基于条件流的人脸正面化生成对抗模型
2019-12-12张鹏升
张鹏升 解 易 刘 钊
1(中国人民公安大学信息技术与网络安全学院 北京 102623)2(北京燧原智能科技有限公司 北京 100191)3(中国人民公安大学网络空间安全与法治协同创新中心 北京 100038)
0 引 言
人脸正面化是根据侧面人脸生成相同身份的正面人脸。这为人脸识别中经典的姿态不一致问题(Pose-Invariant Face Recognition,PIFR)[1]提供了有效的解决办法。不仅如此,生成的正面人脸可以应用到一系列与人脸相关的任务,如人脸重建、人脸属性分析、面部动画制作等[2]。随着卷积神经网络可以在大型人脸数据集上训练[3]和产生式模型[4-6]的快速发展,人脸正面化取得显著的成果。但因为侧脸本身信息的缺失使得人脸正面化依然是一个极具挑战性的问题。目前基于产生式模型的人脸正面化方法主要集中在使用生成对抗网络(Generative Adversarial Network,GAN)和变分自编码器(Variational Auto-Encoder,VAE)。
GAN网络是目前产生式模型中最为热门的方向之一。GAN的思想是通过博弈的方法交替训练生成器和判别器,从而使得生成样本和真实样本在分布上越来越相近。基于GAN的拓展网络模型在人脸正面化上取得不错的效果。DR-GAN[7]能够学习解耦的身份表示,实现任意角度人脸的生成。CAPG-GAN[8]使用人脸全局拓扑信息作为指导,保证生成的图片更加逼真。但是,GAN无法对样本进行编码,不涉及对潜在变量空间的计算,因此缺乏对数据的全面支持。同时,GAN的训练不稳定以及模式崩塌[9]现象一直以来是困扰GAN的问题,在训练中判别器过于严格,而且直接在像素级别进行判别往往会导致生成样本的多样性受限。
VAE网络是基于似然的方法,由编码器和解码器两部分组成,通过让图像编码的潜在向量服从高斯分布从而实现图像的生成。在人脸正面化领域,VAE发挥了重要的作用。如SPAE[10]通过堆叠自编码器将非正脸旋转为正面人脸。IntroVAE[11]在不引入额外的对抗判别器的情况下,克服了变分自编码器固有的合成图像趋于模糊的问题。但是,VAE是优化了数据对数似然的下界,属于近似模型,不能实现精确的推理,而且VAE只能用来产生确定分布的图片,如伯努利分布和高斯分布,这限制了产生式模型生成样本的能力。
针对以上问题,本文设计了基于流的条件生成对抗网络模型。该网络模型由生成网络和判别网络两部分组成。生成网络采用流模型,glow模型[12]出色的实验效果使基于流的产生式模型得到了人们的重视。在生成网络中,通过采用条件实例归一化层(Conditional Instance Normalization,CIN)[13]控制角度,生成正面人脸。判别网络采用变分判别器瓶颈(Variational Discriminator Bottleneck,VDB)[14]更好地利用生成网络得到的潜在变量对身份进行判别,保证生成身份一致的正面人脸。总体而言,本文进行了以下创新:① 采用glow模型作为生成网络,实现对潜在变量的精确推理,而不是近似的推理,从而保证生成效果;② 采用条件实例归一化层控制生成,根据不同的角度对归一化层选择不同的缩放和平移参数;③ 采用VDB作为判别网络,提高判别器的判别难度,缓解GAN训练时判别器过于强势的问题,提高训练的稳定性。
1 相关研究
1.1 人脸正面化
人脸正面化常见的方法可以大体分为两类:一是利用图形学的方法从侧脸获得正脸;二是通过产生式模型根据侧脸生成正脸。因为侧面人脸和正面人脸的差异主要在进行二维投影时产生的纹理发生的压缩形变和自遮挡,所以图形学方法是最直接的方法[15]。常见的三维图形学方法有光流法[16]、三维形变模型法[17]、非刚体模型法[18]等。图形学方法虽然直接,但是生成的图片容易存在畸变较大的情况,如图1(a)所示。随着产生式模型不断的发展,网络性能不断提高,第二类方法得到人们更多的关注。如前文提及的DR-GAN、CAPG-GAN和SPAE等网络都在人脸正面化上取得了不错的效果,如图1(b)所示。目前基于产生式模型的人脸正面化方法对于流模型的关注较少,但实际上流模型具有高效的合成和推断能力,生成图片的效果可以与GAN相比。本文采用流模型并利用判别器判别身份,既发可以挥传统产生式模型的优点保持身份一致,又能实现逼真图像的合成。

