基于概率分布估计的私家车和出租车行程时间可变性度量
2019-12-12王召月袁绍欣
王召月 袁绍欣
(长安大学信息工程学院 陕西 西安 710064)
0 引 言
随着城市交通拥堵的日益严重,出行者不仅关心出行时间,也关心行程时间可变性。虽然二者都与出行成本有关,但对于前者,出行者关心如何节省,而对于后者,出行者则关注它的可预测性以降低可变性带来的风险[1-2],这是因为不稳定的行程时间会迫使出行者预留出更多的时间以求准时到达目的地[2]。私家车和出租车是两种重要的出行方式,对它们的行程时间可变性进行度量,可提升对这两种出行方式可靠程度的认识,最终有利于城市出行者进行出行方式选择决策和交通管理者制定相应的管理政策[3-5]。
对私家车和出租车的行程时间可变性进行度量,需要相同路段、相同时间段两类车的行程时间数据,这有助于通过对比研究从这两类共享相同车道的出行方式中发现它们在行程时间可变性方面的差异。当前能满足这方面数据要求的主要是城市自动车牌识别(Automatic Number Plate Recognition,ANPR)数据。自动车牌识别系统实现了对车辆闯红灯和超速等违规行为的检测[6]。该系统在城市重要的道路卡口安装摄像头,识别车辆经过卡口时的车牌号码、通过时刻以及速度等信息。通过上下游两个卡口的信息就可获得车辆通过两个卡口间路段的行程时间和平均速度等数据[7]。与具有路网覆盖能力广但采集精度低的GPS数据[8]相比,ANPR数据具有采样精度高、数据量大且可通过车牌信息区分车型的优点,已是城市车辆道路行程时间估计的一个重要数据源。
值得注意的是,并不是所有的ANPR数据都适合于研究私家车和出租车的行程时间可变性,这是因为ANPR系统采集到的一些行程时间观测数据并不能反映特定时空下大概率出现的通常交通状况[9-10]。如:在两卡口间车辆因各种原因的临时停靠(停车、购物、装卸/卸载等);空载出租车以低速缓行寻客;私家车司机因对路况环境不熟悉而缓行;恶劣天气、交通意外和红绿灯故障等罕见事件发生时,多数车辆在个别时段整体缓行等。