基于迁移学习的自然环境下香梨目标识别研究∗
2019-12-04孟欣欣阿里甫库尔班吕情深周雷
孟欣欣,阿里甫·库尔班,吕情深,周雷
(1.新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046;2.中国科学院软件学院,新疆 乌鲁木齐 830008)
0 引言
新疆是香梨的故乡[1].截至到2014年,仅巴州地区香梨的种植面积已经达到4.711万hm2,其中年产量为48.3万吨[2],这给香梨的采摘工作带来了巨大的挑战:人工采摘高额的成本、采摘工作中安全隐患及采摘工作时间成本高等.现在国内外还没有专门的香梨采摘机器,在人工智能迅速发展的今天,香梨采摘机器人的研究也将逐步提上议事日程.相信农业机器化的普及,对于新疆农业的发展有着重要的意义,它不仅解放了农民的双手、提高了农产品的生产效率,对增强农业的抗风险能力也有着至关重要的作用.
近年来,对于自然环境下果实的识别,国内外的学者都做了大量的工作,其中丁亚兰等[2]基于R-B颜色因子分割图像[4]对于果实识别来讲具有局限性,对于高强光以及阴影区的果实识别效果不是很好;宋怀波等[5]利用凸壳理论[6]对苹果识别有着非常好的效果,其通过L*a*b颜色空间下的K-means聚类算法[7]得到目标边缘,然后利用目标边缘的凸壳提取光滑的轮廓曲线,此模型对于近似于圆形的苹果识别效果非常好,但是对于其他水果的识别则具有较大的局限性.傅隆生等[8]基于卷积神经网络模型识别方法大大提高了果实的识别准确率,但是却丢失了果实的边缘轮廓信息.
与传统方法不同,期望能得到一个识别自然环境下[9]成熟香梨果实的深度卷积神经网络目标检测模型[10],通过给该模型输入不同样本下的香梨图像,模型总能输出准确的检测结果,给出图片中目标的位置和轮廓.综上所述,提出了基于Mask R-CNN[11]的深度网络模型,若仅使用COCO数据集预训练的模型识别水果,对于遮挡水果的识别效果不是很好.因此,本文提出使用大量的水果图片数据集先对Resnet[12]神经网络模型进行预训练,得到水果图片特征提取器,然后在预训练的基础上训练香梨图片数据集,最终得到香梨目标检测模型.
1 模型与方法
1.1 用于香梨检测的Mask R-CNN主要过程
为了训练出有效的香梨检测模型,本文将工作分为三个阶段,即预训练阶段、迁移学习训练阶段和测试阶段.如图1所示.首先在Kaggle数据集中以及网络上爬取并筛选出大量的水果图片(9 600张)对Resnet进行预训练,获得能识别水果图片的神经网络模型,然后在预训练模型的基础上加上Mask分支以及classifier分支来对自然环境下获得的香梨图片进行再次训练,从而获得识别自然环境下[13]成熟香梨的目标检测模型,最后对目标检测模型输入新样本数据从而得到目标检测结果.

图1 基于Mask R-CNN的香梨目标检测流程Fig 1 Target detection flow of fragrant pear based on Mask R-CNN
1.2 Mask R-CNN模型
Mask R-CNN同Faster R-CNN[14]具有同样的原理,相比于Faster R-CNN,Mask R-CNN是在Faster R-CNN的基础之上融合了FCN[15](全卷积网络)和FPN[16](特征金字塔网络)的多任务深度神经网络.相比于Faster RCNN中的ROI Pooling操作,Mask R-CNN提出了ROI Allign操作,对于目标的分类没有多大区别,但是在预测目标Mask的值时将会更加准确.如图2所示,Mask R-CNN分为三部分:1、Resnet特征提取部分;2、RPN部分;3、classifier分类网络部分.首先使用Resnet卷积网络提取图片的特征得到特征图(feature maps),将特征图送入RPN(区域建议网络)产生ROIs(感兴趣区),RPN首先对每个特征点产生anchor(锚点),然后通过softmaxloss训练判断每个anchor是否覆盖目标,通过smoothL1loss训练计算包含目标对象的anchor并对包含目标对象的anchor进行第一次边框修正.然后将RoIs和特征图送入ROI Allign layer,通过ROI Allign操作对每个RoI提取对应的特征并将特征的维度转化为特定的值.所有的特征将全部输入到全连接层进行结果共享,产生两个支路和一个掩模分支,同RPN原理一样,一条支路通过softmax回归计算目标属于K+1(背景)类的概率估算值;一条支路输出每个图像中K类目标检测框中的4个坐标值并对含K类目标的边框值进行第二次修正;掩模分支则以像素到像素的方式来对分割掩模进行预测,该Mask分支是卷积网络,它只对ROI分类器选择的正区域生成Mask.
