基于改进Inception卷积神经网络的手写体数字识别
2019-12-12余圣新夏成蹊唐泽恬
余圣新 夏成蹊 唐泽恬 丁 召 杨 晨
(贵州大学大数据与信息工程学院贵州省微纳电子与软件技术重点实验室 贵州 贵阳 550025)
0 引 言
手写体数字识别广泛地应用在银行、快递等领域。例如银行人工服务支取大量现金时需要填写的单据上的金额、日期等手写数字信息。其他常见的应用场景还包括填写快递单时的手机号码、邮政编码等,因此研究手写体数字识别具有较高的现实意义与经济价值。
传统手写体数字识别与分类的方法是通过人为构建特征描述子来提取图像特征,再利用分类器对所得特征进行分类,如通过梯度方向直方图特征(Histogram of Oriented Gradient,HOG)[1]和局部二值模式(Local Binary Pattern,LBP)[2],但是该方法需要大量人工操作。随着硬件设备计算能力快速提升,深度学习也成为图像分类的一个重要方式。1998年,文献[3]结合卷积与池化,提出LeNet-5,用于识别手写体数字,识别率达到99.13%,高于传统方法的98.67%。2012年,文献[4]提出AlexNet,使用Relu作为激活函数,并且大量使用卷积层与池化层,使得网络能够获得更加丰富的特征,在ImageNet(ILSVRC-2012)竞赛中,top-5测试误差为15.3%。2014年,文献[5]提出GoogLeNet,其提出的Inception V1结构,采用不同大小卷积核提取不同的特征,在ImageNet(ILSVRC-2014)竞赛中,top-5测试误差只有6.66%。GoogLeNet为卷积神经网络的研究与发展提供了新方向,即增加网络宽度以获得更好的正确率。但宽度增加也会引起参数增加,同时增加计算负担。