基于概率神经网络的在线分类器
2019-12-11于哲舟
吴 垒,于哲舟
(吉林大学 计算机科学与技术学院,吉林 长春 130012)
0 引 言
概率神经网络(probabilistic neural network,PNN)[1]是Specht利用神经网络实现的贝叶斯分类器,由于其训练效率和统计基础而广泛应用于各领域[2-6]。但是,原始PNN存在一些可能导致PNN性能下降的限制。文献[7-8]提到的一个主要限制是所有训练数据都需要存储在模式层中,尤其是在处理大数据时将导致占用大量存储空间。在OL-PNN中,通过高斯聚类技术数据点被聚类为一部分有代表意义的模式节点,相比需要存储所有数据的PNN,OL-PNN只需要很少的内存。
PNN的另一个缺点是不能处理数据非均匀分布下的复杂分类问题,如图1(a)所示。在PNN中使用共享一个平滑参数的高斯核函数估计概率密度函数,但是从图1(a)中可以看出,一个全局的平滑参数不能表示训练数据的局部分布信息。文献[9-10]中提出一种克服该缺点的方法是异质PNN,即模式节点具有不同的平滑参数。尽管如此,由于一个模式节点中高斯核的维度共享参数,异质PNN忽略了数据维度之间的差异性,这种差异性通常表现为不同特征对分类决策的影响是不一致的(见图1(b))。因此,在OL-PNN中采用的更泛化的方法是给高斯核中的每个维度设置不同的平滑参数,并且通过这种方式可以对数据进行稳定特征的选择,因为具有较大平滑参数值的维度对分类影响很小[8]。与原始PNN相比OL-PNN克服了原有PNN的局限性,并增强了模型的表达能力,在处理复杂和大数据方面具有优势。另外,尽管许多研究都致力于提高PNN的分类性能,但大多数算法都牺牲了原始PNN的效率并增加了大量的计算量。与大多数改进的PNN不同,在线神经网络可以通过在线学习进行训练,所有数据只需要一次扫描,保证了算法的处理效率。此外,OL-PNN通过高斯核中的分离平滑参数来权衡特征对不同模式的影响,并通过添加额外的线性特征层来捕获特征之间的一些交叉效应。
