不同数据集容量下的卷积神经网络图像识别性能
2019-12-03邢世宏施闻明任荟洁
邢世宏,施闻明,任荟洁
(1.海军潜艇学院,山东 青岛 266199;2.中国人民解放军92763部队,辽宁 大连 116000)
0 引 言
深度学习是近十年来人工智能领域取得的重要突破。它在语音识别、自然语言处理、计算机视觉、图像与视频分析、多媒体等诸多领域的应用取得了巨大成功。现有的深度学习模型属于卷积神经网络。神经网络的起源可追溯到20世纪40年代,曾在八九十年代流行。神经网络试图通过模拟大脑认知的机理解决各种机器学习问题。1986年,Rumelhart,Hinton和Williams[1]发表了著名的反向传播算法用于训练神经网络,该算法直到今天仍被广泛应用。
随着2012年Alex Krizhevsky的AlexNet[2]在ILSVRC2012[3](ImageNet大规模视觉识别挑战赛竞赛)中获得冠军,深度卷积神经网络在大数据及高速GPU计算的推动下迅猛发展,到2015年,ResNet[4]以Top5错误率为3.57%的成绩获取ILSVRC冠军;在人脸识别领域,DeepID[5]采用人脸辨识作为监督信号,在LFW[6]上取得了97%的识别率;在物体检测领域,以深度神经网络为基础的检测模型R-CNN[7],Fast RCNN[8],Faster R-CNN[9],R-FCN[10]在物体检测方面获得了很好的成绩,上述的深度神经网络都是基于像ImageNet一样的大数据样本才能获取较好的效果。此外,压缩的卷积神经网络如SqueezeNet[11],MobileNets[12]XNOR-Net[13], Deep compression[14],Deep Model Compression[15], Perforated CNNs[16],Binarized Neural Networks[17]等网络模型的训练都是建立在大数据的基础上,数据容量的多少成为能否训练出一个好模型的关键因素。