深度学习技术及其在舰船目标识别领域的应用
2019-12-11邵利民徐冠雷
马 啸,邵利民,金 鑫,徐冠雷
(海军大连舰艇学院 航海系,辽宁 大连 116018)
0 引 言
对海上舰船目标进行有效识别和监控对维护海洋权益、保障海上航行安全具有重要的现实意义。随着信息探测技术的发展,获取到的舰船目标信息越来越多,传统通过人工判读识别舰船目标的方法资源消耗大且难以保证目标识别的精度和可靠性,迫切需要引入新的技术和方法以节省人力资源,提高舰船目标识别的精度和可靠性。
深度学习作为机器学习领域的新分支,在2006年由Geoffrey E. Hinton等首次提出并迅速发展起来[1]。它通过模仿人脑的学习机制来解释数据,如图像、文本、声音等,其本质上是一种特征学习方法,能够通过自主学习从大数据样本中剔除冗余信息,提取出更具表征能力和区分能力的目标特征,在文字识别、语音识别、图像识别及视频处理等领域得到了广泛应用[2]。将深度学习技术引入到舰船目标识别领域,为实现舰船目标识别技术的突破提供了一种新思路。
1 深度学习模型的发展
从2006年发展至今,深度学习的模型结构不断发展,与传统的机器学习方法,如支持向量机算法、聚类算法、Boosting算法等相比,深度学习模型的中间隐层数更多,结构更深,有的模型甚至达到上千层,通过多隐层的分级变换,将底层特征转换到不同的特征空间,逐步抽象为高层特征,形成一个多层传递、逐步抽象、迭代细化的过程[2-4]。目前深度学习模型中具有代表性的主要有基于受限玻尔兹曼机(restricted Boltzmann machines,RBM)的深度模型、基于循环神经网络(recurrent neural networks,RNN)的深度模型和基于卷积神经网络(convolutional neural networks,CNN)的深度模型。
基于RBM的深度模型是深度学习发展初期提出的一种模型结构,包括深度置信网络和深度玻尔兹曼机。RBM作为这种模型结构的基本组成单元是一种典型的双层网络结构,其可视层单元和隐层单元相互连接,但层内没有连接[5-7]。
循环神经网络是一类用于处理序列数据的神经网络,基于RNN的深度模型多用于机器翻译、语音识别等领域。
传统的神经网络模型中,从输入层到隐含层再到输出层,层与层之间是全连接的,层内节点之间无连接,这种结构无法对序列数据进行预测。循环神经网络RNN模型中,隐含层的输入不仅包括输入层的输出,还包括上一时刻隐含层的输出,且隐含层之间的节点是有连接的。这种结构使得RNN理论上能够处理任意长度的序列数据,实际应用中,一般假设当前状态只与前面几个状态相关以降低结构复杂性。
目前基于RNN的深度模型有SRN、BRNN、DRNN、ESN、LSTM、GRU、CW-RNN等。
