基于深度神经压缩的YOLO优化
2019-12-11陈莉君
陈莉君,李 卓
(西安邮电大学 计算机学院,陕西 西安 710100)
0 引 言
从AlphaGo开始,深度学习逐渐进入业内研究者的视线。深度学习成为热点的主要原因是由于近些年设备的计算力的增加,尤其是图形处理器(graphics processing unit,GPU)对于浮点数运算的有力支持。YOLO[1]提出了一种新的目标识别方法,将检测和回归问题集合在一起,大大增加了对于目标的检测速度。但是,YOLO的网络层数相较于传统的网络也增加很多,导致训练和推理的计算量大大增加。尤其是嵌入式设备和移动设备,这些设备可能并不能很好地支撑层数增加之后带来的计算量增加。
目前许多网络在设计的过程中,都会有一些复杂的结构设计,例如全连接层,增加卷积层,这样会带来更高的精确度。相对的,这样的设计造成了网络模型中存在更多的冗余,增加了计算复杂度。优化压缩模型大致有三个方向:(1)更为精细的网络设计,简化卷积层和全连接层的形式[2]。(2)对模型进行裁剪,在结构复杂的神经网络中,往往存在着大量的参数冗余,因此可以寻找一个适当的评定方法进行剪枝优化[3]。(3)为了保持原有模型中的数据精度,一般常见的网络中,都会以32 bit的浮点类型保存模型权重[4]。这种保存方式,增加了数据存储的大小和重载模型的计算复杂度。对于以上情况,可以将数据进行量化或者二值化。通过量化或者二值化之后,可以对存储空间进行压缩。此外,还可以对卷积核进行稀疏化,将卷积核一部分裁剪为0,从而减少再次加载模型的计算量。
文中着重讨论第二种、第三种方法,对YOLO模型进行剪枝、量化,降低模型对存储空间的占用,减少计算复杂度。
1 相关工作
1.1 深度神经压缩
在计算机视觉领域,深度神经网络已经是一个最佳的实践方法。然而,由于有限的计算和存储资源,这些模型很难转移到嵌入式系统中。更多的研究者逐渐开始关注对于深度神经网络模型的压缩方法[5-7]。对于压缩的方法,主要分为两种: 训练前压缩和训练后压缩。前一种方法主要是在训练期间对于权重、激励和梯度进行压缩。例如Courbariaux[8]在训练过程中使用二值化权重和激励训练二值化神经网络,从而实现在多个数据集上的高压缩的效果。但是这样的压缩方法,需要压缩整个数据集,大大增加了压缩深度模型的时间成本。另一种方法主要是侧重于压缩已经训练好的神经网络。例如Denil[9]等使用权重矩阵的低秩分解来减少网络中的参数数量;Han[4]等使用三阶段对神经网络进行压缩,包括剪枝、训练量化和霍夫曼编码。以这样的方法减少网络的存储需求,并且不减少其准确度。文中将使用Han等的思路对YOLO进行压缩,并且对压缩后的网络进行稀疏属性分析。
1.2 目标识别
以分类为方法的目标识别,即预测边界框和相关类的概率,现在已经成为目标识别领域中常见的方法之一。DMP[10]这种经典的方法常用滑动窗口和分类器来检测窗口内是否存在对象。R-CNN[11]首先提出了使用region proposal生成潜在的边界框,然后在这些区域中运行分类器。这样大大减少了搜索的空间和时间成本。Ouyang[12]提出了一种基于object proposal 的方法,以及一种用于物体检测的可变形深度卷积神经网络。网络学习了大量物体的特征和变形特征。相较于GoogleNet[13],准确率能高出6.1%。但是,遗憾的是,这种网络的计算成本比较高,无法部署在嵌入式系统和设备上。为了解决计算成本问题,Redmon等提出一个命名为YOLO的深度神经网络。模型使用单个神经网络来预测边界框和类概率。后来Redmon[14]等又在YOLO的基础上改进模型,实现了以40 FPS获得78.6 mAP。文中的压缩工作就是建立在YOLO模型之上。
2 方 案
原始YOLO模型在完成训练后,模型大小达到200 M。对嵌入式设备和移动设备而言,200 M的模型进行内存预读,会对设备的性能造成较大影响。本节将从压缩和量化两方面对模型进行优化,并对压缩后的模型进行稀疏度评估,以达到优化模型对于存储空间的要求,并且可以直观地了解到每一层剪枝的情况。
2.1 模型压缩
模型压缩主要分为两个步骤,一个是剪枝,另一个是对权值进行量化存储。框架如图1 所示。

