Human Behavior Classification Using Geometrical Features of Skeleton and Support Vector Machines
2019-11-26SyedMuhammadSaqlainShahTahirAfzalMalikRobinakhatoonSyedSaqlainHassanandFaizAliShah
SyedMuhammadSaqlainShah,TahirAfzalMalik,RobinakhatoonSyedSaqlainHassanandFaizAliShah
Abstract:Classification of human actions under video surveillance is gaining a lot of attention from computer vision researchers.In this paper,we have presented methodology to recognize human behavior in thin crowd which may be very helpful in surveillance.Research have mostly focused the problem of human detection in thin crowd,overall behavior of the crowd and actions of individuals in video sequences.Vision based Human behavior modeling is a complex task as it involves human detection,tracking,classifying normal and abnormal behavior.The proposed methodology takes input video and applies Gaussian based segmentation technique followed by post processing through presenting hole filling algorithm i.e.,fill hole inside objects algorithm.Human detection is performed by presenting human detection algorithm and then geometrical features from human skeleton are extracted using feature extraction algorithm.The classification task is achieved using binary and multi class support vector machines.The proposed technique is validated through accuracy,precision,recall and F-measure metrics.
Keywords:Human behavior classification,segmentation,human detection,support vector machine.
Abbreviations
SVM:Support Vector Machines GMM:Gaussian Mixture Model
RBF:Radial Basis Function HB:Human Blob
HBH:Human Blob Height HBW:Human Blob Width
FHO:Fill Holes inside Objects HDA:Human Detection Algorithm
FEA:Feature Extraction Algorithm UL:Upper Left
UR:Upper Right BL:Bottom Left
BR:Bottom Right
1 Introduction
Surveillance is the monitoring of behaviors,activities or other changing information in a secret manner.The surveillance can be carried out in many different ways i.e.,biometric surveillance,camera surveillance,aerial surveillance and computer surveillance,etc.[Lyon(2010)].Prior to the automatic video surveillance,human supervision was needed to monitor the camera footages that not only needed more effort but remained lesser efficient.During the last decade,automatic surveillance has been focused by researchers involving development of computer vision based algorithms for analyzing the abnormal events from videos.Automatic surveillance may be on different crowded areas like airports,shopping malls,stations and private residences for recognizing and monitoring threats,anticipating and preventing the criminal activities.The main tasks involved in visual surveillance include object detection,tracking and behavior classification,widely studied in computer vision.During the last few years,researchers have achieved progress in this,however yet there exist open issues that are needed to be addressed prior to implementation of a robust video surveillance system.A number of visual surveillance systems have been developed for recognition of abnormality in the crowded scenes,by analyzing crowd flow.A little work is available in recognizing individual’s behavior from crowd.Some of the abnormal events may not change the overall behavior of the crowd but may affect only some of the individuals(two or three persons)in the crowd.The aim of this study is to recognize the individual’s normal and abnormal behavior in the crowd and present a real-time surveillance system.
The proposed technique presents solution of classifying normal and abnormal behaviors of the human in context of recognizing abnormal activities in the crowded scenes.The proposed solution is addressed for constrained environment single and fixed monitoring camera.Rest of the paper is organized as follows:Section 2 presents work related to the proposed research,Section 3 contains proposed methodology,while Section 4 is dedicated to experimental results.Finally,Section 5 concludes the presented research.
