融入多特征的汉越新闻观点句抽取方法
2019-11-18林思琦余正涛郭军军高盛祥
林思琦,余正涛,郭军军,高盛祥
(昆明理工大学 信息工程与自动化学院,云南 昆明 650504)
0 引言
在自然语言处理领域中,观点分析主要解决的是对文本情感极性的判别。但新闻文本有较多与观点无关的信息,导致了新闻情感分类效果不足。普遍的解决方法是先对新闻的观点句进行抽取,然后基于观点句对新闻的情感进行判别。在越南语方面,越南语新闻的观点句标记语料较少,导致了越南语新闻的观点句抽取效果较差。而中文的观点句标记语料较为丰富,因此本文使用丰富的中文标记语料缓解越南语标记资源缺失的问题。
在汉越双语新闻观点句抽取任务中,首先解决汉语和越南语之间的跨语言问题。Zhou[1-3]等解决跨语言情感分析的方式是通过机器翻译将源语言翻译为目标语言。但是基于机器翻译的方法只能解决大语种之间语料资源不平衡的问题。对于越南语小语种来说,机器翻译效果的不足导致了观点句抽取模型的效果较差。本文使用跨语言表示学习的方法来解决跨语言的问题。跨语言表示学习的观点是不同语言的词向量表示可以共享一个向量空间,不同语言中语义相近的词在该空间中的距离相近。Mikolov等[4]提出将双语单词进行对齐,并训练得到了源语言词向量空间到目标语言词向量空间的线性映射。Faruqui等[5]提出将源语言和目标语言的词嵌入映射到同一个向量空间。Klementiev等[6]提出在单语词嵌入的目标函数中添加跨语言正则项的方法来得到双语词向量。Sarath等[7]提出通过自编码器对源语言进行编码,同时源语言和目标语言进行解码来得到双语的词向量。
在观点句抽取任务中,现有的方法主要是基于观点句特征来对文档中的观点句进行抽取。刘培玉等[8]提出了通过隐马尔可夫模型对句子进行序列标注,给句子不同的权重来实现观点句的识别。赵虹杰等[9]定义了句子位置、情感词、特征词等属性,并通过集成学习进行观点句识别。Kim等[10]通过词典的方式获得观点词和非观点词的词集,然后计算观点词的强度,最后通过句子中所有词的观点词强度来对观点句进行判别。罗文兵等[11]提出对词权重和情感信息进行综合排序来抽取观点句。Riloff等[12]使用Booststraping算法来训练观点句的特征并对观点句进行分类。