基于神经网络的二进制文本特征提取*
2019-12-11衡威,范磊
衡 威,范 磊
(上海交通大学 网络空间安全学院,上海 200240)
0 引 言
文档特征可以用于文档的聚类、分类以及相似度分析等领域。已有的文档特征提取算法包括来源于自然语言处理领域的词袋模型、文档主题模型以及近年来常用的神经网络相关特征提取方法等。已有的特征提取方法首先需要完成对文本数据进行预处理,主要包括分词、停用词的过滤等。文档特征提取依赖于解析后的纯文本内容,因此在实际应用中需要对获取的各种格式文档做文本内容解析,以便获取其中包含的文本信息。
与此对应,文本数据在计算机中是以二进制形式存储的,不同的文档类型对信息的保存格式各不相同。如果直接以二进制形式对文档数据进行特征提取,可以免去对文档的恢复,具有对不同文件格式的普适性。本文提出了一种基于滑动窗口的二进制文档取词算法,可实现二进制文档的直接特征分析。
相较于传统的特征提取方法如词袋模型等,神经网络用来做特征提取所能处理的数据量更大,维度更高,效果也更好[1]。而二进制文本经过滑动窗口的取词后,会有数据量的激增和维度的爆炸。因此,本文提出了一种基于神经网络的二进制文件特征提取算法实现特征的降维。
本文模型先使用滑动窗口做取词处理,使用TFIDF生成每篇文章的关键词及其权重,选取权重值较高的部分生成词汇表;再使用Word2vec生成相应的词向量替换卷积神经网络(Convolutional Neural Network,CNN)中原本的One-hot编码,按照词汇表生成每篇文章对应的向量,并将降维后的特征向量输出。综合考虑二进制文本数据的本身的特点,使用THUCNews的一个子集并将其转化成二进制的格式后作为实验数据,使用模型生成特征并用其做分类训练验证效果。
1 研究背景
本文的特征提取主要针对二进制文本进行,希望能提取出该序列的主要成分即特征。特征提取本身是一个降维的过程,其中一组原始变量被简化为更易于管理的组(特征)进行处理,同时仍然准确、完整地描述原始数据集[2]。在已有的特征提取研究中,最接近的是自然语言处理技术(Natural Language Processing,NLP)中所用到的特征提取,因为同样是对一个序列进行特征提取。
1.1 传统自然语言处理文本特征提取模型
1.1.1 One-hot编码相关特征提取
以英文为例,一个文本可以简单被理解为词语的线形序列。一个one-hot编码的文本是一个多维向量,向量的维度是所有出现过的词语,而每一个维度的值为0或者1。0表示该词在该本文中没有出现,1则相反[3]。
1.1.2 词袋模型
词袋模型是抽象文档或句子的稀疏矩阵编码。它本身在各种文章理解中都作为高效的处理方法而存在。基于上述的one-hot编码,每一个文档D可以被简化为N×M矩阵。其中N为此文档的词语数量,M为语料库的词汇总数。对于这个文档,有:

词袋抽象模型:

可以看到,词袋模型直接完成了词汇的相加而去除了词汇顺序的信息。一个人在理解句子意思时,如果句子的词语顺序被打乱,通常情况下人并不会产生理解障碍[4]。
1.2 基于神经网络的特征提取方法
现今深度学习蓬勃发展,特别是在计算机视觉领域,许多前沿的研究已经能利用神经网络提取图片的各种特征。针对自然语言处理问题,学界也研发了许多相应的深度学习网络来提取其特征[5]。
1.2.1 RNN文本特征提取
传统的全连接网络是由一个输入层向量、一个输出层向量和多个隐藏层向量线性排布组成的神经网络,在处理定维特征问题可以起到一定的效果。而循环神经网络(Recurrent Neural Network,RNN)在全连接网络的基础上,在部分隐藏层加入回环,而一个隐藏层的输出会被保留作为下一次处理的输入。这种设计起到了信息保留的作用。自然语言文本作为以词汇为单位的序列时非常适合RNN处理,且其意味着考虑了语序[6]。
1.2.2 LSTM文本特征提取
长短期记忆神经网络(Long Short-Term Memory,LSTM)是一种RNN的变体。由于传统的RNN只有1单位的延时单元,词语的相关性并没有被很好记忆[7]。一旦一个重要信息是跨段落的关联性存在时,随着梯度扩散传播,远处的词汇影响力会持续减小。LSTM在RNN的基础上将RNN中的节点替换成一种专用的单元,以更具有选择性地记忆信息,提升处理效果。LSTM的核心概念是单元(Cell)状态和各种门[8]。
1.2.3 Word2vec
Word2vec是由Google提出的一个词汇向量化方案。相比one-hot编码,Word2vec可以借助语料库信息,将词汇从高维的稀疏矩阵转化成低维的稠密矩阵[9]。
Word2vec目前主要有CBOW和skip-gram两种训练方式。如图1所示的两种模型,CBOW模型以一个中心词对应的上下文的单词作为输入,以该中心词作为输出进行训练,相当于预测在给定的上下文情况下最有可能出现的单词为哪个[10];而skipgram训练词向量主要通过以一个单词作为输入,然后预测它的上下文单词来实现。这种方法可以使用生成的向量快速比较词距,也可以在这个词汇集范围内量化相同词根的不同形式之间的关系。

图1 CBOW模型和skip-gram 模型
1.2.4 Text-CNN
CNN最初用于处理图像问题,但是在自然语言处理中,使用CNN进行文本分类也可以取得良好效果。文本中,每个词都可以用一个行向量表示,一句话可以用一个矩阵来表示,那么处理文本就与处理图像类似。该模型由Kim在2013年提出[11],通过验证实验和业界的共识,在文本分类任务中此模型已经能够取到较好的结果。虽然在某些数据集上效果可能会比RNN稍差,但是CNN模型训练的效率更高。所以,一般认为CNN模型在文本分类任务中是兼具效率与质量的理想模型。Text-CNN模型的整体网络架构由输入层、卷积层、池化层和全连接层4部分构成。
2 方案设计
模型流程如图2所示。获取二进制文本数据后,使用合适大小及步长的滑动窗口对每个二进制文档做取词处理;取词后内容剧增,使用TFIDF生成每篇文章的关键词及其权重,选取权重值较高的前8 000个生成词汇表;再使用Word2vec生成相应的词向量替换CNN中原本的One-hot编码,按照词汇表生成每篇文章对应的向量,之后使用CNN对生成的向量做降维处理,并将其作为最后的特征进行输出,最后使用机器学习的分类算法进行特征好坏的验证。

图2 方案流程
2.1 滑动窗口取词
滑动窗口取词算法是本文的主要创新点之一,目前以及传统的取词算法都是基于特定的语料库。而对文本二进制化后,已经是对文本内容的一种模糊化处理,这种情况下没有合适的语料库来做取词处理。但是,在UTF-8的编码中,中文文本中的一个汉字基本上用3 Bytes表示,像“体育”对应的二进制编码为“xe4xbdx93xe8x82xb2”。因此,考虑到中文词汇大小和尽可能保持语义的问题,最终取词算法采用加窗方式对二进制文本进行取词处理。使用一个固定长度的“窗口”,在二进制形式下遍历文章,从头到尾滑动,窗口内的内容为所要提取的一个词汇,每次移动指定大小的步长,滑动后到达新的位置,此时窗口内的内容为下一个要取的词汇。当遍历完整篇文章后,完成对该文章的取词工作,从而生成该文章比较有代表性的二进制词汇内容。
例如,对于一段序列0x4fff20da002f,取窗长window size为4,步长step为2,那么词汇会被切割为 0x4fff、0xff20、0x20da、0xda00和 0x002f。窗长不宜过长,最终采用的窗口大小是6 Bytes,因为在UTF-8编码中一个汉字是3 Bytes,6 Bytes相当于一个词语,步长是1 Bytes,对于效率与结果都比较均衡,如图3所示。

