基于深度学习的车站旅客密度检测研究
2019-11-20王明哲张研杨栋张秋亮
王明哲,张研,杨栋,张秋亮
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
1 概述
随着人工智能、深度学习等新技术的发展,智能客运车站的建设突飞猛进。智能客运车站是在现代铁路管理、服务理念和云计算、物联网、大数据、人工智能、机器人等最新信息技术基础上,以旅客便捷出行、车站温馨服务、生产高效组织、安全实时保障、设备节能环保为目标,实现铁路客运车站智能出行服务、智能生产组织、智能安全保障、智能绿色节能有机统一的新型生产服务系统[1-3]。车站旅客密度是智能客运车站建设中的关键信息,可提升客运生产作业的智能化水平,实现作业人员实时动态调配,对提高客运生产作业效率具有重要意义。
车站旅客密度的检测主要依靠机器学习技术分析前端摄像头拍摄的画面,统计区域范围内的旅客人数,得出旅客密度。传统图像检测技术主要依靠Svm、Adaboost 等分类算法,结合Haar 特征、Hog 特征等人为选定的特征进行图像检测[4-5],复杂场景中的识别准确率不高,无法满足现场实际需求。
近年来,深度卷积神经网络在图像领域发展迅速,深度卷积神经网络AlexNet[6]、GoogLeNet[7]、VGGNet[8]、ResNet 等的出现,大幅提高了图像分类、目标检测领域的准确率。随着目标检测技术准确率的不断提升,检测的实时性问题也成为图像领域的研究热点。在RCNN 和Fast-RCNN 算 法 基 础 上,Ren 等[9]提 出Faster-RCNN 算法,算法通过选取推荐、目标分类2 步实现目标检测,在ZF-model 下达到了17 F/s 的检测速率;为了进一步提高检测速率,Liu 等[10]提出SSD 算法,算法将Faster-RCNN 算法中的选取推荐、目标分类2 步合并为1 步,直接检测目标,SSD300 模型的检测速率达到了59 F/s。深度学习技术在目标检测领域的迅速发展为实时、准确检测车站旅客密度提供了新思路。
2 Faster-RCNN 算法原理
将图像输入卷积神经网络进行特征提取,对提取的图像特征运行Faster-RCNN 算法,以进行图片分类。Faster-RCNN 算法主要包括候选框推荐和分类检测2 个步骤,其原理见图1。

图1 Faster-RCNN 算法原理
输入图像(image)进入卷积层(conv layers)进行特征提取,得到特征图谱(feature maps),这一步中的卷积层可以是任意神经网络,如ZF-model、VGG16、Res-Net 等深度神经网络;特征图谱信息经过选区推荐网络(region proposal network)产生候选区(proposals),推荐的候选区仅表示有无目标,选取推荐网络的损失函数(损失函数由边框分类损失和边框回归损失两部分构成)定义如下:

式中:pi为方框预测为目标的概率为方框的标签,0 为负样本,1 为正样本为分类损失;为2 组线性变换为将方框变换到预测框的线性变换为将方框变换到标定框的线性变换为回归损失。
最后对候选区进行感兴趣区域池化(RoI pooling),输出固定长度的特征向量,并进行分类和回归,确定最终的分类结果(classifier)。
3 SSD 算法原理
SSD 算法基于VGG16 网络对输入图片进行特征提取,通过综合多尺度的特征图谱,直接进行目标分类和边框回归,得到最终检测结果,其原理见图2。

图2 SSD 算法原理
在图2 中,输入图像尺寸为300×300 像素固定尺寸,算法也支持512×512 像素输入的图像。SSD 通过类似VGG16 的卷积神经网络进行特征提取,从6 个不同尺度的特征图进行特征提取,底层提取特征预测小目标,高层提取特征预测大目标。最终汇集不同特征尺度上的边界框,对每个类别可得到8 732 个边界框,直接对边界框进行分类和回归,完成最终预测。SSD算法的损失函数定义如下:
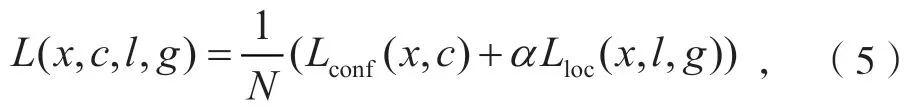
式中:x为的简写,为第i个边界框预测为第j个真实框且分类为p;c为置信度;l为预测框;g为真实框。
损失函数由分类损失函数Lconf和位置损失函数Lloc构成,Lconf为Softmax 损失函数,Lloc与Faster-RCNN 算法类似,为SmoothL1损失函数。
4 旅客密度检测
4.1 评价指标
车站旅客密度检测的主要任务是获取实时视频流,截取图片,并识别图片中的所有人,进而评估区域旅客密度,并在密度过高时给予报警。定义人数检测准确率指标P以评价算法准确性,定义如下:

由于1 张图片中的人数多少、遮挡等因素对检测准确率会产生较大影响,因此将检测场景分为低密度场景和高密度场景2 种,选取具有代表性的100 张低密度场景图片和30 张高密度场景图片,分别评价算法的准确性,图片分辨率为1 080P。对每张图片的人数检测准确率进行算术平均,得到最终算法准确率。
4.2 基于公开数据集的旅客密度检测
深度学习的训练依赖大量带有标注的样本构成的数据集,常用的公开数据集有VOC2007、VOC2012、COCO 等数据集。VOC2007 数据集由训练集和测试集2 部分构成,其中,训练集有5 011 张标注图片,测试集有4 952 张标注图片,共有20 种标注类别;VOC2012 数据集与VOC2007 数据集的样本类别相同,图片数量更多;COCO 数据集有80 个样本类别,图片数量超过10 万张。
选取VOC2007 数据集和VOC2012 数据集一起训练模型。针对Faster-RCNN 算法,采用VGG16 卷积神经网络训练检测模型;针对SSD 算法,分别训练SSD300 和SSD512 两个检测模型。对得到的3 个模型进行评价,Faster-RCNN、SSD300、SSD512 算法的检测准确率见表1。

表1 公开数据集下的检测准确率 %
VOC 数 据 集 下 训 练 的Faster-RCNN、SSD300、SSD512 算法在低密度场景、高密度场景的检测结果见图3、图4。

图3 VOC 数据集下训练的各算法低密度场景检测结果

图4 VOC 数据集下训练的各算法高密度场景检测结果
4.3 基于车站行人数据集的旅客密度检测
分析上述试验结果,3 种算法在VOC 数据集上训练的模型检测准确率均不高,无法满足现场需求。相比而言,Faster-RCNN 算法在低密度场景和高密度场景下的准确率均明显高于SSD300 算法和SSD512 算法。针对公开数据训练的模型在车站旅客密度检测任务中准确率不高的问题,建立车站行人数据集,采用Faster-RCNN 算法训练模型,并分析检测准确率。
通过采集车站各种场景的视频流,截取图片,并标注其中的行人,建立车站行人数据集。车站行人数据集由500 张1 080P 分辨率的图片组成,标注类别为“行人”一个类别,数据集格式为VOC 格式。
选取数据集中80%数据构成训练集,剩余20%数据构成验证集。采用由ImageNet 网络预训练的VGG16 模型进行训练,并固定VGG16 网络的前3 层网络参数,学习率设置为0.001,训练次数设置为70 000。训练和测试中的输入图片归一化尺寸均设置为1 920×1 080 像素,侯选区推荐数量设置为12 000,非极大值抑制后保留的候选区数量设置为2 000。对训练的模型进行评价,分别测试低密度场景和高密度场景的检测准确率,结果见表2。

表2 车站行人数据集下的检测准确率 %
车站行人数据集下训练的Faster-RCNN 算法在低密度场景和高密度场景的检测结果见图5、图6。

图5 Faster-RCNN 算法低密度场景检测结果

图6 Faster-RCNN 算法高密度场景检测结果
4.4 结果分析
(1)在车站场景中,使用Faster-RCNN、SSD300、SSD512 算法在VOC 数据集下训练的模型,行人检测准确率均不高,分析如下:车站摄像头的安装位置角度大多为远距离大场景俯视拍摄,而VOC 数据集中的行人大多为特写,这个差异对检测结果有较大影响。
(2)SSD300、SSD512 算法的检测准确率很低,与Faster-RCNN 算法存在明显差距,分析如下:检测图片的原始分辨率为1 920×1 080 像素,SSD300 算法将分析图片压缩到300×300 像素进行检测,SSD512算法将分析图片压缩到512×512 像素进行检测,原始画面中的行人目标在大比例压缩尺寸后变得难以检测。
(3)针对画面角度、图片尺寸压缩过大的问题,在车站行人数据集下训练的Faster-RCNN 算法准确率明显提升。
(4)在车站行人数据集下训练的Faster-RCNN 算法,在低密度场景和高密度场景的准确率差异不大,分析如下:低密度场景中人数较少,单个目标的漏检会大幅降低整体准确率。
5 结束语
车站旅客密度是智能客运车站的重要基础信息,对客运生产作业提质增效具有重要意义。基于公开数据集的模型和算法难以适应铁路客运站的复杂场景,通过车站行人数据集训练的模型可有效提升旅客密度检测准确率,解决现场问题。目前,车站旅客密度信息已接入旅客服务与生产管控平台,并在智能京张高铁、京雄城际铁路开展工程化应用。