但上述各领域应用的模型对模型的建立与数据集容量间的关系没有进行深入分析,仅停留在大数据集容量上。因此在采用深度学习方法解决现实问题时会出现需要多少训练数据的问题。目前关于训练网络所需的数据集容量的理论研究还处于空白状态,还没有相应的机器学习理论能解释两者直接的关系。本文在深入研究机器学习的相关理论后推导出深度卷积神经网络的复杂度与数据集容量之间的关系,并用实验验证了两者关系的有效性,为卷积神经网络的构建与训练提供相应的理论及经验依据。
1 数据集容量与卷积神经网络复杂度间的关系
1.1 VC维理论
机器学习相关理论中,虽然没有直接给出数据集容量与卷积神经网络参数量之间的关系,但明确阐述了VC维理论。根据Hoeffding[18]不等式:
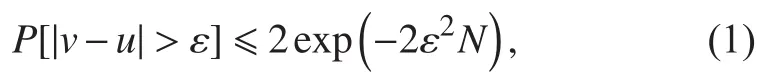
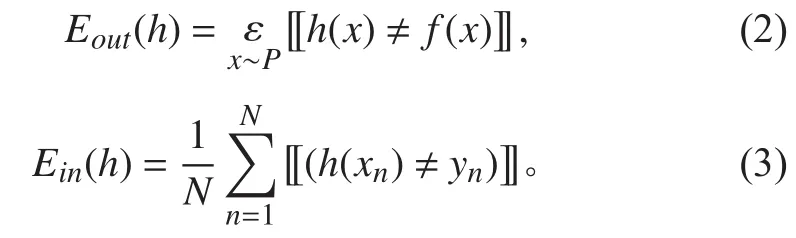
同理可以将式(1)表示为:

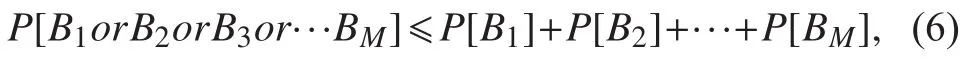
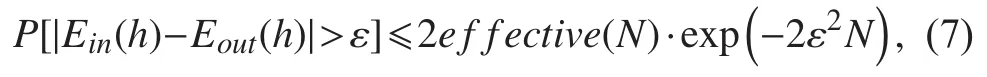
根据上述理论Vapnik-Chervonenkis[19]引入了Vapnik-Chervonenkis dimension(VC维)。VC维度量二元分类器的容量。VC维被定义为该分类器能够分类的训练样本的最大数目。VC维的边界表示如下:
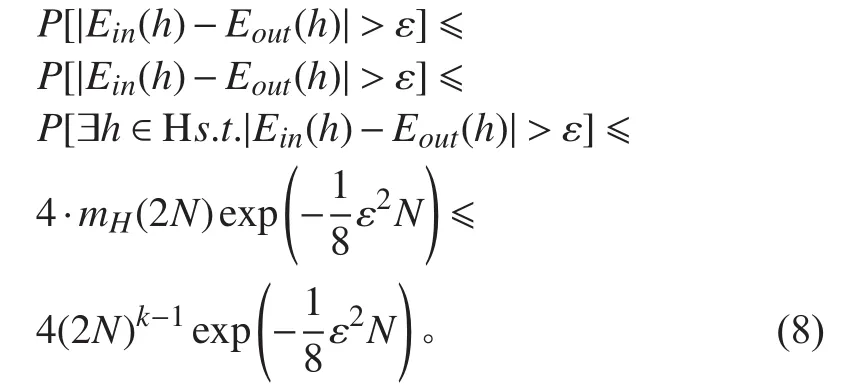
式(8)不等号右端即为VC维边界。
1.2 数据集容量与卷积神经网络参数量的关系
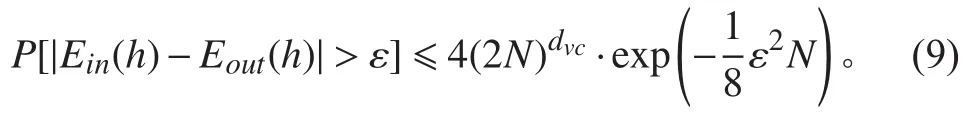

表1 B(N,k)边界值Tab.1 B(N,k)boundary value
表2边界值Tab.2 Nk-1 boundary value
