基于双向时间深度卷积网络的中文文本情感分类
2019-12-12韩建胜彭德中
韩建胜 陈 杰 陈 鹏 刘 杰 彭德中
(四川大学计算机学院(软件学院) 四川 成都 610065)
0 引 言
随着互联网的快速发展,网民可以更加便捷地发表自己对某一事件的看法和评论所接受到的服务。这些带有情感色彩的评论信息表达了人们不同类型的情感倾向。然而由于网络中评论数据规模庞大,单纯依靠人力难以从大量文本中分析出用户的情感倾向,所以需要通过自动化的方式来进行文本分析。文本情感分析就是这样一种能帮助我们从文本中挖掘用户情感信息,识别文本的情感极性或强度的自动化方法。近年来,深度学习在文本情感分析任务中展现出了巨大的潜力。文献[1]利用长短期记忆网络(Long Short-Term Memory,LSTM)在多种不同任务上进行模型训练,以此提高模型编码层的特征提取能力,然后具体分析情感数据进行模型参数调整,得到相应的情感分类输出。文献[2]在LSTM的基础上引入了注意力机制,通过关注文本中被评论的对象、评论词等能够体现情感色彩和倾向的词来实现针对具体对象的细粒度情感分析。因为循环神经网络(Recurrent Neural Networks,RNN)计算上的串行性使得模型计算速度较慢,而卷积神经网络(Convolutional Neural Networks,CNN)不仅有较好的并行性,计算速度快,而且具有提取文本n-gram特征的能力,所以有不少研究者将CNN引入到情感分析任务中。文献[3]利用卷积神经网络对文本进行特征提取,通过不同大小的卷积核提取不同类型的n-gram特征,然后将所有提取到的特征信息融合到一起进行情感分类。文献[4]通过卷积和动态最大值池化提取文本序列中相隔较远的词之间的语义关系,以获得文本中的长期依赖,达到更加全面的提取文本中的特征信息来对文本进行情感分析的目的。文献[5]在使用卷积神经网络对文本进行建模的过程中,考虑了文本序列中词的顺序关系,对时间卷积网络进行了适当改进,使用了非线性、非连续卷积对文本进行特征提取,然后使用提取到的特征信息对文本进行情感计算。