2 Related work
Human behavior classification can be applied in many real-time situations.Andrade et al.[Andrade,Ernesto,Fisher et al.(2006)] presented an approach to detect normal and abnormal events from crowd in context of emergency situations.The experimental results showed that presented models were quite efficient in detecting simulated emergency situation in a dense crowd.In Hsieh et al.[Hsieh and Hsu (2007)],Hsieh and Hsu proposed a simple and rapid surveillance system that achieved human tracking along with classification between normal and abnormal behaviors.Abnormal behaviors included climbing,falling,stopping,and disappearing.Experimental results showed that the system dealt with occlusion and moving objects tracking in an efficient manner.To detect and monitor the human aggressive behaviors,Chen et al.[Chen,Wactlar and Chen (2008)]presented an approach using local binary descriptor for human detection.The proposed approach modelled the actions of arm,body,and the object together.The top 10 retrieval results include about 80% aggressive behaviors,which is much better than the random accuracy of 36.2%.Kiryati et al.[Kiryati,Raviv,Ivanchenko et al.(2008)] presented a novel approach for real time detection of abnormal event.This approach is well suited for applications where limited computing power is available near the camera for compression and communication.The experimental results showed that the system is reliable for the real-time operation.The abnormal action videos on which system was tested include running,jumping,and grass crossing actions.In Wang et al.[Wang and Mori (2010)],authors proposed human action recognition based on topic models.Yogameena et al.[Yogameena,Veeralakshmi,Komagal et al.(2009)] worked on a real-time video surveillance system,classifying normal and abnormal actions of persons in crowd.Abnormal actions include running,jumping,bending,walking,waving hand and fighting.RVM (Relevance Vector Machine)is used to control huge number of vectors problem.G´arate et al.[Garate,Bilinsky and Bremond (2009] presented an approach for crowd event recognition that used HOG (Histogram of Gradients).The events included crowd splitting,formation,walking,running,evacuation etc.This approach dealt with overall behavior of the crowd for recognizing crowd events.There are still some errors in the recognized events.This technique needs to improve the threshold computation at the level of scenario models.In Zweng et al.[Zweng and Kampel (2010)],research is related to the unexpected behavior recognition in highly dense density crowded scenes.The actions recognized by the system include running and fall detection.Lin et al.[Lin,Hsu and Lin (2010)] recognized human actions using NWFE (Nonparametric Weighted Feature Extraction)based histogram.Research classified ten actions including running,jumping,walking,bending etc.To achieve the lower time complexity for a huge sized dataset,dimensionality was reduced using PCA.Popoola et al.[Popoola and Wang (2012)] presented a critical survey to identify the limitation in existing techniques of abnormal human activity analysis.They have discussed the techniques from the methodologies to applications.Authors Chaaraoui et al.[Chaaraoui,Climent-Pérez and Florez-Revuelta (2012)] presented a review over human behavior analysis.Li et al.[Li,Han,Ye et al.(2013)] used sparse reconstruction analysis (SRA)for detection of abnormal behavior.They obtained normal dictionary set for normal behaviors through control point features of cubic B-spline curves and used minimal residue to classify the normal and abnormal behaviors.Cristani et al.[Cristani,Raghavendra,Del Bue et al.(2013)] analyzed human activities on the basis of social signal processing that deals with social,affective,and psychological literature notions.Jiang et al.