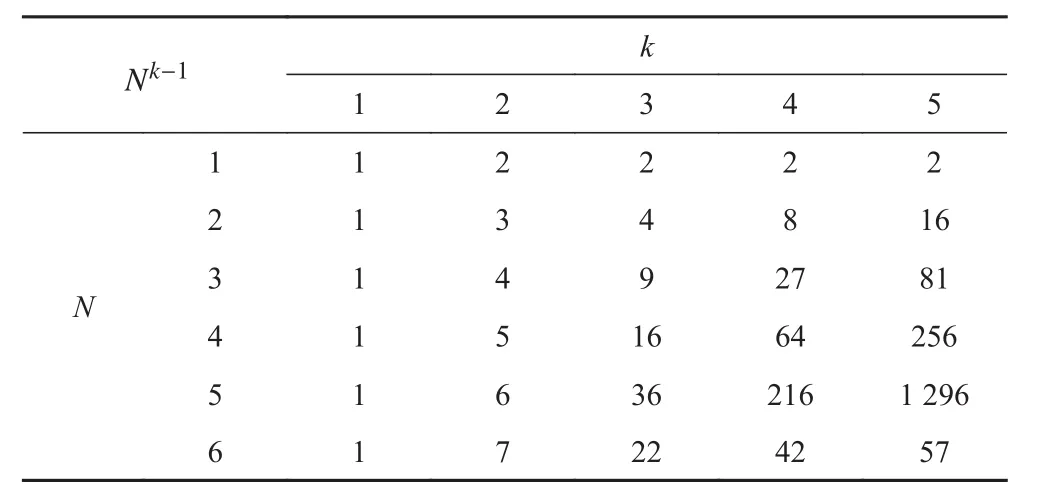
表2边界值Tab.2 Nk-1 boundary value
images/BZ_195_313_525_376_558.pngk 1 2 3 4 5 N 1 1 2 2 2 2 2 1 3 4 8 16 3 1 4 9 27 81 4 1 5 16 64 256 5 1 6 36 216 1 296 6 1 7 22 42 57
由于深度神经网络特征是稀疏的,并且网络中包含了规范化及特征选择技术,实际训练模型过程中真实输入的特征数应少于原始特征数量,因此在估算深度神经网络在训练中所需的数据容量时,可以根据网络隐藏层的参数量来代替,并且通过计算时,容量为的数据集可以满足网络模型的需求,然而实际中有很多领域很难获取如此大的数据集,并且的容量太宽松。在此基础之上,通过实验来紧缩数据容量,得到一个比更紧凑关系。
2 构建卷积神经网络
受Hubel和Wiesel[20]对猫视觉皮层生理研究启发,有人提出卷积神经网络(CNN)[21],Yann LeCun[22]最早将CNN用于手写数字识别。卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和子采样层构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。
构建网络需要上述相关层的组合,可能相似的层会出现多次,具体需要多少层或者需要什么功能的层与网络的复杂度、解决问题的复杂度相关,目前还没有针对构建网络层数的相关理论,所有网络的搭建停留在经验的基础上。本文在研究数据集容量与卷积神经网络参数量之间的关系时也是在LeNet,AlexNet的经验基础上进行的。
2.1 不同容量的数据集