为减少参数,提出Inception V2[6]和Inception V3[7],Inception V2采用三个3×3代替7×7卷积,Inception V3则采用连续非对称卷积1×7与7×1代替7×7卷积。2015年,文献[8]提出残差网络(ResNet),随网络层数增加而出现的梯度弥散问题由此得以解决。2016年,文献[9]结合ResNet,改进Inception提出Inception-ResNet。2017年,为更好地增加网络宽度,深度可分离卷积(Xception)被提出[10],将通道间的相关性完全分离。
尽管卷积神经网络越做越深,但是对于手写数字这类小分辨率图像的识别,大而深的网络会由于参数量过大而占用过多计算资源,因此需要一款深度合适而识别率较高的网络。本文采用深度可分离卷积代替Inception结构中的传统卷积,改进Inception结构,增加Inception结构的网络宽度,并且结合残差网络(ResNet)防止梯度弥散。在分类器的选择上则选用支持向量机作为分类器[11],基于其对数据的维度、多变性不敏感等特性[12],结合支持向量机(SVM)对卷积神经网络提取的特征进行分类[13],使用10折交叉验证法验证SVM所得识别率。
1 网络结构和改进算法
本文采用训练网络整体结构如图1所示。对输入图像进行两次连续非对称卷积代替7×7卷积核,完成图像特征的初步提取;改进Inception结构用于加大网络宽度,并通过Maxpool对特征进行压缩,同时引入残差网络防止梯度弥散;之后使用传统卷积层与池化层相结合的方式,缩小特征图,中间加入Dropout层,其作用为以一定概率随机将部分隐藏层节点权重归零,从而防止网络过拟合;最后分别使用softmax与支持向量机对特征进行分类与比较。每一层卷积后都使用Relu函数y=max(0,y) 作为激活函数,使用交叉熵函数作为损失函数训练网络,同时使用批量标准化来减少网络对学习率的要求,加快网络收敛,缓解过拟合。