(a) 文献[17]三维形变模型法的人脸正面化效果

(b) 文献[10]SPAE的人脸正面化效果图1 部分人脸正面化方法的效果
1.2 变分判别器瓶颈
本文的判别网络采用变分判别器瓶颈来解决GAN训练中存在的问题。在对抗学习中,判别器一直过于强势,当判别器训练到最优时,生成器的梯度消失,造成了对抗中的不平衡,而且直接在像素级别判别会影响生成样本的多样性。文献[14]提出了变分判别器瓶颈,通过对数据样本和编码得到的潜在空间的互信息进行限制,削弱判别器的能力,从而平衡网络的训练。在本文中,互信息反映了样本x和潜在变量z的相关程度。理论上,z是由x编码得到,所以x和z是完全相关的,所以二者的互信息是很大的。限制二者互信息的值,从而限制了二者相关性较低的部分,保留x和z最具有辨别力的特征,增强了训练过程中身份的一致性。同时,VDB是对样本编码得到的潜在空间进行判别保证了生成样本的多样性。为了实现对互信息的限制,通过生成网络E(z|x)对样本x编码为潜在变量z,通过对二者的互信息I(X,Z)进行限制,正则化目标为:
(1)
s.t.I(X,Z)≤Ic
式中:y代表标签;p(x,y)为样本和标签的分布;q(y|z)代表z到y的映射。互信息定义如下:
(2)
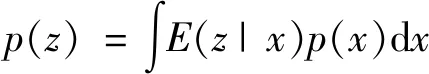
Ex~p(x)[KL[E(z|x)‖r(z)]
(3)
(4)
s.t.Ex~p(x)[KL[E(z|x)‖r(z)]]≤Ic
优化时可以采取拉格朗日系数。
1.3 Glow流模型
流模型早在2014年就已经提出,先后经历了NICE[6]和RealNVP[19]两个阶段,Glow正是在这两个模型的基础上进行了改进,展现了强大的图像生成能力。相比GAN不涉及潜在变量的计算和VAE只是近似的推理,Glow在图像编码得到的潜在变量上可以做到精确的推理,而且可以计算样本的准确对数似然。流模型选择直接计算数据样本的分布,所以可以产生任意的分布样本,弥补了VAE只能产生确定分布的图片的缺点。Glow通过学习一个确定的非线性转换,能将高维数据映射到潜在空间,同时这个过程是可逆的,可以将潜在空间的数据映射到高维。因此,关键在于确定一个可逆的函数f,使得z=f(x),生成过程可以表示如下:
z~pz(z)x=f-1(z)
(5)
pz(z)为可选择的先验分布;z为潜在变量通过可逆函数f生成样本。为了保证样本信息充分混合,选取f为一系列转换函数的组合f=f1∘f2∘…∘fk。
(6)
正是因为存在着这样一系列可逆的转换过程,像流水一般,所以模型被称为流模型。对于式(5),其似然函数可以表示为:
(7)
文献[6]通过对输入进行分组,构建了便于求雅克比矩阵的可逆映射函数f,从理论上证明流模型可以优化求解。
在Glow模型中,单步流操作包括Actnorm层、可逆1×1卷积层和仿射耦合层。Glow采用可逆的1×1卷积层替代固定的置换操作,保证对输入图片信息的充分混合。在训练过程中,随机生成旋转矩阵W,对其进行LU分解,即W=PLU。其中:P为置换矩阵;L为下三角阵,对角元素均为1;U为上三角阵。因此矩阵W的值容易求得:
log|det(w)|=∑log|diag(U)|
(8)
在训练时,需要固定P,约束为L对角元素均为1,U为上三角阵,对其他参数进行优化训练。
在仿射耦合层确定了可逆函数f,具体包括分割、仿射变换和连接操作。对于给定人脸图片x,在通道方向上将其分为两部分(xa,xb),仿射变换操作如下:
ya=xa
yb=xb⊙exp(s(xa))+t(xa)
(9)
式中:函数s和t代表缩放和平移操作,可以为任意复杂的函数,保证公式的可计算性和模型的非线性能力;⊙代表哈达玛乘积操作。文献[19]已经证明该仿射变换是可逆的,而且雅克比矩阵是易求的,为exp∑s。连接操作属于分割操作的逆操作,将分割开的两部分张量合为一个张量y=(ya,yb)。
2 基于流的条件生成对抗生成网络
本文设计的模型由两部分组成:采用流模型的生成网络;采用变分判别器瓶颈的判别网络。因为流模型是基于可逆变换的模型,所以训练完成时会同时得到一个编码模型和生成模型。判别网络通过判别身份,进一步加强生成图片的身份一致性。
2.1 生成网络
本文在Glow模型的基础上提出了新的条件流模型。整体结构沿用了文献[19]的多尺度框架,保证模型的非线性能力。在单步流操作中通过采用条件实例归一化层对传统Glow模型进行创新。传统的Glow模型是非条件的生成模型,不能做到生成指定角度的人脸图片。通过对单步流操作进行改进,采用条件实例归一化层,在训练过程中加入标签与人脸图片进行训练,从而控制生成图片的方向,生成正面的人脸图片。单步流操作具体包括条件实例归一化层、可逆1×1卷积层和仿射耦合层。生成网络结构图如图2所示。
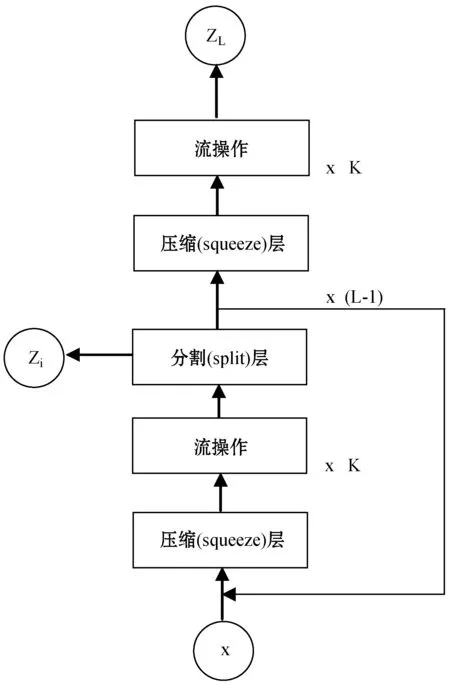
(a) 多尺度框架(沿用文献[19]的多尺度框架)