简单循环神经网络(simple recurrent neural networks,SRN)是RNN结构的特例,它是一种三层网络,在隐含层增加了上下文单元,上下文每一个节点保存与之相连的隐含层节点上一时刻的输出,作用于当前时刻隐含层的状态,即隐含层的输入由输入层的输出和上一时刻自身状态决定,使得SRN能够实现对序列数据的预测[8]。
双向循环网络(bidirectional recurrent neural networks,BRNN)是由两个RNN上下叠加组成的,BRNN模型假设当前输出与前后序列均相关,输出由两个RNN隐含层的状态决定[9]。
深度循环神经网络(deep recurrent neural networks,DRNN)与BRNN相似,但模型包含层数更多,复杂性更高,具有更强大的表达与学习能力,需要的训练数据也更多[10]。
回声状态网络(echo state networks,ESN)使用大规模随机连接的RNN取代经典神经网络的中间层,从而简化网络的训练过程[11]。
长短时记忆模型(long short-term memory,LSTM)使用不同的函数计算RNN隐含层的状态,能够更好地对长短时依赖进行表达,在机器翻译、语言建模、多语言处理等方面应用广泛[12-13]。
门循环控制单元(gated recurrent unit,GRU)是LSTM的变体,GRU模型中将前面时刻状态对当前状态的影响进行了距离加权,距离越远权值越小。GRU既保持了LSTM的效果,又简化了模型结构[14]。
时钟循环神经网络(clockwork recurrent neural networks,CW-RNN)是一种使用时钟频率来驱动的RNN。它将隐含层分为几组,每一组按照自己规定的时钟频率对输入进行处理。不同的隐含层模块在不同的时钟频率下工作,从而解决了长时间依赖问题[15]。
CNN是一种适用于处理网格化数据(如图像)的前馈式人工神经网络,具有自主分层学习自身特征的能力,最早由Yann LeCun等于1989年提出[2]。基于CNN的深度模型多用于图像识别和视频处理等领域,在大样本集背景下,基于CNN的目标识别方法比传统目标识别方法具有更强的鲁棒性和泛化能力[16]。经典的CNN模型由输入层、输出层、若干卷积层及池化层组成,如图1所示。卷积层与前一层采用局部连接和权值共享的方式相连,大大降低了模型的参数数量。池化层大幅降低特征的维度,减小分类难度,使网络具有更高的鲁棒性[17]。

图1 经典CNN模型的简易框图
2012年以前,受计算机计算能力的限制,卷积神经网络在图像分类、目标识别等领域的发展一直没有取得质的突破,直到Hinton等提出了更深的卷积神经网络AlexNet,并将该模型用于2012年的ImageNet图像识别竞赛中(ImageNet是目前公开的最大的视觉数据库,包含100万幅图像,超过1 000个物体类别),得到了比当时最好的识别方法高出将近一半的正确识别率,引起了人们对深度卷积神经网络的高度重视。基于CNN的深度模型开始快速发展[18],更深更广的深度卷积神经网络模型相继被提出,如ZFNet[19]、VGG16[20]、GoogleNet[21]以及ResNet[22]等。