[Jiang,Bhattacharya,Chang et al.(2013)] provided a review over the techniques dealing with high-level event recognition in unconstrained videos.The idea behind their review was to tackle the problem of analyzing the videos developed by the non-professionals and the videos widely available over the web.Weiyao et al.[Lin,Chen,Wu et al.(2014)]proposed an algorithm which takes a scene from video and represents the video in the form of the network architecture.They termed it as network-transmission-based (NTB)algorithm.The presented algorithm represented scenes as nodes and edges represented the correlation between the scenes.They used their model for classifying the abnormal events.Tran et al.[Tran,Gala,Kakadiaris et al.(2014)] proposed a framework for group activity analysis.They took the liberty of graph by representing human as nodes of the graph and edges as interaction between those humans.Bag-of Words were used as features and SVM was used for classification.Elloumi et al.[Elloumi,Cosar,Pusiol et al.(2015)] in their paper presented different features for recognizing the human activities in unstructured environment.They have used unsupervised learning and tested their technique over the video dataset of medical field for patients monitoring suffering from Alzheimer’s and dementia.Vishwakarma et al.[Vishwakarma and Kapoor (2015)] proposed a hybrid classifier for analyzing the human activities from videos.The presented classifier used K-NN and SVM at its baseline and authors named it SVM-NN.They tested it over Weizmann,KTH,and Ballet Movement datasets.Eweiwi et al.[Eweiwi,Cheema and Bauckhage (2015)] proposed a new research for classifying human actions in still images.They used local descriptive from images which are supported by their presence in particular areas evident through different videos.Experimental results showed promising outcomes.Vignesh et al.[Ramanathan,Huang,Abu-El-Haija et al.(2016)] proposed their technique for recognizing multi-person event recognition.They used recurrent neural network for tracking individual humans and then model supported the extraction of individuals responsible for the activity.On the next level they again used recurrent neural network for classification of activity.Yogameena et al.[Yogameena,Komagal,Archana et al.(2010)] classified actions like person carrying a long bar,walking,bending and waving hand in the crowd.Human features were extracted using star skeletonization [Fujiyoshi,Lipton and Kanade (2004)] which gives five extreme points of the human skeleton and motion cues.These features are then classified using SVM(Support Vector Machine)classifier.Human body is treated as the interconnections of the five rigid bodies [Guo,Li and Shao (2018)].The motion of each part was taken as discriminating factor to distinguish between the actions.Bag of features of each part was calculated and the classification was performed through SVMs.Human action classification,involving upper and lower part of the human body,is presented [Lai and Lau (2018)].The main features were based on the detection of wrist,shoulder and elbow points.K-means clustering was used to imply the classification task.
3 Proposed methodology
The proposed methodology classifies the normal and ab-normal human actions in a thin crowd.The graphical representation of the proposed research is shown in Fig.1.
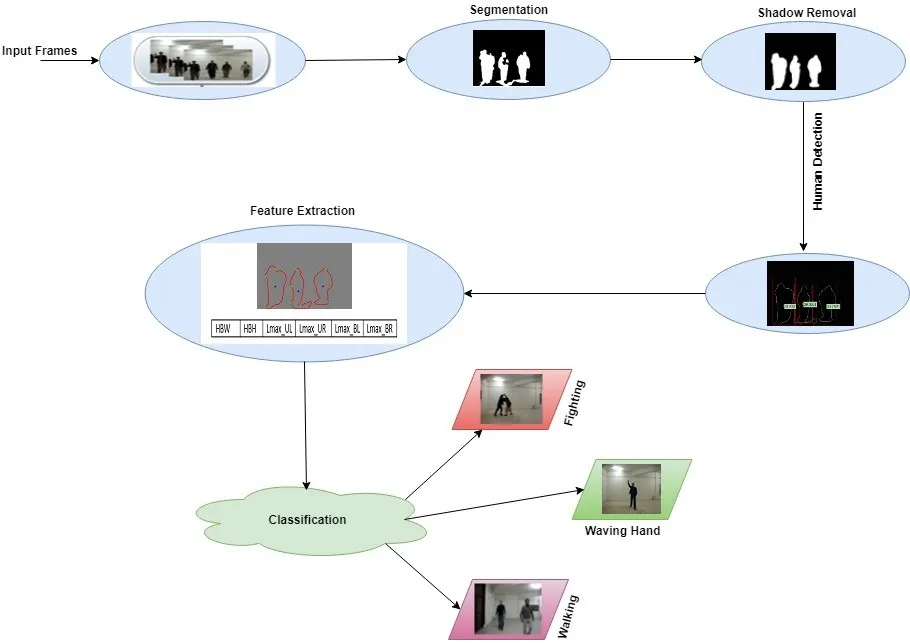
Figure1:Flow diagram of the proposed technique
3.1 Segmentation and post-processing
Segmentation of foreground from the complex background is achieved by using Gaussian Mixture [Atev,Masoud and Papanikolopoulos (2004)].It segmented the foreground moving pixels by finding the probability of each pixel in the image.Every new pixel value is checked against the existing K Gaussian distributions,until value is less than the standard deviation.