(b) 单步流操作结构图2 生成网络结构
图2(a)中的压缩(squeeze)层实现了输入图片在通道轴上具有更高的维度,使得在之后的操作中输入数据在空间上仍具有局部相关性。一个完整的流操作需要K次单步流来完成,完整流操作结束后进行分割操作,经过L-1次多尺度循环得到最终的潜在变量z=(z1,z2,…,zL)。
2.1.1条件实例归一化层
在训练深度学习网络时,使用批归一化层(Batch Normalization,BN)[20]或者实例归一化层(Instance Normalization,IN)[21]可以让训练过程更加容易和稳定。文献[13]提出了条件实例归一化层,在每次归一化操作时使用缩放和平移参数可以有效地控制生成。每次归一化的目标函数如下:
(10)
式中:μ和σ是输入x均值和标准差;γd和βd代表缩放和平移参数;d代表标签。在本文设计的模型中,d代表人脸角度标签ypose,不同的人脸角度选择不同的缩放和平移参数以此来控制生成。采用条件实例归一化层既能保证训练过程的稳定性,同时起到了控制正面人脸生成的作用。
2.1.2生成网络的目标函数
对于本文设计的生成网络,将高维数据映射到潜在空间时相当于编码模型E(z|x),将潜在空间的数据映射到高维空间时相当于生成模型G(x),对于潜在变量z,希望生成真实图片xL,因此根据式(7)可得目标函数为:
(11)
式中:px为真实数据分布;pz为生成模型的先验分布;fi(x;θi)为第i个转换函数。
2.2 判别网络
判别网络采用变分判别器瓶颈可以更好地利用生成网络中编码模型E(z|x)得到的潜在变量z,不再是传统上在像素级别进行判别,而是在互信息上进行瓶颈限制,实现平衡网络的训练并保证生成图片的身份一致性。根据原始GAN的目标函数,判别网络希望最大化识别出真实图片为真和生成图片不为真的概率,因此加入变分判别瓶颈的判别网络的目标函数为:
Ex~G(x)[Ez~E(z|x)[log(1-D(z))]]
(12)
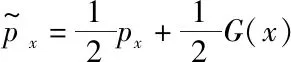
Ex~G(x)[Ez~E(z|x)[log(1-D(z))]]+
(13)
因此,我们可以根据具体的限制Ic来更新β实现对互信息的约束。在实际训练过程中需要对编码模型E(z|x)得到的z求均值和标准差,从而可以求解与r(z)~N(0,1)的KL散度。
3 实 验
3.1 网络结构
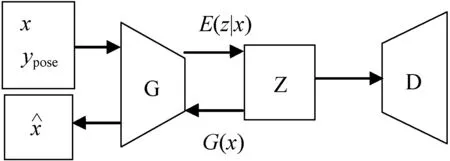
图3 Cflow-GAN网络结构
3.2 实验设计
本文使用Multi-PIE数据集进行训练,选取数据集中300位具有中性表情的参与者的人脸进行实验,角度选取±60°共9种。其中200名参与者的人脸图片作为训练集,共32 238幅图片。剩余100名参与者的人脸图片作为测试集,共9 000幅图片。
在实验中,生成网络的每个耦合层采用三层卷积,前两层采用ReLU激活函数,第一层和最后一层是3×3的卷积核。中间一层是1×1的卷积核,通道数为512。与文献[12]不同之处在于将Actnorm层替换为条件实例归一化层(CIN),通过CIN层实现控制正面人脸的生成。
因为本文采用的生成网络既属于编码器又属于解码器,所以判别网络不需要像文献[14]中的VGAN一样分为两部分,可以直接使用生成网络所得的潜在变量z,只需要承担线性分类器的功能。对于变量z采用VAE中重参数技巧,传递给判别网络,保证网络可以计算KL散度。对于β的更新,采用αβ=10-5的步长进行更新。网络结构设置如表1所示。