在大规模视觉识别竞赛ImageNet中,基于深度学习的模型展现出了强大的学习能力:在图像分类竞赛单元中,2012年AlexNet模型获得了比传统方法高出10%的正确率;2014年GoogleNet模型的正确率为93.344%,VGGNet模型的正确率为92.68%;2015年ResNet模型的正确率为96.43%;2016年的Inception V4模型的错误率仅为3.08%,而人类正常进行图像分类的错误率约为5%,基于深度学习的图像分类能力已经明显高于人类的区分能力[23],卷积神经网络逐渐被成功应用于目标检测、图像分割、物体识别等领域。
2 基于深度卷积神经网络的目标识别方法
随着深度卷积神经网络模型的不断变深,基于深度卷积神经网络的目标识别(或目标检测)方法也取得了重大进展,它可以通过自主学习从大量训练样本数据中学习到包含一定语义信息的目标特征,更有利于目标的识别和分类[24]。目前有代表性的主要有R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、YOLO、SSD等。
R-CNN(region-based convolution neural networks)是Ross B. Girshick在2014年提出的一种基于区域的深度卷积神经网络目标识别框架,它将候选区域与深度卷积神经网络组合代替传统目标识别算法中滑动窗口与手工设计特征的组合,是深度学习在目标识别领域的首次突破[2,25-27]。
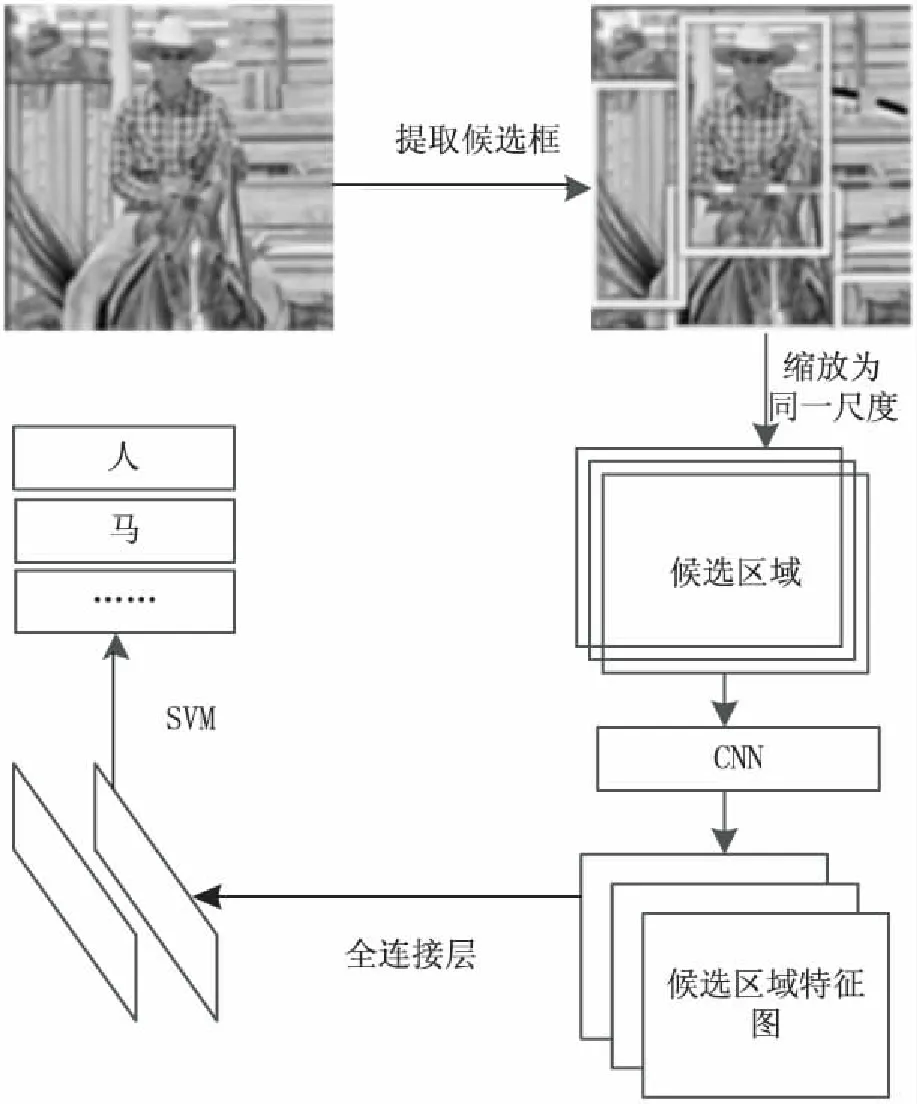
图2 R-CNN目标识别流程
R-CNN的目标识别流程如图2所示。首先采用选择性搜索算法从输入图像中提取2 000个候选区域,然后将所有的候选区域缩放为同一尺度,通过预先训练好的卷积神经网络获取每一个候选区域的特征图,再经过两个全连接层把特征图转化为特征向量,最后利用支持向量机(SVM)对每个候选区域内的物体进行分类识别[2,25-28]。相比之前的目标识别方法,该方法的目标识别精度有了很大提升,这充分体现出深度学习的优势,但该方法存在提取的候选区域数量多、计算量大、中间数据需单独保存、算法运行速率慢、支持向量机分类模型需进一步优化等问题[25-26]。
空间金字塔池化网络(spatial pyramid pooling in deep convolution networks,SPP-Net)是何凯明基于R-CNN改进的一种更加快速的目标识别方法。该方法在提取出图像中不同大小的候选区域后,通过预先训练好的卷积神经网络对整幅图像进行卷积得到整幅图像的特征图,将每一个候选区域投影到特征图上,找出候选区域对应的特征,再利用空间金字塔池化层对不同大小的候选区域进行池化,得到固定大小的特征向量并连接到全连接层,最后将全连接层的输出作为分类器的输入进行目标的分类识别[2,26-29]。由于空间金字塔池化层的存在,使得SPP-Net可以处理任意大小的图像。SPP-Net的目标识别流程如图3所示。