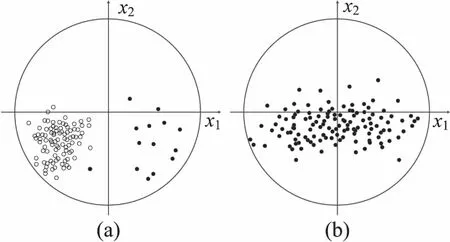
图1 数据分布
图1中,图(a)为两类数据分布。左边数据分布密集而右边数据分布分散。因此,较小的平滑参数值适用于左边数据,而不适合右边的数据。由于数据分布复杂且不均匀,在实际问题中常常没有理想的全局平滑参数能适用于所有区域。图(b)为一类数据分布。数据在x2轴上的分布比在x1轴上的分布更密集。数据在不同维度的分布常常差异很大,对所有维度使用统一平滑参数会影响模型的精度。
1 相关研究工作
传统PNN是Specht在1994年提出的神经网络模型,通过Parzen窗口来估计概率密度函数,并利用贝叶斯策略形成模型的决策边界,即最小化误分类风险[1]。随着PNN在各个领域的广泛应用,已经有许多改进研究尝试克服原始PNN的局限性。其中一个研究热点是高斯核函数中平滑参数的选择和优化。在原始PNN中,通常通过交叉验证来调试全局平滑参数,以获得更好的性能[7]。然而,固定的全局参数不能表达复杂数据分布和大型训练集中的复杂关系。一种可行的改进方法是Streit提出的异质混合高斯模型[9],这种模型的PNN通常被称为异质PNN[10],其主要思想是利用最大似然估计代替非参数核密度估计,并使用期望最大化(EM)算法更新参数。然而,EM中所需的完全协方差矩阵在许多问题中可能无法获得[8]。而且,由于数值上计算的困难,这种算法在实践中常常失败[10]。基于Streit的工作,Yang将EM算法与Jack-Knife结合起来训练异质PNN,克服了EM算法数值计算的困难。此外,一些进化计算算法,比如遗传算法[11]、粒子群优化算法[12],也被用于优化平滑参数。
PNN的另一个限制是计算复杂性和存储空间的要求[7-8],即PNN的时间开销和空间开销随数据规模增大而线性增长。解决此问题的主要策略是聚类技术,通过较少的模式节点表示所有训练数据。一些聚类技术,比如K-均值聚类[13]、高斯聚类[14]等已经应用于PNN以改善性能。除了聚类技术之外,在某些应用中,预处理手段在原始数据库中提前进行以减少数据维度[11,15]。
