航拍场景下的车辆生成
2019-12-11陶晓力刘宁钟
陶晓力,刘宁钟
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
0 引 言
随着无人机飞控技术的快速发展以及摄像云台的成熟,民用无人机航拍的应用领域逐渐扩大。尤其是政府对于智能交通的逐渐重视,无人机在交通事故检测、道路勘探等方面起着越来越重要的作用[1]。这其中,航拍车辆检测作为智能交通领域的核心,更是研究的重点。
目前,基于卷积神经网络(CNN)的目标检测虽然已经在多个数据集上取得了不错的结果[2-5],但在航拍小目标检测中,由于真实场景的多变性,需要大量的人力物力和精力来收集多场景下的图片并进行标注。同时,有限的训练数据很难让检测器达到一个较好的性能。因此,文中基于生成对抗网络提出了一种真实场景下的航拍车辆生成方法。
1 相关工作
不同于判别模型学习样本的条件概率分布,生成模型通过从训练集和标签中学习联合概率分布,并产生与训练集同样分布的图像。传统机器学习的生成模型很难拟合真实的样本分布,而随着深度学习的发展,Goodfellow等提出的生成对抗网络[6](generative adversarial nets,GAN)已经在图像合成领域获得了很多的成功应用[7]。
文献[8]提出了一种DCGAN模型,将CNN与GAN结合,使用卷积网络代替了GAN中的全连接网络,利用卷积网络强大的特征提取能力来提高生成网络的学习效果。文献[9]提出了一种图像风格迁移模型(pix2pixGAN),通过图像对的方式进行一对一的监督训练,能够将准备好的原始图像转换成所希望的风格。
但是要想使得GAN生成的目标图像能够辅助检测器的训练,还面临两大挑战:一是GAN能生成足够真实的目标图像;二是如何使得生成的目标图像融合到周围的场景中[10-12]。
2 模型和方法
生成对抗网络是由一个生成网络和一个判别网络进行竞争博弈的过程。不同于传统的GAN,文中的GAN模型采用了一个生成网络G和两个判别网络Dc和Db。
其中,生成器G将带有噪声块的图像变成航拍车辆图像,Dc用来判别车辆的真假,Dc用来判断背景的真假。通过生成器以及两个判别器的对抗学习,最终生成足够真实的航拍车辆图像。
文中提出的基于生成对抗网络的航拍车辆生成方法,与PS-GAN一样,在pix2pix的基础上,通过增加判别器以及对于不同目标任务采用不同的损失函数,以达到对生成器G的约束。网络结构如图1所示。
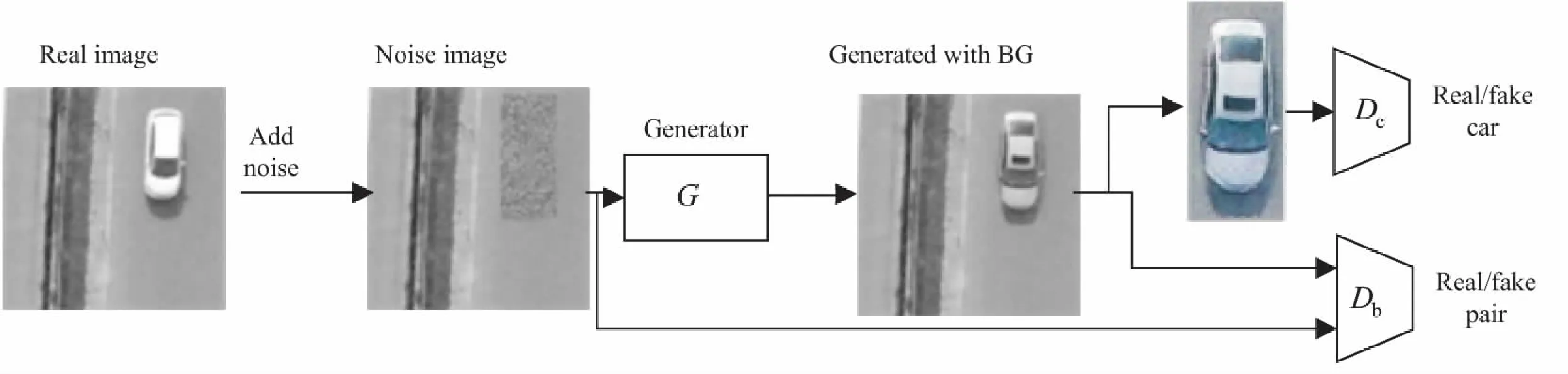
图1 多判别器约束的pix2pixGAN
2.1 生成模型
生成器G的目标是学习一种x到y的映射,使得G(x)=y。其中x是输入的噪声图像,y是目标图像。文中的生成网络G采用U-Net[13]作为网络结构,遵循编码解码结构。编码解码结构将输入图像x通过卷积层(如下采样层)来减少信息量,然后将编码得到的信息输入到解码器中通过上采样的方式进行解码,完成图像到图像之间的转换,如图2所示。但是传统的编码解码器会在数据编码的过程中出现信息丢失的情况,使得映射不稳定。U-Net生成器结构在编码解码过程中使用跳步连接将下采样和上采样的镜像层连接,复制编码层的特征图给对应的解码层,保留了更多的原图信息,解决了信息传递丢失的问题。U-Net结构如图2所示。