与通常交通状况相比,这些小概率发生的交通事件会导致少数私家车和出租车在个别时段具有较长的行程时间。与此相对的是,也存在比通常交通状况较短的行程时间情况,如个别日期个别时段,经常拥堵的路段异常通畅,个别车辆以较短的时间通过该路段而未遇到红灯等。较快和较慢的两种观测数据称为异常数据,与有效数据相比,在分布上具有右向尾部以及比例少的特点[10]。虽然它们是真实数据,但发生概率低,对于多变的私家车和出租车道路行程时间,大概率发生的通常情况才具有参考价值。因而对私家车和出租车的行程时间可变性进行度量必须排除这类异常数据的干扰。
1 相关研究
对行程时间可变性的研究方法主要包括为两种类型。其中一种方法基于平均值-标准差,其中平均值代表出行的平均成本,而标准差代表从出发地到目的地的稳定程度[11]。对行程时间可变性的表征就可表达为以标准差结合平均值为自变量的出行费用函数,这种方法因其简单而应用广泛,但缺乏对行程时间可变性表达更为丰富的分布形状的描述[12];第二种方法是基于百分位点的行程时间可变性度量[1]。如用90百分位值和10百分位值的差值除以50百分位值((T90-T10)/T50)来度量行程时间分布的宽度,用90百分位值和50百分位值的差值除以50百分位值和10百分位值的差值(即(T90-T10)/(T50-T10))来度量行程时间分布的偏斜度[10],然而这种方法对行程时间分布形状描述仍较为粗略。
很多研究者都注意到对行程时间可变性度量需要更细致地描述行程时间不规则的分布形状,同时也不能忽略异常数据对分布形状的影响。Emam等[13]比较了各种分布:对数正态分布、伽马分布、威布尔分布和指数分布,得出了对数正态分布对行程时间分布具有较好的拟合效果的结论。然而受到交通需求、交通事故和驾驶行为特性等一系列波动因素影响,城市道路车辆行程时间通常具有多种交通状态,在分布形状上则反映为用单峰分布很难进行准确描述的偏斜、多峰等不规则特征[14]。