由于卷积神经网络的训练对计算机的硬件性能要求较高,因此考虑到实验条件的限制,这里选取手写数字识别的数据集mnist[23]及Cifar10[24]。Mnist是由Google实验室的Corinna Cortes和纽约大学柯朗研究所的Yann LeCun建立的手写数字数据库,训练库有60 000张手写数字图像,验证库有10 000张,另外通过其他途径获取了包含有10 000张的测试集,相应的各标签下的容量如表3所示,数据集中的部分数据图像如图1所示。
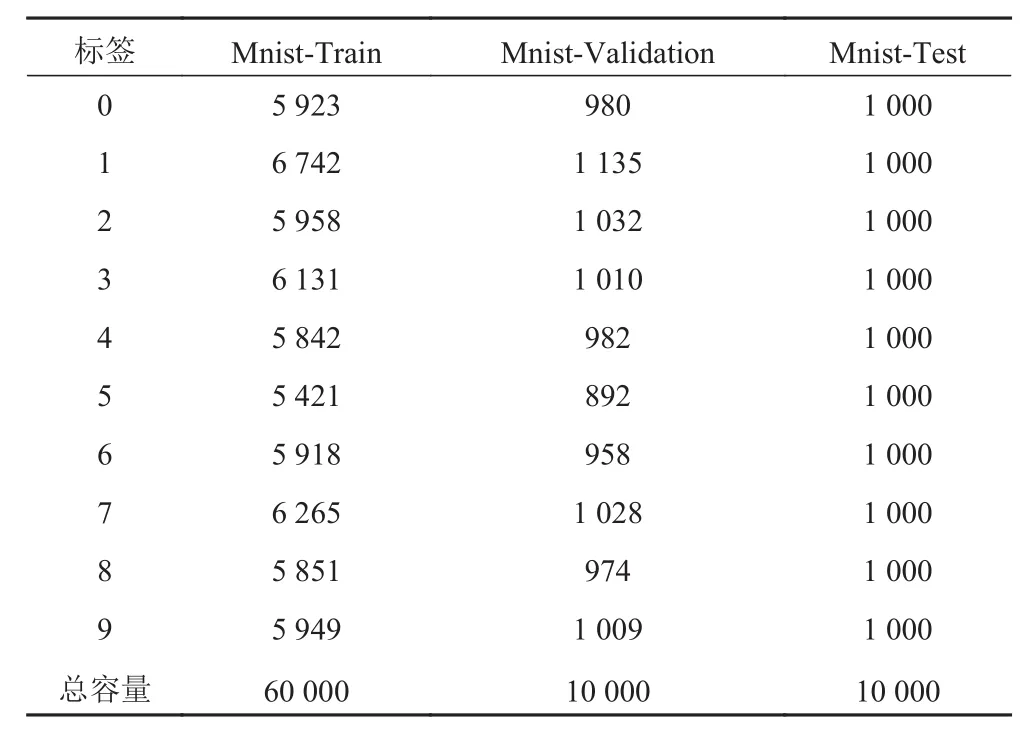
表3 Mnist数据集容量Tab.3 Mnist data set capacity

图1 Mnist数据集Fig.1 Mnist data set
Cifar10数据集共有60 000张彩色图像,尺寸为32*32,分为10个类,每类6 000张图。这里面有50 000张用于训练,构成了5个训练批,每一批10 000张图;另外10 000用于验证,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1 000张。剩下的随机排列组成了训练批。一个训练批中的各类图像数量并不一定相同,总的来看训练批,每一类都有5 000张图,部分Cifar10图像如图2所示。
2.2 构建卷积神经网络DigitNet和Cifar10Net
根据手写数字识别及Cifar10识别的复杂度,并参考LeNet及AlexNet网络构建经验,搭建了DigitNet及Cifar10Net网络,网络结构包括输入层、卷积层、ReLU、Pooling层、全连接层、Softmax层、输出层,结构如表4和表5所示。给出相应数据集容量及网络模型的参数量的比值,如表6所示。

图2 Cifar10数据集Fig.2 Cifar10 data set
3 数据集容量与卷积神经网络图像识别的关系
3.1 不同数据集容量对DigitNet识别性能的影响
