基于嵌入式GPU的运动目标分割算法并行优化
2019-12-13马震环张三喜
张 刚,马震环,雷 涛,崔 毅,张三喜
(1.中国科学院大学,北京100049;2.中国科学院光电技术研究所,四川 成都 610209;3.中国华阴兵器试验中心,陕西 华阴 714200)
引言
在光电监视系统中,运动目标分割为进一步实现目标跟踪、目标识别、行为分析等高层应用奠定了基础。背景减除法是运动目标分割的重要方法之一,其基本思想是通过建立一个背景模型,通过比较当前视频帧与背景模型的差异分割出前景物体。背景减除法大致可分为两类,一类是基于参数模型的方法,另一类是基于非参数模型的方法。高斯混合模型[1]是一种经典的参数模型算法,它通过多个高斯分布平滑地模拟像素的变化情况。PBAS算法[2]是一种广泛使用的非参数模型算法,它是在ViBe算法[3]的基础上,利用观测到的像素点建立背景模型,为每个像素点分别设立单独的判别阈值和学习率,根据背景的变化不断更新背景模型。PBAS算法良好的性能是以计算复杂和参数量大为代价的。它需要计算图像中每个像素点与背景模型中相应像素点的欧氏距离,以一定概率自适应更新背景模型和相关参数。为达到良好的性能,需要存储30帧以上的图像数据作为背景模型以及每个像素点的模型参数。因此,若不对其进行并行优化,难以达到对运动目标进行实时分割的要求。由于PBAS算法是对每个像素点独立处理的,特别适合于在并行结构的处理器上进行实时实现。随着多核处理器的不断发展,具有强大并行计算能力的GPU越来越多的被应用于高计算需求的领域。随着CUDA(compute unified device architecture)[4-6]的推出,大大提高了GPU的可编程性,使得开发人员能更好地把GPU大规模并行计算的能力发挥出来。因此,GPU是进行PBAS算法并行优化的理想处理器平台。
本文通过分析PBAS算法和GPU的并行架构特点,在数据存储结构、共享内存使用、随机数产生机制三个方面对PBAS算法进行了并行优化。在嵌入式GPU平台Jetson TX2[7-8]上的实验结果表明,对于480×320像素分辨率的中波红外视频序列,该并行优化方法可以达到132 fps的处理速度,满足了实时处理的要求。
1 相关理论
1.1 PBAS算法原理
PBAS算法针对当前帧每个像素点,统计N个相应像素点的历史值作为其背景模型,为每个像素点建立独立的前景判别阈值和背景更新的相关学习参数,根据背景变化动态地控制这些状态变量。图1是PBAS算法的结构框图。
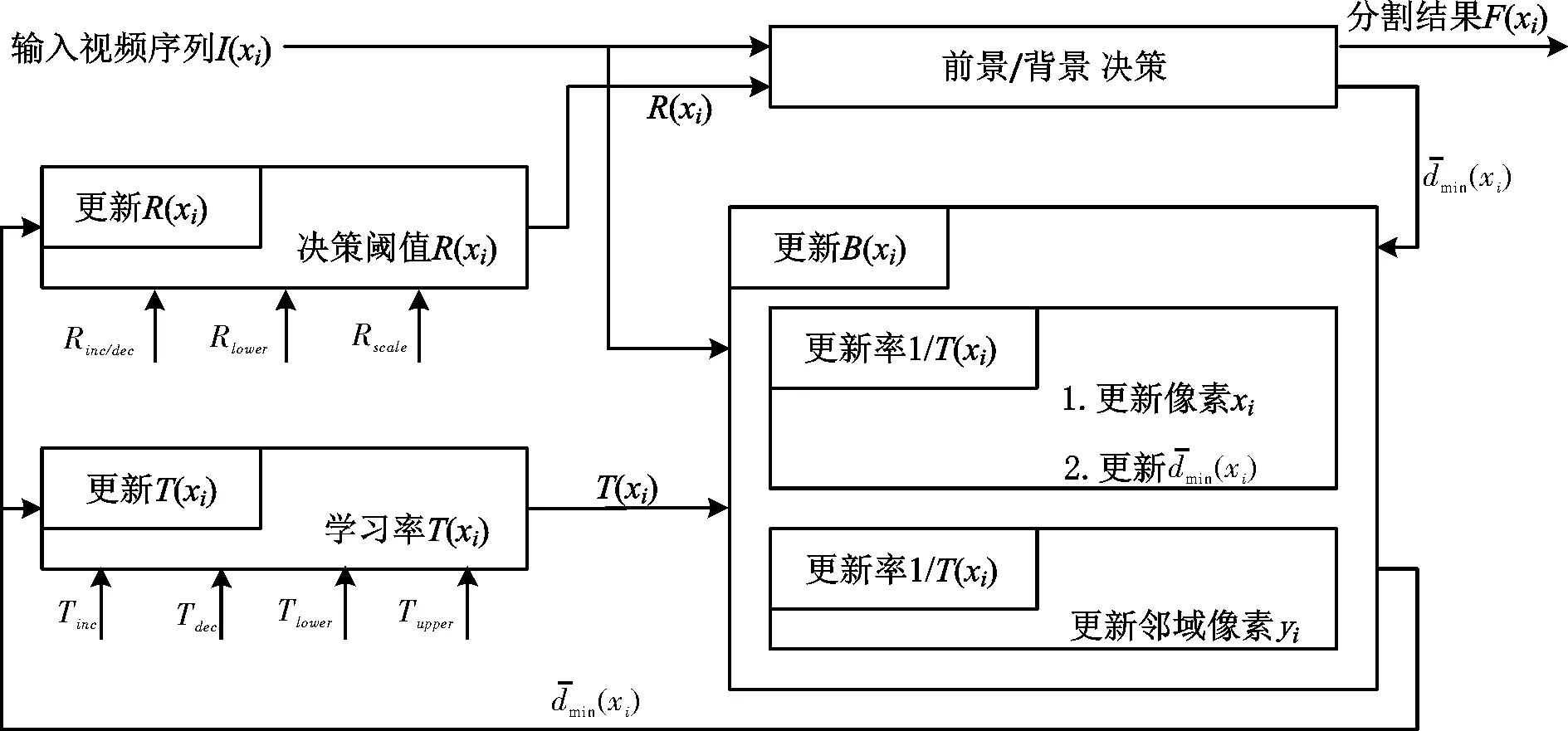
图1 PBAS算法结构框图Fig.1 Architecture of PBAS algorithm
