基于改进K-Means聚类算法的互联网涉烟违法犯罪区域划分研究
2019-12-16吕飞
吕飞
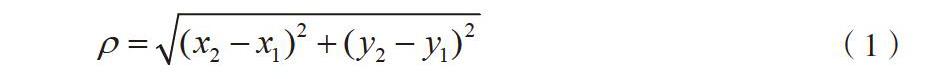


[摘 要]近年来,利用物流和快递从事卷烟非法交易的违法犯罪活动日益猖獗,随着烟草行业打假打私力度不断增大,各级烟草专卖管理部门在物流寄递渠道均查获了大量的涉烟案件数据。由于目前行业内外鲜有对该类案件进行大数据分析研究,因此,本文以理论结合实际,首先介绍了数据挖掘技术中聚类算法相关理论,重点对经典K-Means算法及其相关改进算法进行了研究,然后以W市烟草专卖局的真实涉烟案件数据进行实验仿真,通过分析历史各类案发地址等信息,帮助烟草专卖执法人员在涉烟案件经营侦办、卷烟消费市场监管等方面开展精准打击、重点治理。
[关键词]烟草专卖;市场监管;数据挖掘;聚类分析;K-Means算法
doi:10.3969/j.issn.1673 - 0194.2019.22.077
[中图分类号]TP391.3[文献标识码]A[文章编号]1673-0194(2019)22-0-05
0 引 言
近年来,不法分子利用物流寄递渠道,将非法卷烟销往全国各地,严重干扰了正常卷烟市场秩序,使国家税收流失,消费者利益受到侵害。为进一步加强对物流寄递领域涉烟违法行为的监管,自2016年起,烟草行业逐渐加大了对利用互联网制售假冒卷烟犯罪活动的打击力度,积累了大量的物流寄递渠道涉烟案件数据。但是,由于缺少大数据的整理整合以及内在价值的挖掘分析能力,在目前的烟草专卖市场监管和案件侦办工作中,“数据丰富、情报匮乏、手段单一”的现象仍然存在。如何有效利用这些历史案件数据,全面、客观、系统地挖掘互联网涉烟案件线索,深入拓展卷烟市场监管的新领域,以实现新时期烟草专卖管理的高质量发展,是目前迫切需要研究的课题。数据挖掘作为当前一种新颖高效的数据分析手段,如今被广泛应用在各行各业,例如数据库营销、客户关系管理、顾客行为预测及市场趋势预测等,在公安部门情报侦察、案件侦办领域也发挥着举足轻重的作用。因此,利用数据挖掘方法对物流寄递渠道的海量涉烟案件数据进行深入研究,充分挖掘犯罪数据中的犯罪规律、行为特征等情报价值,给烟草专卖市场监管提供帮助,是让沉淀的历史案件数据发挥最大价值的有效途径。对于如何运用大数据分析方法对烟草专卖管理领域的案件数据进行价值挖掘,行业内外鲜有相关研究,而采用类似方法的研究课题大多集中在卷烟营销领域。本文基于数据挖掘中的聚类分析K-Means算法,围绕互联网涉烟案件中的大量案发地址数据,开展智能化自动分类和辅助预警,以帮助一线烟草专卖执法人员迅速了解和掌握管辖市场的违法犯罪活动高发区域和活动中心,准确开展市场信息分析,全面推动卷烟市场监管由“人工经验”向“数字决策”转变。
1 聚类算法概述
1.1 聚类算法
聚类算法是一种非监督机器学习算法,实质是按照特定的标准把一组数据对象划分成若干类子集或簇的过程,使同一个子集或簇的数据对象相似度尽可能大,不同子集或簇的数据对象差异性也尽可能大。即聚类后具有相似属性的数据对象尽可能聚到一起,不同的数据对象尽量分离。聚类算法有很多种,分为划分法、层次法、基于密度的方法、基于网格的方法、基于模型的方法等。每一类中都有目前广泛应用的算法,例如,划分方法中的K-Means聚类算法、层次方法中的凝聚型层次聚类算法、基于密度方法中的DBSCAN聚类算法等。
1.2 经典K-Means算法
