基于注意力机制Bi-LSTM算法的双语文本情感分析
2019-12-12翟社平杨媛媛毋志云
翟社平 杨媛媛 邱 程 李 婧 毋志云
1(西安邮电大学计算机学院 陕西 西安 710121)2(陕西省网络数据分析与智能处理重点实验室 陕西 西安 710121)
0 引 言
随着互联网行业的发展,电商评论和社交平台得到了有效的推广,形成了大量包含用户情感观点的短文本信息数据。将文本中的情感及观点进行提取,可以帮助企业、政府进行有效决策。情感分析也称为观点挖掘,是自然语言处理领域的研究热点,其关键任务是分析社交媒体和商品评论的文本数据,进而挖掘出用户的情感观点。目前国内外对于文本的情感分析多为单语种文本的分析,但随着中英文搭配使用在社交中的普遍化,情感分析的相关研究仍需更深一步。
在单语种情感分析方面,已取得了较好的研究成果[1]。其中,深度学习模型在情感分析任务重有着优异的表现,可以在没有人工标注的特征工程前提下,提高分类的准确率。Tai等[2]构建了树状长短时记忆网络(Long Short-Term Memory,LSTM)结构,在情感分析任务中取得了进步。Wang等[3]将递归神经网络和条件随机场整合到一个统一的框架中,用于显式方面和意见术语的共同提取,提升了分类准确率。但此类方法未将文本中重点知识进行突出,由此,注意力机制被引入情感分析任务。注意力机制可为文本分配不同权重,进而为关键部分分配更多注意力,提升分类准确率。谭皓等[4]考虑到表情符对文本的影响作用,提出了基于表情符注意力机制的情感分析模型。张仰森等[5]提出双重注意力机制,构建包含情感词、程度副词、否词、表情符等情感符号库,引入注意力模型和双向长短时记忆网络(Bilateral-LSTM,Bi-LSTM),提升情感分析的准确率。胡朝举等[6]提出深层注意力的LSTM情感分析,对文本进行特定主题探索,分析特定主题的情感倾向。
在双语种情感分析方面,Meng等[7]利用平行语料库提升词典覆盖率,采用最大化似然值对词语进行标注,进而提升情感分类准确率。栗雨晴等[8]通过构建双语词典,进行微博多类情感分析。但这两种方法需构建多语言平行语料库,分类准确率依赖于语料库的质量和规模大小。Wang等[9]利用因子图模型的属性函数从每个帖子中学习单语和双语信息,利用因子函数来探索不同情绪之间的关系,并采用置信传播算法来学习和预测模型。
在中英文搭配文本中,英文单词对文本的情感表达产生重要影响,甚至能改变文本的情感极性,但情感的表达并非词语极性的累加。例如下面两个例子,句①通过英文单词更改了句子极性,句②通过英文单词加强了句子极性。