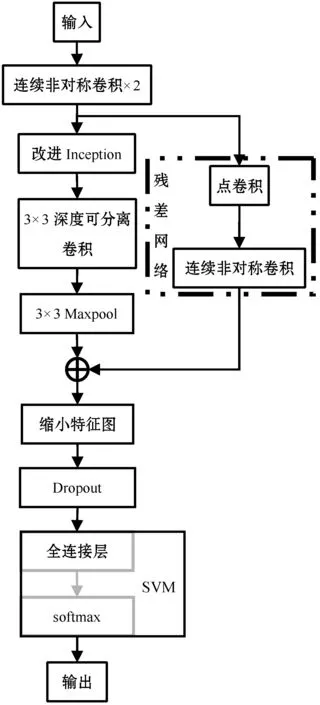
图1 整体网络结构
网络各层输出如表1所示。

表1 各层输出特征图大小
算法流程如图2所示。
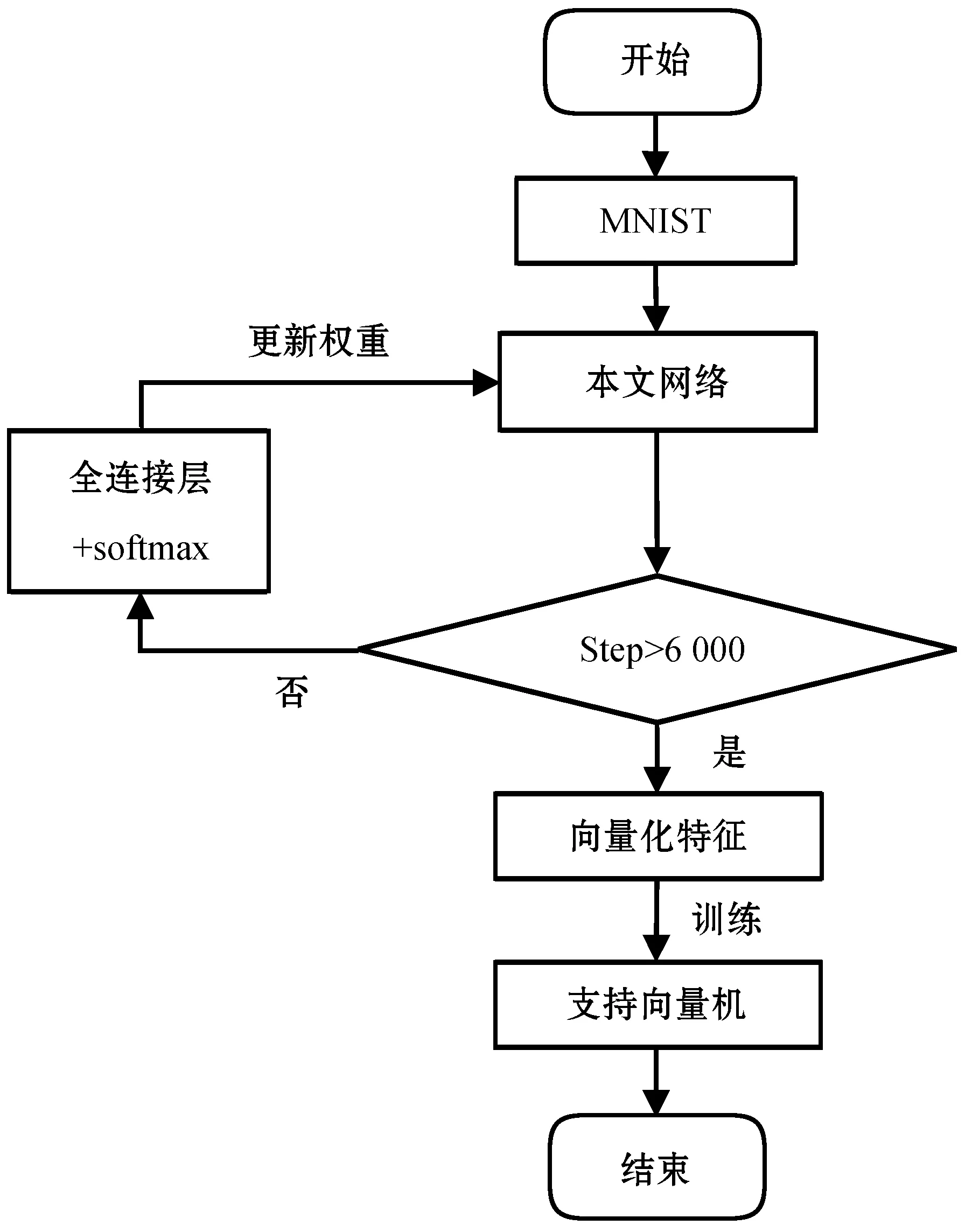
(a) 训练流程图
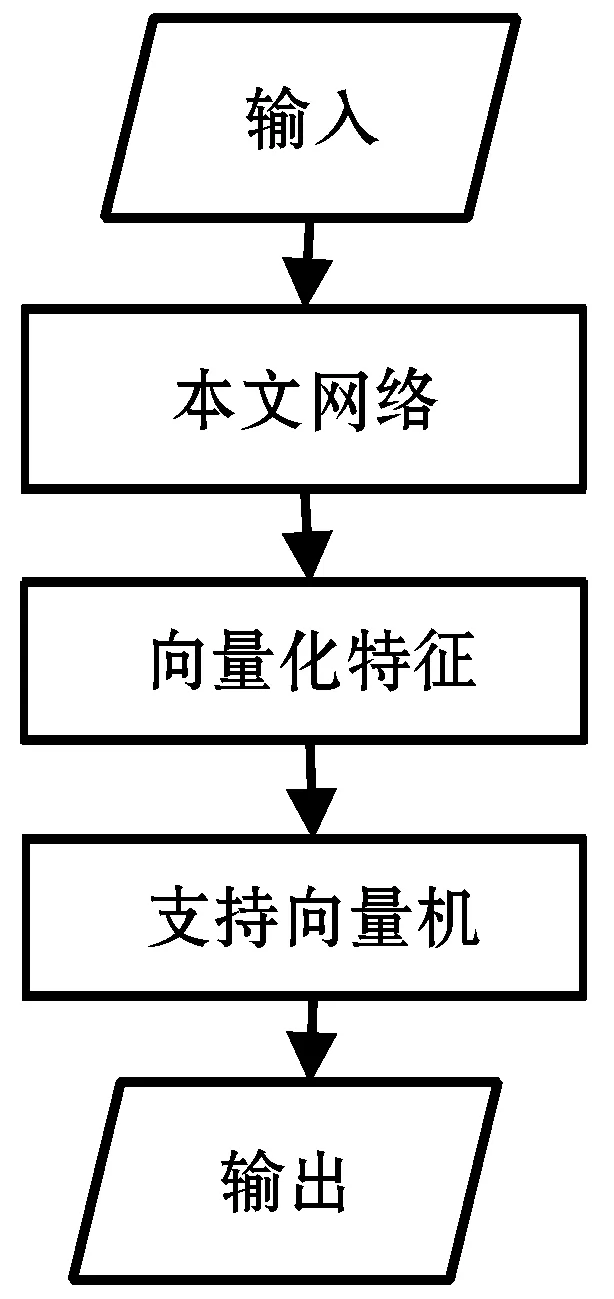
(b) 识别流程图图2 算法流程
图2(a)中训练过程分为本文网络训练与支持向量机训练两个部分。第一部分为MNIST数据集通过本文网络、全连接层与softmax,更新本文网络的权重;第二部分为MNIST数据集通过已训练的本文网络,将本文网络所提取的特征图向量化后所得特征训练支持向量机。训练完毕后,以图2(b)中所示顺序完成识别。
1.1 连续非对称卷积
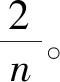
图1中连续非对称卷积×2结构如图3所示,其中Conv代表卷积(convolution),Convn表示使用n个卷积核。首先使用一组连续非对称卷积实3×3卷积,得到26×26×32输出特征图。第二组同样使用一组连续非对称卷积实现3×3卷积,得到24×24×64的输出特征图,这与直接使用5×5卷积所得特征图大小相同。

图3 两组非对称卷积实现5×5卷积
1.2 改进Inception结构
本文使用深度可分离卷积代替Inception结构中的传统卷积以增加网络宽度,同时提升网络性能。深度可分离卷积[10]是针对加大网络宽度提出的一种卷积形式,该卷积可以分解成一个深度卷积和一个1×1点卷积,深度卷积用于拓宽网络,点卷积用于调整输出通道数。
传统卷积可以表示为:
(1)
式中:F表示输入特征图,大小为k+i-1×i+j-1×m;G表示输出特征图,输出特征图的大小为k×l×n;K表示卷积核,大小为i×j×m,卷积核个数为n。可见,为得到k×l×n大小的输出特征图,传统卷积所需参数量为i×j×m×n。
