灌区农业用水测算方法研究
2019-11-19赵自阳王中根李建新王红瑞
王 磊,赵自阳,王中根,李建新,王红瑞
(1.浙江省水资源管理中心,杭州 310009;2.北京师范大学 水科学研究院,北京 100875;3.中国科学院 地理科学与资源研究所,北京 100101;4水利部海河水利委员会,天津 300181)
随着改革开放以来40多年的建设,我国的发展日新月异,但同时使得水资源面临的问题愈加复杂,为了实现我国水资源的可持续利用,国务院办公厅于2013年印发了《实行最严格水资源管理制度考核办法的通知》,发布了用水总量、用水效率和水功能区限制纳污“三条红线”[1]。我国作为一个传统的农业大国,农业用水一直是用水大户,占到全国用水总量的60%以上。农业灌溉用水总量的合理测算不仅是落实最严格水资源管理制度的要求,而且是社会经济可持续发展的基本保障;不仅对于解决我国农业用水矛盾非常重要,而且是实现农业绿色发展的必由之路[2-3]。基于此,本文对灌区的农业用水测算方法进行了详细具体的分析和研究,总结了在灌区农业用水中常用的两类测算模型,以期为不同灌区的农业用水管理提供一定的技术和理论支持。
1 灌区农业用水测算方法概述
灌区农业用水的测算一般可分为2类方法:一是基于水循环过程的物理模型方法;二是基于监测数据的统计分析方法。这2类方法各有利弊,未来发展趋势是将统计分析与物理成因分析相结合,遥感反演与常规监测相结合,基于高性能计算与大数据挖掘,开展灌区农业用水测算。
1.1 基于水循环过程的物理模型方法
针对降水丰沛、灌区情况复杂,进水出水口较多,作物种类多样,甚至灌区中存在河道、水库、山塘以及工业生活生态用水等各种情况的地区,一般可采用构建具有一定水循环物理机制的模型,开展农业灌溉用水量的测算。目前,比较常用的是美国农业部开发的SWAT模型。模型的作用主要用于将点(国控农业用水监控点)的监测数据,转化为面的数据,结合耕地的数据,可以得到“农业用水总量”,从而为“最严格水资源考核”提供数据的支持[4]。
1.2 基于检测数据的统计分析方法