① 玩了一下午轮滑so tired!(中性+负性=负性)
② 昨晚一夜没睡,坐过了车,多么happy的一天啊。(负性+正性=负性)
结合以上分析,本文将双语文本和句中的英文子句分别作为Bi-LSTM的输入,得到两者的知识表示。引入注意力机制,根据英文子句为双语文本分配不同权重,得到融合了英文子句特征的知识表示,进而得到最终的情感分析模型。通过爬取新浪微博上的数据作为数据集进行实验,与现有双语分析模型相比,本文所构建模型实现了效率的有效提高。
1 相关工作
1.1 Bi-LSTM
循环神经网络(Recurrent Neural Network,RNN)是前馈神经网络的改进,一个序列t时刻的输出不仅与之后的输出有关,也与之前的输出也有关。RNN会对前面的信息进行记忆,保存于网络的内部状态,当前的输出即由该内部状态计算得出。RNN中隐含层的节点是相互连接的,隐含层的输入由上一隐含层的输出和输入层的输出两部分组成。理论上,RNN可以对任何长度的数据进行处理,但实践中,任意长度的数据具有复杂性,为了简化运算过程,设置当前状态只于前n个状态相关。
RNN仍然存在梯度消失和梯度爆炸问题,为了避免该问题,Hochreiter等[10]提出并实现了LSTM。在一个LSTM模型中,每个单元包含输入门it、遗忘门ft、输出门ot以及记忆单元ct。输入词向量可以表示为{x1,x2,…,xn},其中xt为一个单元的输入,是输入文本中一个单词的词向量。ht表示网络中的隐藏层向量。单元中的3个门和记忆单元可由以下公式计算得出:
(1)
ft=σ(Wf·X+bf)
(2)
it=σ(Wi·X+bi)
(3)
ot=σ(Wo·X+bo)
(4)
ct=ft⊙ct-1+it⊙tanh(Wc·X+bc)
(5)
ct=ft⊙ct-1+it⊙tanh(Wc·X+bc)
(6)
ht=ot⊙tanh(ct)
(7)
式中:Wi、Wf、Wo∈Rd×2d为权重矩阵;bi、bf、bo∈Rd表示训练过程中学习到的偏置值;σ表示激活函数;⊙表示点乘积。
双向循环神经网络由前向神经网络和后向神经网络构成,前向神经网络负责记忆上文信息,后向神经网络负责记忆下文信息,对文本分析起到了促进作用。Bi-LSTM由两个LSTM构成,且连接着同一个输出层,为输出层的数据同时提供上下文的信息,图1为Bi-LSTM沿时间的展开图。
1.2 注意力机制