刘荣等[13]提出一种基于语义模式的半监督中文观点句识别方法,通过融入语义特征对观点句进行分类。田海龙等[14]提出了一种基于三支决策分类器的微博观点句识别方法。但是上述方法只考虑了观点句的特征,较少考虑句子的语义信息。随着深度学习在自然语言处理领域的广泛应用,本文提出将特征和文本理解结合的思想对观点句进行抽取。
首先采用跨语言表示学习的方法构建汉越双语词嵌入模型。该模型通过对中文和越南文的词嵌入进行联合训练,得到汉越双语词向量。然后提出一种融入多特征的观点句抽取方法。该方法首先定义了句子主题、情感和位置特征,然后将这些特征融入编码层和注意力机制中,得到了句子在主题、情感和位置等方面的表征。最后根据得到的句子表征进行观点句分类。
1 汉越双语词嵌入模型
双语词嵌入模型可以使不同语言中语义相似的词在双语词向量空间中的距离接近。现有的双语词嵌入模型主要是使用大量的双语平行语料进行构建,但汉越平行语料同样难以获取。因此,本文通过对单语词嵌入模型进行联合训练的方式,构建汉越双语词向量。
本文构建汉越词曲嵌入模型如图1所示,主要分为2部分内容。
(1) 用大量的中文语料和越南语语料分别训练汉语和越南语的词嵌入模型。
(2) 用少量的中文和越南语平行句子对汉语和越南语词嵌入模型进行联合训练。
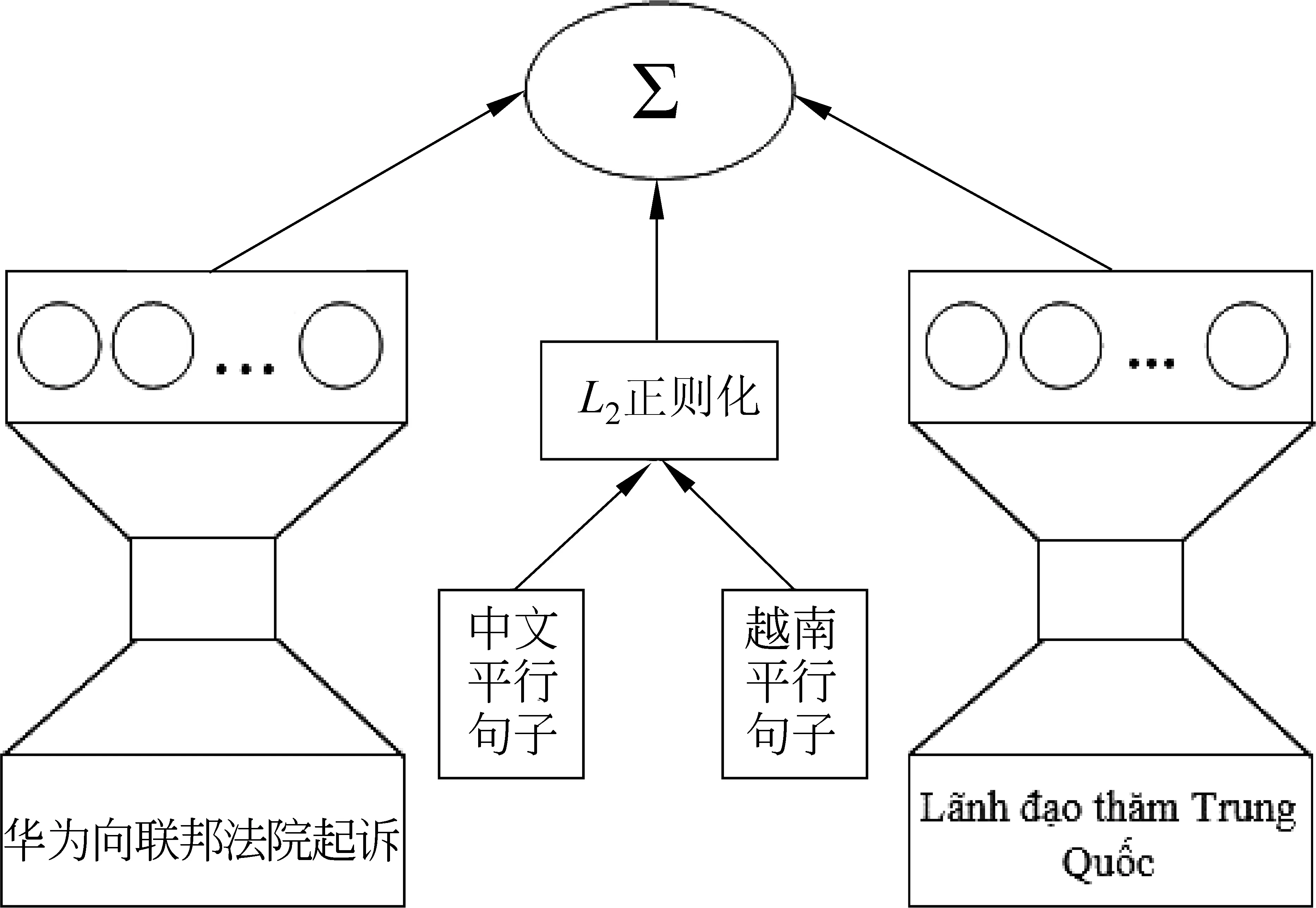
图1 汉越双语词嵌入模型
在联合训练过程中,汉语和越南语的目标函数L如式(1)所示。
(1)
其中,L(wt,h;θl)表示单语词嵌入模型的目标函数,正则项Ω(θc,θv)则表示中文词语和越南语词语的关联程度。我们用汉越双语的正则化项Ω(θc,θv)对单语模型进行约束,不仅可以学习到单语环境下不同词汇的关联关系,同时还可以学习到中文词语和越南语词语之间的关联关系。
本文不仅考虑到中文和越南语词语之间的语义关联,还考虑到它们之间的情感关联,并赋予这两种关联约束不同的权重。汉越双语正则项约束Ω(·)的定义如式(2)所示。
Ω(Rc,Rv)=λ1Ωtranslation(Rc,Rv)+λ2Ωemotion(Rc,Rv)
(2)
其中,λ1和λ2分别表示语义关联和情感关联这两种关联约束在训练过程中的权重。Rc和Rv分别表示汉语和越南语的词向量。