卷积神经网络因计算速度快而被大家推崇,但是基于卷积神经网络的情感分析模型中,多数模型没有考虑到文本序列中词出现顺序的影响。少数模型考虑了词的前向顺序,即文本中先出现的词对后面出现的词的影响,用单向时间卷积(Temporal Convolutional Networks,TCN,Uni-TCN)[6]提取文本特征信息,忽略了后面的词对前面的词的影响。因为文本序列后出现的词会对之前出现的词在词共现的角度存在统计学意义,所以单向时间卷积网络不足以捕捉文本序列中全部的特征信息。针对这一问题,本文提出使用双向时间卷积网络(Bidirectional Temporal Convolutional Networks,Bi-TCN)提取文本特征,并通过将两个方向上的语义特征融合,得到综合信息之后再对文本进行情感分析,并在4个中文数据集上进行实验。实验证明,双向时间卷积网络比单向时间卷积网络具有更强的情感分析能力。
1 相关工作
1.1 传统方法
传统提取文本信息分析情感倾向的方法主要利用先验知识,人工设计出能够识别情感倾向的词典,然后根据情感词对文本进行定量的分析。这种方法主要包括两类:基于规则、词典和基于传统机器学习。
基于规则、词典的情感分析方法,利用统计信息和点互信息对文本进行规则定义,或者通过给文档中的情感词、否定词以及程度副词的不同组合打分,按照分数大小判别文本的情感倾向。
基于传统机器学习的方法,如支持向量机(Support Vector Machine,SVM)[7]、朴素贝叶斯模型(Naïve Bayesian Model,NBM)[7]等,利用文本的词频逆文本率(Term Frequency-Inverse Document,TF-IDF)作为特征进行情感分析模型训练,再利用训练好的模型识别文本的情感类别。
1.2 神经网络方法
深度学习在情感分析任务上的表现,大多数网络模型都以循环神经网络(RNN)和卷积神经网络(CNN)为基本结构对文本进行特征提取,然后依据提取到的特征向量对文本进行情感分类。文献[8]在基本的网络模型中加入了层级注意力机制,分别实现了词的注意力和句子的注意力,使文本中对情感体现具有重要作用的关键词和关键句子得到关注。现有的模型除了结构的不同之外,使用的文本特征粒度也有所不同。文献[3,9]使用词特征对文本进行序列建模,文献[10-11]利用字特征对文本进行分析,文献[12-14]则将字和词特征结合起来,使文本特征提取更加全面,更有利于文本情感倾向的分析和判断。此外,文献[8]利用句子粒度特征对文本进行情感分析,也取得了较好的效果。
2 时间卷积网络
时间卷积网络利用卷积计算来对有时间依赖的任务进行序列建模。如给定输入序列x0,x1,…,xn,共n+1个词,需要预测输出序列y0,y1,…,yn,每一时刻的输出yt都仅取决于该时刻之前的一些xt,即:
yt=f(xt-k+1,xt-k+2,…,xt)
(1)
式中:f为变换函数;k为卷积核的大小,当t-k+1小于0时,xt-k+1即为序列的填充值。时间卷积网络有不同的实现方式和不同的应用场景。为了能更好地表达文本序列,文献[5]通过非线性不连续卷积对文本进行特征提取,在文本情感分析任务中达到了较好的效果。文献[15]利用层级时间卷积对视频序列进行动作分割和识别。文献[6]结合序列数据本身的特点以及深层网络模型容易发生退化的因素,将空洞因果卷积[16]和残差结构[17]融合,构建了一个由空洞因果卷积和残差连接组成的新的时间卷积网络,并在文本分类、文本语义推理等多种序列建模任务中取得较好的成绩。
2.1 因果卷积
时间卷积网络中,卷积的因果性质主要通过因果卷积实现。当卷积核大小为k时,卷积计算每一时刻的输出仅依赖当前的输入和之前k-1个输入,而不涉及之后的信息。在具体网络结构实现上,为了能够使输入与卷积计算输出在维度上保持一致,需要在输入序列的左边进行k-1个零值向量填充。
2.2 空洞卷积
因果卷积仅能在卷积核大小的范围内提取文本序列中的连续的n-gram特征,无法获得距离较远的内容。为使卷积的感受野变大获得长期依赖,文献[6,16]使用空洞卷积作为因果卷积的基本结构。空洞卷积隔一定的空洞数对序列进行采样计算,在功能上与将部分卷积值进行归零相似。或者通过扩大卷积核后将部分卷积核的权值置零也能得到相同的结果,但是在效率上空洞卷积执行的速度更快,效率更高。
2.3 残差链接
残差结构[17]将输入x与经过非线性变换后的F(x)进行求和,形成短路连接:
H=x+F(x)
(2)
这种结构能在深层网络中较好地拟合输入发生的变化,使网络中的参数不随网络的深度增加而难以优化。因为TCN感受野的扩大部分依赖于卷积网络层的叠加,而残差连接可以在网络层数不断增加的情况下抑制网络模型训练可能出现的梯度消失现象。
3 双向时间卷积网络
在深度学习的研究中,对序列进行单向建模在大多数情况下往往不如双向建模对序列的特征捕获更加充分、语义信息表达更完整。基于这个理念,有很多的基础模型都使用双向计算机制对文本序列进行计算。文献[18]在LSTM基础上提出了Bi-LSTM对文本进行特征提取,以弥补单向LSTM随着序列长度的增加记忆能力减弱造成的影响。