人脑关注事物会为关键部分分配更多的注意力,注意力机制即为该现象的抽象化。通过计算注意力概率分布,对事物的关键性部分分配更重的权重,进行突出,进而对模型起到优化作用。注意力机制最主要的特质是为文本中的关键信息分配更多的权重,使得模型更多地关注重要信息,早期多用于图像处理领域,近年来自然语言处理领域也引入了该方法。根据当前单词为输出矩阵分配不同权重,生成特定的上下文表示。
根据LSTM产生的隐藏层特征H=[h1,h2,…,hN]构建注意力机制的输入,H∈Rd×N,其中:d表示隐藏层的长度;N为输入文本的长度。注意力机制最终产生注意力权重矩阵α和特征表示v可由以下公式计算得出:
ui=tanh(Wshi+bs)
(8)
(9)
(10)
2 基于注意力的双语情感分析模型
为了关注更多有价值信息,本文提出基于英文注意力机制的双语情感分析模型,对语句中英文词汇进行抽取,并对英文词汇和语句进行向量表示与融合。采用双向LSTM和注意力机制,更好地提取出文本中重点词汇。模型构建如图2所示,输入数据包含两部分:双语文本s和英文子句t,英文子句即双语文本中出现的非中文词汇。
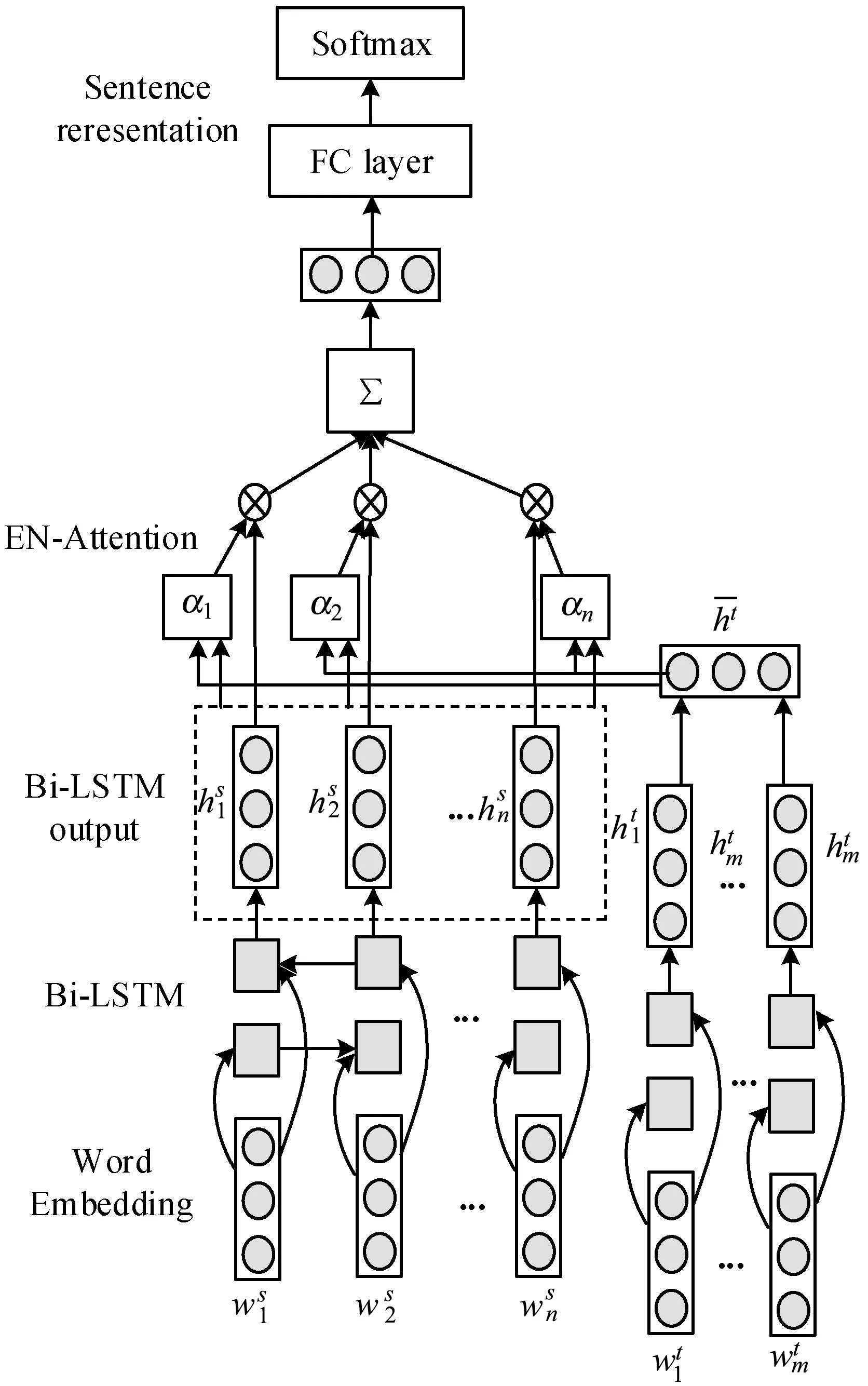
图2 基于注意力机制的模型框图
模型的网络结构中主要包含4个网络层:词向量输入层、双向LSTM层、注意力计算层、情感预测层。词向量层的作用是把句子中的每个词汇映射成为低维、连续和实数的向量表示;双向LSTM层对句子s和英文子句t进行建模,分别生成上下文特征表示和外文特征表示;注意力计算层根据上下文和外文两个部分的特征表示输入,为句子中的单词分配合适的注意力权重,生成特定的情感特征表示;情感预测层基于特定的情感特征来预测情感倾向。
2.1 词向量输入层
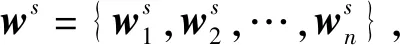
2.2 双向LSTM层
模型采用共享权重的双向LSTM将文本和英文词汇映射到相同向量空间。记Bi-LSTM中的前向LSTM和后向LSTM在时刻i的输入处理分别为:
(11)
(12)


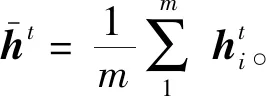
2.3 注意力计算层
根据英文词汇对为句子中的每一个词汇分配合适的注意力权重,从而生成特征相关的情感特征表示。经过注意力计算层,整个句子的表示如下:
(13)
式中:αt表示了句子第t个词结合英文词汇后的重要程度,即模型表示的第t个词在句子中的注意力权重,其定义如下:
(14)
式中:score为衡量词语与英文词汇组合后的重要程度的打分函数,score的定义如下:
(15)
式中:WS、WT为权重矩阵;b为偏执向量;v为权重向量;vT表示v的转置。
2.4 情感预测层
双语文本的情感倾向预测需要同时考虑上下文信息和英文词汇对文本的影响,本文将前向LSTM和后向LSTM的最后一个时间步的隐藏状态连接起来作为句子s的特征表示,并利用非线性变换将其和英文相关的情感特征结合起来:
dc=tanh(Wcs+bc)
(16)
然后,采用softmax函数来获取其情感分布。
(17)
式中:C表示情感标签个数;pc表示情感标签c的预测概率。
2.5 模型训练
模型采用交叉熵作为优化的损失函数,若D表示训练数据集,则基于英文注意力的双语分析模型损失函数如下:
(18)
3 实 验
3.1 数据集
为了训练和测试语料,从新浪微博抽取双语微博文本信息。使用分词器进行分词,替换掉微博中的网址、用户及话题标签等,过滤掉长度小于5的微博文本,获得7 000条用于标注的双语文本。然后依照高兴、悲伤、愤怒、恐惧和惊讶五类情感对文本进行人工类别标注。双语文本表达情感共有四种可能:1) 句子没有表达情感;2) 句中的中文子句表达情感;3) 句中的英文子句表达情感;4) 中英文共同表达情感。因此,分别对句中英文子句、中文子句和双语文本进行人工类别标注。语料在各情感类别中的分布情况如表1所示。
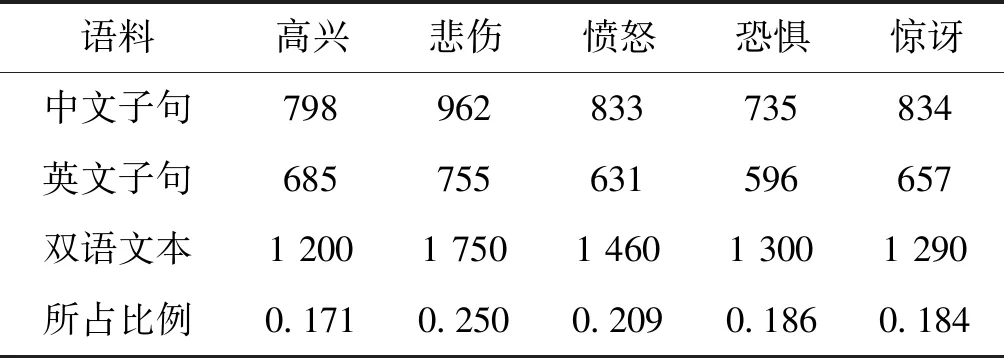
表1 双语文本在5类情感类别中的分布
3.2 实验设计
本实验采用词向量训练工具word2vec,设置参数为:双语文本和英文子句词向量为100维;训练迭代次数100;设置学习速率0.05等。采用Bi-LSTM生成文本表示,因此双语文本中每个单词的输出表示为200维。注意力权重的维度与文本长度一致。本文利用TensorFlow框架来训练注意力机制Bi-LSTM模型,设置LSTM的层数为64层,Bi-LSTM的层数为128层。实验时标注语料按照8∶1∶1分别分为训练集、开发集和测试集。采用准确率P(Precision)、召回率R(Recall)和F1值来表示评估实验的性能。
1) 通过设定不同输入体现英文子句对双语文本的影响作用。
(1) CN-Bi-LETM,仅考虑双语文本中的中文,作为Bi-LSTM网络的输入,得到的表示直接作为判断模型的特征向量。
(2) EN-Bi-LSTM,仅考虑双语文本中的英文,作为Bi-LSTM网络的输入,得到的表示直接作为判断模型的特征向量。
(3) CN-EN-Bi-LSTM,将混合文本的向量表之直接作为Bi-LSTM网络的输入,得到的表示直接作为判断模型的特征向量。
