基于CNN与Bi-LSTM的唇语识别研究
2019-12-04骆天依刘大运李修政房国志安欣魏华杰胡城
骆天依 刘大运 李修政 房国志 安欣 魏华杰 胡城


摘要:针对唇语识别过程中唇部特征提取和时序关系存在的问题,提出一种卷积神经网络(CNN)和双向长短时记忆网络(Bi-LSTM)相结合的深度学习模型。利用CNN学习唇部特征,并将学习到的唇部特征送入Bi-LSTM进行时序编码,通过Softmax进行分类。建立NUMBER DATASET和PHRACE DATASET两个大型汉语数据集以解决汉语唇语数據缺失问题。将该模型与传统的唇语识别方法在两个数据集上进行实验对比,发现在NUMBER DATASET上识别准确率为81.3%,比传统方法提高了8.1%,在PHRACE DATASET上识别准确率为83.5%,比传统方法提高了9%。实验结果表明该模型能有效提高唇语识别的准确率。
关键词:唇语识别;卷积神经网络;双向长短时记忆网络;深度学习;时序编码
DOI:10.11907/rjdk.191058开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2019)010-0036-04
0引言
唇语识别指通过观察人说话时唇部特征变化,识别出入所说的话。作为智能化人机交互的重要组成部分,唇语识别技术由于具有方便快捷、安全度高等特点,逐渐应用在辅助语音识别、协助警方破案、提高人脸识别安全性等众多领域。
目前,大多数研究主要集中在唇部检测定位、特征提取以及对样本数据的训练几方面。在唇部检测定位方面,田原螈等提出基于YCbCr肤色检测与AdaBoost联级算法的嘴部特征定位,采用自适应阈值分割法进行唇部特征状态分析。在特征提取方面,王哗等通过改进的主动形状模型(Active Shape Model,ASM),计算标定点间平均纹理和协方差矩阵实现对人脸表情的识别。虽然这种方法直观地获得了唇部特征参数,但模型对唇部初始位置和形状十分依赖,不能很好地适应唇部复杂多变的纹理结构。在样本数据训练方面,Alan J.Goldschen等利用隐马尔可夫模型(Hidden Markov Model,HMM)和层次聚类算法,实现对口腔动态特征的识别;Jfirgen Schmidhuber提出基于长短时记忆单元(Long Short-Term Memory,LSTM)的递归结构,解决了传统循环神经网络(Recurrent Neural Network,RNN)梯度消失的问题。LSTM考虑了过去信息对当前信息的影响,马宁等将LSTM运用到唇语识别,有效解决了唇读信息多样性问题。然而LSTM没有考虑未来信息对当前信息的影响,在一定程度上影响了识别准确率。
针对以上问题,本文提出一种基于卷积神经网络(Con-volutional Neural Network,CNN)和双向长短时记忆网络(Bidirectional-Long Short-Term Memory,Bi-LSTM)的深度学习方法,充分利用CNN捕捉局部特征以及Bi-LSTM捕捉时序信息的特点,无需考虑唇部纹理特征并将未来信息对当前信息的影响考虑在内,实现了对数字0-9和10个常用汉语短语的唇语识别。
1唇语识别模型
基于CNN和Bi-LSTM的唇语识别模型如图1所示,该模型由4个部分组成:①唇读视频预处理;②利用CNN模型学习唇部特征;③利用Bi-LSTM模型提取唇动时序特征;④利用分类器进行特征分类。
1.1输入层
首先将视频转换成图片,然后利用dlib库提取唇部的20个特征点,根据这20个特征点确定唇部位置和裁取范围,裁出唇部随时间变化的特征图像序列,将唇动序列送人输入层。
1.2CNN模型
CNN是一种专用于处理类似网格结构数据的神经网络,包含卷积层、池化层和全连接层3个单元。多层卷积层和池化层交替排列自主学习,在保留训练样本主要特征的同时防止过拟合,并提高模型泛化能力。全连接层对前面学习到的特征进行加权处理,得到各种分类情况概率。
如图2所示,输入层、卷积层和池化层均只有一个。假设输入层和卷积层之间存在m个卷积核,根据卷积层计算公式可以得到卷积层输出的第m个特征面:
类比这类计算方法,可以得到多卷积层情况下的全连接层。
本实验采用CNN对唇部特征进行学习。将输入层内容送人CNN后,卷积层用采样器从视频中采集唇部关键特征信息数据,池化层对卷积层结果进一步压缩,提取到唇部更关键的特征信息,全连接层对池化层结果进行整合,最终将学习到的唇部特征送人到Bi-LSTM中。
1.3Bi-LSTM模型
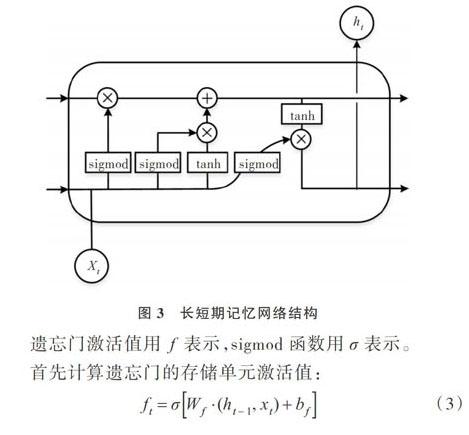