深度可分离卷积可以表示为:
(2)
(3)
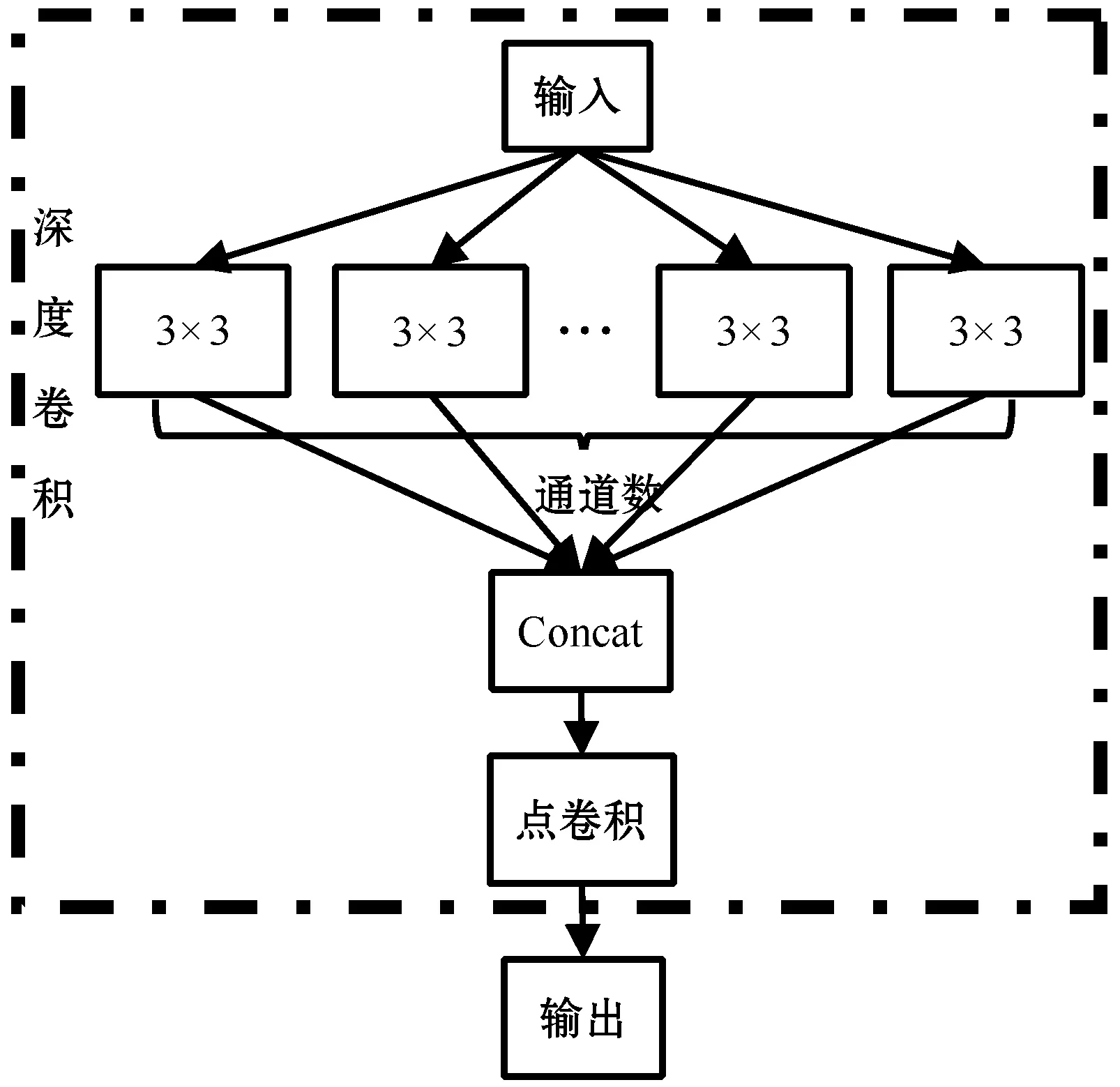
图4 深度可分离卷积结构
因此,对于同样大小输出特征图,深度可分离卷积所需参数量相比传统卷积所需参数量减少了大约n倍。
由于深度可分离卷积能够完全分离通道间的相关性,为进一步加宽网络,将深度可分离卷积引入到Inception里面。Inception结构与深度可分离卷积结构都能加大网络宽度,两者并联之后网络宽度能得到进一步增加。例如,输入特征图通道数为64,Inception间有3个分支,每个分支都使用不同卷积核进行可分离卷积,这样网络宽度就能从64增加到3×64。由于增加网络宽度会造成参数增加,因此引入点卷积,点卷积就是1×1卷积,它能很容易地整合卷积神经网络的通道,因此1×1卷积主要用来降低特征维度以避免因网络受硬件条件而限制网络模型。本文设计结构如图5所示。
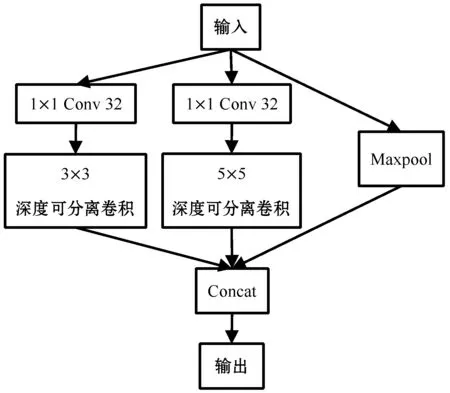
图5 改进后Inception结构
对该部分的输入分别接两个1×1卷积,卷积核个数均为32,得到两个分支,并通过整合输入特征图的通道数来降低参数。接下来分别对两个分支进行3×3与5×5深度可分离卷积,之后对两分支的输出沿通道数方向进行堆叠。
使用Python语言,tensorflow、slim库完成Inception结构改进,改进Inception结构代码如下:
def improved_inception_model(inputs,kernel,o_channels,depth):