经典K-Means算法由于简单易实现且效率高,是聚类算法中最流行、使用最广泛的算法。该算法主要采用距离作为相似性的评价指标,认为子集或簇是由距离靠近的对象组成,最终目标是获得紧凑且独立的子集或簇。即以k为参数,把n个对象分成k个子集或簇,使子集或簇内具有较高的相似度,而子集或簇间的相似度较低。经典K-Means算法主要分为4个步骤。
步骤1:从样本数据集中随机抽取k个值作为初始簇的质心。
步骤2:将每个剩余的样本数据划分到距离最近质心所在的簇。
步骤3:重新计算每个簇内样本数据的质心。
步骤4:重复步骤2和3,直到每个簇内样本数据的质心不再变化或达到设定的迭代次数后停止。
在计算过程中,距离的计算采用欧式距离,在二维空间的计算公式如下。
ρ为迭代次数,k为簇的数目,n为数据个数。经典K-Means算法的计算时间与n线性相关,所以该算法速度很快。
但是,经典K-Means算法在开始之前,需要人工指定两个参数:初始质心和簇数目k。初始质心通过随机选取,簇数目k也凭经验设定。这样做的缺点是,如果初始质心的位置选择不当,例如都在一个簇里面,那么不仅会大大增加迭代次数,最终的聚类结果也比较糟糕,往往只能得到局部最优解。同样,簇数目k在聚类之前就设定也不符合工作实际,例如,专卖执法人员在开展海量案件数据分析之前,不可能知道案发区域大致可以划分为哪几个块。因此,需要对经典K-Means算法进行改进,科学选择初始质心并初步确定最优k值。
1.3 初始质心的选择
初始质心的选择方法有很多种,有经典的随机选择、层次聚类、基于最近邻密度等。本文主要基于K-Means++算法进行初始质心选择改进,具体步骤如下。
步骤1:从数据集中随机选取一个样本点作为初始质心C1。
步骤2:计算每个样本与当前已有质心之间的最短距离(即最近质心的距离),即D(x).
步骤3:计算每个样本点被选为下一个质心的概率:。
步骤4:按照轮盘法选择出下一个質心。
步骤5:重复步骤2、3、4,直到选择出k个质心;
步骤6:基于选定的质心执行经典K-Means算法。
由以上步骤可以得知,除第一个质心是随机选择以外,后继是距离当前已有质心越远的样本点有更高概率被选择,当然这也非常符合人们的直觉,即簇中心相互离得越远越好。
综上所述,K-Means++与经典K-Means的区别就在于初始质心的选择上,确定好初始质心之后,其余步骤都同经典K-Means一样。例如,对于有12个样本点的数据集,坐标分布及序号如图1所示。由图1凭经验可知,该数据集可以划分为3个簇。假设第一个初始质心随机选择了6号样本,若按照经典K-Means算法,则后续初始质心中除6号以外的其余样本点被选中的概率均等。若后续初始质心仍然选中在B簇中的样本点,则对合理聚类十分不利。在K-Means++算法中,从第二个初始质心选择开始,需要进行以下概率计算。
从表1可以得知,下一个聚类中心点落在1~4点的概率区间为[0,0.391 304](例如其分别落在点1、点2的概率为[0,0.086 957][0.086 957,0.228 261]),落在5~8点的概率区间为[0.402 174,0.434 783],落在9~12点的概率区间为[0.521 739,1]。也就是说,选到前4个点和后4个点的概率总和非常接近1,而这也是人们希望看到的,体现了质心相互离得越远越好。此时,只要随机生成一个0~1之间的数(如matlab中的rand函数),就能确定好下一个质心(离当前已有质心较远的点有更大的概率被选为下一个质心)。以此类推,当k个初始质心选好之后,继续进行经典K-means算法。
1.4 最优k值的确定