LSTM网络主要由遗忘门(forget gate)、输入门(inpulgate)及输出门(output gate)构成。遗忘门决定从上一单元中丟失哪些信息,输入门的输入信号为h(t-1)和X(t),输出门输出信号h(t)介于0和1之间,见图3。
输出门最终确定LSTM单元的输出值。首先运行一个sigmoid层确定细胞状态的哪个部分将输出出去,之后经过非线性变换得到最终输出。
2实验结果与分析
2.1数据集建立
唇语识别研究刚刚起步,有关唇语方面的数据集很少,其中较具有影响力的数据集如下:
(1)OuluVS数据集。包含20个说话人,语料为每人读10个日常问候短语。
(2)MIRACL-VC数据集。5男10女录制的同时包含深度图和彩色图的唇语数据集,由微软Kinect录制,语料为每人读10个单词和10个短语各10次的视频。
(3)哈工大HIT Bi-CAV语料库。语料为10人基于96个音读出的200个常用汉语句子。
这些视频数据大部分为外文发音,并且大多是针对特定的拍摄技术和场地要求建立的数据集,无法满足中文数字0-9和短语语料要求。因此,笔者根据需求分别构建了中文数字数据集NUMBER DATASET和中文短语数据集PHRACE DATASET。
NUMBER DATASET数据集由10人录制5天完成,每人每天读0-9各10遍,共计5000个视频的普通话唇语数据集。本数据集的视频分辨率为480×640,帧率约为25fps,时长约为2s,见图5。
PHRACE DATASET数据集的建立方法和NUMBERDA7ASET相同,分别录制了唇读生活中10种常见水果名称的视频,将此作为短语数据集的主要内容。
2.2实验设置
分别对NUMBER DATASE7和PHRACE DATASET两个数据集采用分层抽样的方式,抽取500个样本作为测试数据,其余样本作为训练数据。将测试数据与训练数据分离开进行交叉验证,以更好地评估模型的泛化能力。基于上述训练集和测试集,设置了18个唇部特征点+LSTM、CNN+LSTM和CNN+Bi-LSTM三组对比实验,以验证模型的有效性。
三组实验的神经网络模型均采用Keras搭建并基于Tensorflow后端。
在18个唇部特征点+LSTM的实验中,本实验设置与马宁等的实验设置一致。
在CNN+LSTM实验中,图像特征提取的CNN部分采用在ImageNet上预训练过的VGGl6。VGGl6使用连续的小卷积核对图像进行多次卷积,在图像特征提取中表现较好。而本实验中VGGl6模型对最上面的5层进行fine-tuning,其它层的参数不变以适应本文实验数据。对于输入的每帧RGB图像(初始大小为(128,128,3)),经过VGG抽取后的特征向量为(4,4,512),然后采用Flatten方法将三维特征向量转为一个大小为8192的一维向量,使其能够作为LSTM的输入。同时为避免直接输入LSTM的数据过大,还应在CNN与LSTM之间加入一个神经元数为2048的全连接层以减小LSTM输入的数据量。然后使用Keras中Time Distributed层为视频序列中每个CNN网络输出连接一个LSTM,整个模型输出为10个神经元的全连接层,全连接层的激活函数则采取适用于多分类问题的softmax函数。
在CNN+Bi-LSTM实验中,仅将LSTM替换为Bi-LSTM,其余实验设置与第二组实验设置一致。
2.3实验结果
本文选取识别准确率作为评价指标,识别准确率定义如下:
表1和表2分别展示了3种模型在NUMBER DA7AS-ET和PHRACE DATASET数据集上的识别准确率。从表中可以看出,采用CNN+LSTM方法比采用18个唇部特征点+LSTM方法的单词识别准确率提高了5.6%,短语识别准确率提高了6.1%。采用CNN+Bi-LSTM方法比采用CNN+LSTM方法在单词识别准确率和短语识别准确率分别提高了2.5%和2.9%。采用CNN识别特征信息时无需考虑特征对象复杂多变的纹理特征,比采用传统的特征点提取特征信息容错率更高。同时,Bi-LSTM考虑了未来信息对于当前信息的影响,对于唇语识别准确率提升是切实有效的。实验结果表明,CNN和Bi-LSTM相结合的方法识别准确率最高。
3结语
通过对现有深度学习技术和传统唇语识别技术研究,发现传统唇语识别方法存在以下问题:①唇部特征提取时用特征点替代唇部特征不能很好地体现唇部特征;②在时序编码时LSTM并未捕获未来信息对当前信息的影响。针对以上问题,本文提出了一种基于CNN和Bi-LSTM相結合的唇语识别方法,通过CNN有效地学习唇部特征,通过Bi-LSTM捕获上下文信息。实验结果表明,CNN和Bi-LSTM相结合的唇语识别方法,对于提高唇语识别准确率作用明显。本实验还有待完善的地方,如训练数据不够、语料数据集仅包含数字和汉语短语等等,后期将针对以上问题进一步改进。