图1 网络压缩的框架
2.1.1 剪 枝
剪枝的主要目的是保存YOLO中重要的链接来达到降低存储数量和计算复杂度的目的。在传统神经网络训练过程中,在神经网络训练之前,神经网络的框架结构就已经被固定了。用户只需要输入数据,就可以在迭代训练后获得需要的权重。但是这种固定框架结构的方式,导致不能在训练过程中随时对神经网络的结构进行优化。因此,常规训练出的模型文件大小都不适合部署在嵌入式设备或移动设备上。YOLO常规训练后的模型大小达到200 M,对于嵌入式设备,将模型预读进内存中,提供给推理过程使用,将会消耗设备的所有内存。所以,根据深度神经压缩的剪枝思路,对YOLO模型进行压缩,是提高YOLO在各种设备上通用性的一种方式。剪枝过程的步骤如下;
(1)通过训练找到权重小于阈值的神经网络链接;
(2)删除权重小于阈值的神经网络链接;
(3)重新对神经网络进行训练。
在训练的过程中使用式1对权重进行计算,使一部分权重趋向于0,然后将小于阈值的链接剪枝。
(1)
使用式1的目的是能够减少在训练剪枝过程中的过拟合现象,并且可以保持较高的精度。在剪枝过程中,从大到小对阈值进行细化,流程如图2所示。

图2 剪枝流程
稀疏度评估将会展示剪枝后每一层中剩余的链接的数量,具体如2.2所述。
2.1.2 量 化
量化是以一个适度的误差为代价,使得精度很高的数值能够以更少的位数进行存储。量化主要分为三个步骤:K-means;确定量化阈值;微调。
先分别介绍三个步骤的相关做法。量化主要通过K-means实现。K-means对质心的选取对于最后量化的结果有很大影响。选择质心有三种方法:均匀量化、随机量化和按密度量化。这里选择均匀量化的方法进行初始化。K-means定义如式2所示。
(2)
其中,n为需要量化的位数;w为权重。
式2根据规定的量化的位数进行初值选取,在过程中使用式3进行聚类。
(3)
在完成聚类之后,将进行稀疏度和准确率的评估,依据评估后的结果进行微调。微调主要是对K-means的质心进行调整。在微调过程中,因为在初始化之后,权重矩阵已经成为稀疏矩阵,有部分位置已经被置零,这些位置的梯度相应地在微调过程中也会被放弃。微调的对象为式2计算出的质心。
微调的方法为使用梯度矩阵对质心进行微调。微调主要是将权值的梯度进行求和再乘以学习率,然后再将这部分的数值从质心中减去,如式4所示。
(4)
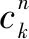
量化完成后,剪枝后的稀疏矩阵将成为一个稀疏矩阵加一个查找表。
2.2 测试和评估模型
2.2.1 测试模型
在YOLO原始模型中,并没有计算任何准确率的方法。这样就不能将压缩后的结果和预期结果进行对比,因此,实验中需要加上对模型的测试功能。测试将分为三个指标进行:True Positive被模型预测为正的正样本 、True Negative负样本和False Positive被模型预测为正的负样本,以及精度P和召回率R,如下:
(5)
(6)
2.2.2 稀疏度评估
在剪枝和量化过程中,会将原始权重矩阵改变为稀疏矩阵。稀疏编码在神经网络模型压缩领域中有着很大作用。在每一次剪枝和量化中,可量化每一次的结果,并且根据结果进行修正。代码实现如图3所示。

图3 修正代码
稀疏度评估函数主要是将现有的权重稀疏矩阵和原始网络的权重矩阵进行对比,算出每一层的权重稀疏度和贝叶斯数值。
3 实验结果及分析
3.1 实验结果
采用voc2012数据集,并且在基于PyTorch的YOLO模型上进行实验。在阈值接近0.9时,准确率接近原始模型。在表1中展示权重比例从0.9到0.6模型的mAP。并且将模型部分层的稀疏度进行打印。