‴inputs为改进inception结构的输入,kernel为每个分支中1×1卷积核的个数,o_channel每个分支中深度可分离卷积的输出通道数,depth为每个分支中深度可分离卷积的卷积核个数,函数返回三个分支输出的堆叠。其中stride均设为1,padding均设为′SAME′,即输入与输出同维度,以便堆叠。‴
batch0=silm.conv2d(inputs, kernel, [1, 1],
stride=1, padding=′SAME′)
batch0=slim.separeble_conv2d(batch0,
o_channels, [3, 3],
depth_multiplier=depth,
padding=′SAME′)
#对第一个分支进行1×1卷积后再进行3×3
#深度可分离卷积。
batch1=silm.conv2d(inputs, kernel, [1, 1],
stride=1, padding=′SAME′)
batch1=slim.separeble_conv2d(batch1,
o_channels, [5, 5],
depth_multiplier=depth,
padding=′SAME′)
#对第二个分支进行1×1卷积后再进行5×5
#深度可分离卷积。
batch2=slim.max_pool2d(inputs, [3, 3],
stride=1, padding=′SAME′)
#对第三个分支进行最大值池化
output = tf.concat([batch0, batch1, batch2], 3)
#将三个分支的输出在通道数上进行堆叠
return output
由表2可知,改进后结构在保留Inception结构对尺度适应性的同时减少参数量。

表2 参数量对比
1.3 残差网络结构
为防止网络深度增加导致梯度爆炸或者梯度弥散,造成梯度不能很好地往后传播,一般会在网络中引入残差网络,本文使用残差网络结构如图6所示。
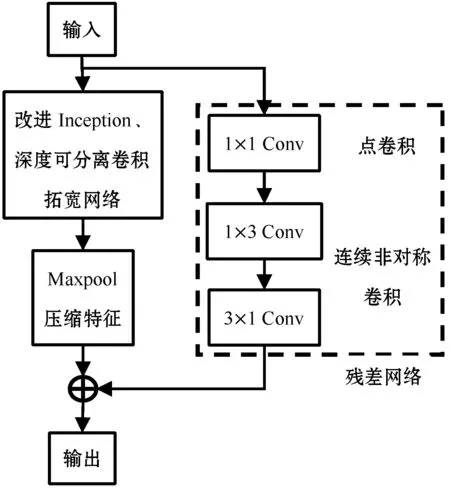