(4) EN-Attention Bi-LSTM,为双重LSTM模型引入注意力机制,在特征表示时为不同词语分配不同权重,作为最终的特征向量。
2) 通过与现有算法进行对比,体现深度学习在情感分析中的高效性,以及引入注意力机制对深度学习情感分析算法的影响。
(1) 基于平行语料库的分类方法。采用平行语料库与最大化似然值结合的方法扩展词典,进而实现情感分类。
(2) 采用情感词典与监督学习算法相结合,实现较好的分类效果。
(3) 基于双语词典的分类方法。通过构建双语词典,采用半监督高斯混合模型进行中文及双语微博文本进行分类。
(4) 联合因子图模型。利用因子图模型的属性函数学习文本的单语和双语信息,使用置信传播算法进行情感预测。
3.3 实验结果与分析
1) 表2显示了不同基线的实验结果,可以看出:
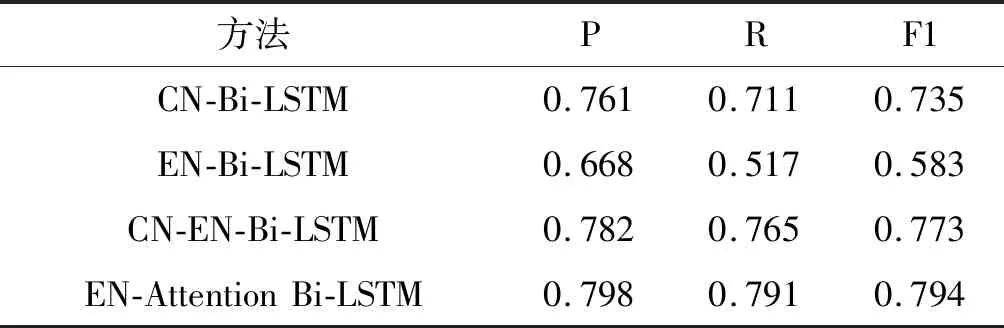
表2 与其他基线比较
(1) 由于双语文本中存在大量由中文陈述客观事实、英文表述情感的现象,CN-Bi-LSTM只考虑了中文文本同样是不稳定的。
(2) 由于英语是我们语料库中的嵌入式语言,EN-Bi-LSTM的结果只考虑英语文本是不稳定的。
(3) CN-EN-Bi-LSTM将双语文本共同作为网络输入,忽略了英文对中文子句的影响作用。
(4) EN-Attention Bi-LSTM引入注意力机制,明显优于以上算法。
上述实验表明,本文所提模型由于英文子句改变或加强了文本的极性,同时注意力模型也发掘出了文本内部的语义权重,提升了识别效果。
2) 表3显示了不同算法在相同数据集上的实验结果,可以看出,本文提出模型提升了分类的准确率。
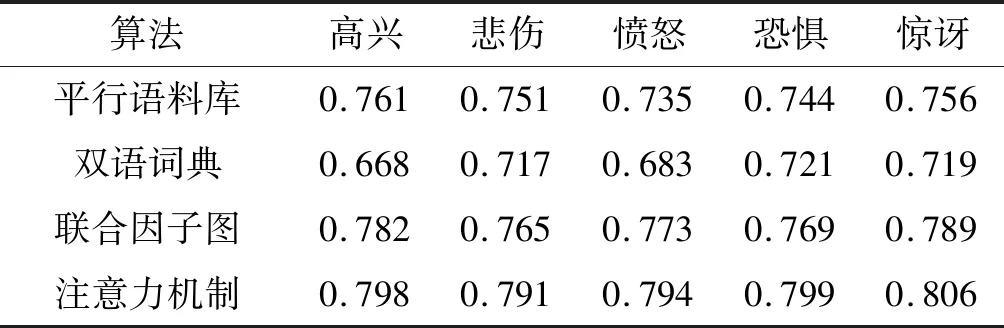
表3 各分类算法F值
4 结 语
本文提出一种基于注意力机制的双语文本情感分析模型,将双语文本中的英文子句提取出来,分别采用双重LSTM模型进行特征表示,利用注意力机制,根据英文子句对双语文本词汇分配不同权重,进行特征融合,最终形成基于注意力机制的特征向量,该方法能获取到更加精准的语义表示。实验结果显示,英文子句注意力机制能够有效识别双语文本情感极性,并且准确率都超越了现有分类算法,取得了较好分析的结果。
本文方法立足于新浪微博,双语文本以中文为主,英文为辅,未考虑到英文所占比重对分析结果的影响,不具有普适性。此外,下一步工作可针对双语文本中的词性进行比重划分,对本方法进行改进。