传统农业用水基本上采用灌溉定额(或调查定额)与统计的灌溉面积推算而得。该方法直接从最基层开始统计,层层汇总上报,导致工作精度与时间难以控制[3]。长期以来,传统农业用水基本上是估算数,与实际用水情况有较大出入。目前需要发展具有数学基础的“科学”统计方法。其中,抽样统计是经过严密的数学分析与论证的一种有效手段。可以通过抽取一定的样本进行统计分析,得出相对精确的结论。抽样调查的周期短、时效性强,作为普查的补充,可用来评价和修正普查结果[5]。
2 基于SWAT模型的农业用水测算方法
SWAT(soil and water assessment tool) 模型的物理机制很强,是一种分布式的流域尺度的水文模型。它的时间步长以日为单位,优点是可以长时间连续的模拟。它的模拟不仅包括流域的水文过程、水土流失等,还可以预测未来人类活动、气候变化、土壤状况、土地利用等改变对这些过程的具体影响。在几十年的实践过程中,SWAT模型已经在国内外得到了各行各业专家的认同,有关的研究成果也非常丰富,这也说明了SWAT模型重要的实用性[6-7]。
2.1 灌区SWAT模型构建
SWAT模型在模拟流域水文过程的时候可以分为两个部分,一是陆面部分,二是水面部分。陆面部分主要指的是产流和坡面汇流,水面部分主要指的是河网汇流[8-9]。陆面部分主要控制的是每个子流域的产流和汇流过程中在水、沙、各种营养物质和化学物质等的全部的输入量;水面部分则是上述种种物质向流域出口的运移过程。在SWAT的研究过程中,一般在所有的结构单元上都会建立相对的水文过程模型(图1),从而对产流和坡面汇流进行相关的计算,最终将汇流网络整体的紧密联系在一起。
在水文径流过程和化学物质等演算控制过程中,SWAT采取的方法和HYMO模型非常的类似(图2)。主要就是通过一个个子流域的命令,将统计得到的实测数据和模拟计算得到的模拟值进行一定的对比,并且在这个过程中,通过输入相关的指令,接受其他模型的相关值;同时经过命令的转移,就可以把一个子流域的相关结果转移到另一个子流域中[10]。
