基于著者共现的CBM机构名称规范研究*
2019-11-18吴英杰李军莲孙海霞
吴英杰 李军莲 孙海霞 王 蕾 陈 颖
(中国医学科学院医学信息研究所 北京100020)
1 引言
学术论文是科研评价研究和实践的主要依据之一。精准统计机构发文与被引情况则是客观准确地开展机构科研评价的基础与关键。开展学术论文著者机构规范控制研究,实现同一机构不同表达形式的汇聚,能够最大程度避免由于机构更名、合并、拆分和不同著者对同一机构名使用不同表达形式等原因影响机构论文查准率和查全率,从而优化科研机构学术评价[1-2]。基于科技文献的机构名称规范任务一般包括两个核心环节:一是从著者单位著录项中识别出机构名称。在著者提交的论文及科技文献数据库中科研机构名称一般连同所在城市和邮编出现在著者单位著录项中。二是在同一机构不同名称表现形式间建立映射,实现同一机构名称不同表现形式的汇聚。由于数据库中著者单位著录具有一定的结构性和规范性,前者难度相对较低,相关研究更多聚焦于后者,以相似度聚类技术为基础来实现不同名称同一机构的自动汇聚规范,尽可能地减轻人工负担[1]。
聚类是将物理或抽象对象集合按有关特性的相似程度进行分组的过程,目的是使同一簇中对象特性尽可能地相似,而不同簇对象之间的差异尽可能地增大[3-4]。聚类效果与相似度度量特征密切相关。在关于机构名称规范的众多研究中基于字符串、规则及二者相结合的相似度计算方法探讨较多[5],已成为名称表达差异不大的同一机构识别的常用方法。中国生物医学文献数据库(China Biology Medicine disc,CBM)的机构名称规范早期即通过字符串相似度计算方法对大规模机构名称进行归一化处理,之后在长期实践中持续探讨优化规则与字符串相似度结合的混合方法,不断改进规范效果,为基于CBM的机构规范文档建设提供较好的技术支撑。然而由于上述方法主要基于机构名称表达的共性特征,无法有效解决表达形式差异较大的同一机构的识别与规范问题,即机构变革导致的名称变化、同一单位多个名称等,如无法识别“首都医科大学第六临床医学院”与“北京安贞医院”是同一机构。对此,有学者引入机构网页统一资源定位(Uniform Resource Locator,URL)特征,通过URL与机构名的共现情况来判断机构名称的相似度,取得了一定效果[6-7]。受该研究启发,本文将从发文著者这个重要关联因素着手,开展基于著者共现的CBM机构名称规范机制研究,尝试从 “机构-著者”维度探索因名称表达差异较大带来的同一机构漏归、错归问题,以减少机构规范过程中的人工干预,提升自动规范效果。
2 机构名称规范技术研究现状
在机构名称规范中,依据采用相似度度量特征的不同可划分为基于字符串相似度方法、基于规则的相似度匹配方法、基于共现的关联统计方法以及综合考虑多因素的混合方法[5,8-11]。(1)基于字符串相似度方法。基本思路是将机构名称字符串看作是字符序列,字符序列间相同字符越近表明这两个字符串越相似,二者指向同一机构实体的可能性越大。如French JC等[11]先后采用Hall-Dowling编辑距离算法和Jaccard系数法进行天体物理数据系统(Astrophysics Data System,ADS)作者机构名称规范文档半自动化构建研究;Jacob F 等[12]采用Levenshtein编辑距离法对求职简历中的求职者单位名称进行匹配计算与规范;Jiang Y 等[13]采用归一化压缩距离(Normalized Compression Distance,NCD)聚类算法实现同一机构多种名称的高效集成。(2)基于规则的方法。主要思想是根据机构名称构词特点建立一定的规则库,通过规则进行可能匹配的候选名称字符串识别及错误匹配对过滤。如Huang S等[14]、杨波等[15]在利用WOS数据研究机构名称聚类中综合字面相似度、字长、字顺、子串、地区等特征信息构建识别可能匹配的机构名称对规则,然后基于机构对匹配频率进行错误匹配过滤。(3)基于共现的关联统计方法。主要是利用Web语料,通过计算不同机构名称字符串网络搜索结果中URL的共现情况来判定机构名称的相似度[16-17]。如Aumuller D等[17]基于Google和Yahoo搜索返回的Topk个URL的共现重叠情况来计算两个机构名称匹配程度,同时参考TF-IDF模型对共现URL的排序位置进行加权。(4)综合考虑多因素的混合方法。主要是结合规则、加权统计来克服单纯字面相似度匹配方法的不足。如Jonnalagadda SR等[16]在开展PubMed数据库机构名称规范研究中,通过引入世界地区/邮编字典及机构-地区/邮编一致性规则来过滤错误匹配,提升相似度判断效果;贾君枝等[17]在科研机构名称归一化研究中,通过构建机构特征词表和相关规则进行机构名称分级识别,再基于编辑距离算法、TF-IDF及K-means算法实现机构名称归一,有效提高聚类的准确率和召回率。
3 CBM机构规范文档建设现状
3.1 建设进展
机构规范文档建设主要解决同一机构因表达形式不一致、名称变更、隶属关系不清等带来的成果分散问题[5]。基于CBM的机构规范工作始于2010年。经过近两年的数据分析和算法研究,从2012年起正式启动规范处理工作。目前机构规范工作组已完成千万篇文献所涉机构数据(超过322万条)的清洗,经拆分、去噪、去重、标识机构类型、所在省区等处理,形成近60万条机构信息;通过优化规则与字符串相似度结合的混合方法对大规模机构名称进行归一化处理,形成各类规范机构17万条。其中医院类规范机构8万多条,高等院校类机构3.9万条,实验室机构4 000多条,其他机构4.8万条。这些数据已经成为CBM机构检索、分析等功能的重要支撑[18-19]。
3.2 现存问题分析
尽管目前的规范文档已完成绝大部分机构的同义规范,但仍存在漏归、错归等情况,具体原因分析,见表1。可以发现同一机构不同名称形式漏归、错归的主要原因是这些名称形式与同机构的其他名称相似度不高或极低,仅靠相似度计算很难被发现;而基于著者共现分析角度探索漏归、错归同一机构的发现问题,从理论上分析具有较好的可信度,将是对相似度同一机构发现方法的有效补充。