除了以上两个改进方向外,一些研究者尝试引入其他策略来提高PNN性能。Berthold提出了一种基于RC的动态约简调整算法,以自动形成PNN模型[16]。考虑到一类数据中不同簇之间的距离对精度的影响,Zeinali提出了一种竞争策略,即只有一部分具有最大输出的模式节点将在训练或测试进程中起作用[17]。
尽管上述这些改进的PNN已成功应用于许多领域,但应注意的是,大多数改进PNN都增加了大量额外计算,并且通常需要通过离线学习进行训练。为了继承原始PNN训练简单快速的优点并克服其局限性,文中提出一种在线学习概率神经网络。
2 基于PNN的在线概率神经网络
2.1 算法原理
分类器的一般任务是将D维输入向量X={x1,x2,…,xD}分配给类索引Class(X)。根据贝叶斯规则,输入X的分类类别定义如下:
(1)
其中,N为类的数量;fi(X)为PNN中由高斯核函数估计的类i的条件概率密度函数;αi为类i的先验概率,通常设置为:
(2)
设在PNN的模式层中,类i的模式节点数为Ki,模式节点的总数为K。对于类i中的模式节点j=1,2,…,Ki,设pi,j(X)表示第j个模式节点的概率密度函数,则在原始PNN中,fi(X)有以下形式:
(3)
(4)
其中,μi,j,d表示第i类的第j模式节点在第d维度的中心;σ表示原始PNN中的全局平滑参数。
在原始PNN中,一个全局平滑参数σ被统一应用到不同维度、不同模式节点和不同类别中,整个模式层共享该平滑参数,这个参数也是原始PNN唯一需要训练调节的参数。因此交叉验证就能够方便地对原始PNN进行训练。然而,全局参数不能准确地表示复杂数据集中数据分布的局部信息,尤其是在数据不均匀分布的情况下。因此,具有分离平滑参数的异质PNN被提出来以提升算法性能。在异质PNN中,pi,j(X)具有以下形式:
(5)
其中,σi,j表示第i类的第j个模式节点的平滑参数。
虽然异质PNN在对不同的模式节点设置不同的平滑参数,但是同一高斯核中的所有维数仍然共享一个平滑参数,这使得异质PNN忽略了维度间的量纲差异性。通过对不同维度设置不同的平滑参数,如图2所示,经过训练后的单个高斯核中的平滑参数可以表示相应维度或特征的分类重要性,因为有较小平滑参数的维度数据分布更集中,说明数据在该维度上更加稳定。
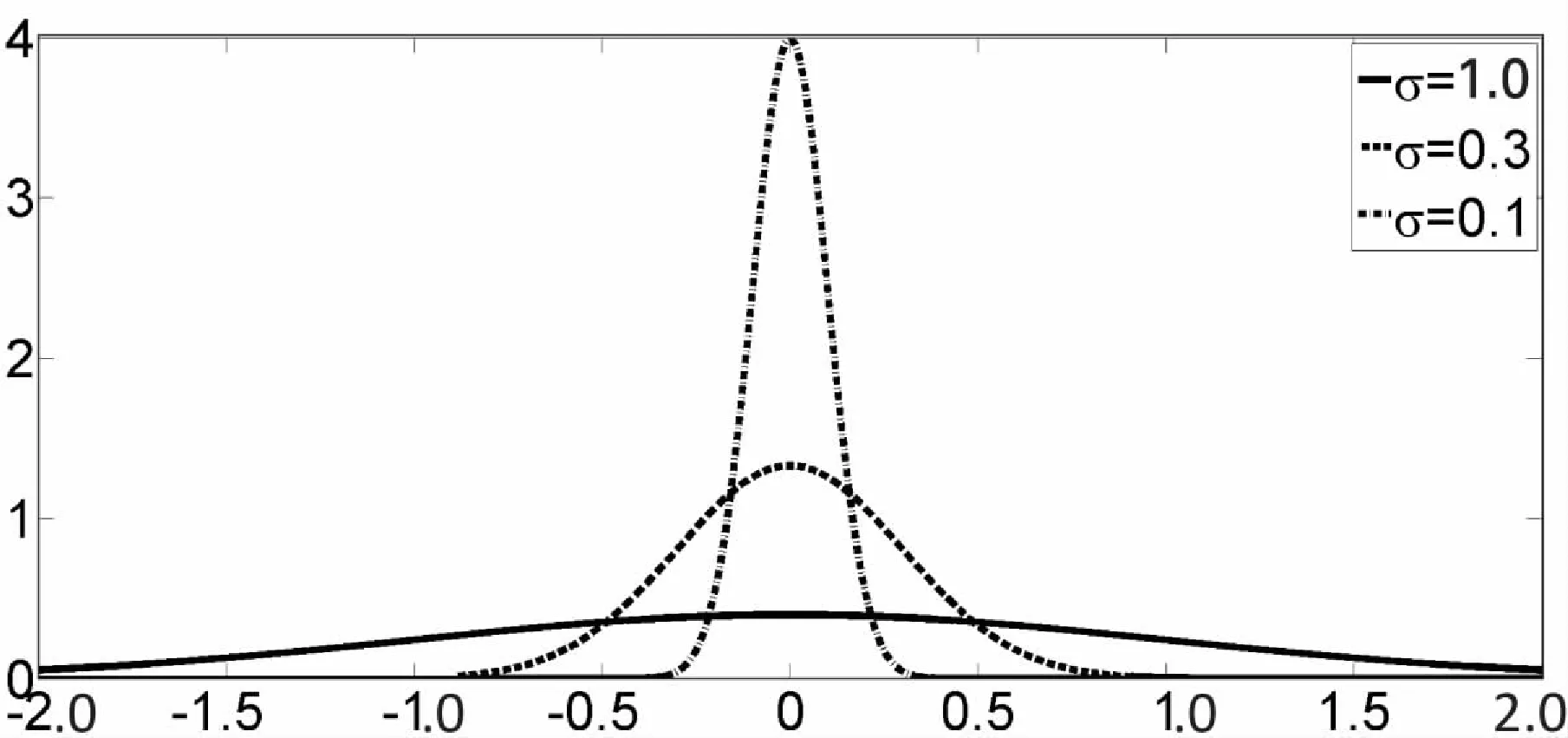
图2 特征的一维高斯分布
因此通过对不同维度设定分离的平滑参数,OL-PNN可以得到一种更泛化的pi,j(X)定义形式:
(6)
其中,σi,j,d表示第i类中第j个模式节点在第d维的平滑参数。
采用类似于文献[17]的竞争策略,文中算法中类i的条件概率密度函数由下式给出:
(7)
但是在有高维特征的情况下,大量小于1的乘积分量会导致pi,j(X)趋于零,失去了计算意义。为了避免这种情况并加速计算,在实际模型计算中,pi,j(X)中的乘法被替换为加法:
Lpi,j(X)=log(pi,j(X))=
(8)
2.2 模型结构
在线学习概率神经网络模型分为5层,分别是输入层、特征层、模式层、加和层和输出层(见图3)。在图3中,输入层仅将输入矢量的相应值传递给所有特征节点。特征节点中的加权参数W={w1,w2,…,wd}是通过一种称为球面编码[18]的方法预设的,用于将输入空间线性转换为更高维的特征空间。特征层和模式层采用全连接的方式,每一个连接上都有拥有两个独立参数的高斯核函数,即平滑参数σ和中心参数μ。在模式层中,来自不同特征层节点的输入按照式10计算相应的概率密度函数,在分类时数据被分类为有最大概率密度函数值的模式节点对应的类别。每个模式节点具有所有特征的混合高斯核,可以表征一类具有特定分布的数据,对应高斯聚类中的一个类簇。在原始PNN中,加和层节点的输出是来自各个模式节点的输入之和平均,以计算类内所有模式节点的平均似然。在OL-PNN中应用竞争策略,加和层节点仅输出所有模式节点中的最大值。输出节点将做出一个决定,将测试数据分配给具有最大输入值即最大似然的节点相对应的类。