通过实验验证,在现有的很多任务上Bi-LSTM的效果要优于LSTM。此外,文献[19]以多头注意力[20]作为基本结构提出了对文本进行双向建模的BERT(Bidirectional Encoder Representations from Transformers)预训练模型,并在多项自然语言处理任务中超跃基于单向多头注意力的GPT(Generative Pre-Training)[21]。由此可见,对文本序列进行双向建模能够综合地提取文本的特征信息,更有利于文本的推理和分析。普通时间卷积网络对文本按照时间顺序进行单向卷积计算,每一个时间步上的语义计算仅利用了当前时刻和之前时刻的信息,即每一个词的编码信息仅包含之前的语义信息。而在文本中,词的语义很可能与这个词之后的信息有很大的关联,后面的文本信息可能使文本整体语义发生变化。在这种情况下,单向时间卷积网络忽略了后文的信息,不能够很好地使每一个词的语义信息足够全面得表达,限制了文本整体语义特征的获取。本文针对这一情况,提出了双向时间卷积网络(Bidirectional Temporal Convolutional Network,Bi-TCN),对文本进行前向和后向特征提取,再将两个方向上的最后一个时刻的特征信息线性变换后进行融合,得到文本整体语义信息的综合表达,并在此基础上对文本进行情感分析。Bi-TCN模型整体架构如图1所示。
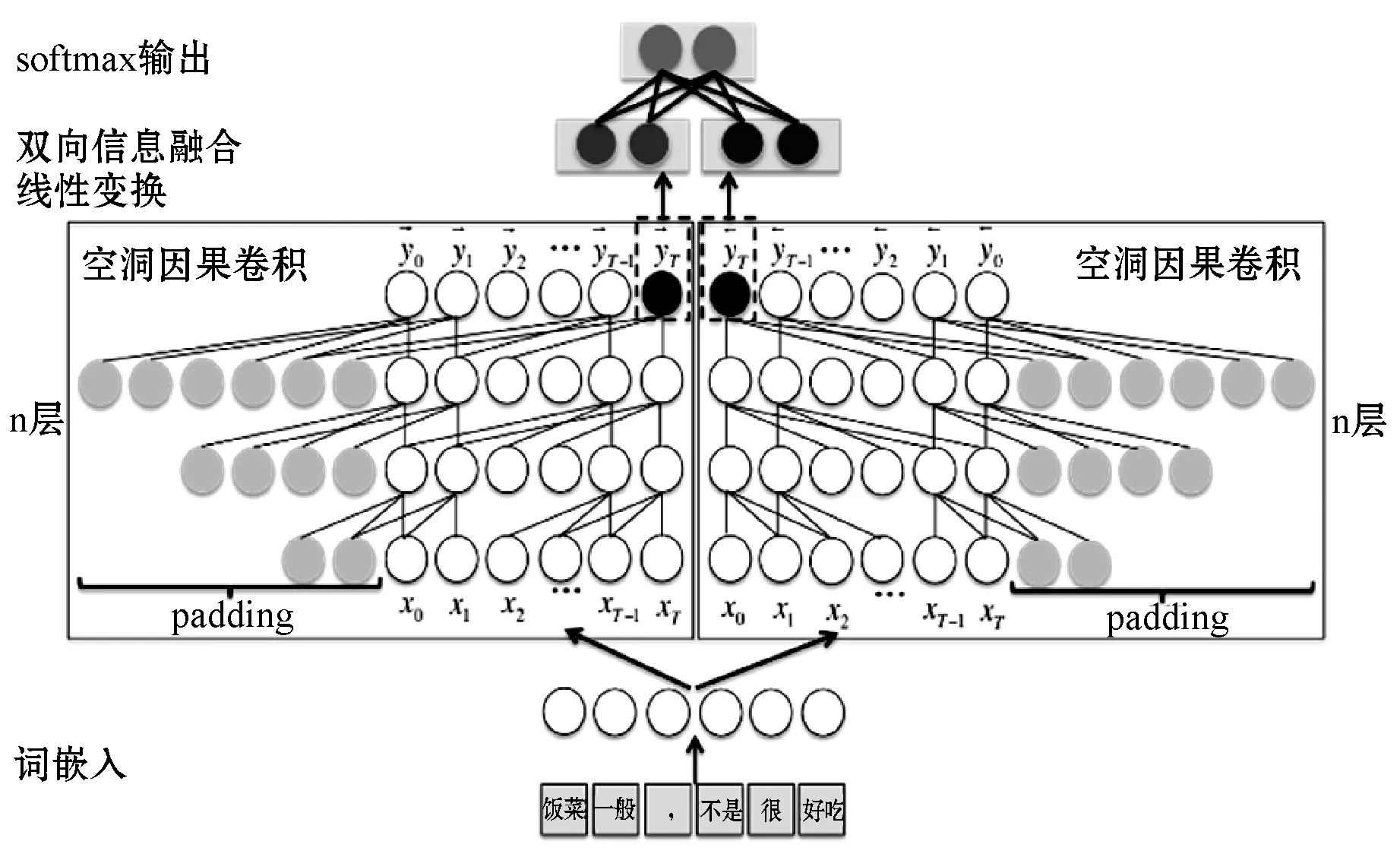
图1 Bi-TCN模型结构图
3.1 词嵌入
本文使用fastText[22]对文本进行词向量预训练,得到所有词汇的稠密词向量表达。该方式训练的词向量不仅能够较好地表达一个词的多种详细特征,体现出词与词之间的相似度和关联性,还能在情感分类中,对于每一个词属于的情感类别进行预判,帮助模型对文本进行情感分析。
对给定一个句子分词之后的序列S={x0,x1,…,xn}进行词嵌入的时候,本文将每一个词xn通过嵌入矩阵Ww转化成固定的词向量ew。
ew=(Ww)Tnword
(3)
式中:Ww∈RNword×Dd;nword表示词在词汇表中的one-hot编码;Nword表示词汇表中词的数量;Dd表示每一个词向量的维度。通过词嵌入,文本序列就被映射成为向量序列。
3.2 空洞因果卷积层
