基于决策树技术的农户小额贷款客户信用评价研究
2019-12-16尹水军
尹水军

摘要:本文研究决策树分类算法lD3算法、C4.5算法和C5.0算法的基础上,通过比较决策树几种分类算法优劣,选择决策树C5.0算法作为本文模型建立方法,并以某市农村商业银行农户小额贷款数据信息作为数据源,利用SPSS Clemen—tinel2.0开发环境建立了决策树分类模型,建立农户小额贷款客户信用评价的决策树模型,并以此帮助农村商业银行对农户信用进行评价,并作为贷款与否的依据。
关键词:决策树;C5.0 算法;农户小额贷款;信用评价
中图分类号:G642文献标识码:A
文章编号:1009-3044(2019)29-0259-04
1概述
决策树是一颗判定树,其内部结点代表属性判定,分支结点代表测试结果,叶子节点就代表一个判定类别。决策树根结点信息量最大,树的中间结点是子树中信息量最大的属性,决策树的叶子结点是样本的类别值。决策树的构建是一种自上而下的归纳过程。从根结点开始,对每个非叶子结点,找出其样本集中的一个属性对样本集进行测试。根据测试结果将样本集划分成子样本集,子样本集构成新叶子结点。对新叶子结点再重复上述过程,直至达到终止条件。构建决策树的关键环节是测试属性的选择和样本集的划分。构建决策树后可对一个新数据对象进行分析,从而判定出新数据对象的分类或取值。
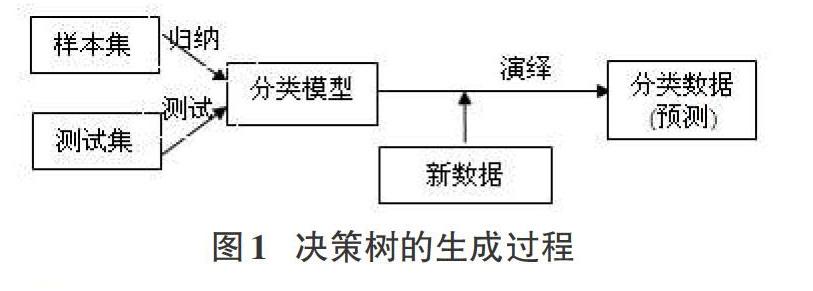
决策树的归纳学习是以样本集为基础的,它是从一组无序样本集中形成分类规则。它采用递归方式,其内部结点进行属性值的比较,根据判定并得到向下分支。最终得到判定结论。得出分类模型后,取一级已知类别的数据作为测试集,用测试集对分类模型进行测试,以验证其分类判定的正确性。决策树的生成过程可表示为如图1所示,从图中可知决策树的生成过程是一种归纳一测试一演绎过程。由训练集得到决策树分类模型的过程称归纳一过程,用测试集对分类模型进行测试称为测试过程,再由分类模型对新数据进行分类的过程称为演绎过程。
2ID3算法
ID3算法是一种基于信息熵的由Quinlan提出的决策树分类算法,其选择测试属性的依据是信息熵的下降速度,属性集的取值确定其类别。在构造决策树时,ID3算法属性选取的标准是信息增益,决策结点即为信息增益最大的属性,并由其建立分支,再递归调用该方法建立决策树结点的子分支,直至仅包含同一类别的数据为止。
5农村商业银行农户小额贷款分类模型实证研究
5.1实证背景
农户小额贷款作为金融服务的新品种,自推出以来,就受到了广大农民的欢迎,这一新的支农金融政策为支持农村经济发展发挥了积极的作用。然而农户小额信用贷款向农户发放的无抵押担保的贷款,是农村商业银行的一种创新产品。因为农户小额贷款对象经营的是一受自然灾害的制约因素较多的产业,导致各类逃债的现象极为频繁,不良贷款比率远远高于其他商业贷款,严重损害了农村商业银行的利益。因此,农村商业银行业面临的紧迫问题是建立一个信用风险评估模型,以降低农村商业银行的信贷风险。将决策树技术应用于信用评估模型,能在一定程度上解决农村商业银行所面临的信贷风险问题。本文以某市农村商业银行农户小额贷款数据信息作为数据源,利用决策树分类模型C5.0对农户信用进行评价,并作为贷款与否的依据。