网络模型的训练收敛速度很大程度上取决于bachsize,因此为了使网络模型在不同容量的数据集上更快收敛,将DigitNet在训练数据容量为57 000到6 000之间的bachsize设定为256,容量为5 100到600间的bachsize设定为20。在不同容量的训练集中分别训练DigitNet的3个模型,训练得到的准确率如表7所示。

表4 DigitNet卷积神经网络Tab.4 DigitNet convolutional neural network

表5 Cifar10Net卷积神经网络Tab.5 Cifar10Net convolutional neural network
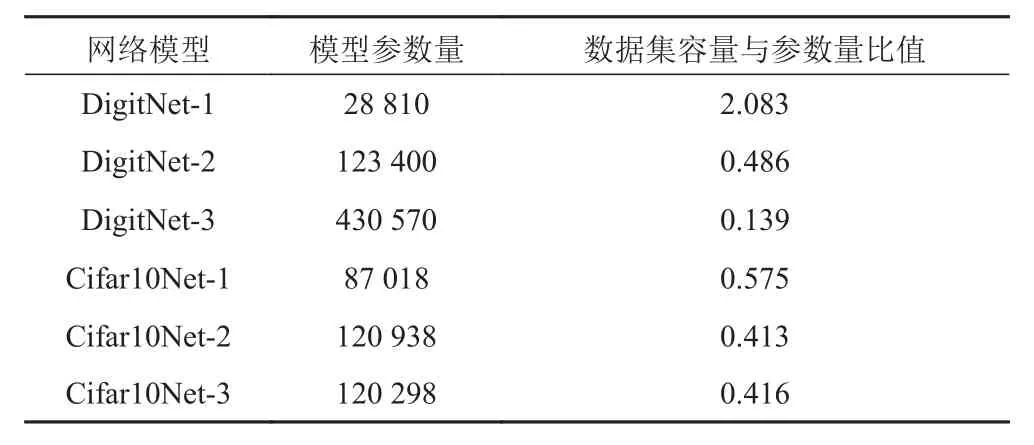
表6 数据集容量与参数量比值Tab.6 Ratio of data set capacity and parameter amount

表7 不同训练数据集下DigitNet模型的识别准确率Tab.7 The recognition accuracy of digitnet model under different training data sets
3个DigitNet网络模型分别在不同容量的数据集上训练并在验证集及测试集上分别实验了识别性能,根据表8的识别正确率绘制了不同训练数据集容量与网络模型识别正确率之间的关系曲线,如图3所示。

图3 不同训练数据集下DigitNet模型的识别准确率曲线Fig.3 The recognition accuracy curve of digitnet model under different training data sets
从表7及图3中可以看出,随着训练数据容量的减少,验证集及测试集上的识别正确率呈现下降趋势,同时可以看出容量超过20 000的识别情况并没有太大的变化,在验证集上的识别率几乎与最大容量时相同,只是在测试集上表现不太稳定,但总体上没有超过0.1。随着容量的继续减少,到6 000到5 100时出现了一个较大的波动,这是因为在这里调整了batchsize的大小,从调整完之后可以看出,数据集容量减少到3 200时识别率才呈现出明显的下降趋势。