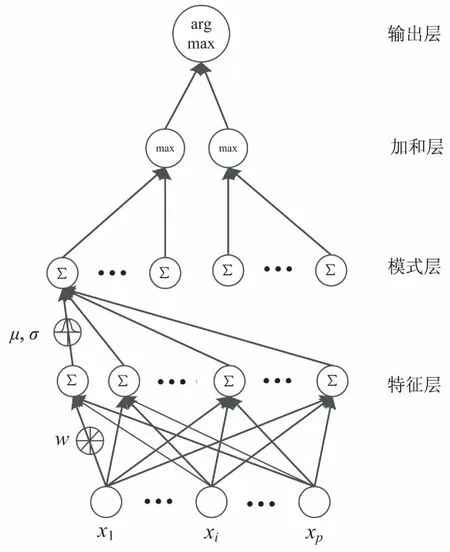
图3 模型结构
2.2.1 特征层
在原始PNN中,数据的所有维度被认为是相互独立互不影响的。但是实际在很多情况下,特征之间存在复杂的关联。为了在模型中获取特征之间的相互关联,OL-PNN在原始3层PNN模型中加入一层特征层用以提取尽量多的线性特征映射关系。在特征层中每个特征节点负责提供从输入向量到单个变量值的线性映射。这种映射函数feature(X)定义为:
(9)
其中加权参数wd满足:
(10)
假设y=1,则等式
feature(X)=0
(11)
表示输入空间中的一个超平面P。等式
(12)
表示从点X到超平面P的距离,则满足式10的超平面到原点的距离都是r=|θ|。因此,所有满足式10的超平面将围成一个半径为|θ|,球心在原点的超球R,也就是说,这种超平面P是R的切平面。将训练数据映射到超球R中,显然R的切向量到数据点的距离可以被当作该训练数据点的线性特征,而所有的切向量将穷尽数据点的所有线性特征,如图4所示。但是由于R的切向量是无限的,对应数据的线性变换是无限多的,为了获得有意义的线性变换,需要在R上找到足够的切点W使得W满足式10,并使得切点之间的距离最大化。这就是球形编码问题[18]。由于直接计算球面编码非常困难,因此文中提出了一种更简单的近似算法以找到尽可能多的切点。
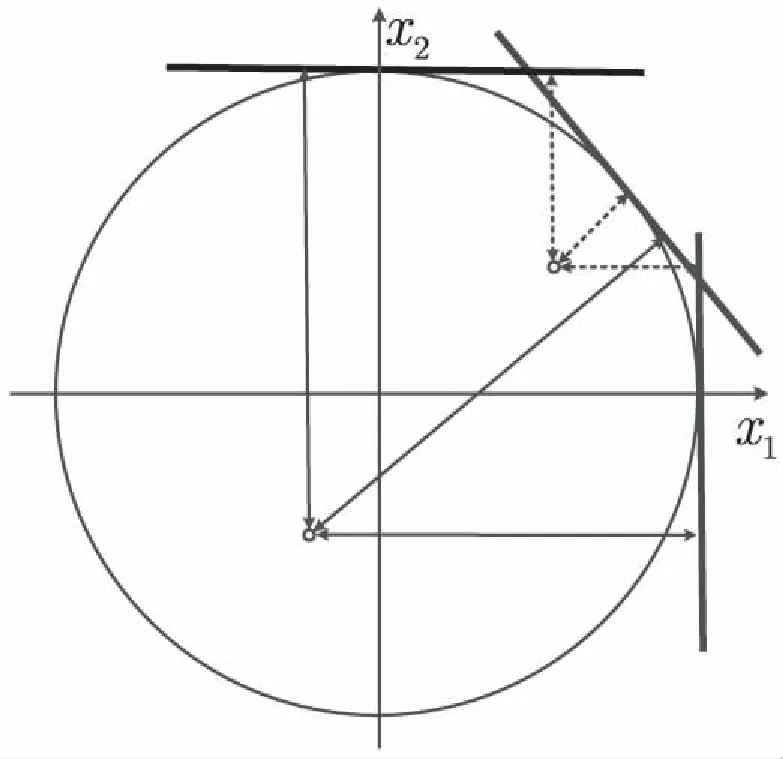
图4 线性特征表示
该算法的主要思想是将m(m>0)个球分配到D个盒子中,设第d个盒子中的球数是md,D是输入数据维度,则可以得到以下等式:
(13)
为了满足式10,一种满足要求的权重W可以设置为:
(14)