前景/背景决策模块主要完成输入视频序列与背景模型的背景减除,分割出前景物体,其实质上是一个二分类器。在PBAS算法中,每个像素点xi的背景模型由N个背景像素点组成:
B(xi)={B1(xi),B2(xi),…,BN(xi)}
(1)
如果像素点xi的值I(xi)与背景模型中的N个像素点B(xi) 的距离小于决策阈值R(xi)的个数小于#min,则该像素点被判定为前景像素,否则为背景像素,即:
(2)
其中:F(xi)=1表示前景像素;F(xi)=0表示背景像素。有两个参数:1) 针对每个像素点xi,决策阈值R(xi)是相互独立且动态变化的;2) 小于R(xi)的背景像素的个数#min,是全局固定参数,一般取值2。
对于背景模型的更新,当某个像素点被判定为背景像素时,以概率1/T(xi)用当前像素值I(xi)随机更新背景模型中相应的像素点B(xi)。更新率T(xi)决定了背景模型更新的速度,T(xi)越大,被更新的概率越小。在更新当前像素点的相应背景像素点时,同时随机选取其邻域内的某个像素点yi,以相同的方式用当前像素值I(yi)以概率1/T(xi)更新背景模型中某个随机选取的像素点B(yi)。

(3)
其中Rinc/dec、Rscale为全局固定参数,一般分别取值0.05和5。

(4)
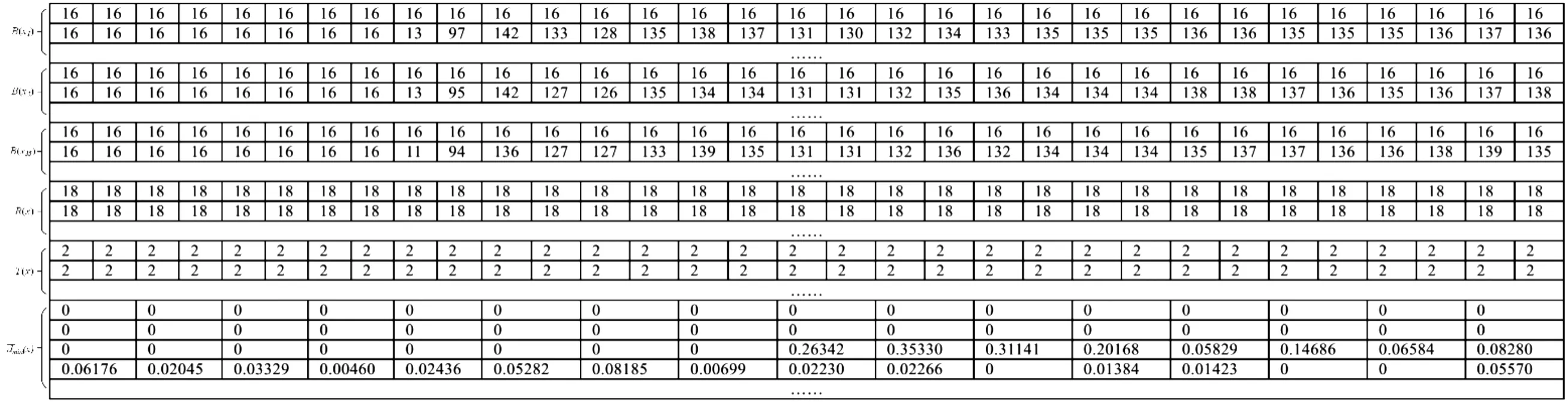
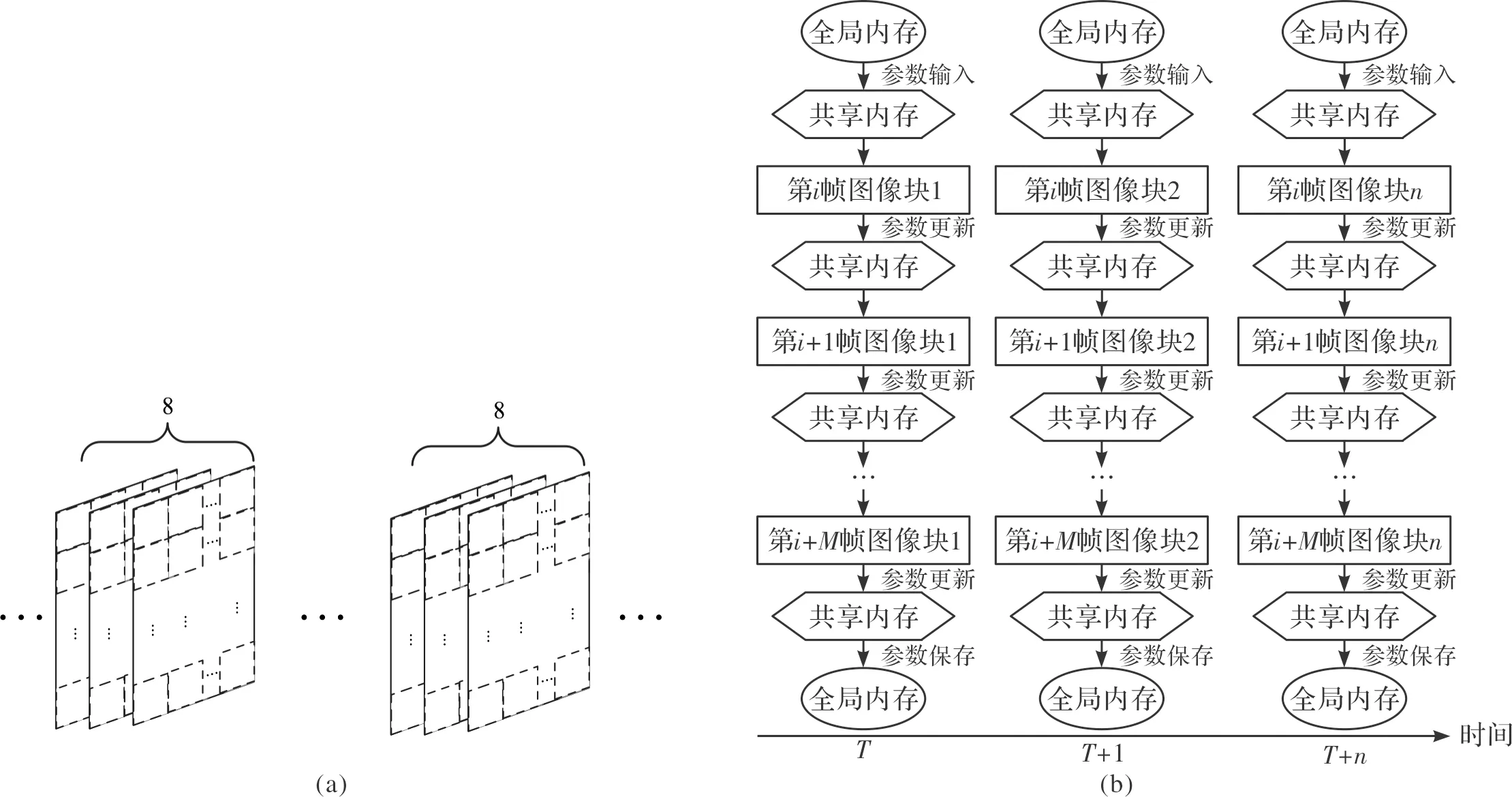
其中Tinc、Tdec为全局固定参数,一般分别取值1和0.05。同时,PBAS算法规定Tlower GPU是一种SIMT(single instruction multiple threads)架构的并行处理器[9],它的主要特点是多个线程并行执行同一条指令,处理不同的数据。在本文的实验中,我们使用的是NVIDIA公司的嵌入式GPU-Jetson TX2,它包含2个SM,每个SM包含128个Pascal架构的处理器内核[7]。图2是SM的内部结构图。由图可知,除了128个内核外,SM还包括各种存储单元、线程束调度器(warp scheduler)及其他功能单元等。 图2 SM内部结构图Fig.2 SM architecture overview GPU并行编程的核心在于线程的调度,它依靠成千上万个线程的并行执行来达到加速的目的[4]。线程束(thread warp)是线程并行执行的基本单元,通过线程束调度器调度不同的线程束到内核中执行。 GPU的存储器是一种多层异构的存储体系,如图3所示。它提供了不同层次的若干区域供程序员存放数据。其中,寄存器和本地存储器都是每个线程所独有的存储单元。