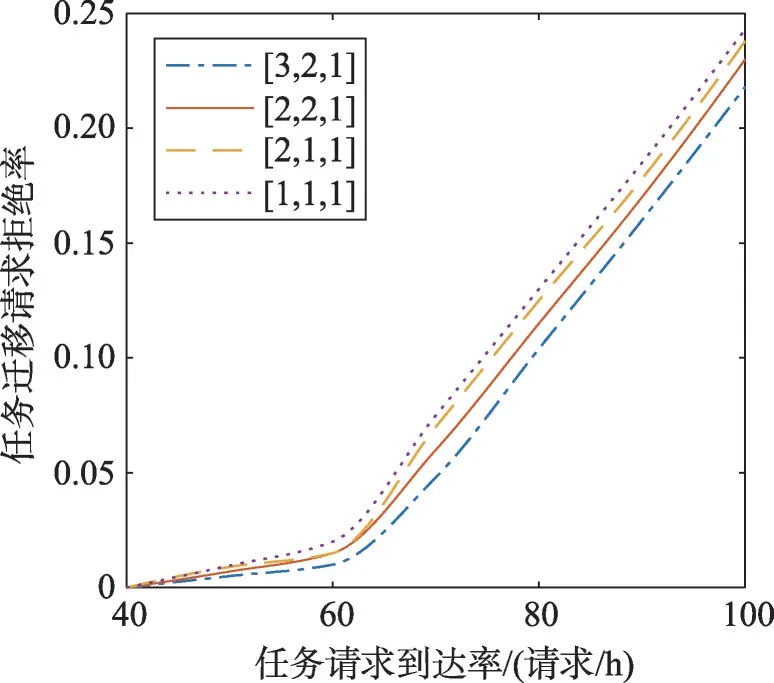
Fig.11 Variation of rejection rate with arrival rate of migration request图11 拒绝率随迁移请求到达率变化

Fig.12 Variation of latency with arrival rate of migration request图12 延迟随迁移请求到达率变化
3.2.4 池查找率对系统性能的影响
池查找率是容器管理模块查找空闲Hot 备机并将其转为Warm 或Cold 类型的频率。Hot 备机先被转为Warm 类型,然后转为Cold 类型,如果Warm 池中主机数量达到阈值,Hot将直接转变为Cold。之前的实验中,平均查找率控制在4次/h。虽然更高的池查找率将降低能量消耗,但是查找率高容易引起pingpong 效应,即一个最近关闭的备机可能很快又被重新启动,导致备机在Hot、Warm、Cold 池中频繁转换类型。备机频繁转换类型可能增加延迟和拒绝概率。
图13展示了池查找率对任务迁移请求拒绝率的影响。从图13中可以看出,容错池中备机越多任务迁移请求拒绝率越低,对于[1,1,1]容量的容错池,查找率在3次/h拒绝率最低。对于不同容量的容错池,在拒绝率最低的情况下,随着容错池容量的增加,查找率递减。对于[3,2,1]容量的容错池,查找率的改变对拒绝率影响较小。
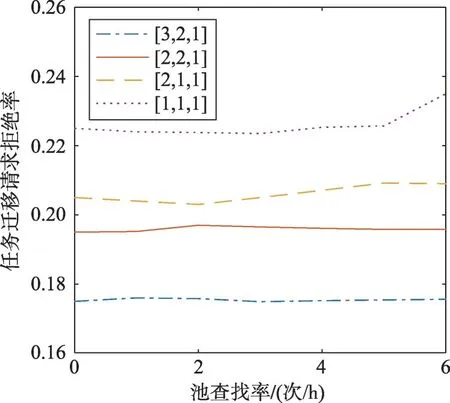
Fig.13 Variation of rejection rate with pool lookup rate图13 拒绝率随池查找率变化
图14展示了池查找率对任务恢复延迟的影响。从图14中可以看出,容错池中备机越多任务恢复延迟越小,对于[1,1,1]容量的容错池,查找率在3次/h拒绝率最低。对于不同容量的容错池,达到最低任务恢复延迟的情况下,随着容错池容量的增加,查找率递减。对于[3,2,1]容量的容错池,查找率的改变对拒绝率影响很小。
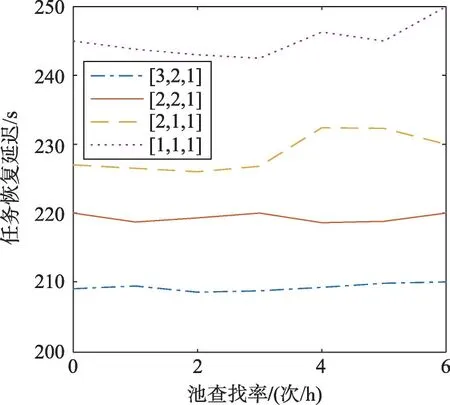
Fig.14 Variation of latency with pool lookup rate图14 延迟随池查找率变化
4 结束语
为应对虚拟化云计算集群可靠性所面临的严峻挑战,在传统集群容错和虚拟机容错的基础上,引入容器虚拟化技术,将传统的物理容错备机虚拟成容错资源池,提出一种有效的云计算集群中基于容器的容错资源分配过程和优化办法。然而,如何对容错资源的动态性进行建模,从而泛化容错资源分配过程和优化手段,仍然是未来亟待解决的重点问题之一。此外,目前针对容器迁移机制的研究主要在进程迁移技术上,如何利用容器启动和关闭快速的特点优化其迁移机制,仍然是未来的研究重点之一。