3.2 不同数据集容量对Cifar10Net识别性能的影响
Cifar10只有训练集及验证集,没有收集相关的测试集,因此训练好的模型只在验证集上进行测试,训练过程中设置batchsize为100,测试的结果如表8所示。
根据训练得到的测试数据,绘制训练数据容量集与识别准确率曲线如图4所示。从图中可以看在容量为17 500时,曲线下降趋势开始明显,在容量50 000到17 500之间识别率没有大的变化,只是有较小的波动。
在上述进行的实验中发现,DigitNet虽然在调节batchsize时曲线有较大的波动,但这种波动可以通过调节batchsize的大小来获取较好的训练网络,也就是说真正由训练集容量导致识别率快速下降的容量为3 200到2 400的时候,如表7,图3所示。在Cifar10Net训练识别过程中,由于没有调整batchsize的大小,因此在识别过程中没有出现大的波动,但是随着训练集容量的变化,在容量为12 500到10 000时识别率下降开始明显。根据上述分析分别选取DigitNet与Cifar10Net识别曲线上容量为3 200及17 500两个容量值作为网络在保持较好识别率的容量下限,并计算其与对应的模型参数量的比值,如表9所示。
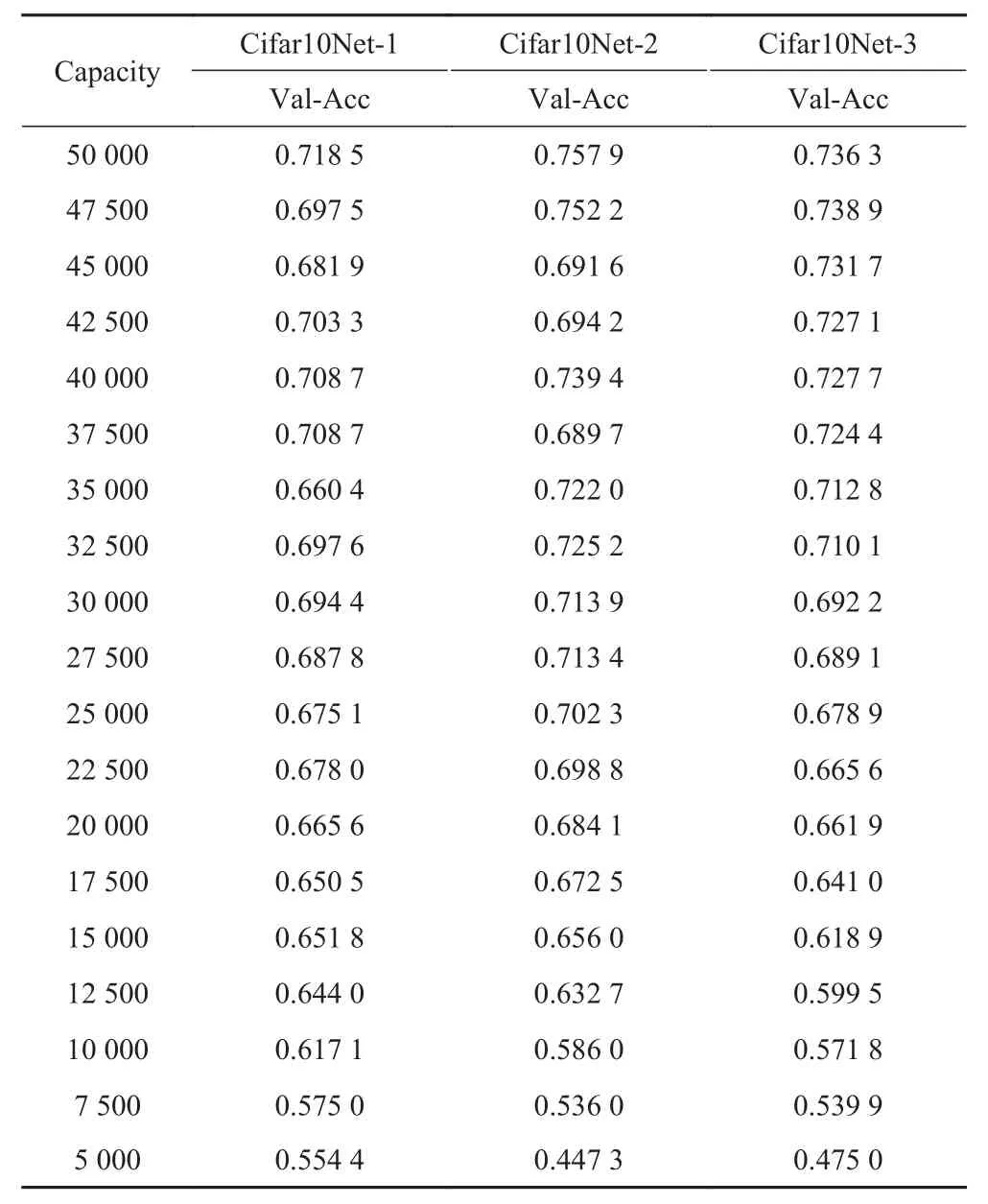
表8 不同训练数据集下Cifar10Net模型的识别准确率Tab.8 The recognition accuracy of cifar10net model under different training data sets
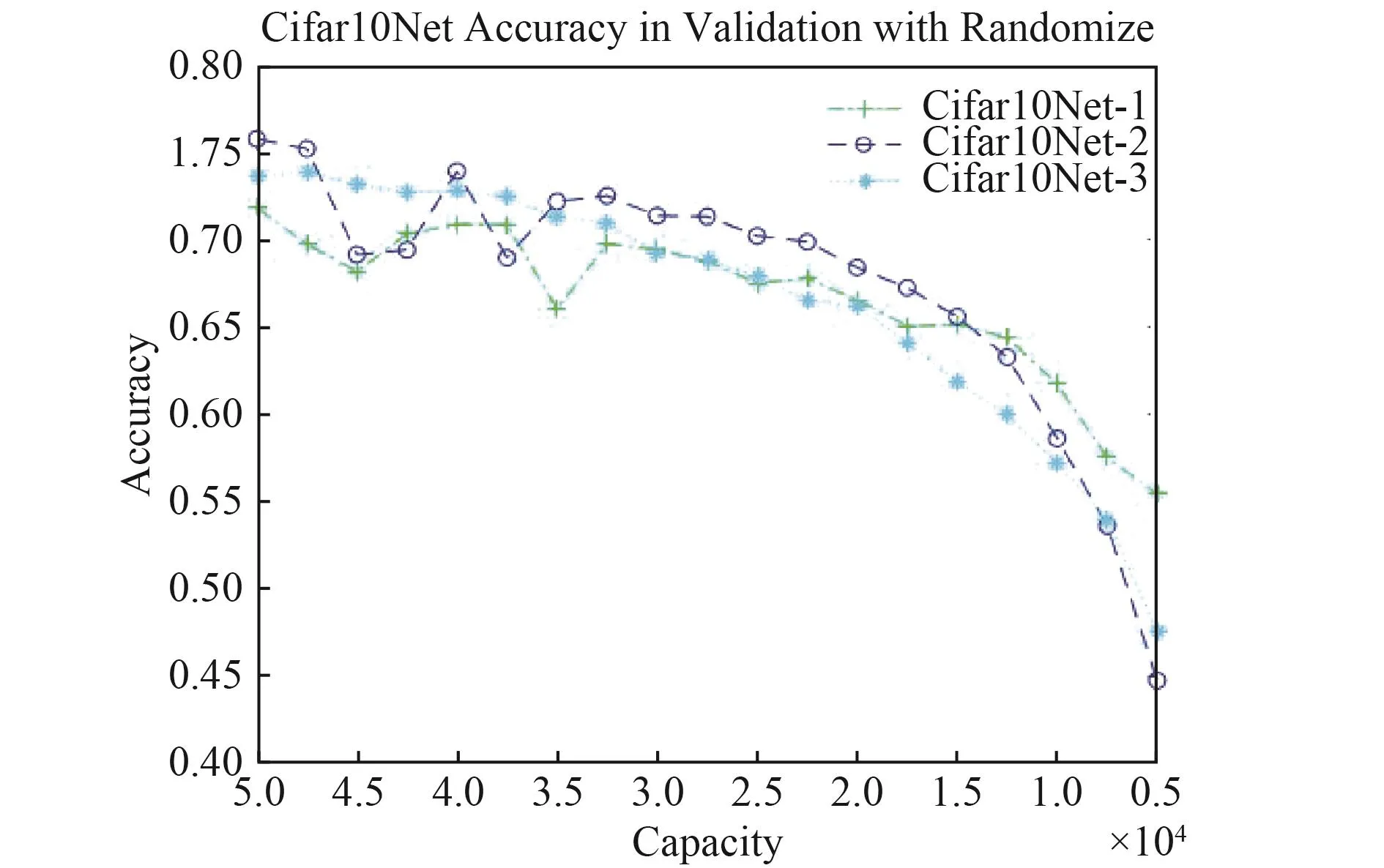