2.2 灌区农业用水模型系统
1)系统总体框架
农业用水模型系统是基于SWAT(soil and water assessment tool)开发适合农业灌溉用水的快速评价系统。该系统的总体架构如图3所示。主要包括灌溉规划管理和快速评价预测管理两大部分,可在功能上满足农业灌溉规划和动态灌溉管理的需求[11]。
2)情景模拟与方案优化
灌溉规划管理子系统侧重于对灌溉方案进行优化,系统可根据历史数据资料对嵌入的SWAT模型参数进行率定和验证;可分不同情景(不同灌溉水量、不同灌溉时间、不同灌溉次数、不同灌溉措施等)对区域年灌溉情况进行模拟;还可以分析灌溉用水量、作物蒸发蒸腾量、作物水分胁迫系数、作物叶面指数等指标,根据作物产量及综合经济效益,确定最佳灌溉方案,对已有灌溉方案优化提供参考依据[12]。
灌溉规划管理子系统基于SWAT模型构建,它主要是在结合农业土壤含水量和农业灌溉信息的基础之上,分析不同的灌溉方案和管理措施等情景下,农业中作物的耗水量、产量和水分生产效率等[13]。从而对于区域的农业灌溉策略优化和制定最佳农业灌溉制度提供一定的技术和理论支持。该系统业务流程共包含6个子模块(图5)。
3)农业用水估算
快速评价预测管理子系统侧重于对灌溉活动进行快速评价预测[14]。系统可根据灌溉区域的当前天气状况以及未来降水、气温的预报数据和当前土壤墒情监测数据,以及土壤类型、作物叶面积指标,对目标区域作物耗水量和土壤墒情进行模拟预测;根据土壤水分平衡原理,结合土壤墒情预报值、作物耗水量,确定灌溉区域灌溉需水量、灌溉时间,为动态灌溉决策提供数据支撑[15]。
农业用水快速评价预测子系统是基于灌溉用水过程的复杂性和实时性,结合目标区域的具体情况,开发灌区动态灌溉管理决策辅助系统(如图6),共包含6个功能模块,如图7所示。该子系统具有人机交互数据录入、查询、结果展示功能,具有较强的可视化定量分析功能,能够为灌区管理提供灌溉模式优选和水资源优化分配的决策支持,为用户指定精细灌溉的作业方案。