共享内存的访问速度与寄存器相当,供线程束内的线程共享数据使用。全局内存位于GPU片外,CPU和GPU均可对其进行访问,可作为它们之间数据交换的介质。常量内存位于GPU片外,可对其进行缓存加速,访问速度较快。纹理内存是位于GPU片外的只读存储,它提供了地址映射和数据滤波等功能。GPU存储结构多层次的特点,对于不同的数据存储需求来说有着较强的适应能力和灵活性,妥善地处理计算数据的存储与访问对于GPU整体性能的发挥来说非常重要。 图3 GPU的存储体系结构Fig.3 Storage architecture of GPU 在GPU中,大量线程的并行涉及到频繁的内存读写,因此会造成内存访问拥塞[10-11]。另外,GPU访问一次全局内存的代价是相当大的,读写延迟一般在400 ms~600 ms。为了提高全局内存访问的效率,CUDA提供了对全局内存的合并访问机制[12]。如图4所示,当线程访问连续对齐(以32位、64位或128位地址对齐)内存块时,GPU会对这些连续的内存访问进行合并,一次读取所有线程所需的数据。 图4 全局内存访问合并原理图Fig.4 Principle of memory coalescing 图5 PBAS算法的数据存储结构Fig.5 Data storage architecture of PBAS algorithm 图6给出了本文实验数据集[11]Sequence 1的第173帧图像相关参数在全局内存中排列的结果。 图6 Sequence 1第173帧相关参数在内存中的排列结果Fig.6 Data storage architecture of 173th frame in Sequence 1 由于PBAS算法对每个像素点独立处理,与邻近像素无关。同时,第i帧某个像素点的计算结果会用于第i+1帧同一位置像素点的计算。因此,把视频序列以M帧为一组,每帧划分为K×K个大小的图像块,如图7(a)所示,处理时序如图7(b)所示。 图7 共享内存优化Fig.7 Shared Memory Optimization 对于M帧视频序列,首先从全局内存读取第1帧的第1个图像块的参数存入共享内存,计算完成后,将共享内存中的参数更新,用于下一帧第1个图像块的计算,按照此顺序依次计算M帧图像的第1个图像块,当第M帧第1个图像块计算完毕后,将参数存入全局内存。然后按照顺序在下一时刻依次读取M帧视频序列的第2个~第N个图像块进行计算。PBAS算法每个像素点的三个参数所占存储空间为36字节(三通道图像,每个参数为单精度浮点数),因此,每个SM最多可以存储约1.7 K个像素点的参数。为了计算方便,我们取K=32。如图8所示,我们对不同的M值进行了实验,当M=8时加速比最大。 