基于上下文词向量和主题模型的实体消歧方法
2019-11-18李弼程杜文倩
王 瑞,李弼程,杜文倩
(华侨大学 计算机科学与技术学院,福建 厦门 361021)
0 引言
伴随大数据时代的来临,网络文本的爆炸式增长带来了严重的“信息过载”问题。互联网数据中存在的海量冗余信息、虚假信息和噪声信息导致用户查询和浏览有用信息变得愈发困难。因此快速准确地匹配目标信息变得尤为重要。为了准确地获取目标信息,需要处理海量无用内容。这一问题源于自然语言表达的多义性,具体来讲,同一实体可以用不同的文本表达(多样性),同一文本也可以表达不同的实体(歧义性)。实体消歧是海量文本分析的核心技术之一,主要解决实体名的歧义性和多样性问题,为解决信息过载问题提供了有限的技术手段。另外,实体作为知识图谱的基本单元,是承载文本信息的重要语言单位,而消除实体的歧义在知识图谱构建的过程中发挥着承上启下的作用。所以,实体消歧是知识图谱构建和补全的关键技术。
1 相关工作
目前已经有很多方法被提出用于实体消歧,根据模型的差异,实体消歧方法可以划分成基于机器学习的方法和基于深度学习的方法。
1.1 基于机器学习的方法
在基于机器学习的方法中,实体消歧的核心是计算实体之间的相似度,在此基础上选择特定实体提及的目标实体。Milne等[1]利用实体统计信息、名字统计信息进行目标实体消歧。Han等[2]利用百科数据作为背景知识,通过百科知识辅助消歧。Ji等[3]考虑到一段文本中实体之间的相互关联,提出用全局推理算法寻找全局最优决策。另外,为解决语料标注问题,近年来已经开始研究高效的弱监督或无监督策略。Shen等[4]对实体流行度、语义关联度等特征进行特征组合,利用最大间隔算法计算各个特征的权重,进而通过排序算法完成对实体的消歧。此外,Agichtein等[5]提出的半监督算法、Etzioni等[6]提出的远距离监督算法以及Shi等[7]提出的基于海量数据冗余性的自学习方法也从一定程度上解决了语料标注的问题。
1.2 基于深度学习的方法
在基于深度学习的方法中,实体消歧的核心是构建多类型、多模态上下文及知识的统一表示,并对多源信息、多源文本之间的联系进行建模。深度学习方法通过将不同类型的信息映射到相同的特征空间,并具有高效的端到端训练算法,给上述任务提供了强有力的工具。Francis等[8]在原有的神经网络语言模型的基础上,加入了卷积神经网络(convolutional neural network,CNN)模型,较大程度上改进了实体消歧的效果。Ganea等[9]提出多源异构证据的向量表示学习方法,对不同来源知识库中的知识进行统一空间的表示,进而完成实体消歧。Sil等[10]提出对证据信息进行向量表示,基于表示向量学习不同证据之间的相似度,继而进行相似度融合,最终完成实体消歧。毛二松等[11]提出利用Skip-Gram模型进行词向量训练,并利用词向量进行相似度计算,实现实体链接与消歧。怀宝兴等[12]提出将待消歧实体和待消歧实体上下文语境映射到同一个空间,基于概率空间模型,根据实体的空间向量进行消歧。冯冲等[13]利用Skip-Gram模型进行词向量训练,并基于微博的短文本特征提出语义分类的方法,完成实体消歧。
综上所述,基于机器学习的方法需要借助丰富的标注语料完成实体消歧,基于深度学习的方法需要借助性能良好的消歧模型完成实体消歧。但是,目前实体消歧方法存在如下两个问题:
(1) 由于传统的有监督机器学习算法需要大量的标注语料,而现有的标注语料难以满足实体消歧的需求。词向量训练模型使用无标注的文本作为输入数据,将词组表征成低维的向量表示,可以有效解决缺少标注语料的问题。然而,传统词向量模型由于缺少对于上下文语序等必要因素的考虑,导致词向量的语义表征能力不强,需要进一步改进。
(2) 在实体消歧的过程中,目前主流方法选用上下文语义特征、实体流行度特征、实体关联度特征等进行命名实体消歧。上述特征均是从实体背景文档的全局特征出发,计算待消歧实体和候选实体之间的相似度,没有考虑实体的局部特征。潜在狄利克雷分布(latent dirichlet allocation,LDA)主题模型可以获取实体背景文档的主题信息,将其结合词向量技术生成主题词向量,可以对背景文档的局部主题特征进行表征,较好地解决传统模型仅考虑实体全局特征的缺陷。
因此,本文提出基于上下文词向量和主题模型的实体消歧方法。实验表明,相比现有的主流消歧方法,该方法是有效的。
2 基于上下文词向量和主题模型的实体消歧方法
本文方法包括三个部分: 上下文词向量模型训练、候选实体生成和实体消歧,其流程如图1所示。
首先,为解决传统词向量模型仅考虑词共现特征导致的语义表达能力不强的问题,在原有Skip-Gram模型的基础上增加表征上下文语序的方向向量,利用无标注语料训练词向量模型,将每个词表示为n维的向量;其次,获得实体指称项的背景文档,获得候选实体在知识库中存储的背景知识,并使用上述词向量模型,将二者均表征为向量形式,针对实体的全局特征,分别计算上下文相似度和类别主题相似度;然后,基于词向量模型以及LDA主题模型,结合文档的主题特征,训练主题词向量,针对实体的局部特征,进行实体主题相似度计算;最后,按一定比例融合三种相似度特征,得到待消歧实体与候选实体的最终相似度,选取相似度最高的候选实体作为待消歧的最终实体。