图6 残差网络
为保证Maxpool层的输出与3×1卷积层的输出维度相一致以实现线性相加,本文利用点卷积与连续非对称卷积对上一层输出特征图进行大小调整,见图6虚线框。所得输出结合卷积层与池化,对残差网络输出特征图进行缩小。
1.4 支持向量机
本文用支持向量机替代softmax作为最后的分类器。支持向量机是1963年Vapnik[15]提出的一种以统计学理论为基础的学习算法,利用核函数将低维向量映射到高维空间,并有效控制计算复杂度。通常使用高斯函数作为径向基函数:
(4)
式中:xc为核函数中心;σ为核函数宽度参数,控制函数的径向作用范围。
训练完本文设计的网络后,将全连接层与softmax层以支持向量机替代,在MNIST中随机选择10 000幅图片作为训练集,进行10折交叉验证,使用高斯核函数作为径向基函数。
2 实验结果与分析
为验证算法可行性,本文以来自美国国家标准与技术研究所MNIST手写体数字数据集作为实验数据。训练集包含60 000个样本,分别由250个来自不同地区的人手写的数字构成。测试集同样包含10 000个手写数字样本。其中训练集和测试集均为50%高中学生和50% 人口普查局的工作人员组成。图像均为28×28像素,本文所有实验均在配置为Intel Core i5-3470 CPU,主频3.20 GHz,16 GB的RAM上运行,使用3 GB显存的NVIDIA GTX1060做GPU加速。
实验分成两步:第一步先用softmax作为分类器,以交叉熵函数作为误差函数训练该网络,选择合适dropout概率防止网络过拟合;第二步固定所有网络层权重,使用支持向量机(SVM)替代softmax,训练SVM。
2.1 网络参数的选取
为防止过拟合,在模型训练时,本文在图1所示结构中采用Dropout层,保留概率与Dropout概率关系如下:
P=1-PD
(5)
式中:P为保留概率;PD为Dropout概率。
保留率设置为1.0、0.5、0.2、0.1,训练及测试loss曲线,所得结果如图7、表3所示。
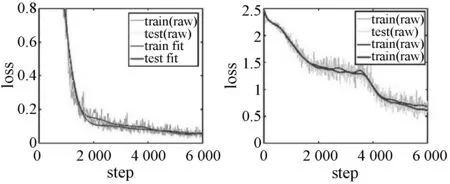
(c) P=0.2 (d) P=0.1图7 保留概率(P)对网络的影响

表3 不同保留概率的识别率
可以看出,当不使用Dropout层时(保留概率为1.0),loss下降至0.3后网络已经收敛,测试误差与训练误差之间相距较远,即两者方差较大,且测试误差在训练至2 200步后一直大于训练误差,说明网络已过拟合,识别率为89.95%;当保留概率为0.5时,loss下降明显,测试误差与训练误差之间相距较近,即两者方差较小,识别率为99.38%;当保留概率为0.2时,loss下降明显,同时测试误差始终高于训练误差,且在5 700步后基本重合,即方差最小,识别率为99.45%;当保留概率为0.1时,loss值大且下降较慢,说明此时网络欠拟合,识别率为78.34%。因此保留概率为0.2时,网络性能最优。
2.2 不同网络的比较
为便于比较,实验时分类器统一使用softmax作为分类器。经softmax分类后,正确率相对于LeNet-5提高了0.20%,相对于Inception结构提高了0.08%,实验结果如表4所示。

表4 不同网络结构实验结果
与Inception结构相比,本文改进结构较Inception具有更大的网络宽度,由图8可以看出,改进Inception收敛速度较快。
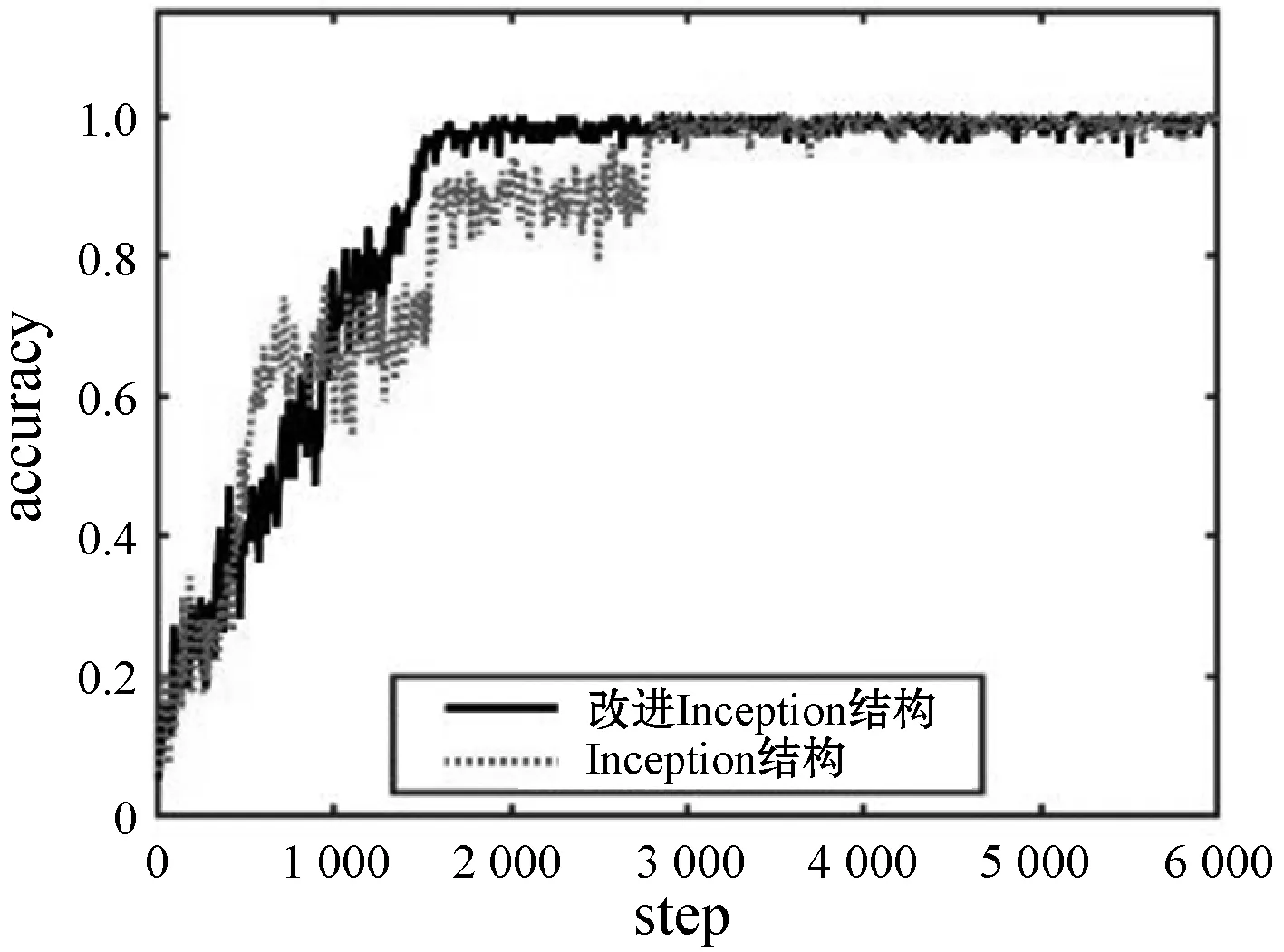
(a) accuracy曲线对比图
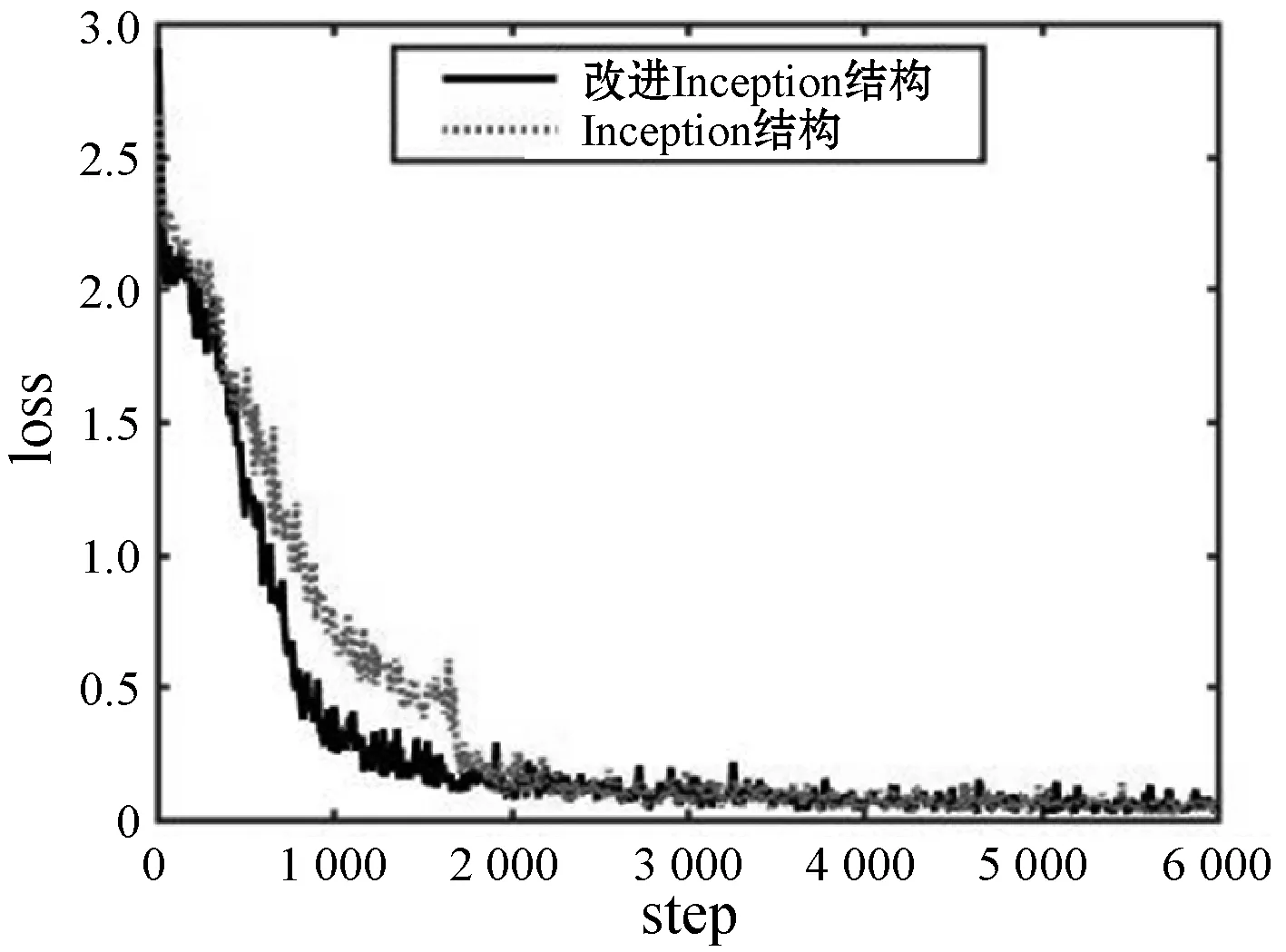
(b) loss曲线对比图图8 accuracy与loss曲线对比图
