藏语N-gram语言模型中的平滑技术研究
2019-12-11仁青吉
仁青吉
(甘肃民族师范学院 藏区非遗重点实验室,甘肃 合作 747000)
0 引言
语言模型在一个识别系统中占据着非常重要的地位,比如说在一个识别系统中,当出现一个同音字时,单凭声学模型已经不能正确的确定文本的内容,因为对于两个同音的字来说机器光凭声音是不能确定当前读的这个字是同音字当中的哪一个,所以声学模型描述和处理语音信号的能力有限,因此,光靠声学模型还不能达到理想的效果.我们还有许多非声学的模型,如句法、语义、语境等没有善加利用,这时语言模型就起到了关键性和决定性的作用,一个可靠的语言模型对识别系统的识别率及效率起着至关重要的作用.
1 建模平台的搭建和语言模型的生成
SRILM的主要目标是支持语言模型的估计和评测.估计是从训练数据中得到一个模型,包括最大似然估计及相应的平滑算法,而评测是从测试集中技术其困惑度.最基础和最核心的模块是n-gram模块,这也是最早实现的模块,包括两个工具:ngram-count和ngram.在训练语言模型的时候主要是用ngram-count来生成训练文本的技术文件count,然后再利用命令ngram生成训练文本的语言模型,在这个过程中可以添加不同的参数来测试不同的平滑算法,ngram-count被用来估计语言模型,ngram生成训练文本的语言模型.本次实验所用到的语言建模工具为SRILM,其运行于Linux操作系统环境下.
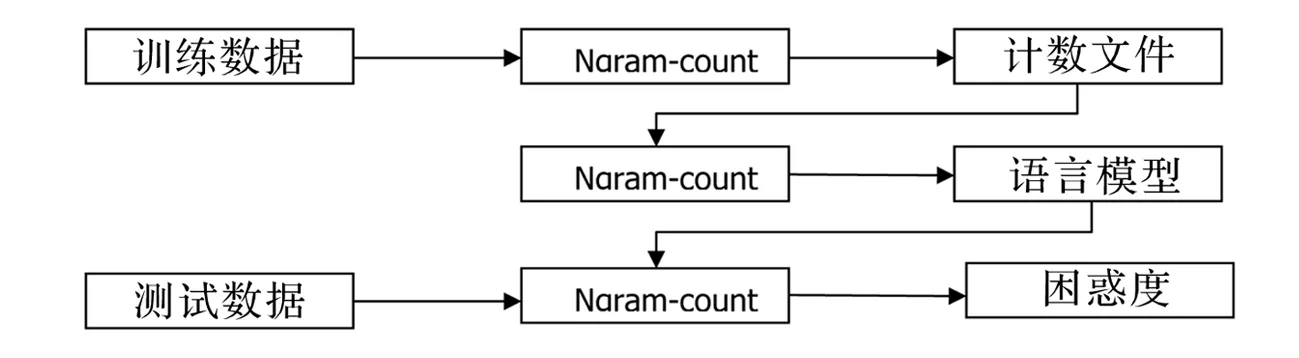
图1 语言模型生成过程
训练和评测语言模型的的流程,分为三个步骤:
1)由语料生成计数文件;
2)由计数文件训练语言模型;
3)利用已经训练好的语言模型来计算测试数据的困惑度.
基于统计的语言模型是从统计学的角度来统计某种语言单位(如词、字、音素等)的分布概率,在具体的实验中,是生产某种语言文本的统计模型,给定句子集合:

其中要统计每个单词在该句子集合中出现的概率时,我们应该用如下公式:
p(wi|wi-1) = count(wi-1,wi) / count(wi-1)
其中部分bigram的语言模型如下所示:

由于基于统计的语言模型的生成首先是通过统计语料文本当中的每一个已经分好的语言单位比如词、字等,所以我们开始要通过n-gram count来统计该文本当中的语言单位.
表1count实例

表2 count实例
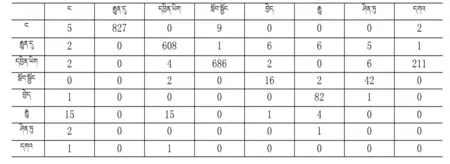
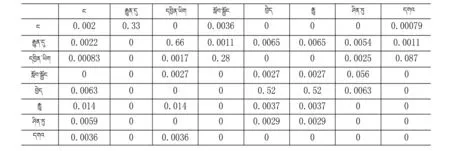
表3 语言模型实例
语言模型是用来计算一个句子概率的模型,如下公式所示:
p(S)=p(w1,w2,w3,w4,w5,…,wn)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
其中p(S)代表语言模型,那么,如何计算p(wi|w1,w2,...,wi-1)才是最简单、直接的方法呢?假设下一个词的出现依赖它前面的一个词,这样语言模型叫bigram则有:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w2)...p(wn|wn-1)
假设下一个词的出现依赖于它前面的两个词,这样的语言模型叫trigram则有:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|wn-1,wn-2)

