融合深度特征的多示例学习陶俑图像分类
2019-11-19温超,屈健,李展
温 超,屈 健,李 展
(1.西北大学 艺术学院 710127,陕西 西安;2.西北大学 信息科学与技术学院, 陕西 西安 710127)
古代陶俑作为珍贵的文物和艺术品,具有重要的历史、科学和艺术价值。近20年来,随着陕西秦兵马俑二次发掘和汉唐墓葬考古等工作的进展,利用各种数字采集方法获取了大量陶俑图像数据。同时,伴随互联网数字图像资源的不断丰富,目前在西北大学数字博物馆中已经拥有包括陶俑在内的大量文物图像[1],如图1所示。

图1 西北大学数字博物馆中的陶俑图像Fig.1 Pottery figurine from digital archaeology museum of Northwest University
近年来,图像理解技术,如图像分割、图像检索、图像标注、图像分类等,已得到了广泛的研究和应用,但是,针对陶俑的相关图像理解研究仍有待展开。由于不同陶俑的形态(艺术)特征各不相同,通过对大量不同年代陶俑图像的分析发现,陶俑文物图像具有如下几个特点:①不同年代和职能陶俑具有较大的类内差异,比如同样都是兵俑图像,秦代的兵俑与汉代的兵俑表现出完全不同的视觉特性;②陶俑图像的局部区域如头饰、面部、足部等特征,对于陶俑语义获取起着重要的作用;③如果对陶俑图像整体标注语义信息,则陶俑图像分类问题就变成一个标准的多示例学习问题,即把陶俑图像看作是包,图像区域作为包中的示例,我们只知道该陶俑图像(包)包含特定区域特征(正示例),却不知道哪个示例是正示例。多示例学习适于表达不完备标记、歧义性问题,并可有效降低标注复杂度,因而受到了广泛的关注,已应用到如文本分类[2]、目标跟踪[3]、行人再识别[4]、计算机辅助医学诊断[5]等诸多具有挑战性的任务中。
基于陶俑图像的自身特点并结合多示例学习的优势,本文提出了一种结合深度特征与多示例学习的陶俑文物图像分类方法。该方法首先对陶俑图像进行分割,从而获取陶俑局部特征区域;之后提取局部区域的手工特征如尺度不变特征变换(scale invariant feature transform, SIFT)特征和陶俑形态特征以及基于深度学习的卷积神经网络(convolutional neural network,CNN)特征;然后,将特征分为两部分,一部分是形态和深度特征,另一部分是SIFT特征,并通过多核融合多示例学习计算两部分的相似性;最后,使用直推式支持向量机(transductive support vector machine, TSVM)进行陶俑图像分类。
本文的主要贡献在于:①通过有效的陶俑图像分割,获取重要局部区域,提取出分割区域的手工特征(包括SIFT和形态特征)和深度学习CNN特征,带来了更好的特征表现能力;②使用联合字典学习获取多示例学习的多“概念点”,并通过多核学习将手工特征与深度特征融合到多示例学习框架中,获取了不错的分类效果。
1 多示例学习