图2 编码解码器和U-Net
2.2 判别模型
对于车辆判别模型Dc来说,关注点在于噪声区域。根据车辆的位置标注信息,将生成图像G(x)中相应位置的生成车辆G(z)裁剪出来作为负样本。同样的,从原始图像y中将对应的真实车辆yc裁剪出来作为正样本。判别器Dc的作用是判别输入的车辆G(z)或yc是真还是假。这将迫使生成器G学习到一种将噪声z转换到真实车辆yc的映射,G(z)→yc,其中z是位于噪声图像x中的噪声区域。
判别器Dc的结构如图3所示。使用5层卷积网络进行特征提取。由于Dc的输入是从生成图像或者是原始图像中裁剪出来的不同大小的车辆,因此通过卷积网络得到的特征图大小也不一样。为解决这个问题,使用空间金字塔池化层[14](spatial pyramid pooling,SPP)来得到固定长度的池化特征。这里,使用3层空间金字塔(1*1,2*2,4*4),最终会得到21个特征点,然后进行损失函数的计算。

图3 双判别器网络
对于背景判别模型Db来说,关注点在于全局信息。目标不仅是生成逼真的车辆,更重要的是确保生产车辆能融入到背景中去。像pix2pix中的图像对一样,Db用来判别真实的图像对以及生成的图像对。真实图像对由原始图像y和噪声图像x组成,生产图像对由生成图像G(x)和噪声图像x组成。
2.3 目标函数
如图1所示,该网络主要由一个生成网络和两个对抗网络组成。
对于Db来说,使用最小二乘损失函数[15]来进行训练:
Llsgan(Db,G)=E[(Db(y)-1)2]+
E[(Db(G(x)))2]
(1)
对于Dc来说,使用交叉熵损失函数进行训练:
Lgan(Dc,G)=E[logDc(yc)]+
E[log(1-Dc(G(z)))]
(2)
对于G来说,为了使得生成的图片更逼近于真实图像,在训练过程中增加一个L1正则化约束,具体如下:
Ll1(G)=E(‖y-G(x)‖1)
(3)
所以,生成器G的最终的损失函数形式为:
L(G,Db,Dc)=Llsgan(Db,G)+
Lgan(Dc,G)+λLl1(G)
(4)
其中,y表示原始图像,x表示噪声图像,yc表示原始图像中的真实车辆,z表示噪声图像中的噪声区域,G(x)表示生成图像,G(z)表示生成图像中的生成车辆,λ控制着生成器的L1损失的权重
3 实验结果与分析

在装备的数据集上使用多个模型分别训练了200代,在测试集上的部分结果如图5所示。其中(a)是原图,(b)是噪声图像,(c)是pix2pixGAN得到的图像,(d)是两个判别器Db和Dc都使用最小二乘损失函数得到的模型,(e)是文中方法得到的图像,Db使用最小二乘损失函数,Dc使用交叉熵损失。
通过比较可以发现,pix2pixGAN只能勉强生成车辆的部分形状,内容十分模糊,而(d)中的车辆已经有了较好的外形,效果最好的是文中方法。对于(e)和(d)两种模型得到的结果,可以推测是因为最小二乘损失函数相对于交叉熵损失能够获得更大的损失值,使得Dc在训练集上产生了过拟合,因此生成器G在测试集上面对新的背景以及噪声时,没能产生较高质量的航拍车辆。
图6是在真实航拍图像中生存车辆的结果,左图是原始的航拍图像,右图是生成图像。通过观察对比可以发现,原始图像中的车辆比较少,通过车辆生成方法,在其中的多处空白背景处生成了车辆,相比于真实车辆,生成车辆也比较真实。

图4 车辆生成数据准备

图5 不同方法生成车辆对比

图6 完整航拍图像中的车辆生成
4 结束语
为了解决航拍车辆检测模型训练需要大量标注样本的问题,提出了一种基于生成对抗网络在真实航拍图像中生成车辆的方法。在基于pix2pixGAN的方法上,使用两个判别器分别约束背景的拟合和车辆生成,通过多条件约束将噪声区域转化为航拍车辆。通过实验分析对比不同的方法,结果表明该生成方法具有较好的生成结果。