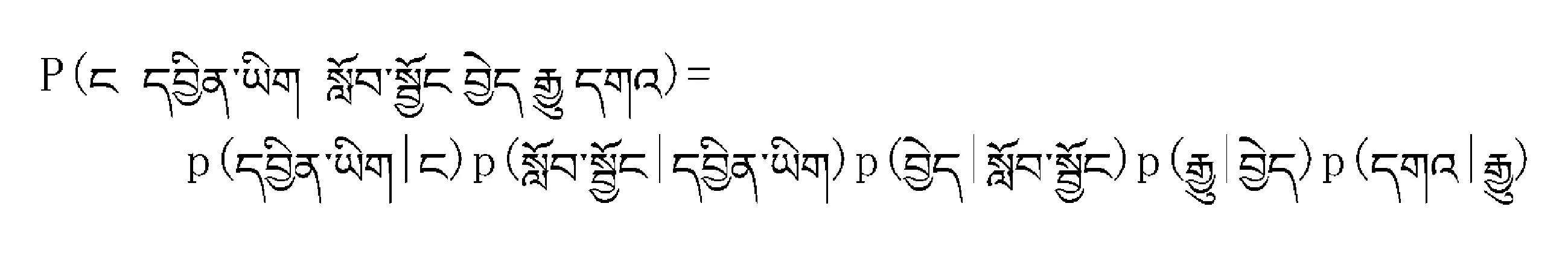
2 实验
在做平滑算法测试实验的过程中,为了使平滑算法测试实验的结果更直观且更有说服力,在做实验时不是把整个文本都拿到一起做平滑测试实验,而是将整个文本进行分块,对语料进行预先处理后要测试的文本的大小有20MB,依次将文本分成1∶4∶6∶8的比例,将这些分块好的文本分别标记为A、B、C、D,并将整个文件标记为E,然后进行算法测试.
实验步骤:
步骤一:
Ngram-count -text train.txt
-order 3
-write train.count
步骤二:
Ngram-count -read train.count
-order 3
-lm Good-Turing.lm
步骤三:
Ngram-count -read train.count
-order 3
-lm Good-Turing3-7.lm
-gt1min 3 -gt1max 7
-gt2min 3 -gt2max 7
-gt3min 3 -gt2max 7
以Good-Turing为例,利用命令ngram生成训练文本的语言模型,在这个过程中可以添加不同的参数来测试不同的平滑算法,相应的被用来估计语言模型和计算语言模型的困惑度.
实验一
实验数据描述:实验数据为藏语旅游风俗文化和一些日常的生活用语,训练数据A(1 MB),测试数据(260 KB),测试结果见表4.
表4对A的平滑测试

实验二
实验数据描述:实验数据为藏文新闻报刊类的文本,训练数据B(4MB),测试数据(255KB),测试结果见表5.
表5对B的平滑测试

实验三
实验数据描述:实验数据为藏文新闻报刊类的文本,训练数据C(6MB),测试数据(255KB),测试结果见表6.
表6对C的平滑测试

实验四
实验数据描述:实验数据为藏文新闻报刊类的文本,训练数据D(8MB),测试数据(255KB),测试结果见表7.
表7对D的平滑测试

实验五
实验数据描述:实验数据为藏文新闻报刊类的文本,训练数据E(20MB),测试数据(255KB),测试结果见表8.
表8对E的平滑测试


图2不同平滑算法对不同语言模型的困惑度比较
3 总结
从以上五个实验的五组实验数据中可以看出,分块的A、B、C、D、E这五个不同大小的文本来说,Modified Kneser-Ney方法表现最好,Absolute方法表现比Good-Turing3-7好,Witten-Bell表现比Good-Turing 要好,最差的是Good-Turing3-7.当数据量小时,Good-Turing方法和Witten-Bell相差不多,当数据量增大时,Witten-Bell方法就明显优于Good-Turing.但是,平滑方法性能的好与不好是由很多因素决定的,没有绝对的好与不好,应该依据现有的条件而定.困惑度是对模型选择下一个词的范围大小的度量,困惑度越小,识别器就越容易识别,困惑度越大,识别器的识别难度就越大.比如,对一个语音识别系统来说,困惑度就是表示识别器每次将会在多大的1个词集合中选择下一个词.