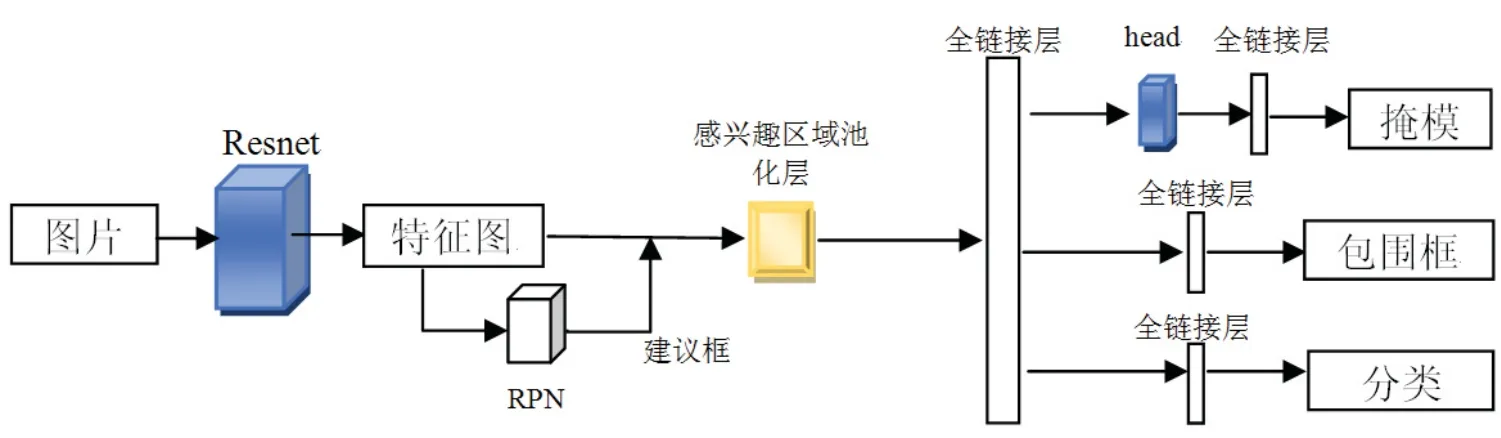
图2 Mask R-CNN原理结构图Fig 2 Mask R-CNN schematic diagram
1.3 输出层回归计算
Mask R-CNN的最终目标是得到三个输出结果:目标的种类、目标的检测框坐标以及目标的掩模.由于本文只对目标进行识别,不做分类,所以对于目标种类的函数损失相应的调小其权重值.Mask R-CNN是通过多任务的损失函数来计算感兴趣区域的输出结果,所以在RPN层中定义损失函数为:
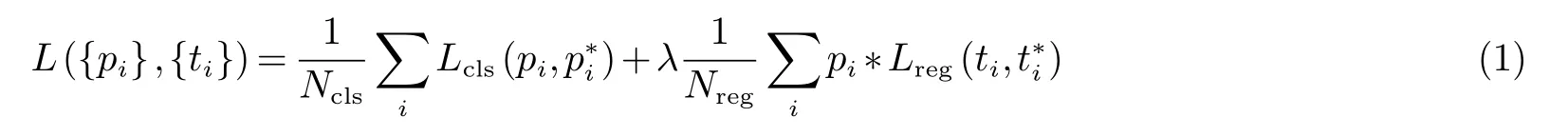
式(1)中λ 表示权衡分类和回归的损失,λ值越大表示越重视回归的损失,λ越小表示越重视分类的损失.Lcls为分类损失函数,它是两个类别的对数损失函数,公式表示为
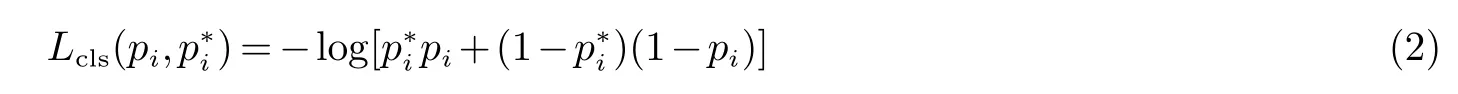
式(2)中i表示候选框的索引,pi表示候选框被预测为含有目标的概率,当候选框表示为正例时pi为1,反之则为0.Lreg为边框回归损失函数,公式表示为:

式(3)中ti是预测出边框的四个参数化构成的坐标向量,表示与正例相关的真实值边框.对于边框损失来说,四个坐标参数化表示公式为:
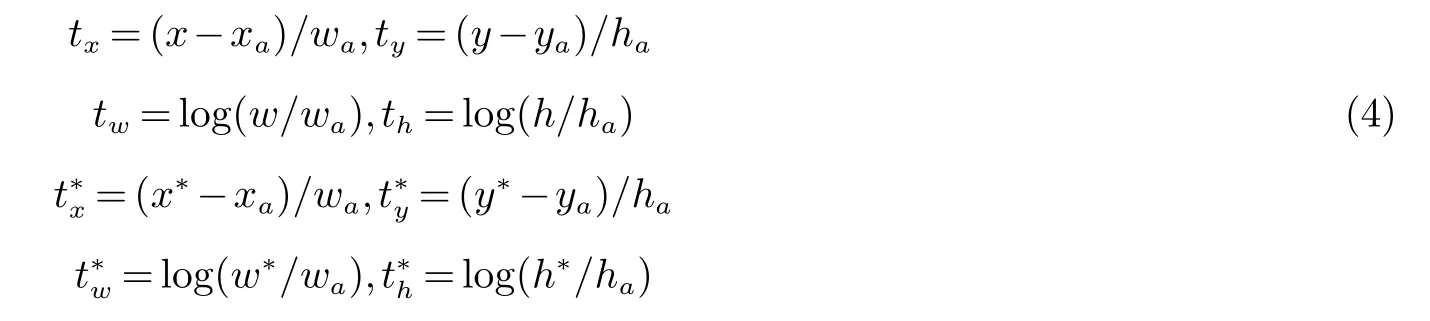