图8 不同M取值时性能比较Fig.8 Performance comparison with different M 图9给出了本文实验数据集[15]Sequence 1的某组视频序列中的一个图像块的参数在共享内存中存储数值的变化。 图9 不同时刻共享内存中某个Block存储数据的变化Fig.9 Data stored in shared memory of one block in different time 在PBAS算法的计算过程中,涉及到大量随机数的使用,每个像素点的计算使用以下5个随机数:1) 背景模型更新概率randT;2) 背景模型像素点选取概率randN;3) 邻域像素更新概率randTN;4) 邻域像素点X坐标选取概率randX;5) 邻域像素点Y坐标选取概率randY。如果严格按照PBAS算法原理对每个像素点都使用上述不同的随机数进行计算,必然涉及到大量的随机内存访问,从而降低了线程并行执行的效率。为了充分利用GPU的并行架构[16-17],我们展开了如下两种随机数产生机制的实验: 1) 严格遵照算法,GPU对每帧图像的每个像素点单独产生一组(5个)随机数。 2) 每帧图像的所有像素点使用同一组(5个)随机数,CPU提前产生M帧图像的随机数存入GPU的常量内存中。当前M帧处理完毕,CPU重新产生M个随机数进行替换。 如表1所示,在我们自建的中波红外数据集上的实验表明,第二种方法采用的随机数产生机制,相比于第一种方法F-Mean指标仅降低了2.083%。同时,实验结果表明第二种方法的执行效率相比于第一种方法提升明显。详细的实验及结果分析见第3节。 表1 两种随机数产生机制性能比较Table 1 Comparison of two pseudo code generation methods 本文采用了CUDA提供的用于随机数产生的函数curand_uniform()[18]和curandGenerateuniform()[18],分别在GPU端和CPU端产生随机数。 本文所使用的实验平台为NVIDIA公司的嵌入式GPU平台Jetson TX2,其硬件配置如表2所示。整个实现基于CUDA 8.0。实验数据集为自建中波红外图像数据集[15],包含了12个视频序列共1 263帧图像,涵盖了动态背景、鬼影、相机抖动、阴影、噪声、高速和低速运动目标等常见场景,分辨率为480×320像素。有关该数据集的详细信息请参考[11]。 表2 实验平台硬件配置Table 2 Hardware configuration 表3列出了在CPU和GPU上执行PBAS算法的实验结果,从中可以得到如下结论:1) 在GPU执行PBAS算法相比CPU有着明显的加速效果。