因此,可以通过找到所有符合条件的分配方案来定义权重W,则特征节点Dm的数量和分配方案的数量相等,即
(15)
最终特征层将输入向量映射为线性特征向量Y。
Y=F(X)={feature1(X),feature2(X),…,
featureDm(X)}
(16)
如果m=1,此时线性映射特征空间就是输入空间,即Y=X。
在给出Y定义后,类i的条件PDF定义为:
fi(X)=max(pi,j(Y))=max(pi,j(F(X)))
(17)
特征层初始化算法如下:
算法1:特征层初始化(m,D,d,W)。
输入:参数m,数据维度D,当前递归层数d,当前权重参数W
Ifd>D
创建一个特征节点,参数初始化为W
Return
End if
Fors=0:mdo
应用式14计算W的第d个分量wd
特征层初始化(m-s,D,d+1,W)
End for
2.2.2 模式层
在特征层中,通过调节输入参数m可以获得大量的线性特征。然而,并非所有线性特征都对算法分类有效,它们中只有少数部分对分类具有积极影响。因此,在OL-PNN中,不同特征采用不同的平滑参数来权衡特征对分类的影响。
图5展示了模式节点pi,j(X)和特征层节点的全连接方式。
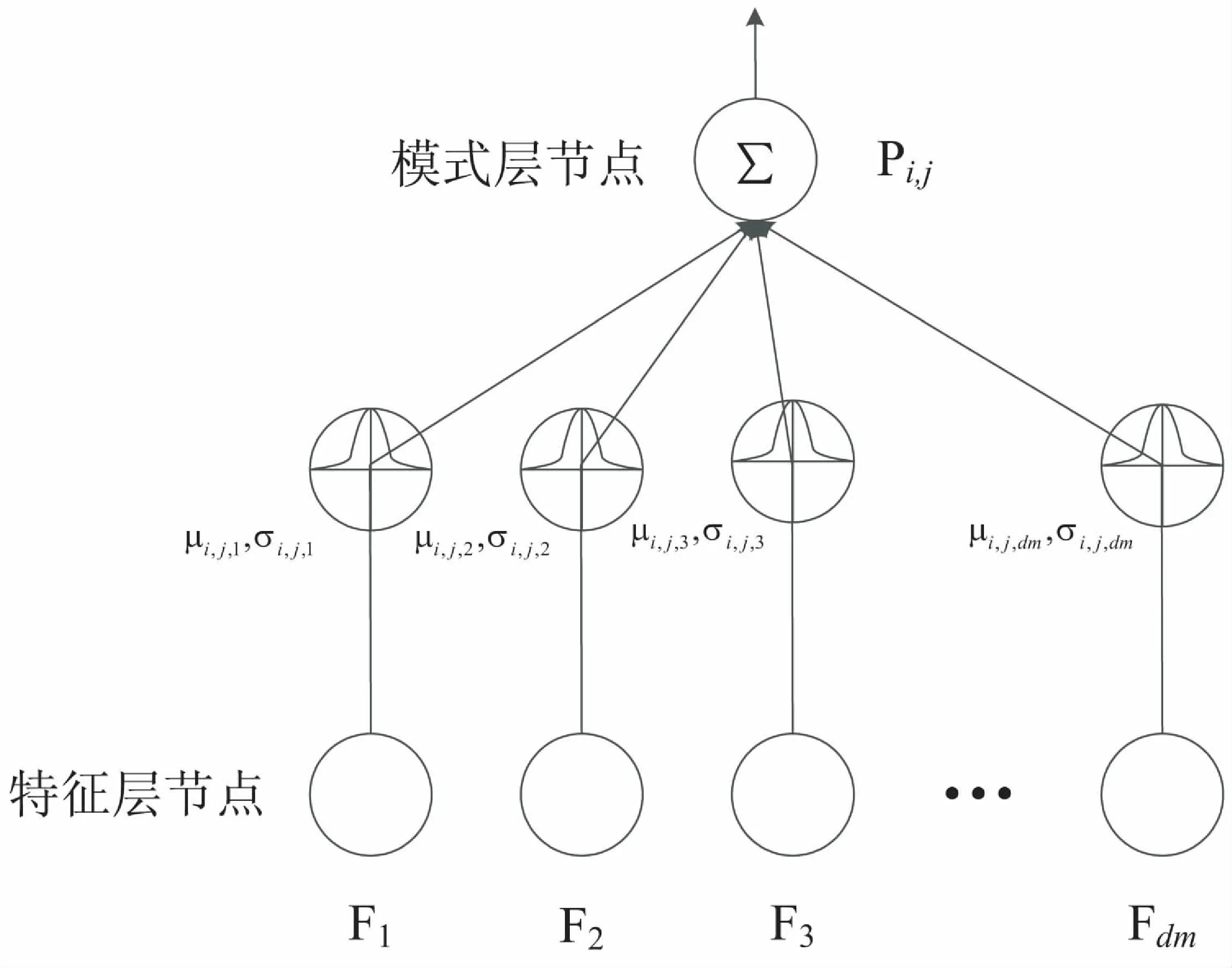
图5 模式节点
每个模式节点在连接不同特征节点时有参数不同的高斯核函数,可以表示为在类中具有特定特征的一类样本,这种方式被称为高斯聚类。通过高斯聚类,模型仅仅需要很少的模式节点就能表征出现的所有的数据模式。
在训练过程中,如果当前训练样本无法被正确分类并且此类中的模式节点总数不超过阈值时,一个新的模式节点将被添加到正确类中以表示现在新出现的数据模式。如果当前训练样本可以被正确分类时,应用竞争性训练策略,调整具有最大输出的模式节点中的参数,使得该模式节点能更好地响应正在训练的数据。在训练过程之后,为了减轻异常值的影响并且防止过拟合,模式节点中很少响应或根本不响应的模式节点将被删除。
2.3 随机梯度上升