k值的设定直接决定了K-Means算法的聚类簇个数,如果设置不当将直接影响聚类结果。以图1样本数据集为例,将k值分别设置为2和4时,聚类结果如图2和图3所示。由图2和图3可以得知,若k值设置不当,聚类结果明显不符常理。其实很多情况下,对数据集进行簇劃分本身并没有绝对清晰和正确的结论,这取决于人们对数据集本身意义的个体认知。因此,研究能够自动求解正确k值的算法是非常困难的,只能从多个角度对k取值进行评估。本文采用基于SSE指标的评价方法对k值进行评估,并给出最优k值建议。
SSE(sum of the squared errors,误差平方和)计算公式如下。
其中,Ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(k中所有样本的均值)。
核心思想是采用肘部法则,即随着聚类数k的增大,数据集的划分会更加精细,每个簇的聚合程度会逐渐提高,随之误差平方和SSE自然会逐渐变小。首先,当k小于真实的聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大。然后,当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,此时SSE的下降幅度会骤减。最后,随着k值的继续增大而趋于平缓。也就是说SSE和k的关系图是一个类似手臂肘部的形状,而这个肘部对应的k值就是数据集的最优聚类数。当然,肘部法则也存在一定缺陷,由于需要对每个k值进行聚类,考虑到计算复杂度,所以k取值上限一般不超过10。不过对于研究地理区域划分这一课题,本身对聚类结果的簇数量没有过多要求,一般也在10以内,故该缺陷对本次研究没有多少影响。
仍然以图1数据为例,利用肘部法选取最优聚类数k。具体做法是让k从1开始取值,直到上限8,对每一个k值进行聚类并且计算对应的SSE,然后画出k和SSE的关系图,最后选取肘部对应的k值作为最优聚类数。由表2和图4可以得知,肘部对应的k值为3,因此对于图1数据集而言,最佳聚类数应该选3,这与观测结果相吻合。
1.5 改进后算法步骤
通过上述对经典K-Means算法和相关改进算法的研究,在一定程度上解决了局部最优等问题,减少了聚类迭代次数,提高了聚类效率,对聚类簇个数也进行了评估并给出最优解。改进后计算步骤如下。
步骤1:对于给定样本数据集,设置初始k值为1。
步骤2:若k=1,则随机选择1个质心;若k>2,则计算每个样本与已选质心最短距离D(x)和被选中的概率P(x),用轮盘法选择后续质心。
步骤3:用选好的质心和k值进行经典K-Means聚类,并计算SSE。
步骤4:k自增1,重复步骤2、4,直到k>8停止。
步骤5:比较k值与SSE关系,根据肘部法则确定最优k值。
步骤6:根据最优k值进行改进后的初始质心选择,并进行经典K-Means聚类。
2 实验仿真
为了进一步验证上述算法理论在实际涉烟违法犯罪区域划分中的应用,本节选取W市烟草专卖局部分物流寄递涉烟案件数据样本进行实验。W市位于A省南部,属于A省物流寄递业核心枢纽城市之一,大量寄往A省的物流快件均通过W市进行中转。2017年起,W市烟草专卖局全面贯彻行业相关工作要求,不断加大对物流寄递渠道涉烟违法犯罪活动的打击力度,违法卷烟查获总量和人均查获量稳居A省前列,积累了大量的互联网涉烟案件数据。同时,W市通过自行研发相关信息管理系统,在案件数据电子化归档的同时,对数据格式进行了统一标准化处理,因此,数据有效性和规范化得到了保证。W市烟草专卖局关于物流寄递涉烟案件数据管理系统中,数据库的主体数据表结构如表3所示(由于涉密原因,已略去部分无关字段)。