Skabardonis[15]等指出传统的数值统计指标很难准确地描述行程时间的可变性和交通控制之间的内在联系,而对行程时间密度分布不规则形状的准确描述可解决这一问题。为此,Guo等[16]提出了使用混合分布模型描述行程时间数据中观察到的多峰分布模式,用两个对数正态分布混合模型来证明其在拟合多峰行程时间分布方面优于传统的单峰分布。Park等[17]指出当行程时间数据的经验分布呈现出多峰或偏斜性时,行程时间分布往往是多分布叠加的结果,并证明了双分布叠加或三分布叠加混合模型用来拟合行程时间分布的合理性。Frühwirth-Schnatter[18]也指出有限混合模型(Finite Mixture Model,FMM)在拟合包含两个或者更多子群体的数据分布时具有很大的灵活性和便利性。Kazagli等[19]采用两个对数正态分布混合模型分析了近10个月的自动车辆识别(Automatic Vehicle Identification,AVI)数据,将数据聚类为有停车行为和无停车行为两种,并将有停车行为的数据视作异常数据予以滤除。
当前在行程时间可变性研究方面的已有成果尚存在的问题是:研究大多使用固定数量分布的有限混合模型来拟合行程时间样本数据的分布形状,并没有确定合适的分布数K来表示因行程时间可变性而出现的单峰、双峰、多峰以及偏斜等多种分布形态;此外,没有考虑到异常数据分布对行程时间分布形态上的影响。
2 拟合算法设计
2.1 数据样本选取
根据车辆通过起始卡口的时间戳,将采集的ANPR数据以30分钟为间隔,划分为48组样本,通过离散化的48组数据样本度量一天内不同时间段的行程时间可变性。针对每个数据样本设定一个行程时间经验阈值π(一般为高峰期间车辆通过路段的平均行程时间的2至3倍),以确保各组样本能包含所有的有效数据和一定量的异常数据,而行程时间大于π的观测点数据将从48个样本数据中滤除。
2.2 拟合数据样本分布