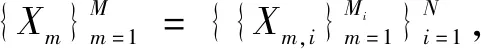
(18)
为了保证模型分类的正确性,可以通过参数调节训练使得L获得最大值。L对需要调节的参数的偏导数为:
(19)
(20)
g(yi,p,d;σi,j,d,μi,j,d)=
(21)
由于在数学上难以直接利用L的偏导来计算参数,因此OL-PNN通过随机梯度上升算法高效地完成训练。随机梯度上升更新函数定义为:
(22)
(23)
其中,α,β表示学习步长。
式22和式23可以解释为每次迭代朝着让当前样本获得更大似然度的方向更新。
算法2:模型训练(α,β,min,max,σ)
输入:梯度上升步长α,β,最少更新次数min,最大模式节点数量max,初始化平滑参数σ
初始化:通过算法1创建特征层
应用式9,式8分别求特征层和模式层输出
If模式层中有最大响应值的模式节点属于正确类i
Or类i中模式节点的数量达到了最大值 max
应用式20更新类i中有最大响应值的模式节点
Else
在类i中创建新的模式节点,其中心参数初始化为特征层输出,平滑参数初始化为σ
End if
End for
For对于所有模式节点 do
If模式节点更新次数少于min
删除该节点
End if
End for
3 实验分析
实验采用UCI数据库中四个基准分类数据库Banknote,Glass,Pima,Wine以研究和比较在线概率神经网络与原始PNN和其他分类器的性能。在实验之前所有数据通过MATLAB中的预定义函数mapminmax对特征进行归一化。为了获得更具统计意义的结果,实验使用重复随机采样方法的10折交叉验证,其中训练数据与测试数据采用5种不同比例:9∶1,8∶2,7∶3,6∶4和5∶5分别进行实验。对于每个比率,训练数据和测试数据被随机划分,并且最后结果是重复50次的平均值。
最后将OL-PNN和PNN的性能与其他五个分类器进行比较,包括K-最近邻(KNN)、随机森林(RF)、朴素贝叶斯(NB)、主成分分析(PCA)、支持向量机(SVM)。