多示例学习(multiple instance learning, MIL)作为和无监督学习、监督学习及强化学习并列的第4种学习框架,是由Dietterich在研究药物活性预测问题时首次提出[6]。在MIL中,正包内存在至少一个正示例,而负包内所有示例都为负。MIL算法需要解决正包弱标记,以及由此引发的示例歧义性问题。针对MIL问题,近年来很多MIL算法被提出,跟据MIL算法的学习机制,可将其归为3类:基于示例的MIL、基于包结构的MIL和深度MIL方法。
基于示例的MIL算法认为,正包标记由包内正示例决定[6-9],而基于结构的MIL算法则认为包标记由包内所有示例共同作用[10-14]。这两类方法中研究比较多的是一种被称为寻找示例空间聚集点即“概念点”的方法,有影响力的“概念点”方法包括APR,DD,DD-SVM和MILES。APR[6]和DD[7]算法认为正示例应该具有相似的特征,因而在欧式空间内存在聚集性,分别寻找矩形和椭圆形正示例稠密区域,这两种方法获取的是单“概念点”。而DD-SVM[12]和MILES[13]都寻找多“概念点”,两种方法认为,具有相同标记的包,应该具有相似的结构,示例特征也是相似的。鉴于多示例学习模型的成功,它的算法研究多被直接应用到图像分类。
随着深度学习尤其是卷积神经网络(CNN)的成功[15],近年来,许多深度MIL算法被提出,并应用于不同的图像理解任务。例如,文献[16]将示例或包信息输入CNN网络,提出了深度监督学习mi-Net和深度无监督学习MI-Net两种方法;文献[17]在卷积神经网络中采用了注意力(Attention)机制,提出了基于注意力的MIL算法,在MUSK,MINIST 和Breast Cancer等数据集上取得了良好的性能;文献[18]提出了一种基于深度MIL的端到端学习框架,该框架通过联合光谱与空间信息融合进行全色和多光谱图像分类;另外,深度MIL也被用于齿痕舌图像识别[19]和图像自动标注[20]等。
2 本文的方法
本文提出的方法将陶俑图像作为多示例包(Bag),图像的局部区域作为示例(Instance)。具体方法分为5个步骤:
1)采用Normalized Cut对陶俑图像进行分割,获取图像的局部区域;
2)提取分割区域的陶俑形态特征和深度CNN特征以及尺度不变特征变换SIFT特征,其中,区域形态特征和CNN特征作为多示例包的示例特征,区域SIFT特征作为局部特征;
3)通过联合字典学习将包内的示例投影到字典所生成的特征向量(示例)空间,获取多示例包的多概念点;
4)使用多核学习融合多示例包和SIFT相似性;
5)采用TSVM完成陶俑图像分类标注。
2.1 陶俑图像分割
陶俑图像分割的目的是为了提取陶俑局部目标区域。本文采用Normalized Cut(简称NCut)算法[21]进行陶俑图像分割。作为一种基于图谱理论的图像分割方法,NCut可融合图像的不同特征,其基本步骤如下:
1)对于给定的一幅图像,NCut通过样本集合建立无向加权图G,用wij衡量边的权重,