空洞因果卷积层通过一维空洞卷积在序列的左侧进行填充,对序列从左向右进行卷积计算,实现前向特征提取。然后将原序列翻转,按照前向的计算方式对翻转后的序列进行后向卷积计算。每一次空洞因果卷积计算后,都将参数进行层级归一化[23],然后通过激活函数ReLU进行非线性计算。将原始输入与非线性计算之后的结果进行残差连接。这一个整体就构成了一个空洞因果卷积模块。
si=Conv(Mi×Kj+bi)
(4)
{s0,s1,…,sn}=LayerNorm({s0,s1,…,sn})
(5)
{s0,s1,…,sn}=ReLU({s0,s1,…,sn})
(6)
式中:si是i时刻卷积计算得到的状态值;Mi为该时刻卷积计算的词的矩阵;Kj为第j层的卷积核;bi为偏置;{s0,s1,…,sn}是序列经过一次完整的卷积计算后的编码。经过多个因果卷积层的堆叠,扩大卷积的感受野,使文本的特征提取更加完整,获得文本序列的高层语义信息。
3.3 线性变换
(7)
(8)
式中:Wn×m是线性变换参数矩阵,前向计算和后向计算的参数不同,维度一致;n为变换前语义向量的维度;m为变换后的维度。
3.4 特征融合
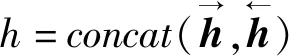
(9)
3.5 softmax输出
利用融合后的特征信息h来进行情感分类,通过Softmax分类器输出文本所属情感类别的概率分布。
prob=softmax(hW2m×c+b)
(10)
式中:W2m×c为参数矩阵;c是情感分类的类别;b为偏差,其维度也是c。
4 实验与分析
4.1 实验数据
本文在文献[7]整理的酒店评论数据集上进行实验,该数据集包含10 000篇文档,共有积极(正)和消极(负)两种极性的情感类别。所有的文档构成了4个不同的子集:ChnSentiCorp-Htl-ba-2000,ChnSentiCorp-Htl-ba-4000,ChnSentiCorp-Htl-ba-6000,ChnSentiCorp-Htl-ba-10000。每一个子集的情感类别数具体分布如表1所示。为了简化表示,本文将以上4个数据集依次表示为corp-1,corp-2,corp-3,corp-4。
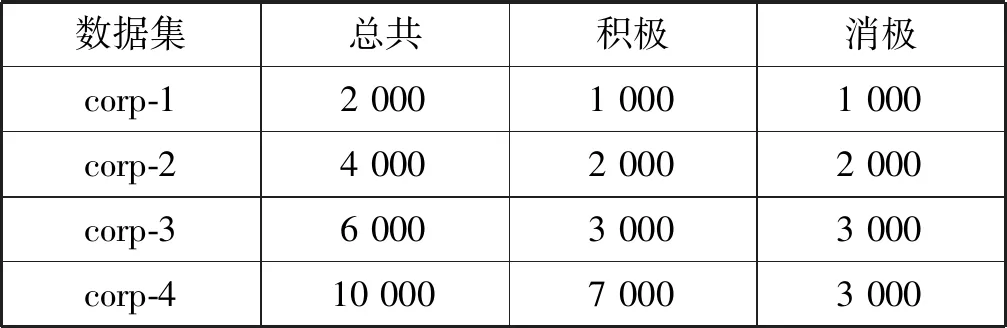
表1 酒店评论数据集
4.2 预处理
本文对文本数据主要做了两个方面的预处理工作,如表2所示。
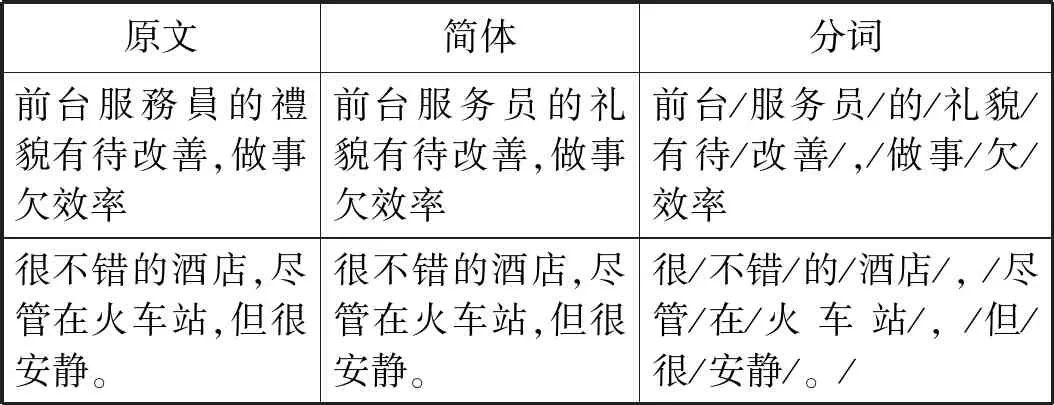
表2 数据预处理
(1) 将文本中的繁体中文转化为简体中文。