FMM是模拟数据同质性和异质性的一个概率化的、半参数模型[20],可用于对潜在类和感兴趣变量的相应分布进行建模统计。模型假设群体由K个未知的子群体(分量)组成,每个子群体具有不同的概率分布密度,但具有相同的已知参数族[21]。所提模型选择对数正态分布作为子群体的分布。运用基于对数正态分布的K分支有限混合模型(以下简称K-FMM)拟合各组观测数据的分布:
(1)
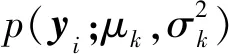
采用EM算法[19]对模型参数φ进行估计。该算法通过多步迭代,使似然值收敛至最优值。算法在以下两个步骤之间进行迭代:
(1) E步骤:根据参数初始值或上一次迭代所得参数值来计算出变量的后验概率:
(2)
式中:后验概率Iik表示在第t次迭代后,各样本中的第i个数据属于第k个子群体的概率。
(2) M步骤:基于E步骤中的后验概率,估计新的分布参数。
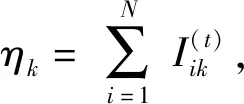
(3)
(4)
(5)

根据E步骤中的Iik可判断观测数据属于哪个群体,从而将数据样本聚类为K个种群。
2.3 拟合有效数据与异常数据分布
样本数据特征是进行建模的基础。分布上的右向长尾特点表明相对于有效行程时间观测,异常数据具有较长的平均行程时间。因此,具有最大行程时间均值μK的对数正态分支fK是表示异常数据分布特征的最佳选择。异常数据分布的密度函数可表示为:
(6)
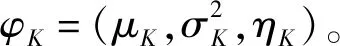
(7)
μK=max(μ1,μ2,…,μk) ∀k∈(2,3,…,L)
(8)
混合密度分布fV(yi|φV)代表有效数据的分布特征,由其他K-1个密度分支组成,这也体现了有效行程时间观测分布的多种群特点。
(9)
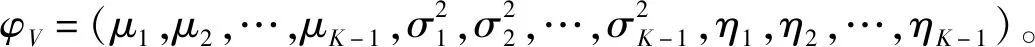
因此,式(1)又可写为:
f(yi|φ)=fV(yi|φV)+fK(yi|φK)
(10)
这表明基于对数正态分布的K-FMM可将行程时间数据分布聚类为K个密度分布,并获得相对应的数据子群体,且可分为具有不同特征的有效数据与异常数据两类。