图4 不同训练数据集下Cifar10Net识别准确率曲线Fig.4 The recognition accuracy curve of Cifar10Net model under different training data sets
通过mnist及cifar10识别实验中发现有实际数据量没有达到10 000时也可以获取较好的结果,这是因为实际给出的训练样本容量较为宽松。因此实际中使用深度卷积神经网络时可以根据解决问题的复杂程度准备相应的训练数据集。从本文的实验数据表8可以推断出,在解决较为简单的识别问题时,数据集容量的下限为,如果解决问题的复杂度较大时可以适量增加数据集容量。
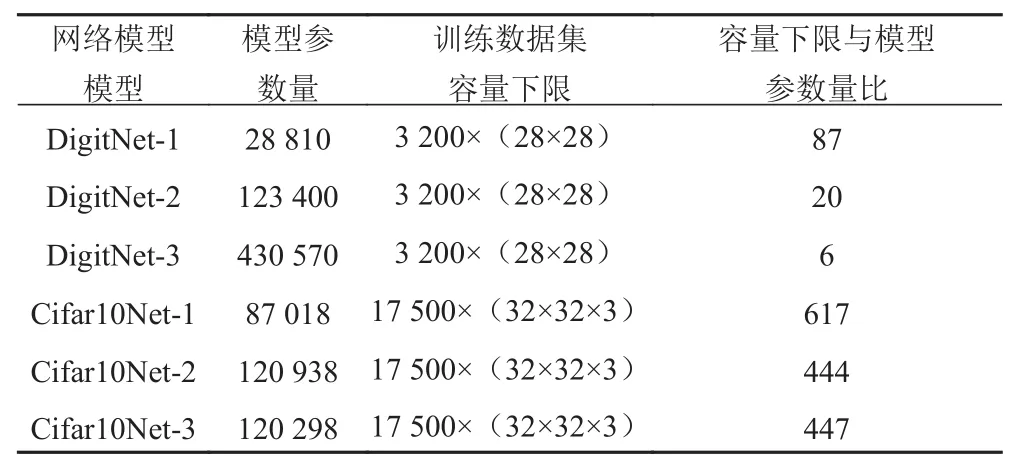
表9 容量下限与模型参数量比Tab.9 The ratio of lower limit of capacity and model parameters
4 结 语
本文根据Vapnik-Chervonenkis的VC维理论,得到了对应于二分类的宽松数据集容量为。然后根据LeNet及AlexNet网络的搭建经验,搭建了适合研究mnist及cifar10数据的DigitNet及Cifar10Net网络,通过6个不同的网络在不同容量数据集的训练后,测试了对应网络模型的识别率,绘制了训练数据集容量对构建的卷积神经网络识别性能的影响曲线,从中发现,卷积神经网络的训练并不是训练数据越多越好,在一定模型下,训练数据也没有必要达到模型参数量的10 000倍,根据VC维理论,过于宽松,因此实际中无需的训练数据。本文实验结果给出了在解决mnist及cifar10数据集识别的问题无需很大的数据集容量,仅需要模型参数量的10倍为下限即可达到很好的识别效果。本文为无法获取大量数据情况下使用卷积神经网络解决实际问题提供了一些实践指导,也为接下来的舰船识别提供了相应的依据。