(1)
2)解出特征方程(D-W)y=λDy最小特征值和对应的特征向量,其中W为权重矩阵,D称为对角矩阵。
3)使用第二最小特征值对应的特征向量进行图像分割。
4)判别图像分割结果,决定是否需要再做分割,若需要,则返回步骤3)。
图2给出了秦俑的分割效果图,分割后的不同区域做了标识。从图2可以看到,陶俑的头饰、面部、身体、足部、腿部及胳膊等这些重点区域可从分割结果中很快辨认出来,表明针对陶俑图像NCut具有较好的分割效果。除了视觉评价之外,我们还选用分割图像的区域内一致性和区域间对比度作为客观评价指标。图2分割图像的区域内一致性为0.962,区域间对比度为0.592,进一步表明本文采用NCut分割是可行的。
需要指出的是,精确的对象(目标区域)图像分割始终是一个具有挑战性的课题,然而本文算法并不完全依赖准确的分割表现。这是因为我们旨在通过新的多示例学习方法,将传统手工特征与深度特征融合,从而达到良好的分类性能。

图2 秦骑兵俑NCut分割效果图Fig.2 The terracotta warrior image before and after NCut segmentation
2.2 区域特征提取
对于无论是单概念点还是多概念点的多示例学习,特征提取在MIL图像理解中都起着核心作用,因此,选择合适的特征来表现图像非常重要。针对陶俑图像特点,本文选择尺度不变特征变换以及区域形态特征和CNN特征进行图像描述。
尺度不变特征变换(SIFT)[22]是由Lowe提出的图像局部特征描述子,具有旋转、尺度缩放、亮度变化的不变性,并对视角变化、仿射变换、噪声也有强鲁棒性。SIFT算法本质是基于图像特征尺度选择思想,其主要步骤为:
1)在尺度空间寻找极值点;
2)对极值点进行过滤;
3)找出稳定的特征点;
4)在每个稳定的特征点周围提取图像的局部特征描述,包括位置、尺度、旋转不变量。
除了提取分割区域的SIFT特征,通过分析陶俑图像特点与比较测试[23],采用傅里叶描述子与椭圆离心率表示陶俑区域形态特征。利用复平面中的有限点集,傅里叶描述子可以表达整个图像的区域轮廓。鉴于轮廓曲线的起始点位置和曲线方向会影响傅里叶描述子,为了保证图像的旋转、平移和尺度不变性,采用式(2)对傅里叶描述子进行归一化。
FD(k)=
(2)
其中,第1位傅里叶描述子作为归一化参数。实验表明,增加傅里叶描述子维数可以使得轮廓特征描述更加精确,但同时带来更多的计算消耗。因此,对于陶俑图像分割区域,将其统一缩放为256×256大小,并使用一个7维的傅里叶描述子,即F(0)(第1位)为归一化参数,F(1)到F(6)(第2到7位)进行归一化处理。在傅里叶描述子描述轮廓特征的基础上,增加椭圆离心率e描述形状特征,以反应分割区域的长宽比,并与傅里叶描述子组合形成一个8维的形态特征向量。
基于深度学习CNN的强大性能,在获取以上传统手工特征的基础上,利用CNN提取陶俑图像区域的全局特征,以进一步提升特征表现能力。如图3所示,陶俑图像区域被输入CNN网络,输出一个二维矩阵,从而得到该区域一个定长的多维特征向量。

图3 秦骑兵俑头饰区域CNN特征提取Fig.3 CNN feature extraction from headdress region of terracotta warrior
1)深度学习架构:文中采用经过预训练的VGG-16。VGG-16共包含16个权重层,其中,13层为卷积层,其余3层为全连接层,第二个全连接层有4 096个单元,将其输出结果作为特征。这样可以为每个区域提取4 096维特征向量。为了使VGG-16适合我们的任务,在网络训练中,将最后的1 000路全连接层替换为2路全连接层(即是否为陶俑图像区域),并使用SoftMax函数作为最终预测函数。
2)网络训练:首先,在ILSVRC2012数据集上进行预训练,然后,在分割的陶俑图像区域上进行微调。考虑到进行训练的区域图像总共为6 300个,不足以训练高性能的深度学习网络。因此,将区域图像的大小调整为256×256,并采用64×64固定大小子图进行随机剪切和水平翻转,以增强训练数据。使用随机梯度下降来微调该网络,单次训练样本数为128。实验中,卷积核大小为{3*3, 5*5, 7*7},池化层分别选用最大池化和平均池化,学习速率大小为{0.001, 0.005, 0.000 1},动量为{0.7, 0.8, 0.9},权重衰减为{0.001, 0.000 5, 0.005},将这些参数进行组合实验,选择最优的结果。最终选择的参数为:学习速率为0.000 1,动量为0.9,权重衰减为0.000 5,卷积核大小为3*3,池化层为最大池化。当精度不再提高后,在36个训练周期停止训练。
2.3 多示例多概念点获取
在MIL图像预测任务中,每个包(图像)含有数量不等的示例(特征向量),导致传统监督学习算法(如SVM等)无法直接用于求解MIL问题。因此,需要将多示例包转化成单个样本,即每个多示例包都嵌入“概念点”生成的空间中,从而将多示例学习问题转化成标准的监督学习问题。
在获得陶俑图像区域的人工特征(SIFT和形态特征)和深度学习CNN特征后,把这3个特征分为两部分:第一部分为形态和CNN特征,第二部分为SIFT特征。由于SIFT特征具有集合特性且元素个数不同、位置互异,不能直接参与包相似性计算,因此,将第一部分的形态特征与CNN特征作为多示例学习包,并采用联合字典学习[24]获取多概念点。具体方法如下:

鉴于多示例学习的核心要是处理歧义性问题,那么,这些概念点(基向量aij)间的距离应该大于某个阈值δ,因此,在联合字典学习模型的基础上附加优化约束,这样,多示例学习的多概念点获取模型就为
s.t. ‖aij-alm‖2≥δ,
i≠l,j=1,2,…,ni,m=1,2,…,nl。
(3)

2.4 特征融合
图像相似性计算的核函数构建一直是计算机视觉领域的研究热点。对于包含ni个分割区域的陶俑图像Bi,xij是区域形态特征和CNN特征连接形成的示例特征,将Bi的所有示例xij排列在一起,投影到D中以每个列向量为基的向量空间,投影函数定义为
φ(Bi)=[s(Bi,d1),s(Bi,d2),…,s(Bi,dN)]。
(4)

针对SIFT相似性问题,文献[25]提出的基于多尺度思想的金字塔匹配核(pyramid matching kernel, PMK)已取得了巨大的成功。PMK采取多解析直方图方法,将局部特征描述子投影到不同尺度直方图,形成直方图金字塔,计算不同局部特征子的重叠区域,最后通过权重组合方式构造核函数。基于PMK方法计算速度快,且具有较高的特征识别率,本文使用金字塔核进行陶俑SIFT特征相似性计算。
接下来,将采用多核学习模型构建一个融合SIFT特征与MIL包特征的新核函数,从而平衡SIFT特征与形态和CNN特征对陶俑图像相似性的影响。多核学习[26]的基本思路是:通过将多个核函数进行正线性融合来构造新的核函数K。
(5)
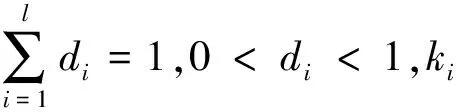
K(Bi,Bj)=αKRBF(φ(Bi),φ(Bj))+
(1-α)KPMK(ψ(Si),ψ(Sj))。
(6)
即实现了SIFT相似性与MIL包相似性的融合。
2.5 TSVM分类
考虑到直推式支持向量机(TSVM)能利用大量未标记图像来提高分类器的性能,本文采用TSVM训练分类器,实现陶俑图像分类。TSVM分类的具体方法是:


(7)
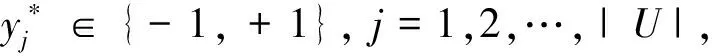
(8)
使用该分类器进行陶俑图像分类。
3 实验结果与分析
分别在陶俑图像集PFImage和标准MIL数据集(Musk, Elephant, Tiger Fox)上实验,并与多个深度和非深度MIL方法比较,以验证本文方法的有效性。实验采用的TSVM分类器基于Libsvm工具包实现,TSVM中需要指定λ,λ*和r这3个参数,实验中,将r固定为0.5,λ=1,λ*参数在训练时从参数集λ*∈{0.01,0.1,1,10}中寻找其最优值。
3.1 陶俑图像分类实验
实验测试的陶俑图像集PFImage来源于西北大学数字博物馆中的文物图像,图4给出了PFImage的示例图像。从秦俑、汉俑、魏晋南北朝俑、隋唐俑及其他俑共5类图像中各选100幅构建图像集PFImage。实验中,每张陶俑图像被NCut预分割成多个区域(不考虑无意义区域,平均为10个区域),采用十交叉验证的方法验证分类的准确度,即图像中每类数据集分为10等份,依次使用其中的9份训练,剩余的1份测试。选用“一对一”的方式处理多类问题。