由表3可以看到,对于每起物流寄递渠道涉烟案件,系统均记录了收发货地址信息及对应的GIS经纬度数据。本次实验采用Python编程实现,从数据库中随机选取了200起W市烟草专卖局2018年1-5月查获的物流寄递涉烟案件数据样本,提取了每起案件的收货地址GIS坐标信息,绘制了散点图,如图5所示(由于案件地址GIS数据涉密原因,故事先对其进行了统一标准换算)。
图5中,每个圆点即为一起案件的收货地点,下面对其进行聚类分析。将k值设定为1~8后,统计每个k值的SSE结果,绘制关系图,如图6所示。
从表4可以得出,当k取值为4时,前后折线斜率最大,即最优聚类簇个数为4个。接着将k值设定为4,进行经典K-Means算法,并同时计算每个聚类簇的质心,绘制聚类结果图如图7所示。由图7可以得知,该200起案件数据样本的案发地址大致可以划分为4个区域,也就是说,在W市的卷烟消费市场中,这4个区域的消费者或非法经营者从互联网购买非法卷烟的频次较高。因此,在市场监管实际工作中,专卖市管员、稽查员要对这4个区域,特别是以“★”为代表的中心区域进行重点走访和调查。
3 指导实践
3.1 发挥大数据情报导侦优势,助力物流寄递涉烟犯罪精准打击
由于物流、快递业的快速发展以及其方便快捷、隐蔽性强、伪装手段多等特点,越来越多的不法分子选择通过物流寄递渠道进行制售假冒伪劣卷烟。目前,W市烟草专卖局采取“现场检查、人工排查”的方式,选派若干名专卖执法人员进驻各物流快递企业城市分拨中心,与公安部门、邮政管理部门等工作人员一起,对每天运抵的各类包裹进行集中排查。由于通过物流寄递渠道进行涉烟非法犯罪活动通常具有“蚂蚁搬家”等少量、多频次的特点,因此,每起查获的物流寄递案件的收发货面单信息均应纳入重点检查名单,特别是查获频次较高和收件地址较为集中的面单信息。在实际工作中,由于目前缺少先进的数据分析方法,负责现场检查的执法人员只能根据自身经验,对印象中经常查获的收件人和收件地址进行重点检查,这种方法受个人能力影响较大,容易遗漏关键人员地址等信息,且不利于执法人员之间的情报沟通交流。2018年7月,W市烟草专卖局在自行研发的案件管理系统中采用了包括改进K-Means聚类算法在内的大数据分析方法,在几分钟之类即可对历史案发地址进行归类总结,并建立了情报沟通交流信息群,将近期的案发热点区域和临近的收件地址直接分发至每位现场执法人员处,确保了情报信息的研判及时、内容完整、沟通有效。2018年,W市烟草专卖局在物流寄递渠道共查获各类涉烟非法包裹7 706件,假冒卷烟762.1万支,查获总量和人均查获量实现了A省的“双第一”。
3.2 深化大數据在APCD工作法中的运用,助力卷烟消费市场精准治理
卷烟市场监管工作是烟草专卖管理工作基石,是维护卷烟市场经营秩序的基本措施。为了全面变革多年以来专卖市场监管“地毯式检查”的粗放管理模式,烟草行业从2014年起全面推行“APCD”工作法,为传统的工作模式注入新鲜血液,是烟草市场检查方法的创新之举。“APCD”工作法指通过将零售市场检查工作划分为“A分析”“P计划”“C检查”和“D处理”4个环节,通过对卷烟经营数据分析、综合监管信息分析随时掌握市场异常情况,找出市场检查的重点对象,由此可见,该工作方法重在A分析阶段。在实际工作中,烟草专卖市场管理员虽然能够通过业务系统对卷烟零售户的经营数据进行实时监测并分析异常,但是对卷烟零售户的销售行为数据和消费者的实际需求了解十分有限,缺少必要的信息获取渠道。实际上,物流寄递渠道查获的涉烟案件数据中包含了大量的行为信息,收件人、收件地址、卷烟品牌规格等数据能够为卷烟市场监管工作提供大量的情报来源。由于缺少高效的分析手段,采用人工的方式在数以万计的物流寄递涉烟案件中进行犯罪行为规律查找和统计分析难以实现,大量的案件数据被束之高阁,其中蕴含的有价情报线索白白流失。