在处理480×320像素图像时,加速比最高可达70.653倍,平均可达66.533倍,每秒可处理132帧图像。这说明设计的PBAS算法的并行结构极大提升了算法执行的效率。2) 采用2.3节第二种随机数产生机制比第一种得到了明显的加速效果,加速比提高了11.275%。这说明规则的数据访问比随机的数据访问能更好地发挥GPU的并行计算性能。 图10给出了使用本文提出的PBAS并行优化算法在中波红外数据集上进行运动目标分割的结果,每组图像由输入图像、运动目标分割结果和相应的背景图像组成。由图可知,该算法能较好分割出运动目标,特别是远距离小目标。同时,PBAS算法能够很好地对背景图像进行建模。 表3 CPU和GPU耗时比较 msTable 3 Comparison of processing time between CPU and GPU 图10 中波红外数据集运动目标分割结果Fig.10 Results of moving objects segmentation on medium-wave infrared video sequences 图11是中波红外数据集Sequnece 1的一组视频序列图像(第57帧~第64帧)及其分割结果。图12是Sequnece 1第57帧~第64帧的第81个32×32大小的图像块的分割结果。由图可知,并行优化实现的PBAS算法能够正确分割出运动目标,由于背景下方存在动态变化,分割结果有一些噪声,这是由于PBAS算法本身的特点造成的。 图11 Sequence 1第57帧~第64帧的输入图像和分割结果Fig.11 Frames 57~64 of input image and segmentation results in Sequence 1 图12 Sequence 1第57帧~第64帧的第81个图像块Fig.12 The 81th block of each frame in frames 57~64 in Sequence 1 本文通过对PBAS算法的分析,结合GPU的架构特点,在数据存储结构、共享内存使用、随机数产生机制三个方面对其进行了并行优化。在嵌入式GPU平台Jetson TX2上的实验表明,对于480×320分辨率的中波红外视频序列,该优化方法可以达到132 fps的处理速度,是CPU处理速度的66.533倍。算法实现采用的技术具有通用性,可以供其它光电监视系统中运动目标分割算法并行优化借鉴使用。1.2 GPU架构


2 PBAS算法的实时优化方法
2.1 全局内存访问合并优化



2.2 共享内存优化
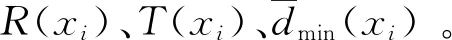


2.3 随机数产生机制优化

3 实验结果与分析







4 结论