汉越双语正则化约束Ω(·)的具体计算如式(3)所示。
(3)
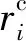
2 汉越双语观点句抽取
现有观点句抽取方法是基于观点句特征对句子进行分类,但该方法没有考虑句子的语义信息。本文将基于注意力机制的LSTM网络用于观点句分类的任务中。LSTM网络可以识别句子的语义信息,注意力机制可以对观点句相关的信息进行表征。句子位置特征、主题相关度特征和句子情感特征对判定该句子是否为观点句有重要作用。但是传统的LSTM网络和注意力机制无法识别这些信息。因此,本文将句子的情感、主题、位置等观点句相关特征融入编码层和注意力机制中,来提升观点句抽取的效果。具体的观点句抽取模型如图2所示。
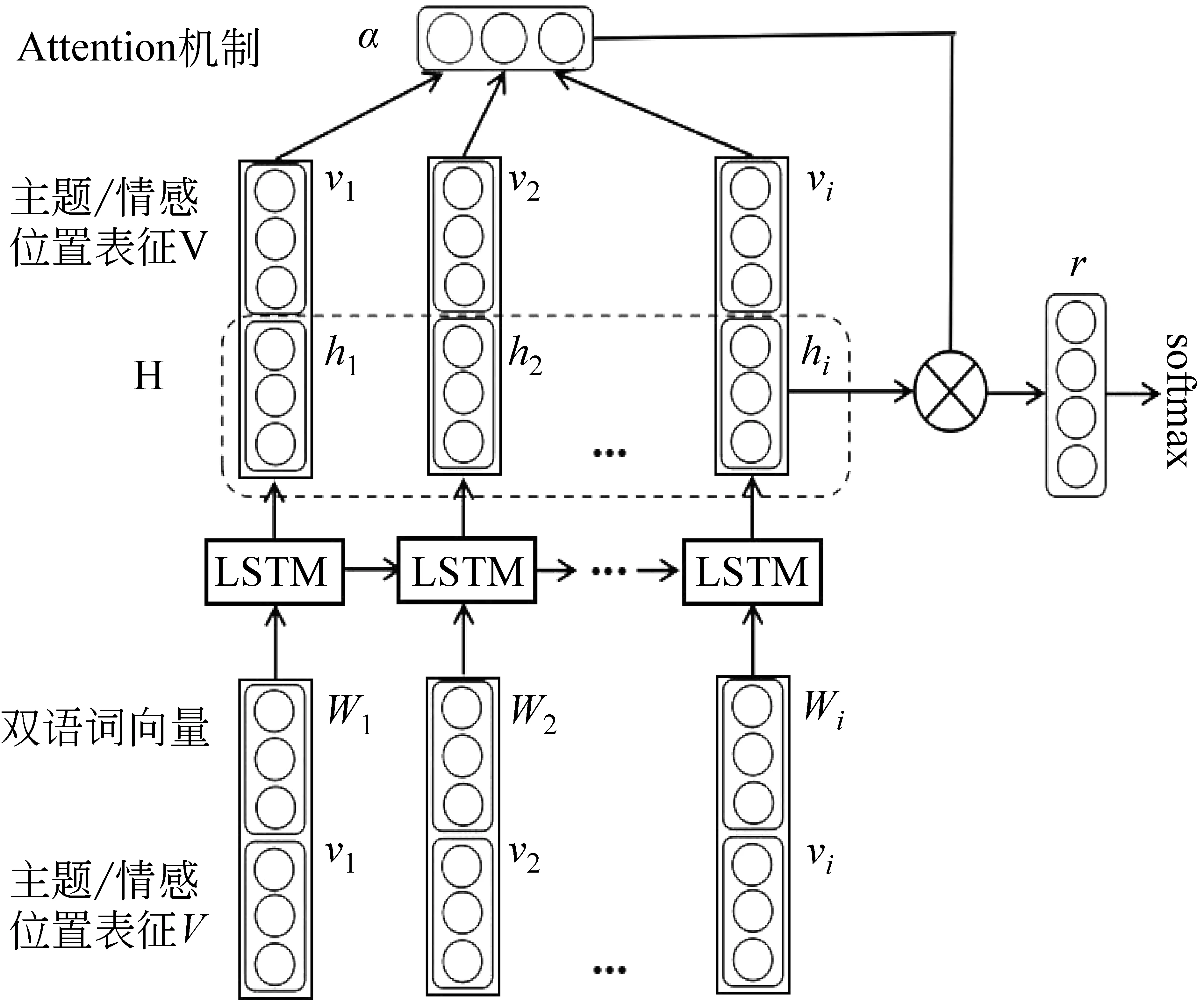
图2 汉越观点句抽取模型
在新闻文档中,新闻的标题很大程度上能反映这篇新闻的主题。因此本文将新闻的标题作为该新闻的主题。句子主题相关度score1的计算如式(4)所示。
(4)
其中,ST表示新闻标题的向量表征,S表示新闻中每个句子的向量表征。
句子位置特征主要考虑的是句子在文档中的位置。因为新闻文档的开头或结尾一般能体现作者的观点,所以句子在文档中的位置打分score2如式(5)所示。
(5)
其中,n表示文档中的句子数目,i表示当前句子是文档中的第i句话。
句子的情感特征主要是用来识别句子是否具有情感倾向。我们通过情感词典来计算句子的情感打分。句子si的情感打分score3如式(6)所示。
(6)
其中,emotion(wi,k)表示词wi,k是否为情感词,如果该词是情感词,则emotion(wi,k)的值为1;否则为0。m表示句子中词的个数。
在词嵌入层中,我们首先用汉越双语词嵌入模型将中文或越南语的词映射为双语词向量。然后在双语词向量后拼接词所在句子的主题相关度特征、情感特征和位置特征。图2中,Wi表示第i个词的双语词向量。vi是第i个词的主题、情感和位置的表征。
由于LSTM网络无法识别隐状态中哪些部分对观点句抽取是有用的。因此,本文引入了注意力机制。注意力机制的核心思想是: 对重要的内容分配较多的注意力,对其他部分分配较少的注意力。在观点句抽取任务中,位置信息、情感信息和主题相关度对判断观点句具有重要作用。因此,我们将这些特征融入注意力机制中,通过注意力机制来捕捉与观点句抽取任务相关的信息。注意力机制的公式如式(7)~式(10)所示。