图3 SPP-Net目标识别流程
基于SPP-Net方法,2015年Ross Girshick提出了一种改进的目标识别方法Fast R-CNN。该方法将整幅图像通过训练好的卷积神经网络进行卷积,得到整幅图像的特征图,将提取的候选区域投影到特征图上,用简化的空间金字塔池化层(SSP)——感兴趣区域池化层(ROI pooling)提取候选区域的特征并连接到全连接层,得到特征向量,最后将边框回归直接加入到模型中进行训练,用多任务学习的方式同时进行分类和回归[26,30]。该方法的中间数据不再需要单独存储,测试速度相较于SPP-Net方法提高了近10倍,在国际标准目标检测数据集VOC2007上的平均测试精度为68%[25-26]。
虽然Fast R-CNN的运行时间相较于R-CNN和SPP-Net大幅缩短,但候选区域的提取仍是速度提升的瓶颈。为进一步提高算法的运行时间,Girshick又与何凯明等合作提出了一种Faster R-CNN目标识别方法,它由一个区域生成网络(region proposal networks,RPN)和Fast R-CNN组成。RPN是一种直接用于提取候选区域的神经网络,与Fast R-CNN共享卷积特征,在对整幅图像卷积得到图像的特征图后,将特征图输入到RPN中提取出候选区域的特征,经过感兴趣区域池化层(ROI pooling)将候选区域特征输出到全连接层,最后使用分类器进行目标的分类识别。该方法通过RPN直接提取候选区域特征,进一步提高了目标识别的速度,在VOC2007上其平均测试精度达到了73%[16,26,31]。Fast R-CNN和Faster R-CNN的目标识别流程分别如图4(a)和4(b)所示。
YOLO(you only look once)是Redmon在CVPR2016(计算机视觉领域国际顶会)上提出的一个端到端的基于深度卷积神经网络的目标识别方法。该方法将目标检测作为回归问题求解,无需提取候选区域,通过将图像划分为固定大小的网格,在每个网格内预测边框内包含目标的置信度和边框区域属于不同类别的概率,直接在整幅图像上回归得到目标边框的位置和所属类别,运行速度有了极大提高。YOLO的目标识别流程如图5所示[32],与R-CNN、Fast R-CNN、Faster R-CNN等方法不同,YOLO中训练和目标检测在一个单独网络中进行,大大提高了目标检测的速度且背景误检率低,但该方法的目标定位误差较大,当多个目标的中点位于同一网格内时只能识别出一个目标,检测精度低[26]。
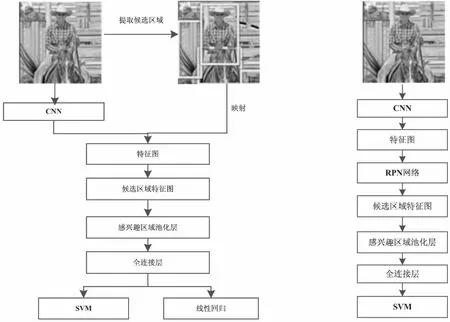
(a)Fast RCNN (b)Faster R-CNN
图4 Fast RCNN及Faster R-CNN目标识别流程