fV(yi|φV) 与fK(yi|φK) 在区间(0,π)内存在至少一个交叉点,设交叉点X具有最大横坐标值Tx,则区间(0,π)分为(0,Tx)和(Tx,π)两部分。
2.4 确定有效数据和异常数据最佳分离效果
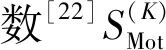
(11)
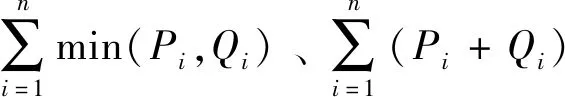
(12)
2.5 算法实现
根据上述介绍,可将算法的具体实现步骤描述为:
Step1根据车辆通过起始卡口的时间戳,以30分钟为间隔,将采集数据划分为48组样本。
Step2设置K=2、ε=0.02。
Step3利用基于对数正态分布的K-FMM,通过EM算法将各组样本数据聚类为K个子群体并获得相对应的密度分布。
Step4将同时满足约束条件式(7)和式(8)的密度分支标识为异常数据分布的分支fK(yi|φK)。
Step5混合密度分布fV(yi|φV)满足式(12),该K值即为最佳分离值,设置K′=K-1,执行Step6;否则K=K+1,执行Step3。
Step6得到K=O个密度分支及相应数据的子群体,过滤识别出的异常数据,将获得的有效数据分布重新拟合为K′个密度分支。
Step7输出有效数据平均值和标准差等相关指标。
实验在包含混合模型软件包MIXMOD(实现EM算法)的MATLAB环境下实现。
3 实例分析
3.1 数据来源
陕西省西安市的不同地点安装了自动车牌识别摄像头,以捕获违章车辆并提供交通计数。实验选取西安市咸宁路和友谊路自西向东方向的两个站点间的ANPR数据为研究对象,如图1所示。

图1 研究所选咸宁路段和友谊路段
ANPR数据包含如下信息:
(1) 站号、经度和纬度:可以计算任意两个卡口之间的距离。实验选用咸宁路段长度为2.2公里,友谊路段长度为1.8公里。
(2) 车牌号码和车牌颜色:根据车牌的颜色可以区分公共汽车(黄色)、私家车(蓝色)和出租车(蓝色),并利用交通管理局的车牌号码区分出租车与私家车。