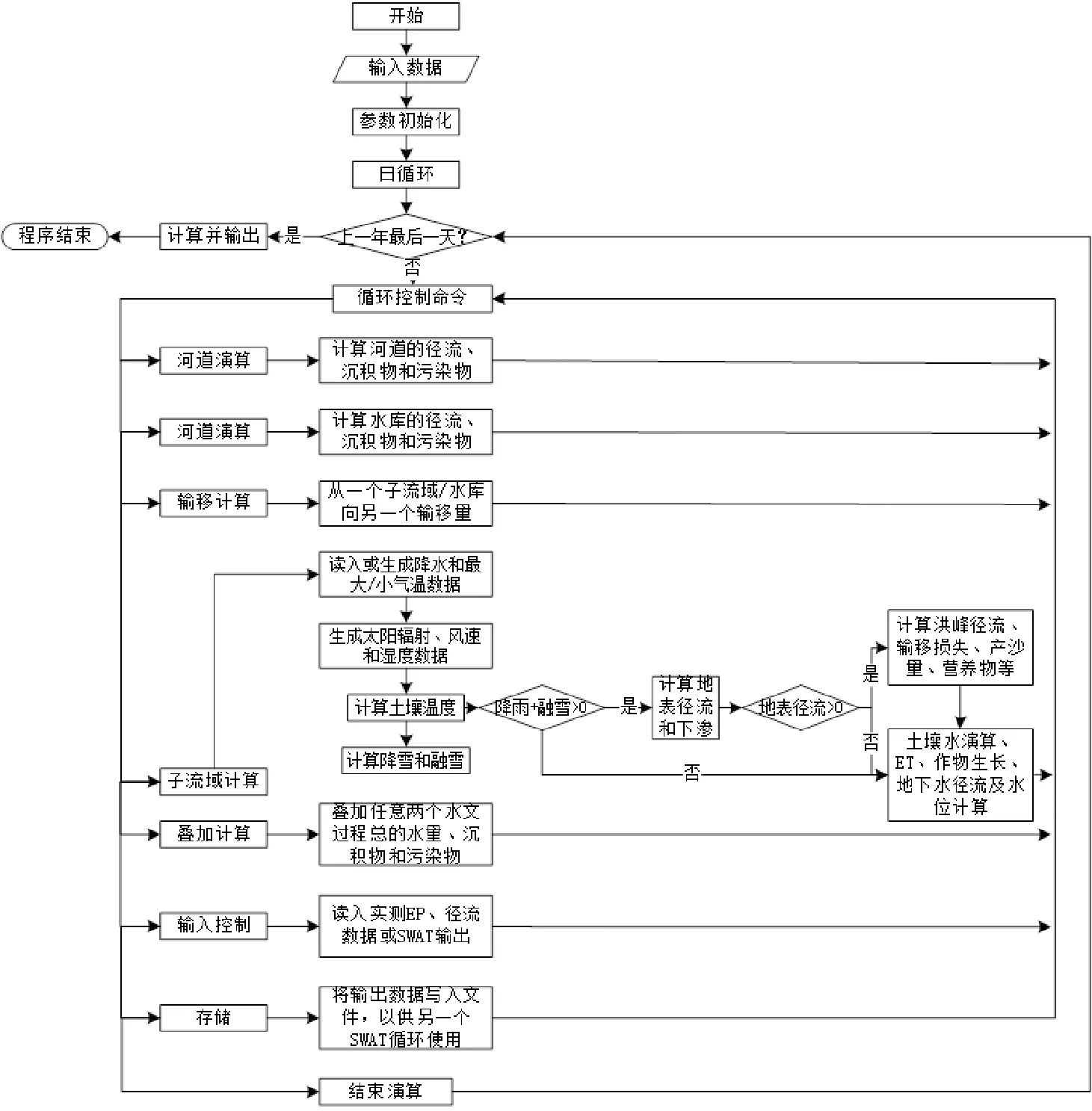
图2 SWAT模型运行命令控制图Fig.2 The running command cohtrol diagram of SWAT model
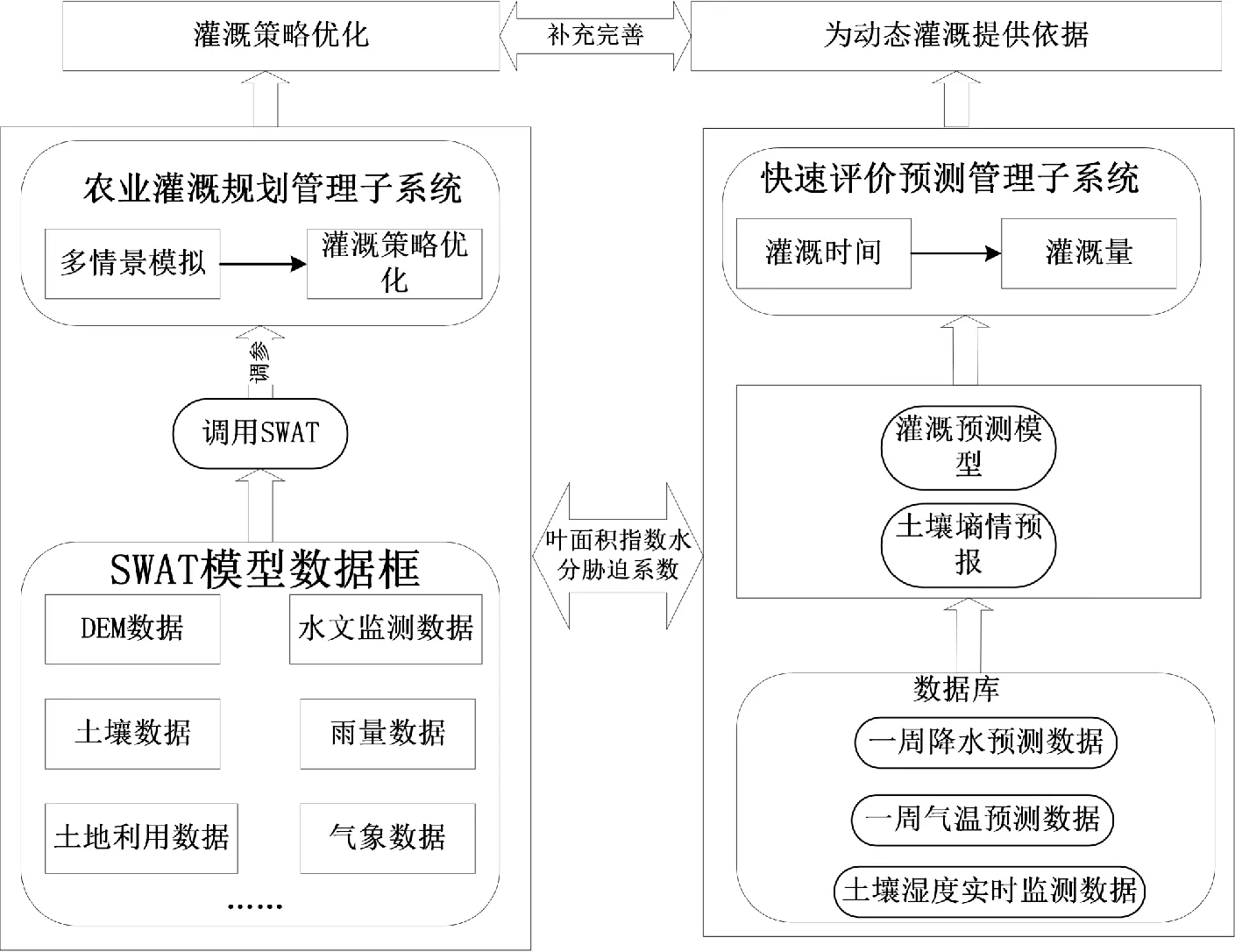
图3 系统总体框架图Fig.3 The system framework diagram

图4 灌溉规划管理子系统结构图Fig.4 The subsystem structure diagram of irrigation planning management
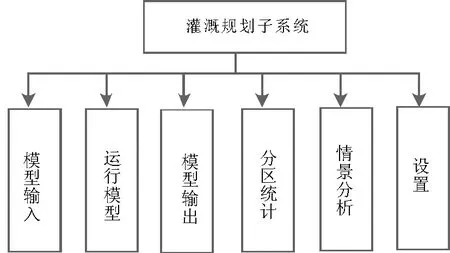
图5 灌溉规划管理子系统主要模块Fig.5 The main module of irrigation planning management subsystem

图6 农业用水评价预测子系统结构图Fig.6 The subsystem structure diagram of agricultural water evaluation and prediction
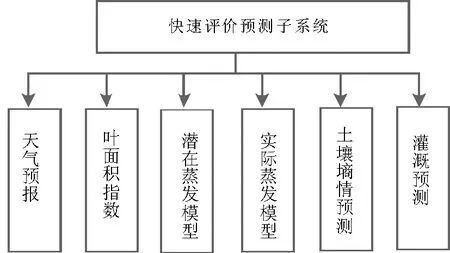
图7 农业用水快速评价预测子系统主要模块Fig.7 The main module of agricultural water evaluation and prediction
3 基于监测数据的统计分析方法
本次研究主要探讨了传统的统计分析方法(如,主成分分析法、聚类分析法和回归统计模型法等)与抽样统计分析方法,及其在农业用水测算应用。
3.1 传统统计方法概述
1)传统统计方法对比
目前常用的统计分析方法包括主成分分析法、聚类分析法和回归统计模型法等。其中主成分分析主要是通过降维的思想将多个变量变为少数几个可以代表原始变量信息的统计方法。聚类分析是根据待分类模式特征的相似或者相异程度将数据样本进行分组,从而使得同一组的数据尽可能相似,不同组的数据尽可能相异,其目的是进行数据分类而不是预测。