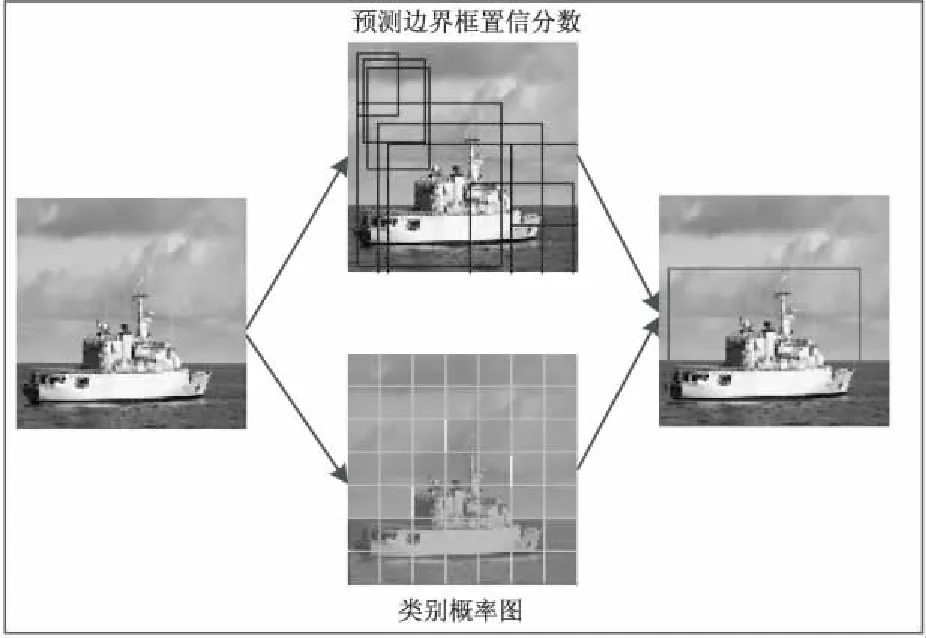
图5 YOLO目标识别流程
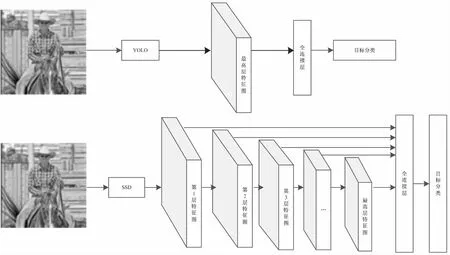
图6 SSD与YOLO网络结构对比
SSD(single shot multibox detector)是Wei Liu提出的另一种端到端的目标识别方法。该方法借鉴了Faster R-CNN中的RPN网络和YOLO的回归思想,基于前馈卷积神经网络,将边界框的输出空间离散化为一组固定尺寸的默认边界框,在每个默认边界框中预测目标及其归属类别的得分,同时在不同层次的特征图上使用小的卷积核预测一系列回归边框的位置,调整边界框从而更好地匹配目标形状,实现目标的高精度检测[33]。SSD与YOLO的网络结构对比如图6所示。从图中可以看出,YOLO的卷积层直接与全连接层相连,在目标分类识别时只用到了最高层的特征图,而SSD采用了特征金字塔结构,将不同层次的卷积层与全连接层相连,使用低层特征图进行小目标识别,使用高层特征图识别较大目标,与YOLO相比,该方法能够在保持检测速度的同时得到高精度的检测结果。
随着硬件性能的提升和计算机技术的进步,基于深度学习的目标识别新方法不断被提出,推动着计算机视觉和人工智能在理论和实践中的快速发展。2012年,Google公司在Google Brain项目中,通过深度神经网络对YouTube上的视频进行无监督的训练和学习,自动识别出视频中的猫[17,34]。2013年,百度成立了深度学习研究院,利用深度神经网络构建了百度大脑,在人脸识别中达到了99.7%的正确识别率[34]。专注于无人驾驶技术研究的MobileEye、Tusimple等公司也将深度学习技术引入到车辆目标识别系统中[17,34]。目前,深度学习在交通信号识别、行人检测、车辆检测、动物检测、人脸识别等目标识别领域已经得到了广泛的应用。
3 深度学习技术在舰船目标识别领域的应用比较
基于以上分析,将具有代表性的基于候选区域的Faster RCNN目标识别方法和端到端的YOLO目标识别方法应用到舰船目标识别当中,对两种方法得到的舰船目标识别结果进行客观分析,从而比较不同方法在舰船目标识别领域的优劣性。
由于目前没有公开的用于深度学习模型训练的舰船样本数据集,文中通过互联网搜集、拍摄船模以及出海采集舰船样本的方法构建了一个包含20 000张不同舰船样本的数据集用于模型的训练和学习。随机选择其中15 000张图像作为训练集,剩下的5 000张图像作为测试集。训练集和测试集中部分舰船样本图像如图7所示。实验的硬件平台为:Intel(R) Core(TM) i5-6300HQ GPU960M@2.30 GHz,8 GB内存。