Likelihood of all the unmatched components is updated and if match is found for any of the K distribution then mean,covariance and likelihood of k matched components are updated.If c matches a mixture component,Mk,it must be determined that it is a part of the background or foreground.Given a thresholdB∈[0…..1],Mkis considered a part of the background if

Morphological dilation using square as a structuring element is applied over the segmented regions.The size of the square is kept as 7 pixels resulting 49 neighbourhood for dilating the segmented regions.Over the dilated regions,we have applied Gaussian filter for noise reduction.Unwanted pixels are removed and marked as part of background.Holes within the blobs are filled using FHO algorithm followed by retaining the larger blobs than the specified size ones.

Algorithm 1:Fill Holes inside Objects (FHO)INPUT:Segmented and Processed Image having Blobs OUTPUT:Image with filled holes within Blobs 1:Find the boundries of processed objects.2:Build boundry set BOS1,BOS2,….,BOSp for each object OB1,OB2,….,OBp.3:Find minimum and maximum along horizontal and vertical for each set.i.e,BOSjxmin,BOSjxmax,BOSjymin and BOSjymax.1≤j≤p 4:For each BOSt:1≤t≤p 5:∃ OBS such that OBS ⊆ OBt i.e,if ((BOSSxmin>BOStxmin)^(BOSSxmax<BOStxmax)^(BOSSymin > BOStymin)^(BOSSymax < BOStymax))6:OBS is a hole within OBt 7:For each point pm ∈ OBS 8:If pm is background 9:Mark pm as foreground 10:end for 11:end for
3.2 Shadow removal
The foreground extracted from the segmentation is subject to shadow detection [Khatoon,Saqlain and Bibi (2012);Kelly,Agapito,Conaire et al.(2010)] where first frame of the video sequence is considered as the background image.A color brightness difference value D is calculated as follows:

where Dgbis the distance between the current pixel and the background pixel which is normalized by gb space;background brightness is represented by VBGand Vcurris the brightness of current pixel.If color/brightness level has difference value D<0.5,then the foreground is marked as a shadow pixel and gets discarded.Post-processing is then applied to the resultant image for suppressing the noise and fill the holes in silhouette.The segmented image is reconstructed after marking the shadow pixels.
3.3 Human detection
Human detection is achieved by using local HOGs and SVM.The local HOGs are calculated over the four partitioned areas of the window having segmented object.The details of the proposed method are presented in human detection algorithm (HDA).

Algorithm 1:Human Detection Algorithm (HDA)INPUT:Segmented Image SI having n Blobs OUTPUT:k Blobs detected as Human INPUT:Segmented Image SI having n Blobs OUTPUT:k Blobs detected as Human 1:For each blob Bj :1 ≤ j ≤ n.2:Find enclosed rectangle around Bj by finding points(xmin ,ymin) , (xmax ,ymin) , (xmin ,ymax) , (xmax ,ymax)lying over Bj.3:Calculate center of rectangle around Bj by using xrc = xmax-xmin and yrc = ymax-ymin 2 2 4:With reference to (xrc ,yrc)divide Bj into four Regions Ri :1 ≤ i ≤ 4 i.e.,Upper Left defined by {(xmin ,ymin) , (xrc ,ymin) , (xmin ,yrc) , (xrc ,yrc)},Upper Right defined by {(xrc , ymin) , (xmax ,ymin) , (xrc ,yrc) , (xmax ,yrc)},Bottom Right defined by {(xrc ,ymin) , (xrc ,yrc) , (xmin ,ymax) , (xrc ,ymax)} and Bottom Left through {(xrc ,yrc) , (xmax ,yrc) , (xrc ,ymax) , (xmax ,ymax)}5:For each Ri :i ≤ 1 ≤ 4 6:Find Oriented Descriptors by using HOG method.Parameters used in HOG are:Size of region:W × H where W = xrc - xmin and H = yrc - ymin.1-D Derivative masks used are:images/BZ_104_984_2670_1157_2726.png and images/BZ_104_1246_2589_1331_2711.png

Cell size:8 × 8 Block Size:2 × 2 Block overlap:1 × 1 Weighted Gradients are used for each pixel orientation.7:Create 1-D vector vi having descriptors obtained through HOG,corresponding to Ri 8:end for 9:vi :1 ≤ i ≤ 4 are provided to 4-SVM classifiers each classifying one of four UL,UR,LL and LR.If three of the regions are classified as human parts.We classify blob as human.10:end for 11:Blobs identified as humans are kept enrectangled.Non Humans are turned as background.
Each of the segmented blob,Bj:j>=1<=n,is provided as an input to the HAD that finds the minx,minyand maxx,maxypoints of the rectangle enclosing Bj.By finding the centroid of each of the enclosing rectangle,they are divided into four sub rectangles with reference to the center points.HOG is calculated for each of the four sub rectangles and their histograms are fed to the corresponding SVMs trained over upper left(UL),bottom left(BL),upper right(UR)and lower right(LR)regions.All the four trained SVM models produce an output whether the region represents a human part or not.If three out of the four or all the models produce positive response,the blob in the rectangle is classified as human.Otherwise,it is a non-human is made part of the background.
3.4 Feature extraction
The task of feature extraction is accomplished by proposing feature extraction algorithm(FEO).It takes each of the potential human blob as input and divides it into four regions which are computed with reference to the centroid of the blob.The extreme points in each of the four regions are computed which are then combined with the width and height of the blob to form a 6-dimenttional feature vector.The FEO is presented as:

Algorithm 2:Feature Extraction Algorithm (FEA)INPUT:Image Having k-Human Blobs OUTPUT:k-vectors having feature set for each Identified Human 1:For each human blob HBk :1 ≤ k ≤ m,m are total number of blobs identified as human.2:Find Width (HBWk)and Height (HBHk)using xbmax - xbmin and ybmax - ybmin respectively,where xbp ,ybp are point lying in HBk.3:Centroid of Human blob is calculated using Xcb = 1 i=1 4:Divide the human contour in four sub-regions i.e.,Upper Left(UL),Upper Right(UR),Bottom Left(BL)and Bottom Right(BR).5:For each sub-region SRq ∈ { UL,UR,BL,BR } ⊆ { HBk } ∑ yi ∑ xi n i=1 and Ycb = 1 n n n

6:Calculate distance of the centroid from each boundary pixel using:d = (xi -Xcb) 2 + (yi -Ycb) 2 resulting a 1-D discrete signal.7:1-D discrete signal is smoothed using low pass filter for noise reduction 8:Local maxima LMq in 1-D discrete signal is taken as extreme points which is detected by finding zero-crossing difference function δ (i)= d^ (i)- d^ (i - 1)9:end for 10:Create a 1-D vector vk corresponding to HBk having HBWk ,HBHk and LMq where q ∈ { UL,UR,BL,BR }.11:end for
3.5 Classification
In the proposed technique,Support Vector Machines (SVM)are used for the action classification.The solution to the problem of multi-class is achieved through the combination of multiple binary class SVMs.The decision functions for the binary-class linear SVMs are represented by (u.fsj+m)≤-1 if cj=-1 and (u.fsj+m)≥1 if cj=1.The two relations can be combined to cover both the cases i.e.,cj(u.fsj+ m)≥1 wherecrepresents the class,fsis the input feature set,urepresents weight and mis the margin.Decision function for the non-linear classification is represented asf(fs)=u.Φ(fs)+m.This is presented as we are dealing with the research problem having input feature subset instead of a single dimensional problem and we have performed experiments with SVM using other modalities than linear functions.In order to have convergence for the non-linearity,SVM kernel functions are widely used.In a kernel-based SVM,umay be represented asn is number of samples.Decision function for a non-linear classification problem having multidimensional feature set can be represented as:

where Φ(sj).Φ(s)is defined as the kernel function and denoted asKF(s,sj).By replacing Φ(sj).Φ(s)byKF(s,sj)the decision function is given as:

In order to implement non-linear classification task,radial basis function(RBF)based kernel is identified as the most suitable.This is due to the RBF kernel being known to be used in solving infinite dimension problems.The RBF kernel can be represented as

By substituting (6)into (5),the required decision function becomes:

In order to adopt the binary class SVM for the multi-class problem of K categories and using the one-vs-one approach,we need to buildbinary SVM classifiers [Lee,Lin and Wahba (2004)].In the presented researchbinary SVM classifiers are modeled i.e.,C=3.On the other hand,the one-vs-all technique has three binary classifiers are modeled as well.The classifiers for one-vs-one are {Walking-vs-Waving,Walking-vs-Fighting,Waving-vs-Fighting} and for the one-vs-all methodology the same are {Walkingvs-All,Waving-vs-All,Fighting-vs-All}.The term ‘All’ is different in all the tree cases i.e.,it is {Waving,Fighting} for Walking-vs-All,{Walking,Fighting} for Waving-vs-All and {Walking,Waving} for the classifier Fighting-vs-All.The final classification of the input feature set,fs,through the one-vs-one multi-class classifiers is achieved as:

wherep,q∈{Walking,Waving,Fighting}andfp,q∈{Walking-vs-Waving,Walking-vs-Fighting,Waving-vs-Fighting}.The classification of a feature set,fs,using one-vs-all modality is computed as:

where cp(i)is the class probability of the ithclass.
4 Experimental setup,results &discussion
4.1 Experimental setup
In this subsection,the detail of dataset,specification of hardware system used for implementation,description of the tool used and the evaluation metrics will be presented.
4.1.1 Dataset &system platform
The proposed method is experimented on a dataset of self-created video sequences and publically available datasets for classifying walking,waving hand and fighting in the crowd.The proposed technique is evaluated over two types of experiments i.e.,individual action classification (walking,waving hands and fighting)and normal-abnormal action detection.In case of second type experiment,walking and waving hands is taken as normal action while fighting is classified as abnormal action.Total number of tested frames is 1000.The proposed technique is tested by implementing in MATLAB R2015 on a machine with multicore 1.8 GHZ processor.Following datasets are used other than the self-created dataset:
• Weizmann (http://www.wisdom.weizmann.ac.il)
• CAVIAR http://groups.inf.ed.ac.uk/vision/CAVIAR/CAVIARDATA1
Video sequences taken from the above-mentioned datasets represent different scenarios and it will be considered while performing the experiments.Following are the seven ones:
Scenario 1:One person walking in corridor
Scenario 2:Two persons walking in corridor
Scenario 3:Three persons walking and waving hand in corridor
Scenario 4:One person walking in outdoor scene and shadow appears large
Scenario 5:One person walking with dog in outdoor scene
Scenario 6:Four person walking and waving hand in corridor
Scenario 7:Two persons fighting in corridor
4.1.2 Quantitative measuring parameters
Precision,recall,f-measure and accuracy are used to compute quantitative performance of the proposed technique i.e.

4.2 Results &discussion
Results of the presented methods for each of the scenarios are presented in Figs.2-7.The results of segmentation of two consecutive frames for each scenario are shown in Fig.2.In the scenario 1,although there are different lightning conditions in the scenes,yet the results of segmentation are quite promising as mixture of Gaussian deals with such conditions.In the scenario 4 the shadow of person appears large in outdoor scene and which is little bit handled by segmentation and will be totally removed after applying shadow removal technique.In scenario 5 there is flickering of leaves in the background that is well handled by mixture of Gaussian as it eliminates misclassification due to cyclic motion in the background.
After applying the shadow removal,results get much simplified and clear as the shadow is removed and false human detection would be minimized.The fact may be evidently visualized for the scenarios 1 and 4 in Fig.2 and Fig.3,where larger sized shadows are removed and chance of misclassification of those shadows as humans is tackled.

Figure2:Consecutive frames and corresponding segmentation results for each scenario

Figure3:Results of shadow removal for consecutive frames of each scenario

Figure4:Partwise feature extraction for human detection
Fig.4 is showing the division of the extracted blobs,which were obtained through the segmentation and shadow removal steps.Each of the blob in the segmented image is divided into the four parts and their corresponding HOG features are extracted.If any of the blob has a greater size than a threshold,there is a chance of occurring multiple humans.In this case,with reference to the centroid the blob is divided into multiple set of regions where each of the set looks for occurrence of a unique human.The HOG feature is fed to the four SVM classifiers using RBF kernels resulting either a part of human or not.In case,if the majority of SVM models result in positive the blob is labelled as human otherwise it is considered as non-human.
Fig.5 is showing the results of the human detection through HDA.It may be observed that HDA detected all the human blobs present in the frames and for all the seven scenarios.