式(4)中x,y,w,h分别代表标记框的中心点坐标和宽高,x,xa,x∗分别代表预测框、anchor框、和真实框的x坐标(y,w,h同样).式(5)是式(3)中的R,R为鲁棒损失函数,公式为:
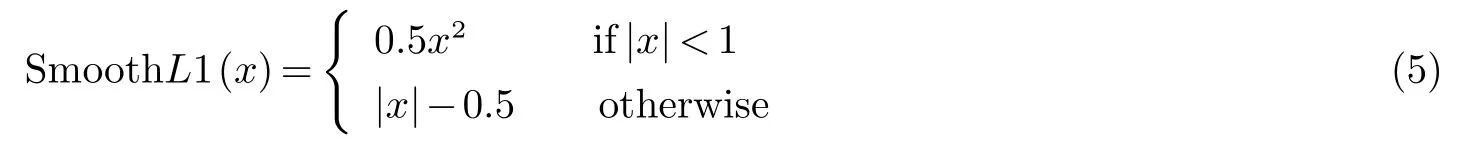
由于在ROI区域上加上Mask层,所以classifier分类网络部分的损失函数表示为:

在式(6)中Lcls和Lbox同RPN原理近似,其中Lbox和Lmask都是对含有目标的ROI起作用.Lmask为掩码误差,公式表示为:

式(7)中m2表示掩码分支对每个正例的ROIs产生的m∗m大小掩模,i表示当前ROIs的种类,K则表示物体的种类数目.在Mask R-CNN模型中,总的训练损失函数Lfinal可以描述为:
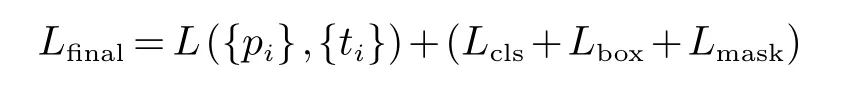
2 实验准备
2.1 数据获取
迁移学习[17,18]是训练深度神经网络模型常用方法,它通过在别人模型训练的基础上获得相应的权重,然后将这些权重应用到自己的模型中,从而在数据量较小的情况下,获得更准确的模型.COCO数据集中的水果图片数量较少,为了在预训练环节中获得更多的水果特征,使香梨检测模型在迁移学习中获得更多的香梨图片特征,因此通过选取水果图片对模型进行预训练的方式来实现.