表1 同一机构不同名称形式漏归、错归原因分析
4 基于著者共现的机构名称规范机制研究
4.1 发文著者机构特征分析
一般而言,发文著者的机构主要有两种情况:单机构和多机构。单机构指著者机构为某单一机构,如胡XX-中国医学科学院医学信息研究所,胡XX-中国医学科学院医学情报研究所。当某著者所在机构包括多个机构名称时,这多个机构可能是某机构对外的不同名称,也可能确是多个机构但仅是存在某些关系而已,如孔XX -武汉大学人民医院 湖北省人民医院,赵XX-三峡大学第一临床医学院 宜昌市中心人民医院,程XX-蚌埠医学院药学院 安徽省生化药物工程技术研究中心。CBM中机构著录主要包括机构实体和地址信息,二者之间用逗号分隔。其中机构实体部分主要包括机构名称、科室/学系等信息,机构地址部分包括机构所在省市和邮编信息。当某著者机构为多机构时,则在“机构(AD)”字段项著录多个机构的信息,多个机构名称间用“/”或空格进行分隔。如AD字段为“国家癌症中心“/”中国医学科学院、北京协和医学院肿瘤医院, 北京 100021”、“首都医科大学附属北京安贞医院 首都医科大学第六临床医学院超声诊断科,北京 100029”,即描述了多个机构名称信息,见图1。CBM收录文献时遵照客观事实对发文著者及其所在机构进行全面揭示,也就是说CBM不仅描述著者机构的基本信息,还对著者与机构的对应关系进行规范揭示,为基于著者共现开展同一机构发现提供重要数据基础。

图1 著者机构著录形式样例
4.2 方案设计
基于著者共现开展同一机构/相关机构发现研究主要是通过计算机构间发文著者的共现次数与重合度,实现一个机构不同表达形式的发现与推荐。其基本思想是:在一个地区,若两机构共有的发文著者越多则二者为同一机构/相关机构的可能性越大。具体方案,见图2。首先利用CBM数据库的著者-机构关系构建机构-著者空间,在此基础上分地区计算各机构间的著者共现关联度,结合机构类型维度从高到低排序,著者共现关联度高的机构将被推荐为高相似度机构。方案的核心是基于机构的发文著者量、不同机构间的共有发文著者量计算机构的著者共现关联度。因其主要测度机构发文著者集合间的包容度,不关注个体著者间的相关关系,也不受著者发文多少的影响,故采用相对简约的包容指数[20]进行计算,具体计算公式为:

图2 整体研究思路
Iij=Cij/min(Ci, Cj)
其中Cij是文献集合中机构对(Oi和Oj)共现的发文著者数;Ci是机构i(Oi)在文献集合中出现的发文著者数;Cj是机构(Oj)在文献集合中出现的著者数;min(Ci,Cj)取Ci,Cj中的最小值。
4.3 处理流程
包括以下8个步骤:(1)以机构规范库中各机构为处理对象,依据所在地区进行分组提取,生成地区机构子集。(2)基于CBM数据库,结合发文机构所在地区、文献发表年等维度特征构建相应的地区著者-机构关系表。(3)将著者按机构进行分组,构建“机构-著者空间”。(4)统计各机构发文著者数。(5)若某两个机构有一个相同著者,即表示该两个机构基于著者共现一次,依此遍历生成机构-机构著者共现矩阵。(6)计算机构两两之间的“著者共现”关联度。(7)结合机构类型对关联度按从高到低进行排序。(8)结合人工评测初步划定输出阈值,对高关联度机构进行推荐。
5 效果评测
5.1 测试对象
初步遴选北京、天津、上海3个地区82家机构为测试对象,其中北京27家、天津35家、上海20家。
5.2 统计数据源
CBM 2010-2016年北京、天津、上海上述机构发表的所有文献数据10.3万条。
5.3 评测思路
基于提出的著者共现同一机构/相关机构发现算法,尝试在指定统计数据源中对各地区遴选医院的著者共现情况进行统计,根据共现频率计算机构间著者共现关联度,分析预设推荐阈值并对高关联度机构推荐结果进行输出。通过人工判定对推荐结果的准确性进行分析评价。
5.4 评测结果
经统计共2 100个机构对间存在著者共现情况,部分数据示例,见图3。随机遴选300个机构共现对,对比分析阈值<0.5、<0.4、<0.3、<0.2及0.1的误判率,从希望较高准确性的角度考虑,各段阈值内推荐结果的误判率,见图4。预设推荐阈值为≥0.4,共输出90个机构共现对。

图3 著者共现关联度计算——北京地区部分数据示例

图4 各段阈值推荐结果误判率
5.5 结果分析
人工测评结果,见表2。通过统计分析可以看出输出的90个机构共现对中,人工认为77个机构对是同一机构或高关联度机构,部分数据示例,见图5。推荐结果的准确率为85%,具有较好的可参考性。
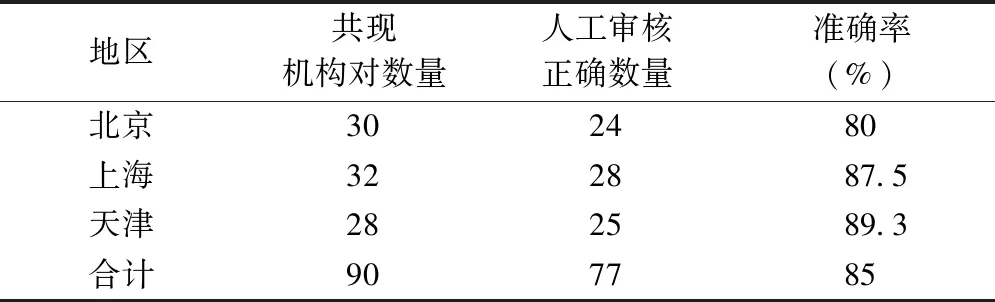
表2 机构著者共现关联度计算人工测评结果

图5 机构著者共现关联度计算——专家判定部分数据示例
6 结语
本文基于目标应用环境中国生物医学文献数据库,从著者这个重要关联因素着手开展基于共现分析的机构名称规范机制研究,提出基于著者共现的同一机构/相关机构发现算法。经测试评估,该算法推荐结果具有较高的可信度,是对当前相似度同一机构发现方法的有益补充。后续将进一步优化算法,实现过程中的数据处理细节问题,尽快推进其在CBM机构规范文档建设中的实践应用。