Figure5:Results of human detection for each scenario
Once the human is detected,his action needs to be classified.In order to classify the human action,features are extracted through FEA.A feature vector is of dimension 1×6 and shown in the Fig.6.
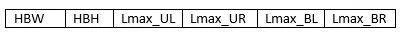
Figure6:Feature vector for action classification
where HBW,HBH represent human blob width,human blob height,while Lmax_UL,Lmax_UR,Lmax_BL and Lmax_BR represent farthest point from centroid in upper left,upper right,bottom left and bottom right regions.For the actions like walking sidewise,waving hand and fighting the width of blob is more than those of walking towards camera but all the three actions have discriminant region wise features i.e.,sidewise walking have higher values for Lmax_BL or LMax_BR or both while the waving hands has higher values for Lmax_UL or Lmax_UR.The fighting action may have all the region values different from the other two actions.
The results of feature extraction and action classifications is shown in Fig.7.The green bounding box represents normal and red bounding box represents abnormal action.The multiclass problem is solved through the adoption of binary class SVMs.In the current research,two types of adoptions are used i.e.,one-vs-all and pairwise classification.Here,the adoption of pairwise classification is called binary class SVM while one-vs-all is termed as multi-class SVM.In order to implement pairwise classification modality,following set of binary classifiers i.e.,{Walking-vs-Waving,Walking-vs-Fighting,Waving-vs-Fighting}.The task of one-vs-all is adopted through following set of classifiers i.e.,{Walking-vs-All,Waving-vs-All,Fighting-vs-All}.The pairwise classification is performed using radial basis function kernel and linear kernel,while one-vs-all modality is performed using RBF kernel bases SVM classifiers only.In case of pairwise classification (Binary class SVM)majority voting criteria is adopted.In order to predict using one-vs-all (Multiclass SVM),the test instance belongs to class whose class probability is highest amongst the three classes i.e.,walking,waving and fighting.
For an example,an image frame which needs to be classified after the feature extraction has an action of waving hands.In order to predict the action using binary class SVM,the extracted features are fed into all the three pairwise classifiers.The binary class classifier,walking-vs-waving,predicts the action as waving,walking-vs-fighting classifier predicts and action as walking and waving-vs-fighting fives prediction output as waving.The majority of the votes are for the waving class i.e.,2,so the action is classified as waving.While testing through multiclass SVM,the features are fed to the walking-vs-all,wavingvs-all,and fighting-vs-all classifiers.The output class probabilities by all the three classifiers were 0.45,0.81 and 0.13 for walking,waving and fighting class.The maximum class probability is for the waving class,so the action is classified as waving.
Fig.8 is showing the comparative results of the proposed methodology in terms of accuracy using three different modalities i.e.,binary class SVM (pairwise classification)using linear kernel,binary class SVM using radial basis function (RBF)kernel and multiclass SVM(one-vs-all)using RBF kernel.The graph shows the comparative accuracies for all the seven scenarios as defined in dataset description.The highest of the accuracies for scenario 1 are 100% for multiclass SVM using RBF and binary class SVM using linear kernel while it remained 85% for the and binary class SVM with linear kernel.The highest accuracies for the reaming six scenarios are 98.82%,96.53%,100%,95.0%,100%,94.83% for radial basis binary class SVM,RBF based binary class SVM,multiclass SVM with RBF kernel,RBF based binary class SVM,multiclass SVM with RBF kernel(combined with linear kernel SVM)and multiclass SVM with RBF kernel respectively.
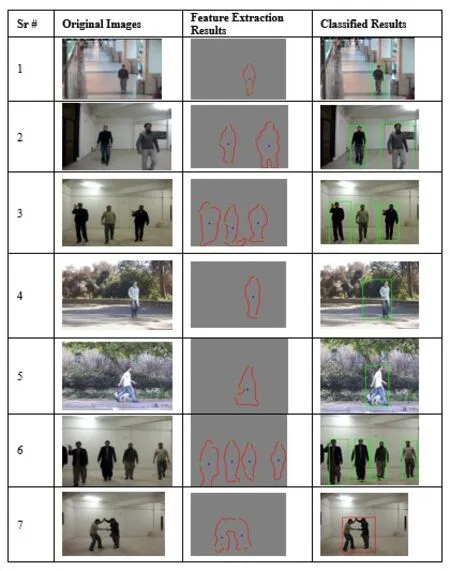
Figure7:Results of feature extraction and classification for each scenario
On the other hand,RBF based binary SVM has least accuracy for scenario one,four and seven while binary SVM with linear kernel retained lower accuracy for the second,third,fifth and seventh scenarios.
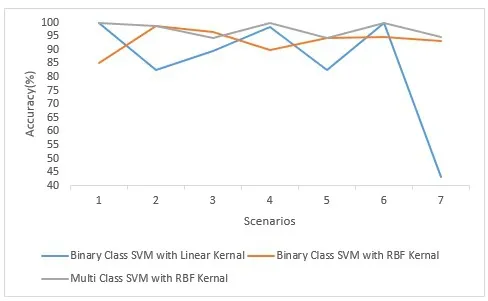
Figure8:Comparative analysis of classification accuracies using variant of SVM modalities
In Fig.9,the comparison of the above stated three modalities for the SVM classifier is presented in the form of precision.It is quite clear from the graph that all the three modalities attained 100% precision for all the first six scenarios.In case of seventh scenarios,the precision values are 93.10%,43.10% and 94.83% for RBF kernel based binary class SVM,linear kernel based binary class SVM and multiclass SVM with RBF kernel respectively.
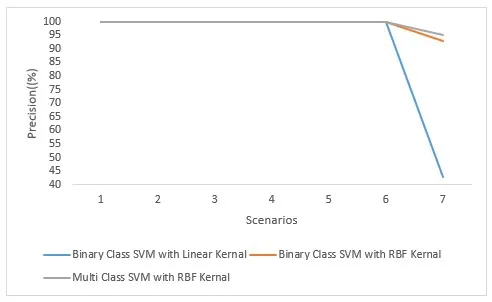
Figure9:Comparative analysis of classification precisions using variant of SVM modalities
Fig.10 is showing the comparative analysis of the proposed technique evaluated through recall measurement.The comparison is presented for all the three variants of SVMs.The binary SVM classifier with RBF kernel achieved recall values 85.19%,98.80%,96.53%,90%,94.23%,94.57% and 100% for the scenarios 1-7 respectively.In case of linear kernel based binary SVM,the same evaluation parameter and for the same one to seven scenarios the achieved results are 100%,85.25%,89.58%,98.33%,82.69%,100% and 100%respectively.While using RBF based multiclass SVM,the proposed technique has achieve following recall values i.e.,100%,98.80%,94.44%,100%,94.23%,100% and 100% for all the seven scenarios in a sequence respectively.