2.3 SVM参数的选取
为进一步提高识别率,选择SVM代替softmax,为选择合适的参数,从MNIST中随机取10 000个数据,对SVM的不同核宽与惩罚系数进行10折交叉验证,每次实验所得平均识别率如表5所示。
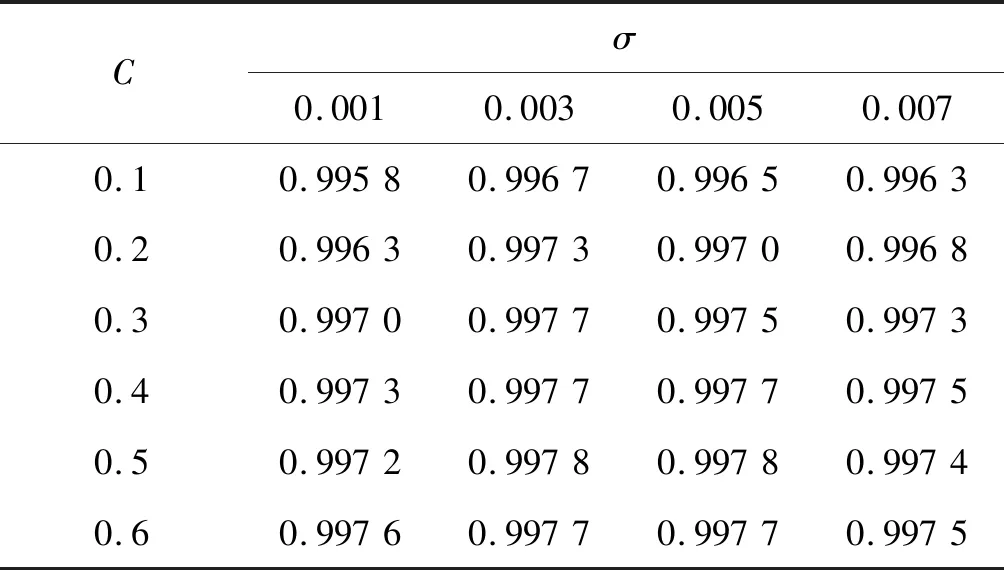
表5 核宽与惩罚系数对交叉验证平均正确率的影响
在表5所选参数条件下,10折交叉验证所得平均识别率均分布在99.58%~99.78%区间,均高于表4中softmax正确率。其中:C=0.5,σ=0.005时,平均识别率为99.78%;C=0.5,σ=0.007时,平均识别率为99.74%;C=0.1,σ=0.003时,平均识别率为99.67%。其10折交叉验证正确率曲线如图9所示。可见当惩罚系数C=0.5,σ=0.005时,10折交叉验证的每一次结果均高于其余两个,即为最优惩罚系数与核宽。

图9 10折交叉验证正确率
综上,本文网络结构在采用softmax分类器已经获得较高正确率,使用SVM分类器代替softmax分类器,可以将正确率从99.45%进一步提高到99.78%
3 结 语
本文采用改进Inception网络模型提取手写体数字的特征,并将其传递给SVM分类器进行识别。连续非对称卷积可以实现传统卷积功能同时节省计算开支,而改进Inception结构相比Inception结构拥有更大的网络宽度。实验结果表明,改进Inception结构相比Inception结构获得了更高的识别率。使用本文设计网络提取的特征作为特征向量训练SVM,识别率相比使用全连接层后经softmax分类所得识别率有明显地提升,说明SVM对于数据分类能力优于softmax分类器。在财务、税务、金融及实验记录等领域,存在大量的手写体数字文档。本文模型有望在上述领域的自动化识别中得到应用,以节省时间提升工作效率。