(2) 利用结巴分词(https://pypi.org/project/jieba/)工具对文本进行分词。
4.3 Bi-TCN参数研究
在实验过程中,我们发现Bi-TCN模型存在易受卷积层数、卷积核大小和空洞因子这三个参数的影响而发生不收敛的现象。当卷积层数少,并且卷积核较小时,利用卷积计算进行特征提取的感受野不够宽,不能捕捉文本的长期依赖,不足以提取足够的特征进行情感分析而使得模型不收敛。而层数过多,卷积核过大,受空洞因子的影响会使卷积的感受野超过文本本身长度,这既增加了不必要的计算,也会使模型出现过拟合。故本文就这三个参数对Bi-TCN在中文情感分析任务上的影响进行了对比实验。
4.3.1卷积层数
实验固定卷积核大小为7,空洞因子为层数的两倍,保持其他参数不变的情况下,改变卷积层数对模型进行训练,得到的实验结果如图2所示。实验表明,随着卷积层数的增加,模型的泛化能力逐渐提高,而层数过多则会导致性能有所降低。可以看出,当卷积层数为4时,实验效果最好,此时可以计算得到模型的长期依赖最长距离为79。当卷积层数为5时,最长依赖为127,此时需要进行126个值填充,由底层向上层传播时就会引入很多的噪声,使模型的拟合能力和泛化能力都下降。而本实验中的文本长度最长为140个词,模型层数越多,最高层感受野就会超过这个长度,模型学习的对象就偏离了数据本身,故在测试集上的表现就会变差。
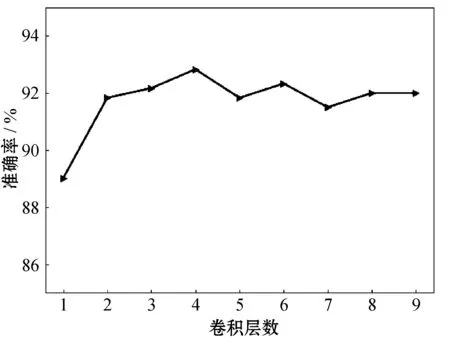
图2 卷积层数对Bi-TCN分析结果影响
4.3.2卷积核大小
固定卷积层数为4,空洞因子为2n,通过改变卷积核的大小来研究卷积核的变化对模型性能的影响,实验结果如图3所示。可以看出,卷积核大小为7时模型表现较好。卷积核的取值决定了模型n-gram特征包含的词的数量。当卷积核较小时,一次卷积计算所能囊括的关联性较少,不足以提取词与词之间的关系,故随着卷积核的增大,模型的准确率会上升。当卷积核过大时,可能会将无关信息纳入卷积计算,增加噪声,破坏模型对文本规律的学习,所以卷积核越大,模型的性能反而会降低。
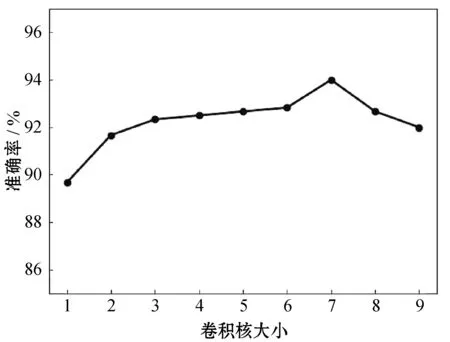
图3 卷积核大小对Bi-TCN分析结果影响
4.3.3空洞因子