Figure10:Comparative analysis of classification recall using variant of SVM modalities
The statistics of the third evaluation metric,F-measure,is graphically presented in Fig.11.It shows the comparative results of the proposed technique using all the three SVM modalities.It may be observed that while using RBF based SVM,the f-measures of the proposed technique on all the seven scenarios are:92%,9.9%,98.23%,94.74,97.03%,97.21% and 96.43%.The same metric and over the same scenarios but using linear kernel based SVM the results are 100%,990.43%,94.51%,99.16%,90.53%,100% and 60.24%.The results are in sequence corresponding to the sequential scenarios in an order of one to seven.At last,the f-measure results through the proposed technique and using RBF based multiclass SVMs are presented as:100%,99.39%,97.14%,100%,97.03%,100% and 97.35% for the scenarios 1-7 respectively.
While performing the second set of experiments i.e.,abnormal action detection over the available dataset,the normal class is defined as Normal={walking Images}U{Waving Hands Images} and the abnormal class is Abnormal={Fighting Images}.Tab.1 presents the comparison of the proposed technique with the existing one [Yogameena,Komagal,Archana et al.(2010)].The results show that the proposed system out-performs than the existing technique [Yogameena,Komagal,Archana et al.(2010)] for normal behavior classification using both the SVM classifier with RBF kernel and multi-class SVMs.The same results were achieved for the abnormal behaviors through the binary class SVMs with RBF kernels but the proposed technique was out-performed by the existing technique[Yogameena,Komagal,Archana et al.(2010)] through the multi-class SVMs for abnormal behavior classification.
5 Conclusion
In this research,a methodology for human behavior classification is presented.The proposed methodology comprised on five modules including segmentation,shadow removal,human detection,feature extraction and for achieving the required goals fill hole inside objects (FHO),human detection algorithm and feature extraction algorithm (FEA)are presented.The presented human detection technique is robust as applied in both indoor and outdoor scenes and give good results.The proposed methodology is implemented to classify the different human actions along with normal and abnormal human behaviors in thin crowded videos.It was tested over different public datasets and the performance of the proposed technique is evaluated through accuracy,F-measure,precision and recall metrics.
Declarations
Availability of supporting data
Our dataset may be provided on request from the corresponding author.
Competing interests
The authors declare that they have no competing interests.
Funding
This research did not receive any specific grant from funding agencies in the public,commercial,or not-for-profit sectors.
Acknowledgements:Authors are thankful to Ms.Shafina Bibi at International Islamic University,Islamabad,Pakistan for her continuous support during the conduct of whole research.
杂志排行

Computers Materials&Continua的其它文章
- Efficient Computation Offloading in Mobile Cloud Computing for Video Streaming Over 5G
- Geek Talents:Who are the Top Experts on GitHub and Stack Overflow?
- Implementing the Node Based Smoothed Finite Element Method as User Element in Abaqus for Linear and Nonlinear Elasticity
- Dynamics of the Moving Ring Load Acting in the System“Hollow Cylinder + Surrounding Medium” with Inhomogeneous Initial Stresses
- Improvement of Flat Surfaces Quality of Aluminum Alloy 6061-O By A Proposed Trajectory of Ball Burnishing Tool
- Keyphrase Generation Based on Self-Attention Mechanism