(3) 日期和拍照时刻:当车辆经过卡口识别时,在每个卡口记录车辆捕获日期和拍照时刻。据此信息可以计算每辆车在任意两个卡口之间的行程时间。
选用2014年3月1日至2014年3月30日在两路段上采集的出租车与私家车样本观测数据进行实验研究。
3.2 实验结果及分析
图2为咸宁路段和友谊路段出租车和私家车在6:00至20:00期间的行程时间观测结果(π=4 200 s)。其中,横坐标表示车辆经过起始卡口被摄像头捕获的时刻,纵坐标表示车辆经过起点、终点两个卡口间路段的时间差,即行程时间。图中,观测数据可明显地分为两个部分:比较密集的有效数据区和较分散的异常数据区。其中异常数据所占比例较小,且普遍高于有效数据。两数据区域间的界限比较模糊并且随时间动态变化,采用固定阈值无法对两类数据进行有效区分。
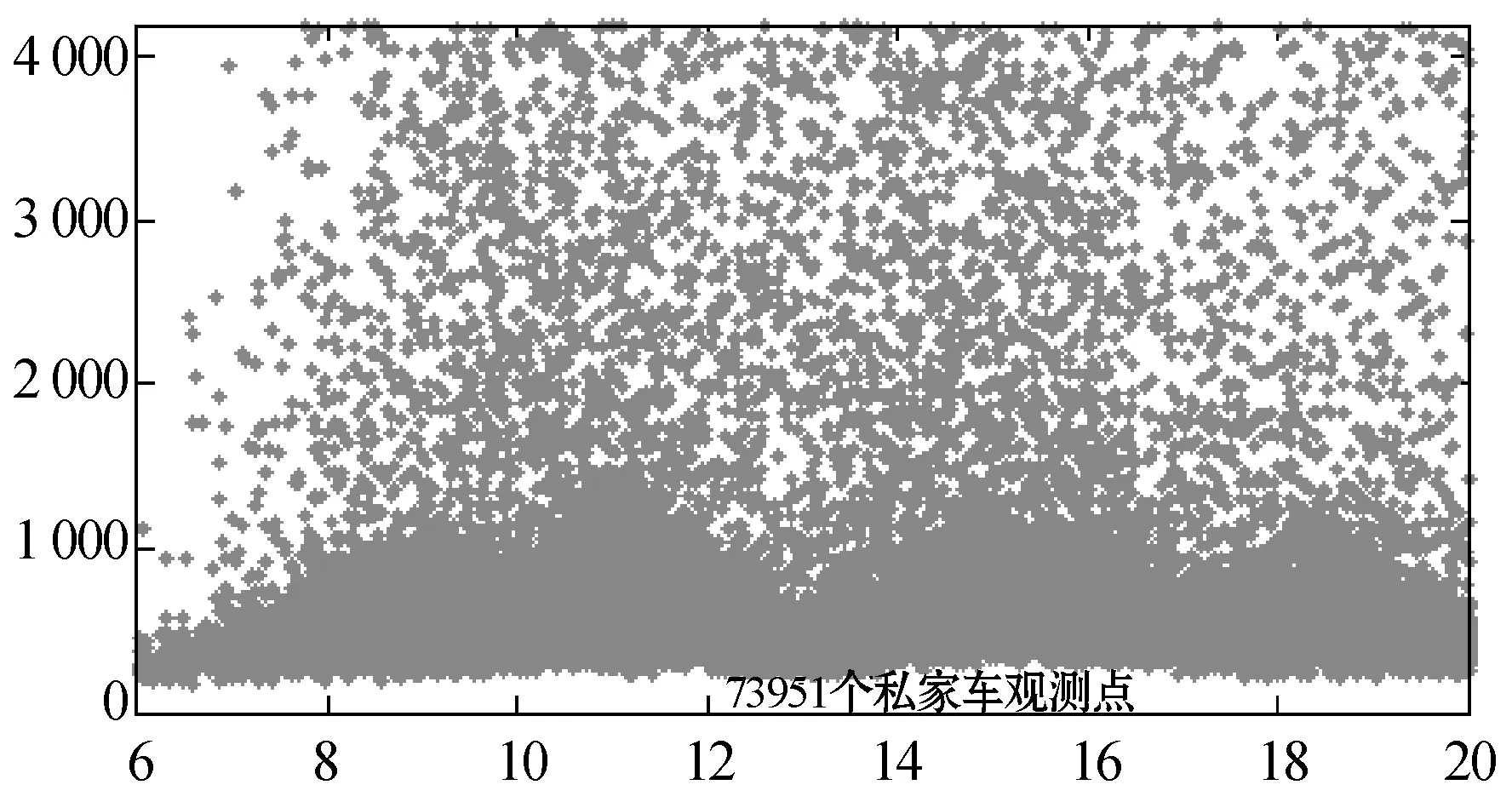
(a) 友谊路私家车观测点
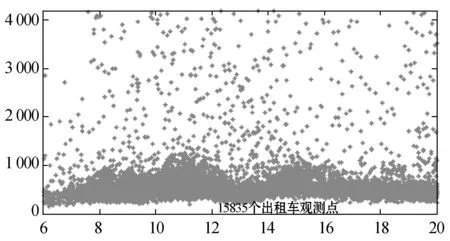
(b) 友谊路出租车观测点
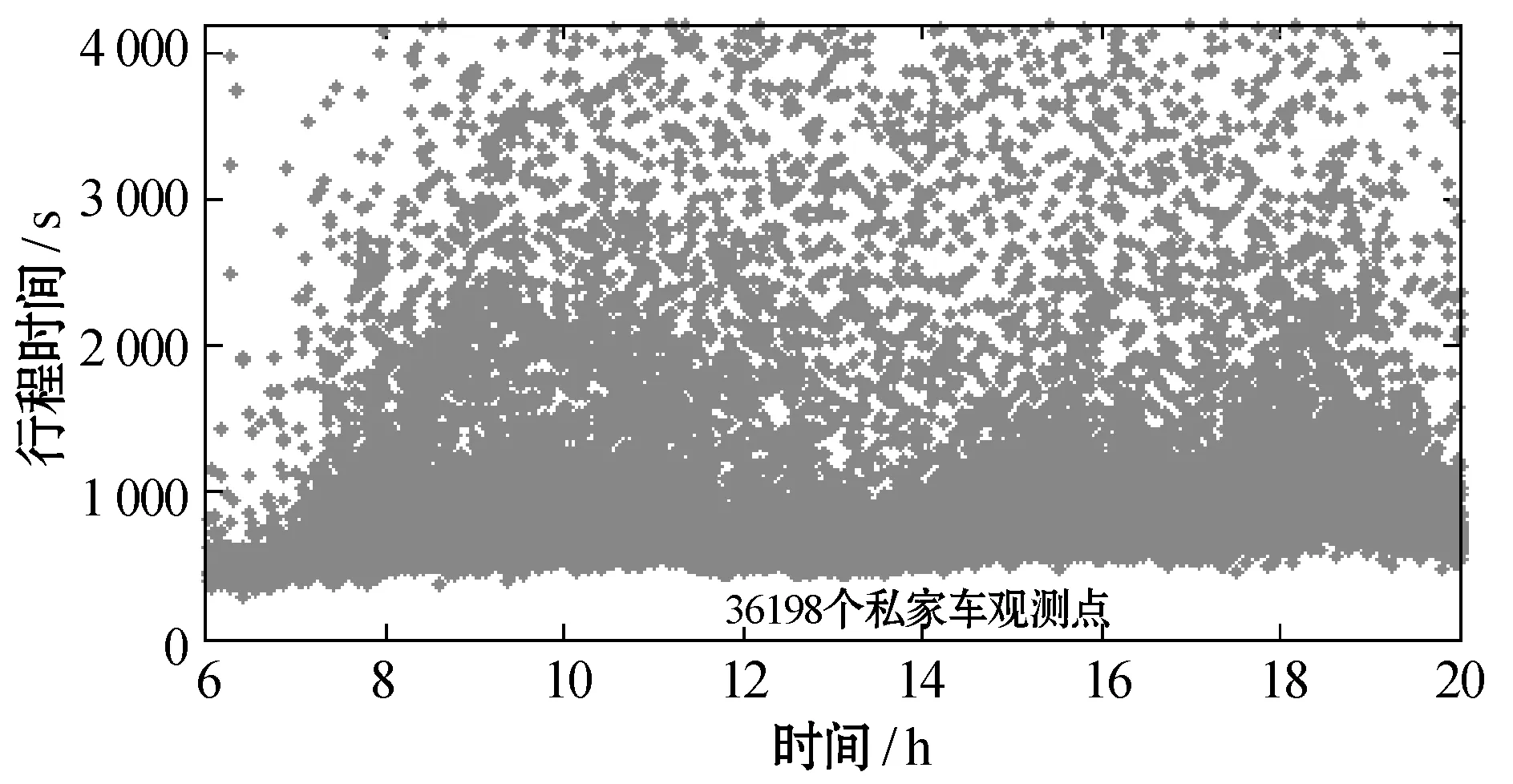
(c) 咸宁路私家车观测点
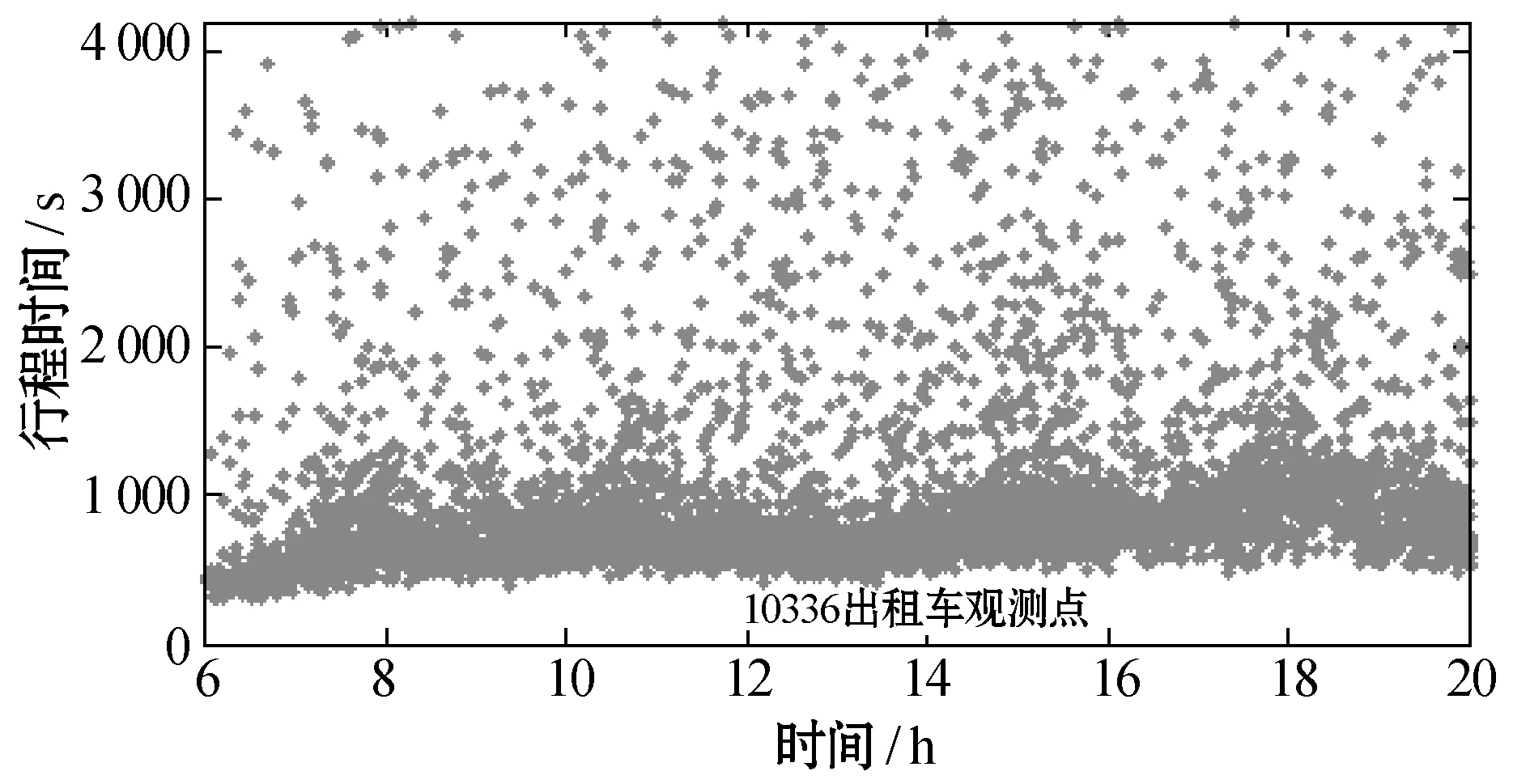
(d) 咸宁路出租车观测点
图2友谊路段和咸宁路段行程时间观测数据
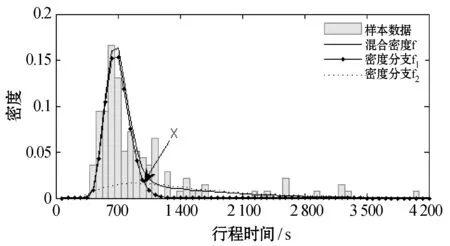
(a) 过滤异常数据前(K=2)

(b) 过滤异常数据前(K=3)
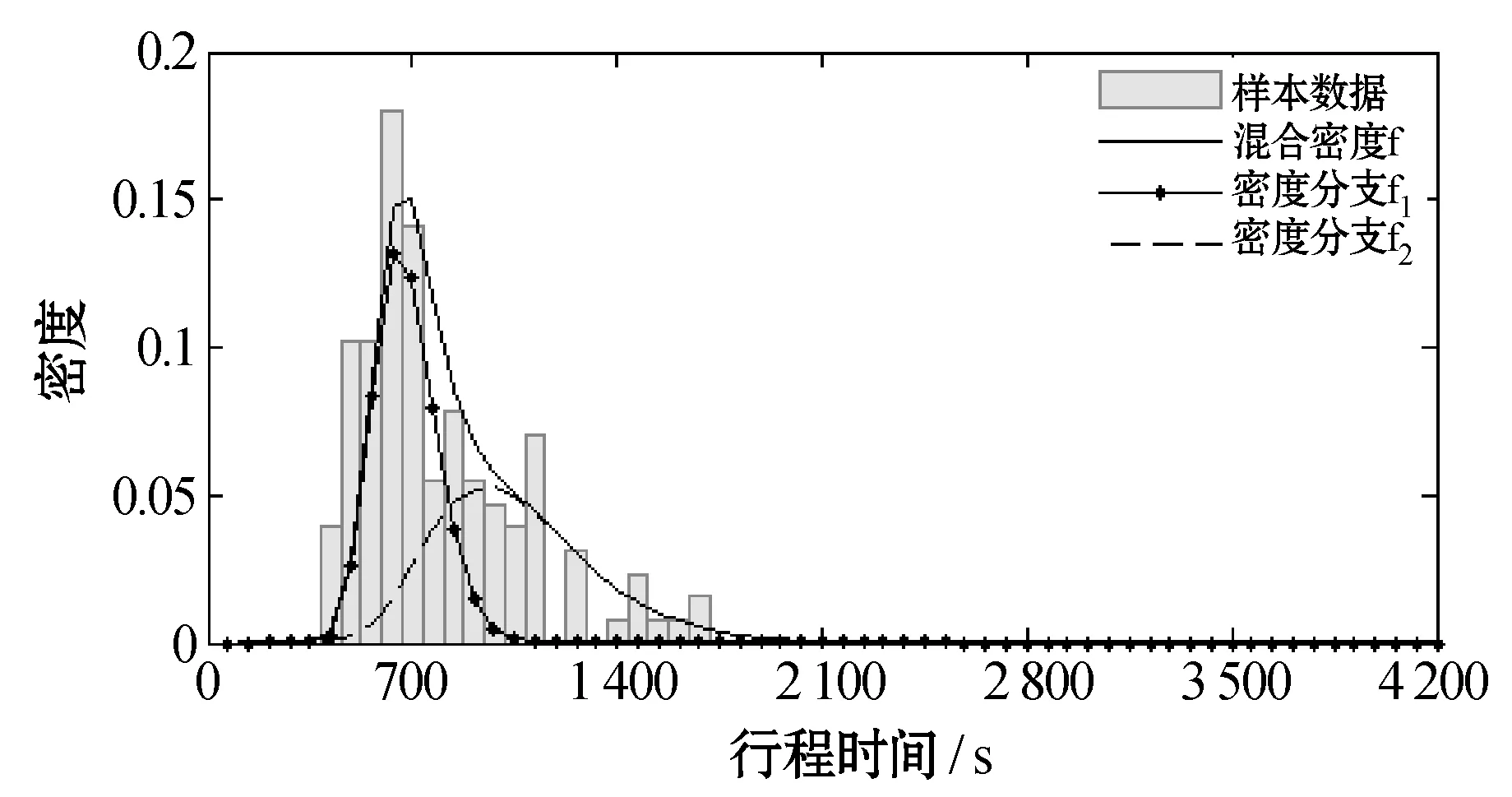
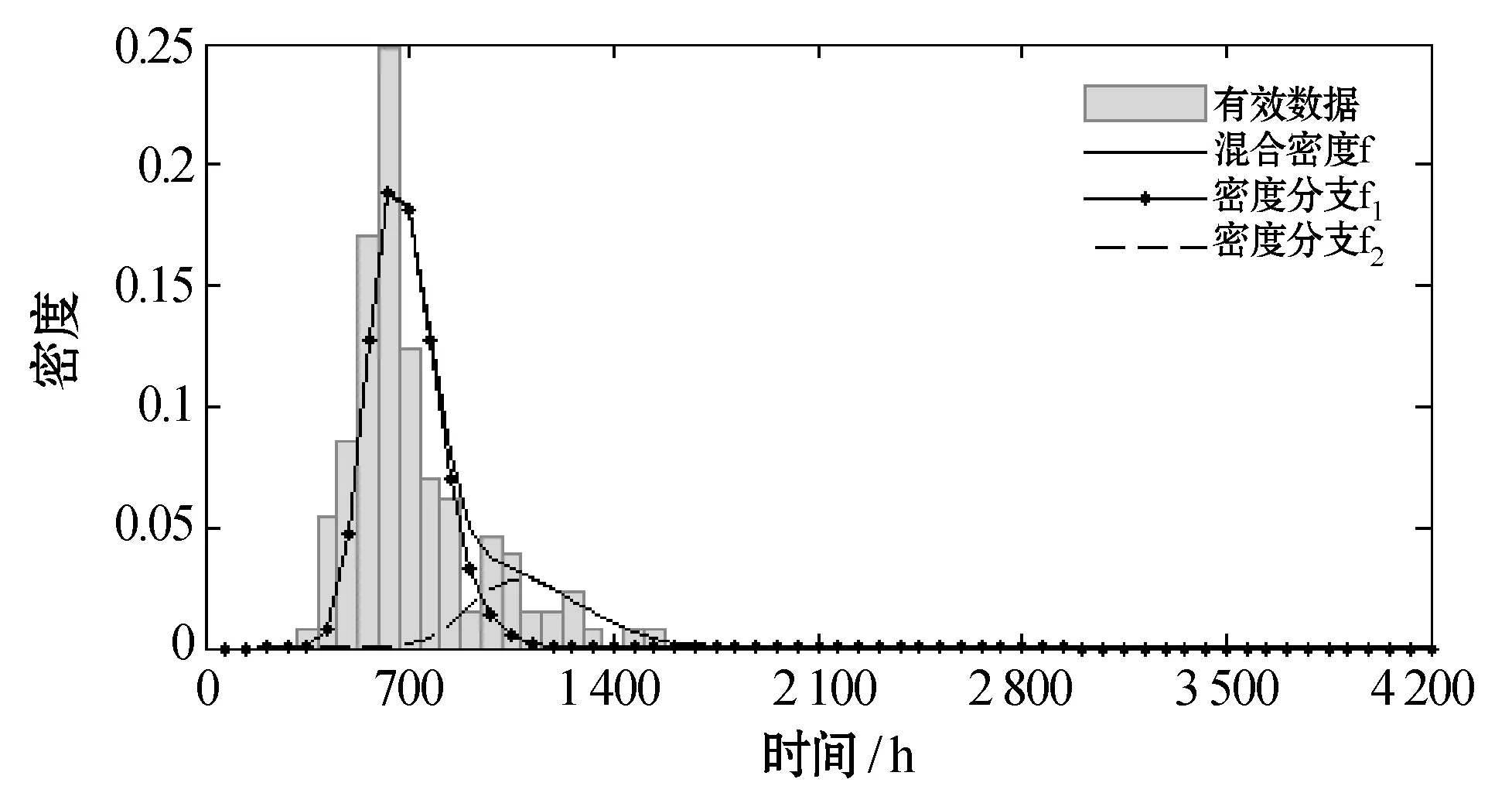
(c) 过滤异常数据后(K′=2)图3 咸宁路段出租车8:00 - 8:30样本数据密度直方图与分布拟合结果