图3 二进制文件取词示意
但是,由于步长大小的限制和窗长的设定,最终的取词结果会产生一定程度上的冗余而导致空间爆发,如原本1 MB的文件经过取词以后可能会变成14 MB。但在后续词汇表的构建中可通过词频的统计和筛选来减少词汇的冗余。
2.2 TFIDF生成词汇表
由于上文的取词处理使得每篇文档的大小及内容都成倍扩增,通过观察取词后的数据,发现一些词重复出现且并没有实际意义,如表示空格的x00。因此先使用TFIDF对所有的文本进行初步训练,生成每一篇文章的关键词及其对应的权重。
TFIDF是一种常见的文档特征提取算法,基本原理是在一个文档库中降低泛用词的权重而提高专有词权重。词频表示特定词语出现在文中的频率。为了使不同长度的文章比重差不多,需要对该文章的词数做归一化处理。对于某一特定文件的词语,它的重要性可以表示为:

式中的ni,j指这个词在文件dj中出现的次数,而下面的分母表示所有词汇在文件中出现的总次数。
逆向文件频率(Inverse Document Frequency)是一个词语在整个语料库中重要程度的表示。某一特定词语的idf可以表示为:

其中|D|指语料库中文件的总个数,|{ j:ti∈dj}|指包含词语的文件数目。如果该词语不在语料库中,导致分母为0。因此,一般情况下使用1+|{ j:ti∈dj}|。然后,有:

某一特定文章内的高频词汇以及在整个语料库出现较少的词汇,可以产生高权重的TFIDF。因此,常见词语的TFIDF一般较低,而重要的词语会相对较高。
训练完成后,将所有的关键词按权重从大到小进行排序,选取前8 000个作为词汇表,之后使用词汇表中每个词汇对应的ID与每篇文章中的词汇替换,初步生成该文章对应的向量。同时去除无意义的、非关键性的词汇做初步降维。这是本文的一个创新点。
2.3 Word2vec
Word2vec主要用来训练数据集生成其对应的词向量来嵌入到后续步骤CNN模型中的词嵌入层来替代原本的One-hot编码。其采用3层的神经网络,如图4所示,包含输入层、隐层和输出层。核心技术是根据词语出现的频率用Huffman编码,使得所有词频相似的词在隐藏层激活的内容基本一致。出现频率越高的词语,激活的隐藏层数目越少,有效降低了计算的复杂度[12]。

图4 Word2vec结构
流程如下:
(1)分词-滑动窗口完成取词;
(2)构造词典,统计词频。这一步需要遍历所有文本,找出所有出现过的词,并统计各词的出现频率。
(3)构造树形结构。依照出现概率构造Huffman树。
(4)生成节点所在的二进制码。
(5)初始化各非叶节点的中间向量和叶节点的词向量。树中的各个节点都存储着一个长为m的向量,但叶节点和非叶结点中的向量含义不同。叶节点中存储的是各词的词向量,作为神经网络的输入;而非叶结点中存储的是中间向量,对应于神经网络中隐含层的参数,与输入共同决定分类结果。
(6)训练中间向量和词向量。
2.4 Text-CNN
Word2vec模型对取词好的文档进行词向量化后,将相应的词向量数据嵌入CNN模型的词嵌入层。该模型主要由输入层、卷积层、池化层和全连接层4部分构成,其中输入层又叫词嵌入层。该模型的输入层需要输入一个定长的文本序列,通过分析语料集样本的长度指定一个输入序列的长度L。比L短的样本序列需要填充,比L长的序列需要截取[13]。最终,输入层输入的是文本序列中各个词汇对应的词向量。
卷积层输入的是一个表示句子的矩阵,维度为n×d,即每句话共有n个词,每个词由一个d维的词向量表示。假设Xi:j+i表示Xi到Xi+j个词,使用一个宽度为d、高度为h的卷积核W与Xi:i+h-1(h个词)进行卷积操作,再使用激活函数激活得到相应的特征ci,则卷积操作可以表示为:

经过卷积操作后,可以得到一个n-h+1维的向量c形如:

在Text-CNN模型的池化层中使用最大值池化(Max-pool),即减少了模型参数,又保证了在不定长卷基层的输出上获得一个定长的全连接层的输入。卷积层与池化层在分类模型的核心作用是特征提取,从输入的定长文本序列中,利用局部词序信息提取初级特征,并组合初级的特征为高级特征,通过卷积与池化操作省去了传统机器学习中的特征工程步骤。本文主要使用该模型做特征的降维。
3 实验结果与分析
3.1 实验数据处理
为使实验过程及结果更具说服力,使用THUCNews的一个子集作为实验数据集。而THUCNews根据新浪新闻RSS订阅频道2005—2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式,选取其中的部分数据进行实验。文本类别涉及10个类别,即categories=[‘体育’,’财经’,’房产’,’家居’,’教育’,’科技’,’时尚’,’时政’,’游戏’,’娱乐’],每个分类6 500条数据。训练集每个种类有5 000条数据,验证集每个种类有500条数据,测试集每个种类1 000条数据。为使其更符合实验场景,将原来的纯文本数据分别转存为二进制Word文档。
而文档作为一种二进制文件,是数字编码的线形表示。如果相同类型文件具有结构共性,那么这两个文件的二进制编码中一定存在相似的部分。原则上,只要提取出共性部分,剩下的部分就是文档独特的内容。因此,首先对获取的二进制文档数据集使用滑动窗口做取词处理,结果如表1所示。

表1 文档取词结果示例
处理完后,使用Word2vec对取词后的文档进行词向量化处理,再将其嵌入CNN中替代原本one-hot编码模式。
在这之前需要先构建词汇表,遍历所有的文档,使用TFIDF统计每篇文档中的关键词及其权重,汇总后选取权重值较高的前8 000个作为词汇表。经过滑动窗口的取词处理,最终统计所有不重复的词汇有近100万个,实验数据有50 000篇,每篇文章中的词汇少则有几千个,多则上万,而权重值靠前且数值较大的,每篇文章中平均有几十个。考虑到同种类文章的重复性,选取8 000的维度能够实现对每种类型的文章94.5%的高平均覆盖率,其中部分二进制词语的中文对应如表2所示。

表2 二进制词汇中文对照
生成该词汇表后,首先使用Word2vec生成词向量。在这种方法中,生成每一个二进制文档的词向量前,首先遍历该文档中包含的二进制词汇,看其是否在词汇表中。如果不在,直接跳过,在词汇表中则将其汇总后使用Word2vec训练,生成该文档对应的词向量表达形式。本文中使用的是Word2vec中的CBOW算法,即预测在给定的上下文的情况下,最有可能出现的单词为哪个[14]。特征向量的维度是100,window(表示当前词与预测词在一个句子中的最大距离是多少)大小为5,min_count参数设定为1,workers(控制训练的并行数)设定为6,结果如表3所示。

表3 Word2vec词向量化结果示例
完成这一步骤后,将每篇文档对应的词向量文档转化成numpy格式文件保存,在后续使用中将其嵌入CNN的嵌入层作为模型的词向量使用。之后使用该词汇表生成和表内词汇对应的词典,即原词汇表中的二进制词汇作为键,值为从上往下遍历词汇表每个二进制词汇相应的ID顺序。完成这一步骤后,遍历每个二进制词汇文档,若所取二进制词汇不是则该位置记为0,若是则将其存储替换为该键对应的ID值,最后生成整篇文章的ID数值表达形式。完成后,使用keras提供的pad_sequences将文本pad设定为固定长度,这里选取max_length为60。文章向量化后,作为输入送入CNN中做进一步处理。
CNN模型使用的是经典的单层Text-CNN模型,由Word2vec生成数据集的词向量,嵌入到CNN模型中的embedding层,替换原本的One-hot编码。其他参数包括词汇表的大小设定为8 000、卷积核的尺寸设置为5、卷积核的数目为128。同时,将该词嵌入层的维度设置为与Word2vec训练的词向量相同的维度100,并预留好后续输入数据的占位符input_x。该占位符的参数序列维度需要设置为60。但是,由于只是对于二进制文本的特征提取,并不涉及原本CNN实质性的分类的相关内容,因此其他部分的输入如类别等内容不做专门处理,之后在池化层后输出降维后的每篇文章的特征向量。最终,每篇文章以一个256维的向量来表示,如表4所示。
表4 二进制文本特征向量
3.2 特征向量效果验证
上文中,提取到了每个文本各的特征向量,然后使用如余弦距离的计算等方法比较文章之间的相似度,计算相同种类文本特征向量之间和不同种类文本特征向量之间的余弦距离,初步证明该方法进行特征提取效果的好坏。再用机器学习的分类方法支持向量机(Support Vector Machine,SVM),用数据集中的训练集训练分类模型,测试集检验分类效果。余弦距离计算结果如表5所示。可以看出,不同种类文档间和相同种类文档间的距离有明显差异,同种类文档之间距离更近。