5.2商业理解
在实施决策树分类前,要充分理解项目的商业目标。如果不能完全理解项目的商业目标,挖掘模型很难符合要求。在项目进行需求分析之后才能进行项目实施,以此确定系统的目标。决策树挖掘模型能将重要信息从海量数据中挖掘出来,以形成有用的规划,且这些重要信息人们很难通过观察直接得到,我们可以利用形成的规则来确定信用等级。本文以农户小额贷款相关数据信息作为测试对象,运用决策树模型形成的规则帮助农村商业银行进行信用评估,分析出农户哪些因素能确定农户信用等级,并用决策树的形式显示其相关程度,为农村商业银行发放小额贷款提供参考依据。
5.3数据准备
数据准备是决策树分类过程中一个重要环节,数据准备阶段工作量巨大。要对某一项目建立决策树分类模型,必须有明确的数据样本,因此,准备数据就成为决策树分类过程中的非常关键的一个过程。本文的数据信息主要来自某市农村商业银行2018年贷款农户的基本数据信息,考虑到运用决策树分类技术是为了发现规律,作为农户借款的依据,我们只选取了与农户信用评价关系较为密切的信息。我们总共选取采集了600份农户信息,其中300份农户信息作为训练数据集。另外300份农户信息作为测试数据集。
5.4数据预处理
數据预处理的目的是得到完整的、含噪声相对较少的、基本一致的数据。本文的农户数据信息虽然都来自某农村商业银行网点,但由于农户办理小额贷款全部分散到全市所有的营业网点,其数据的填写并非完全一致,将其整理成为一个数据库,有很多与本研究主题无关的信息需要将其摒弃,有的数据还需要进行离散化处理。
(1)数据变换。在农户信息数据库中,保存着农户基本信息,其中有很大一部分是与此次挖掘任务无关的信息,如果用全部数据进行挖掘,就会使此次挖掘变得毫无意义。本文中的农户数据信息来自不同的营业网点,部分数据缺失且不规范,将来这些来自多数据源的数据按统一格式组合、连接到一起,将部分不规范的数据属性作规范化变换。例如。本次挖掘模型中,为方便运用挖掘模型,将家庭收入来源分为三类,包括纯种植业收入、种植业和畜牧业、种植业、畜牧业及其他混合。
(2)数据清洗。采集来的数据中有些是与个人信用风险评估无关的数据,在数据模型建立前必须将其清除,否则将会影响建模效果。本次采集的数据中。由于源数据库包含的个人客户信息很多,有些信息与个人信用评估基本没有关系,如农户姓名、农户身份证号码、农户住址、电话号码、合同编号、合同签订日期、贷款调查人、贷后管理人员等,为简单起见,直接从数据库中删除。
(3)噪声处理。在最终形成的农户信息数据库中,有一些数据明显偏离预期挖掘目标、不符合建模要求、空缺值多、有误差等数据进行清洗或修正,最终得到比较整齐的、干净的、可以用作数据处理和模型开发的数据样本。