(7)

式(7)中,H是LSTM网络中每个神经元输出的隐向量组成的矩阵。V是词编码层中每个词所在句子的主题、情感、位置特征向量组成的特征矩阵。Wh和Wv是参数矩阵。在式(8)中,计算得到的α是注意力机制的权重向量。在式(9)中,计算得到的r是主题相关度、位置信息和情感信息在句子表征中的权重。在式(10)中,h*是句子在主题、位置、情感等方面的表征。
为了对句子进行分类,要添加一个隐藏层,将句子压缩为一个二维向量。然后,通过softmax分类器将二维句子表征变为条件概率分布的形式,如式(11)所示。
y=softmax(Wsh*+bs)
(11)
我们定义模型的损失函数为交叉熵损失,如式(12)所示。
(12)
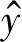
3 实验
3.1 数据准备
本文从汉越新闻语料库中选择35 000篇汉语、越南语新闻,以及10 W条汉越平行句对来训练汉越双语词向量。手动挑选并标记了1 367篇越南语新闻观点句和8 552篇汉语新闻的观点句作为汉越新闻观点句抽取的数据集。训练集、测试集、验证集在数据集中的占比分别为90%,5%,5%。在采用的汉越双语情感词典中,中文情感词典规模为4 626,越南文情感词典规模为2 939。
3.2 实验设置
使用skip-gram训练单语词嵌入模型。在训练汉越双语词嵌入模型时采用异步随机梯度下降的方法,分别为单语词嵌入损失计算和汉越双语正则化误差计算设置不同的线程。将式(2)中的λ1和λ2分别设置为0.7和0.3,双语词嵌入模型的学习率设置为0.1。由于中文和越南文的词表规模较大,因此在词表中过滤掉在文档中出现次数少于两次的词,来加速模型的训练。本文设定训练得到的双语词向量维度为200维。在训练双语观点句抽取模型的过程中,采用了Adagrad优化方法,设定交叉熵损失中的L2正则化权重为0.01,模型的学习率为0.1。
3.3 评价指标
本文采用准确率、召回率、F1值作为评价指标。准确率P、召回率R和F1值的计算如式(13)所示。
(13)