表5 各类文档间余弦距离
之后对于输出的特征向量使用SVM分类模型进行分类训练和验证,最终测试分类准确率达到92.8%,各种类别实验结果如表6所示。
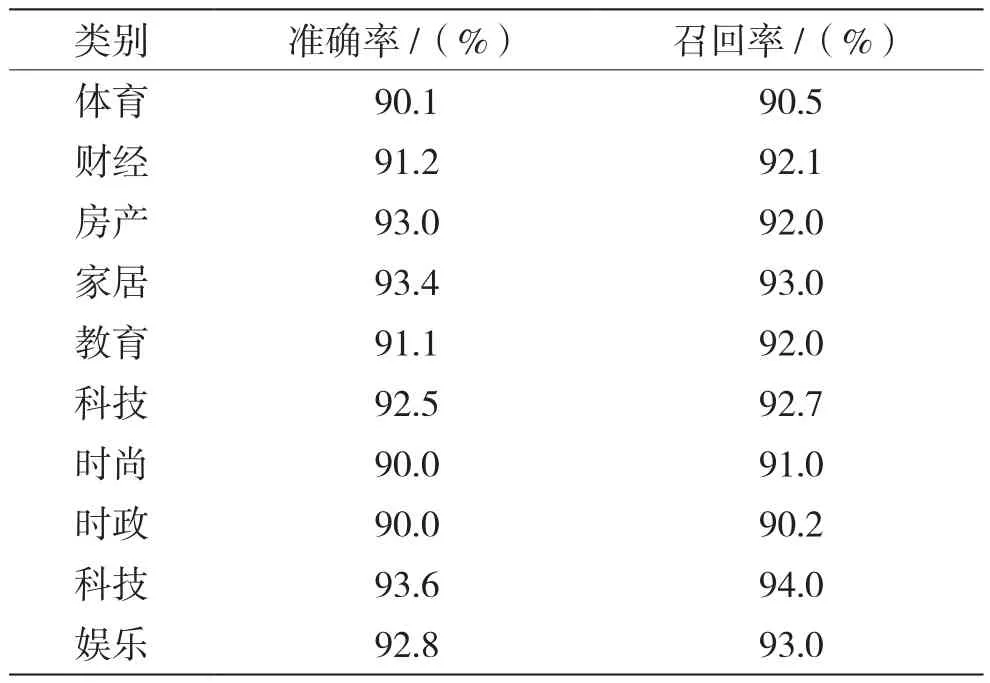
表6 各类别分类结果
从实验结果可以看出,准确率相较于同领域内其他模型稍有欠缺,但在数据预处理上大大简化了操作的复杂程度,省去了其他文本分类方法中复杂的文本恢复、选取合适的语料库进行取词处理等过程,有效的提高了工作效率。
4 结 语
传统的文件分析方法是基于文件格式本身的,但是由于系统并不能确定文件格式,期望一种基于文件二进制的特征提取算法,不管任何文件都能提取它的二进制特征。于是,提出了基于神经网络的针对二进制文本特征的提取模型,经由滑动窗口的取词、TFIDF训练生成词汇表、Word2vec的词向量化以及CNN的降维处理,最终输出所需要的每个二进制文本相对应的特征向量。最后通过余弦距离的比较和SVM分类结果的验证,表明该模型的有效性和高效性。下一步将针对该模型进一步进行优化,从而提高该模型的精度和普适性。