为了得到大量的水果图片数据集,通过选取Kaggle数据集以及在网络上爬取水果图片把模糊的不符合要求的图片进行筛选共获得9 600张与香梨外形相似的水果图片,主要有苹果、柑橘、桃、山楂、草莓、猕猴桃等21类.
由于网上没有公开的香梨数据集,为了增加香梨识别模型的准确性,使模型更好的应用到实际中,通过实景拍摄进行数据采集,试验供试场地为库尔勒村民梨园,通过Canon EOS 70D相机在库尔勒梨园中对不同角度、互相遮挡的香梨进行拍摄,其中天气晴朗时的照片有1 000张,雨天和阴天时的照片共有1 000张,图片为JPEG格式,分辨率为2 736×1 824像素.为了测试模型的性能,又在网上爬取了200张香梨图片作为测试集.
2.2 数据增强
在现实中获得数据常常需要很高的代价,为此需要对数据集进行扩展[18],通过对照片的翻转、旋转、添加噪声等方法来扩展训练数据集.这些方法不仅可以增加数据量,同时可以模拟现实中的真实变化,提升模型的准确性以及泛化能力.通过对数据集进行旋转、翻转、添加椒盐噪声、添加高斯噪声等手段,最终得到4 500张香梨图片,其中训练集3 500张,测试集1 500张,而网上下载的图片全部用于测试集中.每张图片不小于2 736×1 824像素.
3 实验结果和分析
3.1 实验平台
实验基于tensorflow (版本为:1.10.0)深度学习框架,Python版本为3.5.2,实验硬件环境为:Intel(R)Core(TM) i5-4210U CPU @2.40GHz四核CPU,8GB内存,NVIDIA GeForce GT 820M 2GB显卡.Resnet网络的层数不同,其最终训练出的识别模型优劣性也不同,为此,分别选取了Resnet50、Resnet101和Resnet152来进行对比.
3.2 实验对比
如图3所示.在训练30批次后,a图中的resnet152网络结构总的损失函数值相比于resnet50网络和resnet101网络要小,同比于b图中的验证损失函数值,最终选择Resnet152作为Mask R-CNN的特征提取网络.图4为Mask R-CNN模型的检测效果图.