图4展示了友谊路段与咸宁路段出租车与私家车样本数据中的异常数据与有效数据的聚类识别结果,以及异常数据的存在对平均行程时间的影响。可以观测到:两种出行方式的样本数据中存在行程时间较长和较短的两种异常数据;去除异常数据后,样本数据平均值明显低于未去除前样本数据平均值,这表明虽然异常数据的比例较小,但是对行程时间平均值影响显著,也意味对于行程时间可变性的准确度量而言,必须进行异常数据识别。
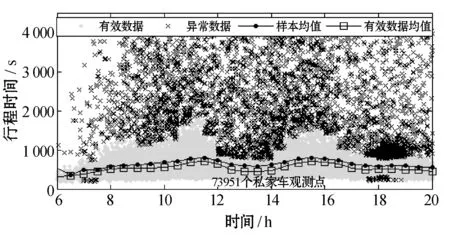
(a) 友谊路私家车数据
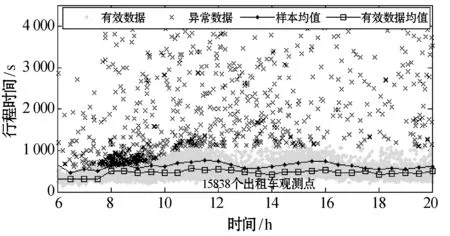
(b) 友谊路出租车数据

(c) 咸宁路私家车数据
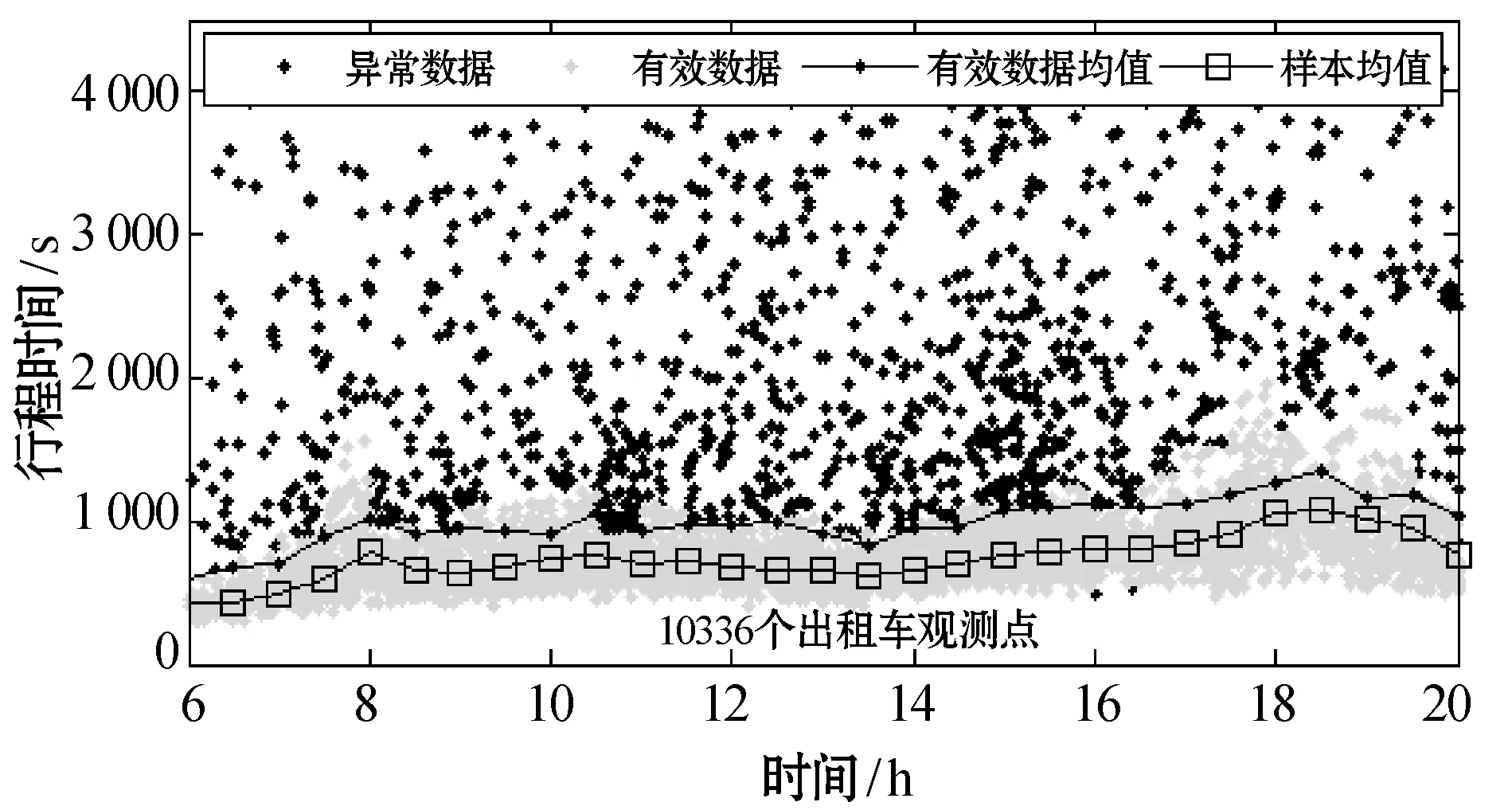
(d) 咸宁路出租车数据图4 样本数据中异常数据识别及异常数据对平均行程时间的影响
图5对比了有效行程时间数据提取前后,咸宁路各时间段内出租车与私家车的行程时间均值。在去除异常数据后,大部分时间段内,出租车的平均行程时间都小于私家车。在7:30 - 9:00和17:30 - 19:00拥堵高峰期内,出租车与私家车的平均行程时间有显著差异。而未去除异常数据,则观察不到该现象。这表明异常数据的存在会对行程时间可变性的统计指标产生很大的影响甚至会导致出行决策的失误。通过设备获得的原始ANPR数据不能直接用于行程时间可变性的量化,它会对数据统计指标的精确性产生干扰进而影响出行方式决策。
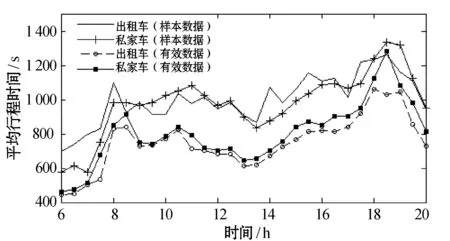
图5 咸宁路段私家车和出租车各时间段样本平均行程时间对比
图6展示了友谊路段和咸宁路段8:00-8:30的私家车样本数据在进行异常数据识别过滤后,对有效数据分布重新进行拟合的结果。与图6(b)相比,图6(a)缺少了具有较长平均行程时间的分支f3,这表明在该时间段,咸宁路和友谊路具有不同的交通状态,很明显,咸宁路更加拥挤。