本轮实验保持卷积层数为4、卷积核为7不变,探究空洞因子对模型的影响。空洞因子中n∈{0,1,2,3},当n=0时,默认空洞因子为1。通过实验,得到不同的空洞因子的实验结果如表3所示。根据空洞因子,结合卷积层数和卷积核大小,计算每一个模型中卷积计算的最长依赖,发现最长依赖距离超过并接近整个序列长度的一半时表现较好(所有实验中,固定序列最长值为140)。而长期依赖距离越大,会使模型性能下降。实验数据中,大多数句子长度都集中在90词以下,并不需要过长的长度依赖,否则会使模型拟合一些噪声,出现过拟合问题。
4.4 实验参数设置
实验中,利用fastText方法预训练词向量和字向量,维度为300,每一个批次大小为64,空洞因果卷积层数为4,卷积核大小为7,空洞因子为2n,Adam优化器学习率为0.002,dropout为0.25,句子长度统一为140个词。
4.5 对比实验
本文用8种方法在酒店评论数据集进行实验对比:
(1) SVM(支持向量机)。利用文本的TF-IDF特征构建SVM模型进行实验。
(2) NBM(朴素贝叶斯模型)。利用文本的TF-IDF特征构建NBM模型进行实验。
(3) Bi-LSTM。通过LSTM神经网络对文本进行前向和后向语义特征提取,并将两个方向的最终状态融合,再根据融合后的综合信息进行情感计算。
(4) COCNN。文献[26]提出了一种改进的卷积神经网络模型,利用双通道的字和词特征进行情感分析。
(5) CNN。利用多核卷积对文本进行多种类型的特征提取,然后将多个特征进行融合,以此进行情感分析。
(6) Uni-TCN。单向时间卷积网络,仅对文本进行单向多层因果卷积计算,使用序列中最后一个时刻的状态作为最终语义进行情感分析。
(7) Bi-TCN(双向时间卷积网络)。即本文模型。
4.6 实验结果分析
本文对比多种模型进行实验,以模型在数据集上进行10折交叉验证的准确率为模型评价结果,具体实验结果如表4所示。其中(c)表示以字为特征的模型的实验结果。
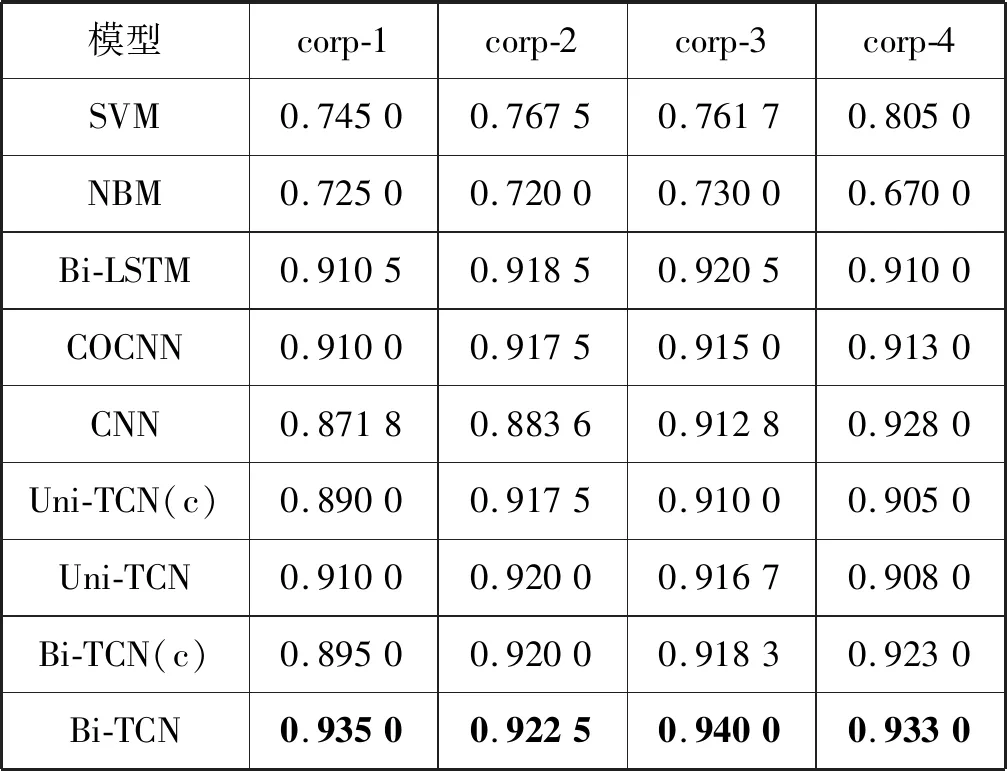
表4 对比实验结果
由表4的实验结果可以发现,传统机器学习算法中,朴素贝叶斯模型(NBM)的分类效果不如支持向量机(SVM)好。因为在大量数据分类情境下,文本中的词并不是独立存在的,词和词之间具有一定的相关性,而NBM将文本中的每一个词看作条件独立,这就忽略了词之间的互相影响,而SVM则会将文本特征进行全面的衡量和计算。