式(13)中,a表示模型将观点句预测正确的个数,b表示模型将非观点句预测为观点句的个数,c表示模型将观点句预测为非观点句的个数。
3.4 实验结果
为了验证在越南语标记语料缺失的情况下,是否可以通过训练汉越双语词嵌入模型,使用中文标记语料来提升越南语观点句抽取的效果,设置了第一组实验。在实验1中,对比了越南语观点句抽取模型和汉越双语观点句抽取模型的效果。
实验结果如表1所示,汉越双语观点句抽取模型在准确率P、召回率R和F1值上更高。该实验证明了汉越双语词嵌入模型和观点句抽取模型可以缓解越南语标记缺失的问题,提升越南语新闻观点句抽取的效果。

表1 越南语观点句抽取和汉越双语观点句抽取效果对比
为了验证在汉越双语词嵌入模型中使用不同规模的平行句子对下游观点句抽取的影响,设置了第2组实验。实验结果如图3所示,横坐标表示的是汉越平行句对的规模,纵坐标表示的是越南语观点句抽取模型的准确率。本文认为随着汉越平行语料规模的扩大,汉越词对齐的规模也在扩大,那么汉越双语词嵌入模型就能更好地捕捉汉语和越南语之间的关联关系,对于下游越南语观点句抽取的效果也有所提升。图3的实验数据也证明了该猜想。

图3 不同平行句子规模的效果对比
为了验证将主题相关度特征、位置特征、情感特征融入词向量和注意力机制的效果,设置了第3组实验。实验结果如表2所示。
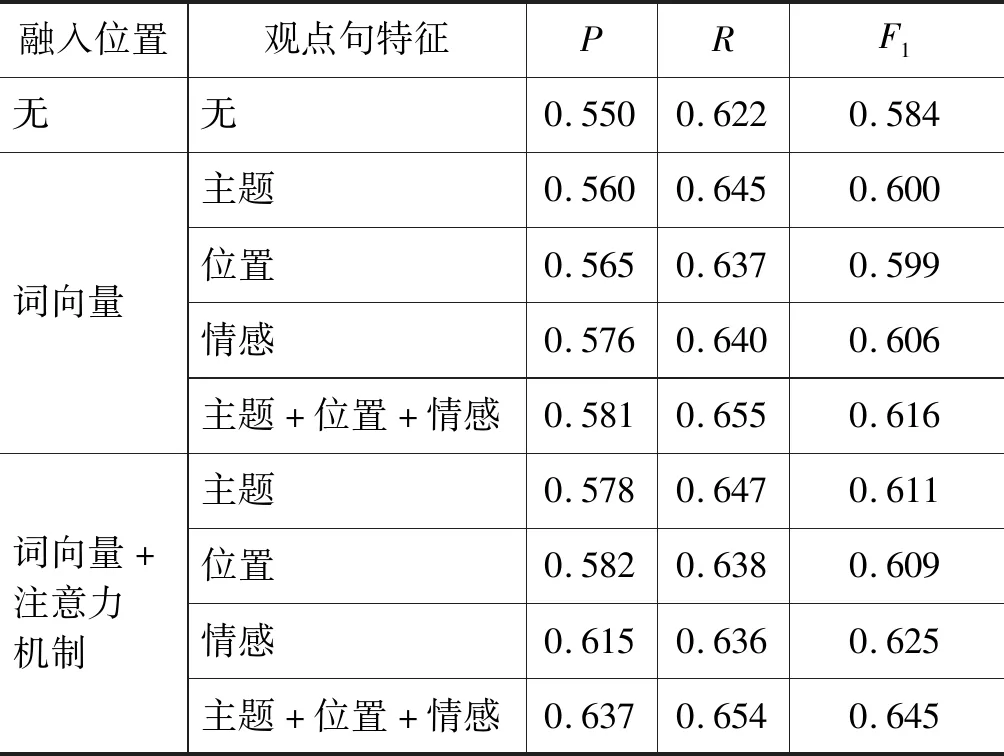
表2 不同位置上融入不同观点句特征的效果对比
从表2中可以发现以下几点: 首先,相比较句子主题特征和位置特征,融入句子情感特征更能提升观点句抽取的准确率。其次,相比较在词向量中融入句子主题、位置和情感特征,同时在词向量和注意力机制中融入这些特征的准确率更高。这一点说明了同时在词向量和注意力机制中进行融入的方法更能表征句子中的观点句相关信息。最后,同时在词向量和注意力机制中同时融入主题、位置和情感特征的方法取得了最好的效果。
4 总结
本文提出了一种汉越双语新闻观点句抽取方法,该方法针对越南语标记语料缺失的问题,提出了使用汉越双语词嵌入模型来构建汉语和越南语之间的联系。然后针对现有观点句抽取模型没有同时考虑句子语义信息和观点句特征的问题,提出了融入情感、主题和位置等多特征的观点句抽取模型。下一步工作将研究如何使用观点句来提升越南语新闻观点分类的效果。