通过比较图6(b)与图3(c),可了解共享车道上的私家车与出租车在同时间段内的行程时间可变性的差异。图6(b)具有平均行程时间明显较高的分支f3的,这表明该时间段内存在明显的交通拥堵现象,这种情况下,私家车无法有效避免。而在图3(c)中,分支f3的缺失表明:虽然出租车和私家车行驶在同一车道上,但出租车司机配备了相关通信器材并且比私家车车主有更多的经验、更加精通路况。即便在交通拥堵时期,出租车司机也可以通过绕路等方式有效避开。这也很好地解释了图5中,去除异常数据后, 7:30 - 9:00和17:30 - 19:00拥堵高峰期内,出租车平均行程时间明显小于私家车的情况。
(a) 友谊路私家车数据
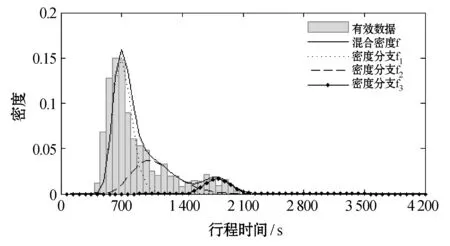
(b) 咸宁路私家车数据图6 8:00 - 8:30选用路段私家车数据密度直方图及有效数据密度分布
4 结 语
行程时间可变性导致行程时间观测数据在分布上呈现多峰、偏斜等多种分布形态。采用固定数量的子分布不能准确拟合行程时间数据分布。此外,利用自动车牌识别系统采集的数据对行程时间可变性进行度量时,样本数据包含一定数量不能代表正常交通状况的异常数据,会对行程时间数据的分布形态产生影响。为识别异常数据并对有效数据分布进行准确拟合,研究工作的主要贡献为:
(1) 根据异常数据的右向长尾和比例较少的特征,利用对数正态分布有限混合模型对两类数据进行建模。给出了对有效数据与异常数据实现最佳分离的分布数K值的确定算法,解决了因行程时间可变性引起的有效数据与异常数据无固定阈值区分的问题。同时,通过动态确定分支数K值,准确描述了有效行程时间数据的分布上的多峰、偏斜等多种分布形态。实验证明了异常数据的存在会对行程时间变性的统计指标产生干扰甚至导致出行者对出行决策的误判。因此,必须进行异常数据的识别过滤。
(2) 通过对同一路段上出租车与私家车的行程时间可变性进行对比研究,发现两类出行方式虽共享同一车道,但具有不同的行驶特性。与私家车驾驶者相比,出租车司机可以有效避免交通拥堵的情况,这是由于出租车配备了相关通信器材,同时司机具有更多经验,从而更加灵活。