将训练集分别输入到Faster RCNN模型和YOLO模型中进行训练,训练过程中,设定最大循环次数为2 000次,初始学习率设置为0.01以快速得到较优的参数值,循环500次后将学习率调整为0.001,循环1 000次后将学习率调整为0.000 1防止模型陷入局部最优。训练完成后,将测试集分别输入到训练好的Faster RCNN模型和YOLO模型中,得到两种目标识别方法对测试集中舰船样本的识别结果,部分识别结果分别如图8和9所示。从图中可以看出,采用两种目标识别方法均能识别出不同种类的舰船目标。
为对两种方法的舰船目标识别结果进行客观评价,采用目标检测中最常用的两个评价指标(准确率和召回率)对两种方法的识别结果进行比较。其计算方法如式1所示:
(1)
其中,TP为正确识别出的舰船目标个数;TP+FP为被判定为舰船目标的总数;TP+FN为真实的舰船目标总数。经统计,舰船样本测试集中包含舰船目标总数为5 256个。

图7 训练集及测试集中部分样本图像

图8 Faster RCNN的舰船目标识别结果

图9 YOLO的舰船目标识别结果
对两种方法在5 000张舰船样本测试集中的识别结果进行统计。Faster RCNN中,正确识别出的舰船目标个数为4 585,被判定为舰船目标的总数为4 931;YOLO中,正确识别出的舰船目标个数为4 406,被判定为舰船目标的总数为4 852。由此可根据式1分别计算得出Faster RCNN及YOLO对舰船目标识别的准确率和召回率,如表1所示。

表1 Faster RCNN及YOLO识别舰船目标的客观评价结果 %
此外,Faster RCNN模型中,舰船样本训练集的训练过程共耗时17分30秒,测试过程中平均一张图像的检测时间约为0.07秒;YOLO模型对舰船样本训练集的训练时间为3分45秒,测试过程中平均一张图像的检测时间约为0.015秒。
基于以上分析可以看出,采用Faster RCNN对舰船目标进行识别的准确率和召回率均比采用YOLO识别舰船目标的准确率和召回率高,但是YOLO由于直接采用端到端的方法实现舰船目标的识别,其训练时间和测试时间相比于Faster RCNN大幅缩短,其检测一张舰船目标图像的平均时间约为Faster RCNN检测一张舰船样本图像平均时间的21.43%。
4 结束语
文中综述了近年来深度学习中具有代表性的深度模型,对基于深度卷积神经网络的几类主流目标识别方法进行了总结,将具有代表性的基于候选区域的Faster RCNN目标识别方法和端到端的YOLO目标识别方法应用到舰船目标识别领域,对两种方法得到的舰船目标识别结果进行客观分析,结果表明:
(1)两种方法均能正确识别出舰船目标;
(2)采用Faster RCNN方法得到的舰船目标识别结果,其准确率和召回率均比采用YOLO方法得到的舰船目标识别的准确率和召回率高;
(3)采用Faster RCNN方法得到的舰船目标识别结果,其运行效率远低于YOLO方法的运行效率。
下一步将针对舰船目标识别领域,综合Faster RCNN方法检测目标的准确性和YOLO方法检测目标的快速性,提出更加适用于舰船目标识别的检测方法,在目标识别精度和算法复杂度之间取得平衡。