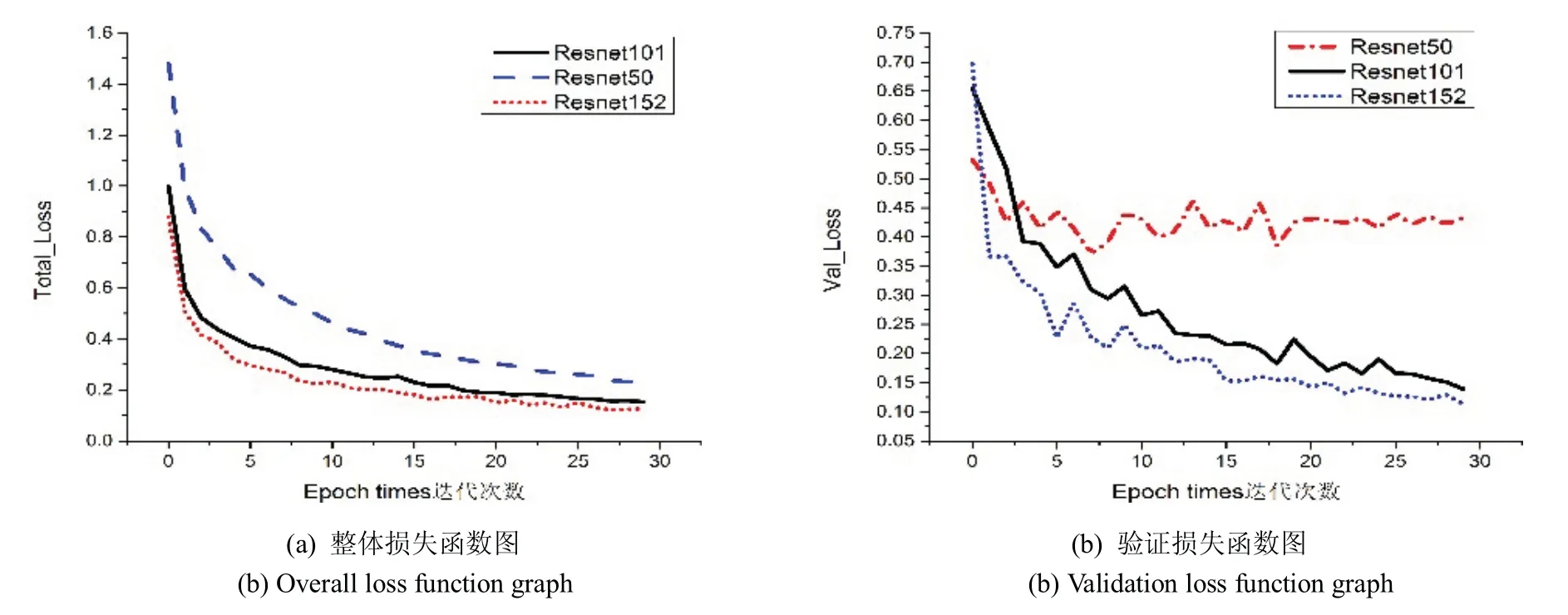
图3 Resnet卷积神经网络训练30批次后损失函数图Fig 3 Loss function diagram of Resnet convolution neural network after 30 batches of training

图4 Mask R-CNN模型的检测效果图Fig 4 Detection effect of Mask R-CNN model
为了验证本文提出的方法在香梨识别分割中的稳定性和有效性,通过分割精度[19]来评价Mask R-CNN模型对香梨图片分割的效果,公式为:
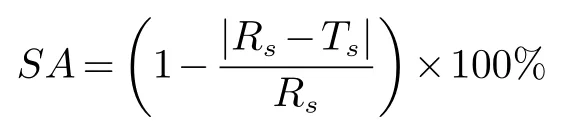
其中RS表示图像中目标的面积(像素个数),TS表示算法分割得到的图像面积,|RS−TS| 表示错误分割的像素点个数.如表1所示,选取部分果实目标像素进行统计,未添加噪声的图像平均分割精度值为98.02%,添加噪声的平均精度值为97.49%.其中表1目标8为被遮挡香梨所测出的像素值,由于被遮挡水果的数目众多,所以对被遮挡的香梨分割精度进行了统计.在未添加噪声的情况下,被遮挡水果的平均精度误差为95.28%,同未被遮挡的香梨误差不是很大,由此可以看出预训练的Mask R-CNN模型对于遮挡水果也有着较好的识别效果.