此次采集到的数据,通过多次使用上述方法进行数据预处理,从农户小额贷款处理数据集形成一个适合数据挖掘任务的数据集,这个集合共有600条记录,每条记录由9个字段组成,分别为:农户年龄、婚姻状况、供养人数、家庭年平均收入、月还款收入比、家庭收入来源、贷款用途、贷款数额以及信用记录。
5.5基于C5.0算法的数据挖掘模型的构造
将决策树预测应用于农村商业银行农户贷款信用评价问题中,基本思路是:根据已知的样本与原始信用评价状态,运用决策树发现贷款人信用状态与其某些特征属性之间的关系,使得能够通过对农户这些属性的具体观察值,对贷款人的信用情况进行预测。
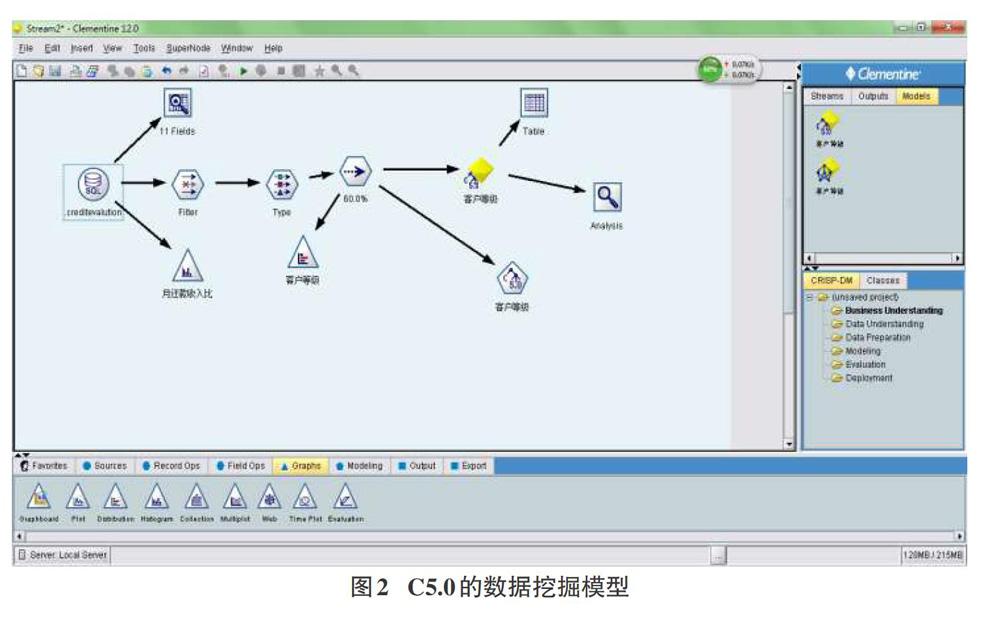
本文采用SPSS Clementine12.0数据挖掘分析工具设计数据挖掘流,得出挖掘结果并进行针对主题的分析,根据需求所建立的数据挖掘模型如图2所示。
5.6挖掘模型执行结果分析
由于挖掘模型选择月还款收入百分比作为根结点,所以能够得出的结论是:农村商业银行要对农户进行贷款前的评估,农户的月还款与收入的比值与农户的评估等级关系最为密切,其次是家庭收人来源,这两项对评估农户的信用等级最为重要,再是家庭平均收入和贷款数额,这两项也与评估农户的信用等级关系较为密切。此外,婚姻状况、信用记录、供养人数、贷款用途也与评估农户信用等级存在一定的关系。农户年龄虽然与评估农户的信用等级相关,但相关度还是非常弱的。通过用决策树C5.0算法对农户信息数据库的实证分析,笔者认为农村商业银行对农户进行贷款,不应重点关注贷款数额的多少,更应该注重农户的还款能力,而且应重点关注农户的家庭收入来源。
对上面的分析结果,也可以用图表形式浏览挖掘模型,当选择数据模型页面中的Viewer页面后,得到一个浏览窗口,该浏览窗口是用一个形象的树来描述模型,且能清晰地看到各个结点中客户信用评级情况,如图3所示。
5.7C5.0模型准确度分析
前面用C5.0决策树模型分析农户信用评估信息后,利用训练集的数据来检验此模型的准确程度,执行测试集的数据流的分析结果如图4所示。
从C5.0模型准确度分析图可以看出,用C5.0算法对农户训练数据集进行测试后,此模型的准确率为86%,数据总数为300个,错误率为14%。从准确率来看,用此模型对农户数据信息进行分析的结果具有一定的参考价值。但不意味着具有这些特征的农户都只要放心贷款,因為此模型的错误率为14%,略为偏高,分析其原因可能是本次挖掘所得到的数据并不全面,或是农户数据信息过少引起的,或者是所选择的数据中还有一部分数据也具有一定的噪声。因此,在数据挖掘中,应该选择农户数据信息足够多,且必须花大量工作来进行数据预处理,这样才能为农村商业银行提供有真正意义的贷款依据。
6结束语
农户小额贷款是面向农村的金融服务的新品种,是国家高度重视“三农”问题的真实体现。如何充分地利用农户信息,把数据挖掘技术应用到小额贷款业务是当前农村商业银行面临的一个非常重要的现实问题,通过建立新的评价模型辅助信贷管理人员进行决策与分析,真正地做到对农户进行客观的评价,从而达到加强信贷能力减少不良贷款产生的目的。