表1 阈值变化对于mAP的影响
图4展示了部分层在剪枝和量化后的稀疏度,最后可以看出,压缩后的模型只有原始模型的0.013权重数量。
图5展示了在压缩过程中的微调步骤,每一次微调都会引起mAP的抖动,在执行多次微调之后,可以将准确率逼近没有压缩前的模型

图4 部分层的稀疏度
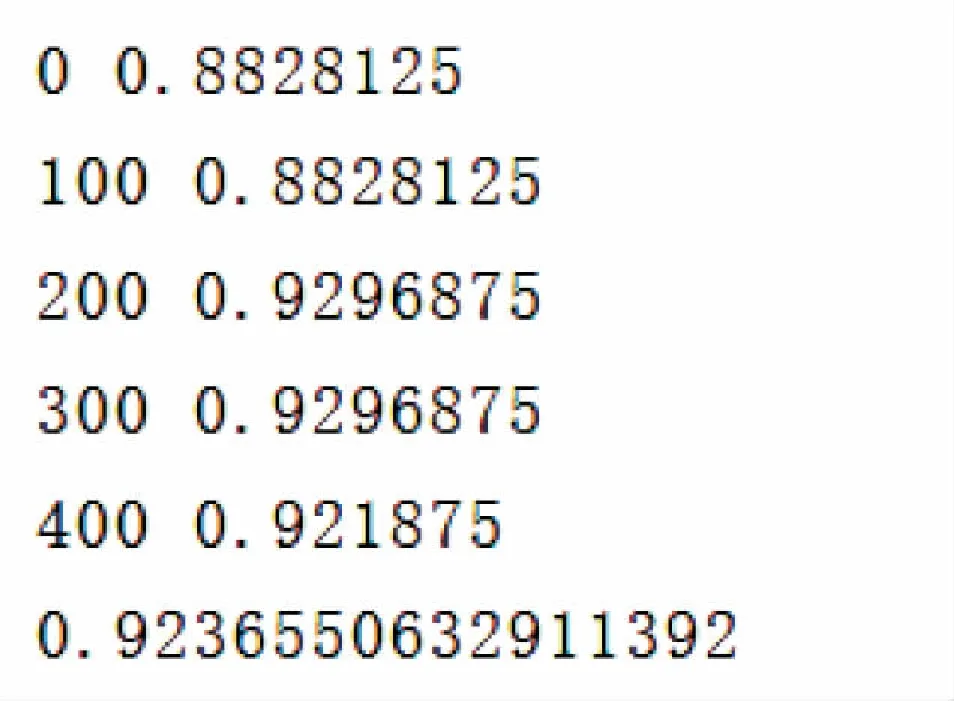
图5 微调过程中的mAP展示
3.2 分 析
从实验中可以看出,深度神经压缩对YOLO模型的压缩效果比较明显。最后的结果可以接近原模型的1%大小。模型大大减少了对存储空间的需求,并且可以满足部署在嵌入式设备上的需求。
对比表1可以得出,对权重比例不是减少得越多越好,减得过多,将会造成模型准确率的大幅下降。模型在保持80%~90%权重的情况下表现较好。
在图4所示的过程中,部分层的权重即将被置零。这说明YOLO网络在设计过程中,部分网络由于全连接的原因,出现冗余,这些链接权重是压缩模型过程中需要去剪枝的部分。在图5所示的过程中可以看出,对于阈值的每一次微调都会对mAP产生一定的影响,所以在压缩的过程中,需要不断地对阈值进行调整。并且阈值调整的步长越细小,得出的结果越好。
4 结束语
基于深度神经压缩对YOLO进行压缩。单独使用剪枝或者量化方法,压缩后的模型依然存在一定的冗余,因此提出了一种结合剪枝和量化的方法对模型进行压缩。并且原始YOLO模型没有对于模型的测试方法以及对于模型稀疏度评估的手段。文中从这两方面对整个压缩过程进行优化,可以在压缩后直观地观察到神经网络中某些层在整个神经网络中的冗余情况。给予设计网络过程一定的指导作用。实验证明,基于深度神经压缩的混合压缩方法,能够有效减少YOLO模型中存在的参数冗余,减少网络模型对存储空间的需求。下一步将在物理存储上进行优化。