表1展示了原始PNN和OL-PNN在四个数据集中的分类性能和结果。在该表中,列出了原始PNN和OL-PNN的标准偏差,模式节点数量的平均数和平均准确率。
很明显,在所有数据集的大多数比例中,OL-PNN的结果都优于原始PNN,并且OL-PNN中的模式节点的平均数量小于原始PNN中的模式节点的平均数量。此外,在原始PNN中,随着训练数据的增加,模式节点的数量随之增加。然而,OL-PNN中模式节点的数量是稳定的并且远小于原始PNN的模式节点的数量。这是因为模式节点的数量在OL-PNN中表示数据集的空间分布信息,对于一个数据集,它在不同的比例下应该大致相等。然而,从标准偏差列可以看出,由于训练序列对随机梯度上升算法的影响,OL-PNN的稳定性不如PNN。
图6显示了在四个数据集上七个分类器的分类精度。从图6中可以得出结论,每个分类器适用于不同的数据集,例如PCA,其在Pima中表现最佳,但在Glass中表现不佳。对于每个数据集,OL-PNN在大多数比例中优于PNN,并且与其他已知分类器相当,尤其是在Banknote数据集中。
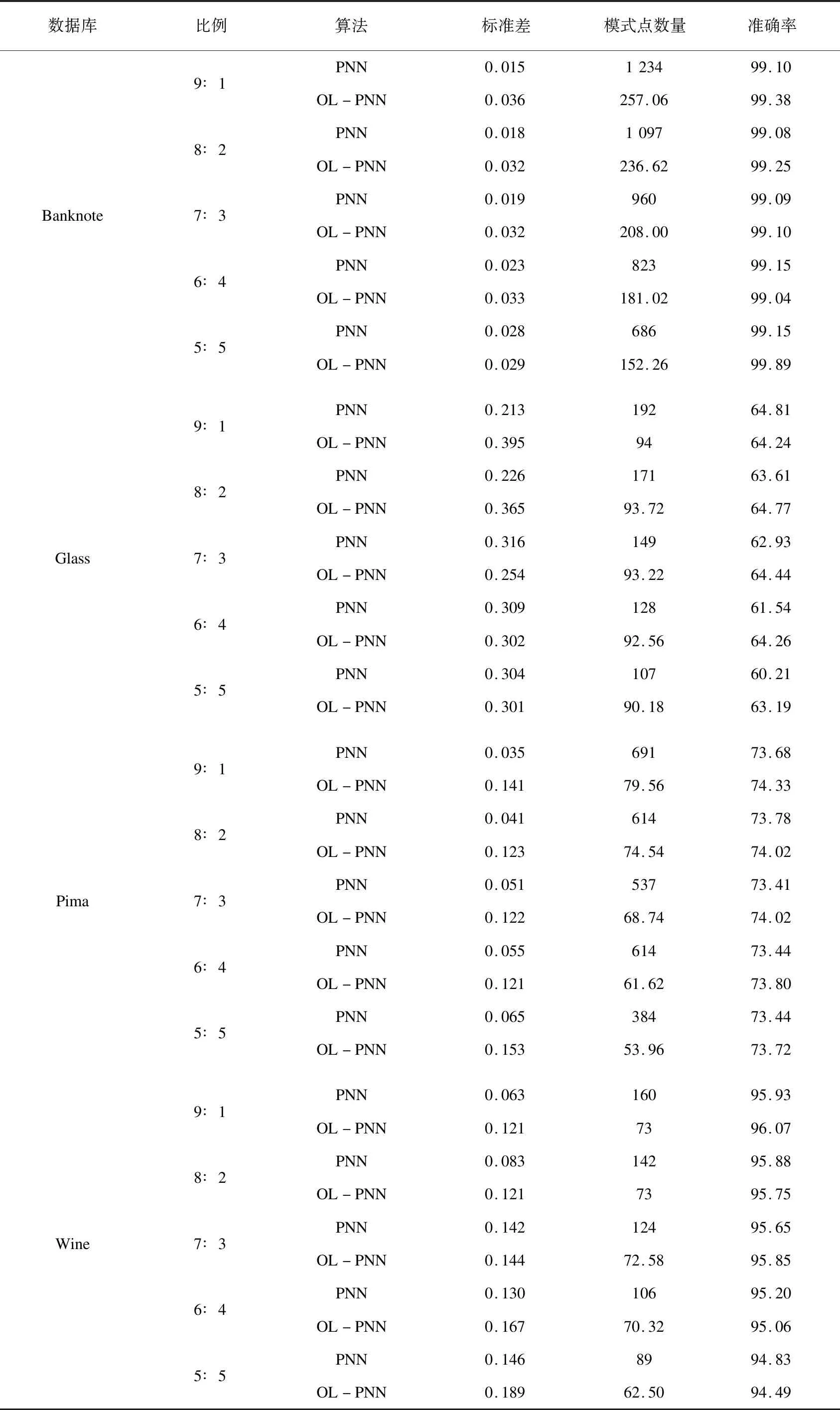
表1 在线概率神经网络和原始PNN实验结果比较
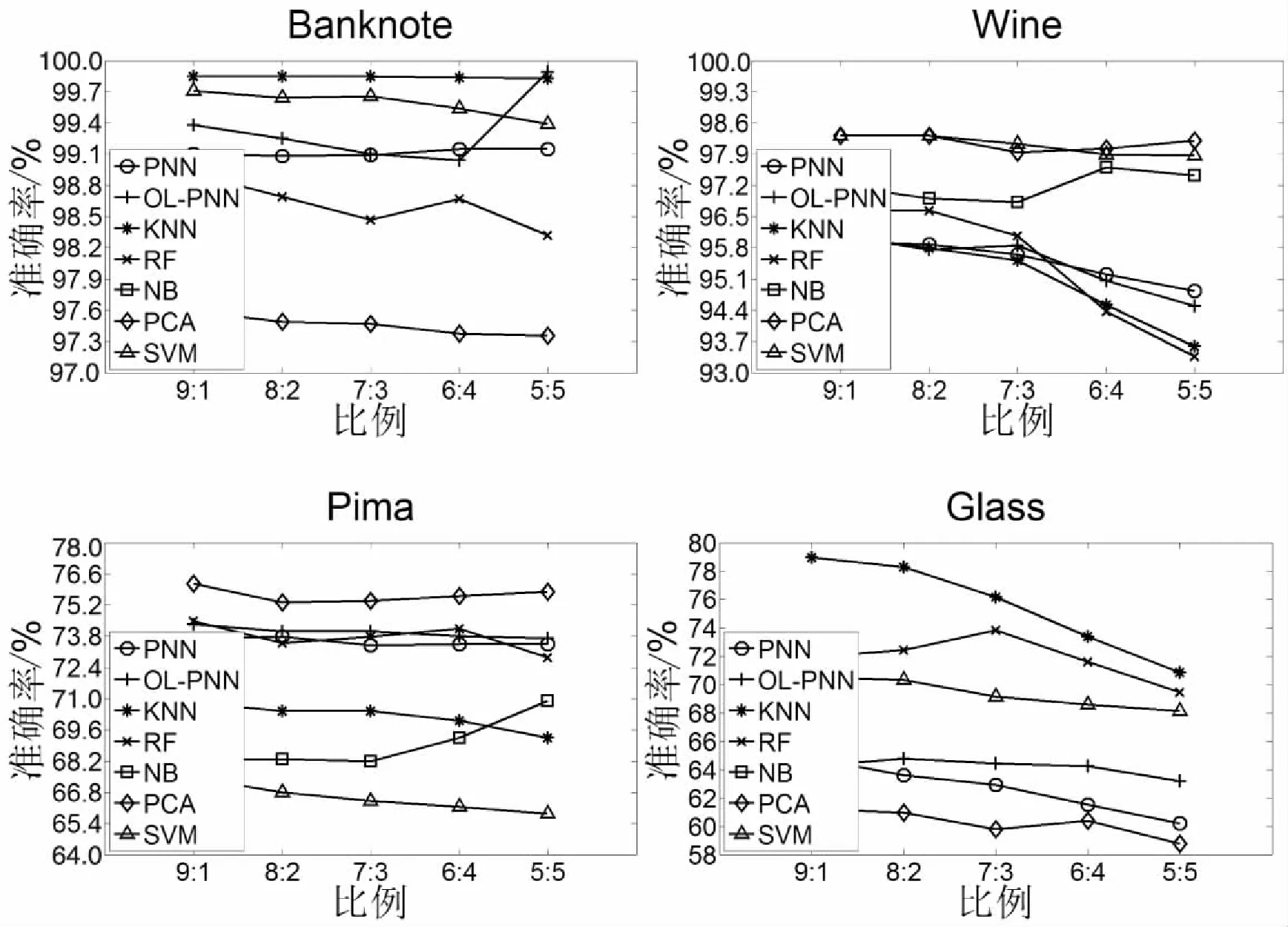
图6 PNN,OL-PNN,KNN,RF,NB,PCA,SVM的
4 结束语
通过对原始PNN模型的改进,增加额外的特征层并利用随机梯度上升算法进行在线学习,新的概率神经网络模型能克服原始PNN的限制,在保证算法效率的同时提高了模型对数据的表达能力。虽然OL-PNN的性能在许多数据集中优于原始PNN,并且具有较小的时间开销,但其性能不如PNN稳定。此外,增加特征层策略不仅增加了计算复杂度,而且还带来了过拟合的风险。在接下来的工作中,将应用一种特征选择技术来删除那些在分类上有不良影响的特征。