对比传统方法和神经网络方法,总体上神经网络方法要优于传统方法。传统方法SVM和NBM利用文本的TF-IDF特征来进行情感分类,其特征具有较大的稀疏性。而神经网络使用稠密的词向量来对每一个词进行特征表达,特征更加丰富。
将Bi-TCN和其他模型相比,在4个数据集上的实验效果而言,Bi-TCN的准确率要优于Bi-LSTM。从训练速度上来说,基于卷积计算的Bi-TCN要比Bi-LSTM模型具有更高的并行能力,模型的训练和测试都要快很多。相比COCNN和CNN,这两个模型都使用了字和词的特征对文本进行建模,而Bi-TCN仅仅使用了词特征,就达到了领先的效果,说明了Bi-TCN具有较强的序列建模能力。对比Bi-TCN和Uni-TCN,分别用字向量和词向量训练了Uni-TCN和Bi-TCN,结果表明,用字特征训练的效果不如词特征好,因为从词汇表而言,字特征数量较少,而词特征的数量相对较多,特征更为丰富。此外,就单独使用字特征、词特征,Bi-TCN在数据集上的实验效果也要比Uni-TCN好。总体上,Bi-TCN在4个数据集上的准确率相比Uni-TCN分别提高了 2.5%、0.25%、2.33%和2.5%,从而证实了Bi-TCN对文本序列的建模能力更强,提高了情感分类效果。
4.7 模型性能分析和对比
除了通过情感分析任务中的实验结果将Bi-TCN与Uni-TCN进行对比,本文还根据两个模型在训练过程中的表现进行了性能比较。在实验过程中,发现Bi-TCN对文本进行情感分析时,第一个轮次训练得到的准确率总是比Uni-TCN更高。而且在之后的训练过程中,Bi-TCN对过拟合的抵抗性更强,总体能达到的效果更优越(如图4所示)。这就说明了双向时间卷积网络在对文本建模的过程中,对文本中关键特征的提取更加全面,模型的收敛速度更快。
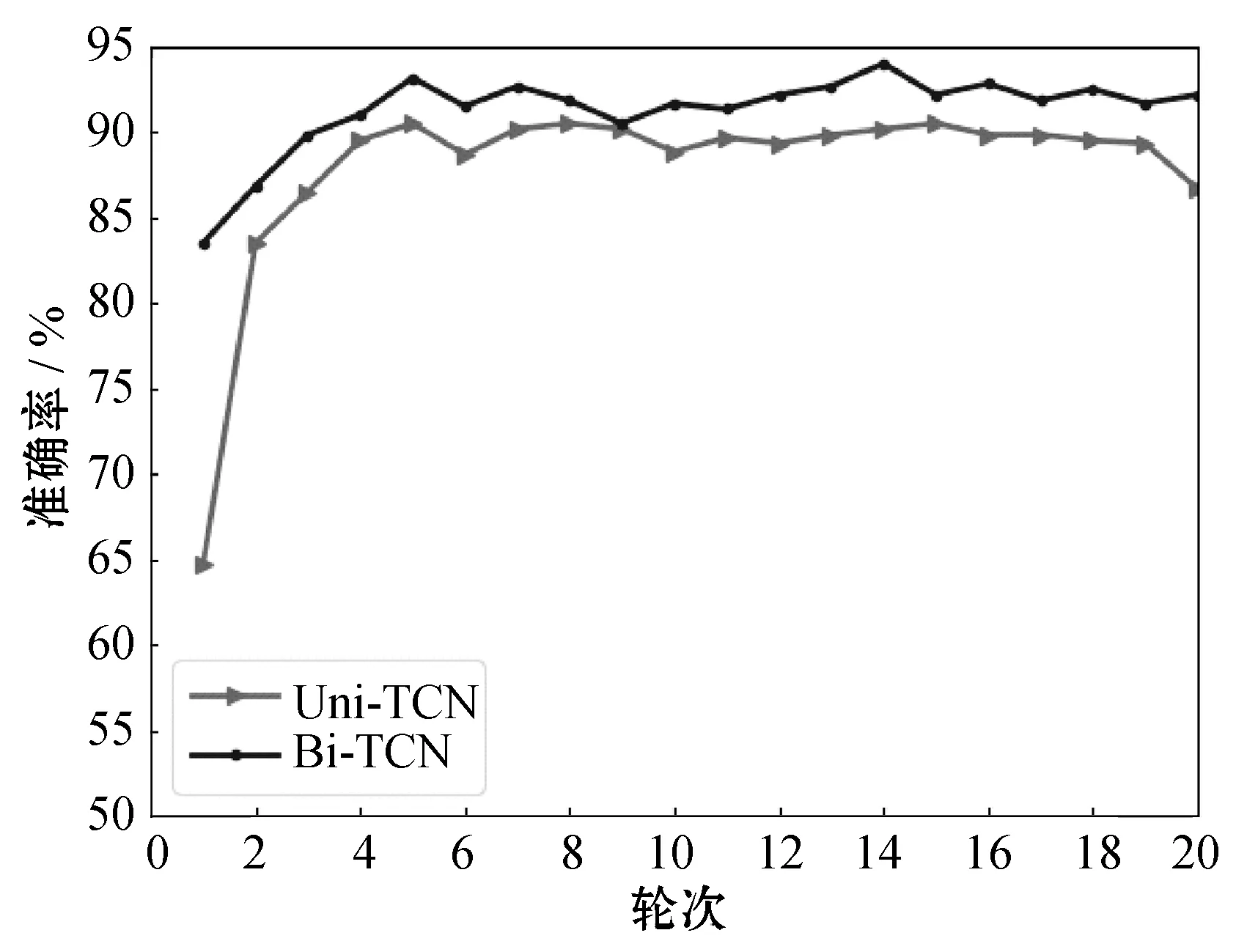
图4 Bi-TCN和Uni-TCN实验结果
5 结 语
针对现有的时间卷积网络模型对文本序列的单向性计算不能完全捕获文本的语义表达的问题,本文提出了双向时间卷积网络的中文情感分析方法。通过对文本序列进行前向和后向的多层空洞因果卷积计算,将两个方向上最后一个时间步的语义向量分别通过线性变化后进行融合,使用两个方向上的综合信息对文本进行情感分类。通过对影响双向时间卷积网络性能的参数进行实验对比,确定了卷积层数、卷积核大小和空洞因子的参数值。在中文情感分析数据上的对比实验表明,本文方法能够提取更为丰富的文本特征,有效提高情感分析的效果。