表1 网络结构设置
实验采用了文献[19]中的squeezing操作,让通道轴具有更高的维度,使得生成网络在对输入信息进行打乱和分割时,可以只对通道轴进行操作,保证图片空间的局部相关性。表1中的C代表经过squeezing操作后的通道轴数。编码得到z经过判别网络中的FC1和FC2得到其均值和标准差,从而可以采用重参数技巧进行训练。在实验中,单步流操作次数K=48,循环次数L=4。
3.3 实验结果
在定量分析中,首先根据负对数似然函数值进行定量分析,将本文设计的模型与Glow[12]进行比较。根据文献[22]将负对数似然函数值转换为bits/dim进行度量。负对数似然函数值可以衡量基于流模型的不同网络框架的生成效果。该值转换为bits/dim后,数值越小代表生成图片质量的越高。根据表2可以看出,相比Glow,本文设计的网络模型(Cflow-GAN)加入采用变分判别器瓶颈的判别网络后,在生成图片时能得到较低的负对数似然函数值。

表2 负对数似然函数值 bits·dim-1
此外,通过Top-1 Accuracy对生成图片的可区别性进行评估,根据文献[23]采用Inception Score生成图片的真实性和多样性进行评估。根据表3可以看出,相比DR-GAN[7],本文设计的网络模型可以生成更具区别性的正面人脸,而且根据第三列Inception score的结果,可以看出Cflow-GAN能够生成更具真实性的图片。
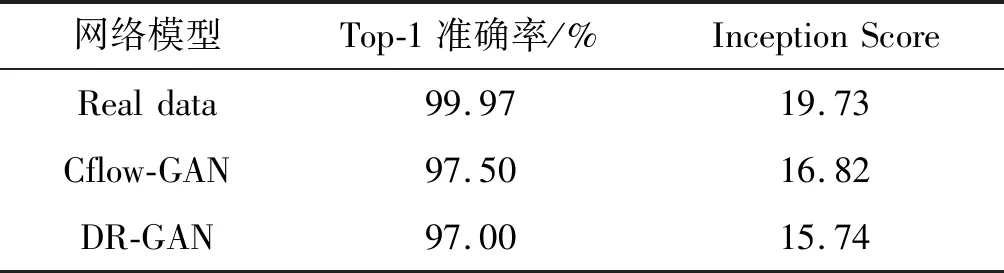
表3 生成图片的定量分析结果
对于定性分析,本文与DR-GAN生成的正面人脸进行比较。图4和图5分别是同一身份及不同身份在不同角度下生成的正面人脸。其中:第一行均为输入的侧脸人脸;第二行均为DR-GAN生成的正面人脸;第三行均为本文设计的网络模型生成的正面人脸。通过图4可以看出在相同身份下,本文设计的模型采用VDB作为判别网络,可以较好地保证生成图片身份的一致性。通过图5可以看出本文设计的模型不同角度和不同身份下仍可以生成质量较高的人脸图片。

图4 同一身份不同角度生成的正面人脸

图5 不同身份不同角度生成的正面人脸
4 结 语
本文设计了基于流的条件生成对抗网络,实现了对流模型的控制生成,将流模型高效的推理与生成对抗的思想结合在一起,在互信息层面上对潜在变量进行限制,提升了网络训练的稳定性,保证了生成图片的真实程度。但是,基于流模型的生成网络训练运算量较大、训练时间较长,需要进一步在模型方面考虑减少运算量,更加高效地进行推理和生成。