2018年7月以来,W市烟草专卖局采用聚类算法对物流寄递涉烟案件的收货地址进行自动划分,并对划分后各区域内的零售户基本资料和经营数据进行对比,特别是对以“★”为代表的中心区域零售户进行经营数据和违法行为的关联分析,迅速定位疑似进行假冒伪劣卷烟批发行为的零售户或嫌疑人,为一线市场检查执法人员在“A分析”阶段提供了高效的研判结论,也为专卖案件稽查人员提供精准的情报来源,为全面实现情报导侦和精准打击奠定了坚实的基础。2018年,W市烟草专卖局市场检查环节查获案件数量同比增长11.7%,查获卷烟数量同比增长50.3%,成效十分显著。
4 结 语
本文运用聚类算法中的经典K-Means算法及其相关改进算法分析了互联网涉烟案件地址数据,对案件发生区域进行了聚类划分,并指出了中心区域。与传统方法相比,基于聚类的K-Means算法在检测的精准度上可能略有不足,但应用便捷、简洁高效,对训练数据集的要求低,特别是对于给定一定数量的案件数据,可以在无须人工干预的前提下快速进行犯罪活动高发区域划分,并寻找中心点,以此不断挖掘出潜在情报线索。该方法可以帮助烟草专卖执法人员在大量案件数据中快速了解案情,在卷烟消费市场监管和涉烟案件分析研判领域有广泛的应用前景。该方法适用的前提是涉烟案件地址GIS数据必须准确,否则运行结果将不具备指导意义。同时,该方法对“噪声”样本点和孤立样本点较为敏感,少量该类数据可能对最终结果产生影响,加上尚未考虑每个样本点的本身“大小”因素,即每起案件的案值不一,因此,如何“降噪”和对样本点“大小”因素进行额外加权评估,将是下一步工作需要继续研究的课题。
主要参考文献
[1]朱明.数据挖掘[M].北京:中国科学技术大学出版社,2008.
[2]张素洁,赵怀慈.最优聚类个数和初始聚类中心点选取算法研
究[J].计算机应用研究,2017(6).
[3]孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008(1).
[4]贾瑞玉,宋建林.基于聚类中心优化的K-means最佳聚类数确定方法[J].微电子学与计算机,2016(5).
[5]翟东海,鱼江,高飞,等.最大距离法选取初始簇中心的K-means文本聚类算法的研究[J].计算机应用研究,2014(3).
[6]钱政.Android平台下基于改进的K-means酒店信息聚类算法[J].淮海工学院学报:自然科学版,2014(4).
[7]王旭仁,李娜,何发镁,等.基于改进聚类算法的网络舆情分析系统研究[J].情报学报,2014(5).
[8]黎光谱.改进K-Means聚类算法在基于Hadoop平台的图像检索系统中的研究与实现[D].厦门:厦门大学,2014.
[9]徐春光.基于语义分析和改进K-means算法的新闻热点提取方法研究[D].北京:北京化工大学,2014.
[10]雷蓓丽.对打击互联网涉烟违法犯罪的思考[J].新西部,2012(12).
[11]韦颖艺.浅析打击互联网涉烟违法犯罪中电子证据采信与运用[C].//广西烟草学会2018年论文汇编,2018.
[12]刘泽林.浅析新形势下“互联网+物流寄递”涉烟违法行为监管难点及对策[J].经贸实践,2018(13).
[13]赵将.基于改进K-means聚类的推荐方法研究[D].武汉:华中科技大学,2016.