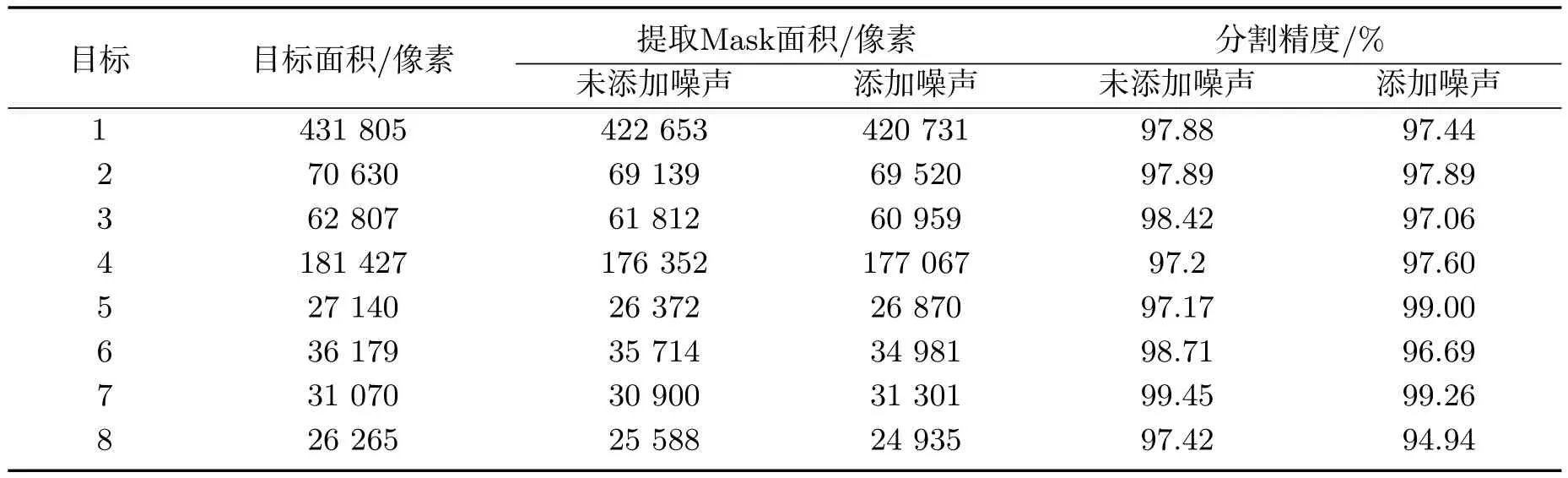
表1 不同参数下分割精度误差对比Tab 1 Comparison of human evaluation scores

图5 水果图片数据集预训练模型与COCO数据集预训练模型对比效果图Fig 5 Comparison of fruit image data set pre-training model and COCO data set pre-training model
图5为与用COCO数据集预训练模型做比较的结果,其中图5中的(c)(e)为分割后的二值图像,可以看出使用水果图片数据集预训练出的Mask R-CNN模型的分割结果要高于用COCO数据集作为预训练的结果.在无噪声的情况下用遗传算法+otsu分割算法和用COCO数据集预训练模型训练出的结果与本文方法做对比,从表2可以看出使用水果图片数据集预训练的Mask R-CNN模型在未添加噪声的情况下,平均分割精度为98.02%,添加噪声后为97.49%,精度误差仅增加了0.53%.用COCO数据集作为预训练的Mask R-CNN模型在未添加噪声的情况下,平均分割精度为93.72%,添加噪声后为92.28%,精度误差增加了1.44%.而遗产算法+otsu分割算法在未添加噪声的情况下,平均分割精度为85.23%,添加噪声后为79.55%,精度误差增加了5.68%.因此使用水果图片数据集预训练出的Mask R-CNN模型在香梨目标检测中取得较好的结果.

表2 不同方法下分割精度误差对比Tab 2 Error comparison of segmentation accuracy under different methods
4 结论
在目标分割上,提出了使用水果图片数据集对Mask R-CNN进行预训练,通过预训练后的分割模型对香梨目标进行分割,从而实现对香梨目标的准确识别.为了检测该模型的稳定性,通过对数据集增加噪声的方法来对模型进行测试,其中添加噪声的平均精度为98.02%,这与没有增加噪声的数据(97.49%)相比,误差仅增加0.53%,因此该模型具有很好的鲁棒性.
由于本文方法只对图片进行了研究与测试,获得了相对不错的结果,但是对于机器采摘来讲,实时准确的对目标进行定位和追踪才是最终的目标,所以下一步的研究目标是怎样实现实时的香梨目标检测与定位[20].