图4 测试图像集PFImage中的陶俑图像示例Fig.4 Sample images of pottery figurine from testing image set PFImage
将本文方法同DD[7],DD-SVM[12],MILES[13]及深度学习MIL算法Attention[17]和MI-Net with DS[16]比较,结果如图5所示。对于Attention和 MI-Net with DS算法,只使用CNN来提取深度特征并训练深度学习网络,对于DD,DD-SVM和MILES算法,采用与本文相同的方法提取SIFT特征。最终,通过多核学习融合SIFT特征、形态特征和CNN特征,并输入相应MIL算法进行分类准确度比较。从图5可以看出,本文算法在陶俑图像分类中获得了最好的效果,不仅优于DD,DD-SVM和MILES这些传统MIL算法,与深度MIL算法Attention和 MI-Net with DS相比,准确度也提升接近4%。本文的方法优于传统MIL算法的原因在于,该方法能够更好地捕获MIL多概念点,并融合SIFT特征,从而更有效地表达图像。同时,相较Attention和 MI-Net with DS算法,本文的方法中,图像的正负示例由手工特征和深度特征结合产生,因而更好地利用了这两类特征。实验结果表明了融合深度特征的多示例学习陶俑图像分类方法的有效性。
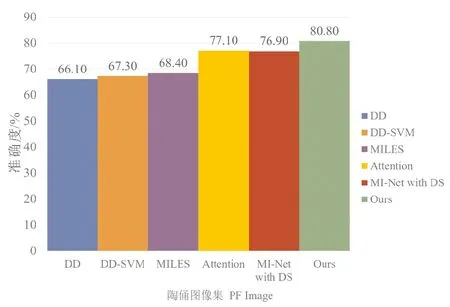
图5 本文方法同其他MIL方法在陶俑图像集PFImage上的分类结果比较Fig.5 The comparison results between our method and other MIL methods on PFImage
3.2 标准MIL数据集实验
为了进一步验证本文方法的有效性和通用性,这里选用标准MIL数据集Musk,Elephant,Tiger和Fox测试其性能。Musk数据集是由Dietterich等在研究分子活性预测时提出的,它由Musk1和Musk2两部分组成。Musk1包含47个正包和45个负包,Musk2包含39个正包和63个负包,其中Musk1中包括的示例数从2到40不等,Musk2包括的示例数则从1到1 044不等,特征向量维度为166。另外, 选择Elephant,Tiger和Fox为3类图像测试集,为了与其他MIL算法进行比较,采用文献[12]的方法将图像分割成不同的区域,并提取其颜色、纹理和形状组成手工特征。表1中列出了Musk1,Musk2,Elephant,Tiger和Fox数据集的信息。
表2给出了本文方法与MILES[13],DD-SVM[12],Attention[17]和MI-Net with DS[16]算法在标准MIL数据集的实验结果。从表2中可以看到,本文的方法优于深度学习算法Attention和 MI-Net with DS,与MILES和DD-SVM相比,在Musk1,Elephant,Tiger和Fox数据集上也都取得了最佳的分类表现。

表1 标准MIL数据集及其正负包、特征和示例信息Tab.1 Standard MIL datasets with information of positive and negative bags, features and instances

表2 本文方法与其他MIL算法在标准MIL数据集MUSK和图像集上的实验结果
4 结 语
针对陶俑文物图像的自动分类,本文提出了一个新的融合深度特征的多示例学习方法。在充分了解陶俑图像特点的情况下,本文首先利用NCut获取陶俑局部区域,并提取图像SIFT、形态和深度学习CNN特征;之后,使用联合字典学习方法获取多示例学习的“多概念”点;最后,采用多核学习模型在多示例包相似计算中融入SIFT相似性,用TSVM进行陶俑图像分类。在陶俑图像集和标准MIL数据集上的实验表明,本文算法相较文献中提到的一些深度和非深度MIL算法是有优势的。今后的工作将对如何更准确、有效地获取图像特征及基于多特征的联合字典学习方法等作进一步研究。