回归统计模型是根据两种或者两种以上变量间相互依赖的定量关系,通过对一组观察值使用最小二乘法进行直线拟合来实现线性回归分析,其功能是分析单个因变量是如何受一个或者多个自变量数据的影响。通过上述三个统计方法的对比分析可知,回归统计模型更适用于分析单一因变量与多个自变量之间的统计关系,与农业灌溉用水量统计要求较为相符。
2)多元线性回归方法
多元线性回归方法是在统计学领域经常使用的一种重要方法,不仅在生产实际中,而且在科学实验中都有着非常广泛的应用。它主要是通过研究多个随机变量之间的内在关系来表示数据样本的整体特征。
3.2 抽样统计分析方法——整群与分层抽样方法
传统农业用水基本上采用灌溉定额(或调查定额)与统计的灌溉面积推算而得。该方法工作量大,组织难度大。需要直接从最基层开始统计,动员大量的人力物力,因为其统计必须从最基层开始,层层汇总上报,导致工作精度与时间难以控制。长期以来,传统农业用水基本上是估算数,与实际用水情况有较大出入,在许多地区或应用中也证实了这一点。由于缺乏一定数学基础的估算,农业用水数据的精度(置信度与误差范围)也不得而知。严格地讲,任何数据如果没有置信度与误差范围,该数据就是存疑的,因此农业用水量或者亩均灌溉水量数据被严重质疑的。
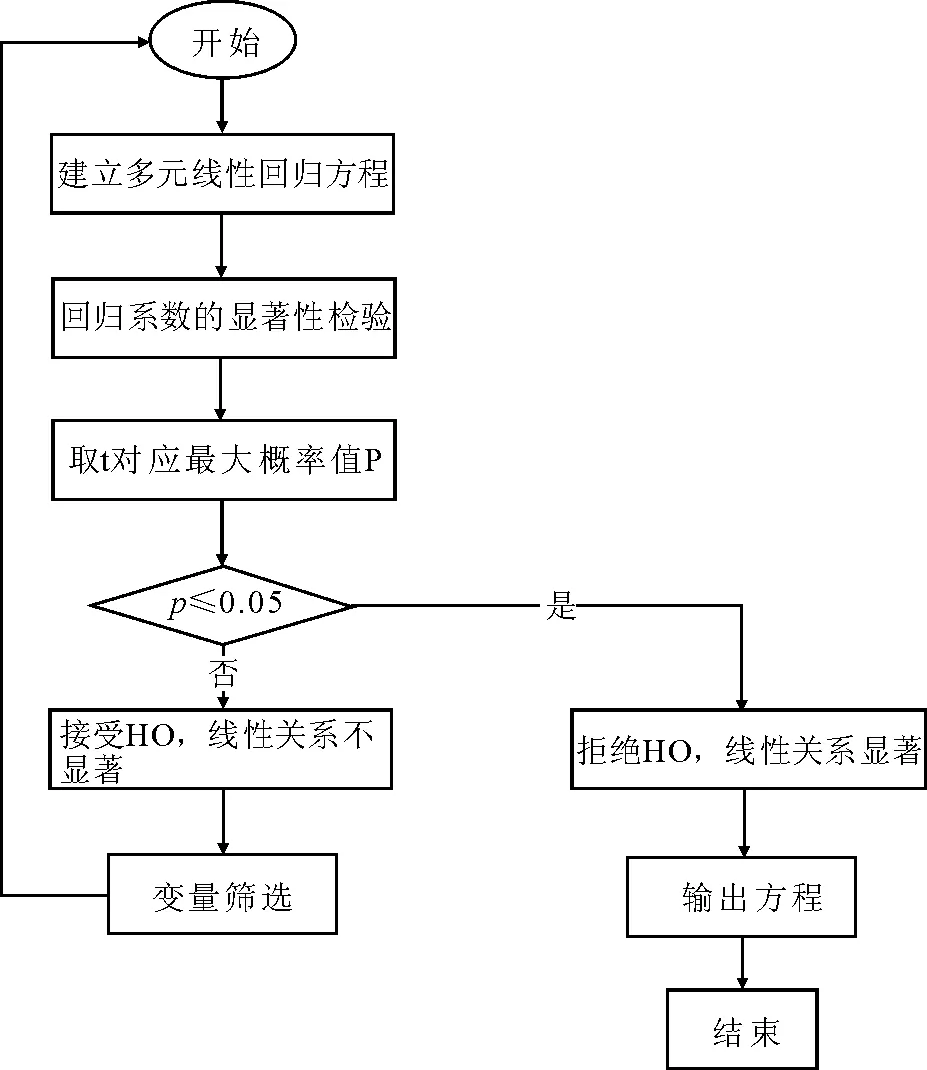
图8 多元回归分析流程图Fig.8 The flow diagram of multiple regression analysis
因此,具有数学基础的“科学”统计方法就显得尤其重要。抽样统计是经过严密的数学分析与论证的一种有效手段。可以通过抽取一定的样本进行统计分析,得出相对精确的结论。如在农业用水统计中,如果采用抽样统计方法,按其规定的步骤进行抽样与分析,其得出的结果则显然有强大的、无可辩驳的权威性。相对而言,抽样调查的周期短、时效性强,并且抽样调查能提高调查的质量,作为普查的补充,也可用来评价和修正普查结果。
整群抽样又称为聚类随机抽样或者集体随机抽样,它主要是从整体的海量数据中抽取随机的一小部分样本,然后将抽取的这一小部分样本作为调查研究的一个群体。分层抽样则主要是分为两个步骤,首先是将所有的样本按照默写规则分为若干个部分,其次是在这些部分中再采用简单随机抽样或者是系统抽样进行子样本的抽取,最终将所有的子样本放在一起就构成了分层抽样之后的样本。针对农业用水量统计而言,我们可以先按水利部《用水总量统计方案(试行)》规定将农业用水划分为农田、林果地、草地、鱼塘和畜禽五个群,开展整群抽样。然后再在每个群中根据土壤类型,如砂壤、红壤、水稻土等等,地形如山区、丘陵、平原等,以及植被类型,如水稻、玉米、小麦等等进行分层抽样。
分层抽样的总体思路是按照每一个小群(例如,农田)中的分异规律将群进行分层划分;然后利用最小二乘法估计最小的样本量,同时将按照相同的比例将样本分别分配到每一层,最终分别利用联合比估计和分别比估计进行整体的回归估计。最后用国控农业用水监控点的监测数据进行回归估计的精度评估。
一般情况下,总体样本的分层数越多,抽样的精度便会越高,但要注意的是抽样方差的减小和分层数的平方是呈现反比关系的。在分层抽样过程中,必须要求最少有两个样本层,最多不能超过总样本量的一般。但在研究过程中发现,当抽样的层数大于6时,方差的下降幅度便会大幅变慢。所以经过理论和实践的研究,一般情况下分层数不超过6层。可选择将以每一个小群(例如,农田)中的分异规律来确定分层标志,分层界限确定采用累计频数直方图法。
4 结 论
农业灌溉用水总量的合理测算不仅是落实最严格水资源管理制度的要求,而且是社会经济可持续发展的基本保障;不仅有利于解决我国水农业水资源的突出矛盾,而且可以实现农业绿色发展。针对我国灌区数量多以及类型复杂的特点,本文将灌区农业用水的测算分为2类,基于水循环过程的物理模型方法和基于监测数据的统计分析方法。其中将物理模型方法以SWAT为例,主要分析了SWAT模型的构建和农业用水模型系统;统计分析方法主要分析了多元回归分析模型与抽样统计分析方法。