图1 实体消歧流程图
2.1 基于上下文的词向量模型训练
Mikolov等[14]提出的连续词袋模型和Skip-Gram模型是目前词向量训练的常用模型,都可用于大规模语料的向量化训练,其中Skip-Gram模型在语义表征层面上效果更佳。但是传统Skip-Gram模型未考虑当前词的上下文词序对于语言模型的影响。词序是影响语言生成的一个重要因素,一个词语左侧或右侧的词语应该对当前词语产生不同的影响。针对该问题,本文设计了一种上下文词向量模型,在Skip-Gram模型的基础上加入方向向量来表达语序[15]。
实体消歧的核心是语义相似度计算,词向量的表达能力越强,携带的语义信息会越多,两个实体之间的特征区分度就越大,相似度计算结果就越精确。相比传统的训练模型,上下文词向量模型可以携带更多的语义信息,进而能够提高相似度计算的准确性。具体步骤如下:
首先,定义预测上下文词的概率函数,用于计算当前输入词t与上下文词t+i之间的共现概率,其定义如式(1)所示。
(1)
其中,V表示语料中词语的个数,wt表示词语t的词嵌入,w′t+i表示词语t+i的词嵌入,w与w′分别表示输入词嵌入与输出词嵌入。
然后,定义softmax函数g(t+i,t)度量上下文词t+i与输入单词t之间的词序关联。softmax函数g(t+i,t)的定义如式(2)所示。
(2)
其中,δ表示任意上下文词t+i相对于t的方向向量,借助负采样的原理,每次让一个训练样本仅仅更新一部分的权重,所以函数g(t+i,t)的更新如式(3)所示。

然后,根据上述定义的softmax方法定义基于上下文词向量模型的目标函数LDSG,如式(5)所示。
(5)
其中,c表示词向量的窗口大小f(wt +i,wt)=p(wt +i|wt)+g(wt +i,wt)。
最后,根据上述的目标函数,使用随机梯度下降和反向传播算法来优化模型。其中,词向量的窗口大小为5,词向量的维度为200,模型的初始学习率为0.03。
2.2 候选实体生成
候选实体借助zhishi.me(1)http://zhishi.me/百科数据获取。zhishi.me 通过从开放的百科数据中抽取结构化数据,融合了三大中文百科: 百度百科、互动百科以及维基百科中的数据,首次尝试构建中文通用知识图谱,其数据组织如图2所示。

图2 zhishi.me数据组织图
以往的研究表明,维基百科可以提供构建候选实体有用的特征信息,但是维基百科中的部分中文实体存在更新不及时的问题。zhishi.me综合了维基百科、百度百科以及互动百科的知识,使得实体的内容更加丰富。zhishi.me提供了客观有用的百科知识,如百科实体页面、百科重定向页面、百科消歧页面、超链接以及类别特征,可供构建候选实体使用。
候选实体生成的步骤如下: 首先,人工标注含有歧义的实体,作为待消歧实体;其次,根据待消歧实体百科实体页面提供的信息,获取待消歧实体在百科中的实体名称;再次,利用百科消歧页面寻找与待消歧实体名称相同但指代不同的实体;最后,将所获得的与待消歧实体名称相同的所有实体作为候选实体。
2.3 实体消歧
实体消歧的重点是计算待消歧实体与候选实体的相似度。全局特征是指实体的整体属性,用于描述实体的上下文、类别等整体特征。常见的全局特征包括上下文特征、类别特征和实体流行度特征等。全局特征具有表示直观、不变性良好等特点,但语义丢失、多义词表示困难是其缺点所在。局部特征是从实体的局部区域中抽取的特征。实体的局部特征主要是实体在特定语义场景下的主题信息。针对实体的全局特征,本文采用实体上下文相似度和实体主题类别相似度描述;针对实体的局部特征,本文采用基于主题词向量的主题相似度描述。
2.3.1 实体上下文相似度
首先,获取待消歧实体的背景文本,分词、去停用词后,根据2.1节训练的词向量模型,将处理的结果进行词向量表征,得到待消歧实体的上下文语境。同时,根据zhishi.me的离线数据,获得候选实体在知识库存储的摘要及全文信息,进行数据预处理,并使用上下文词向量模型进行词向量表征,得到候选实体的上下文语境。通过对处理好的向量进行余弦相似度计算,确定实体指称项和候选实体的实体上下文相似度。
针对待消歧的实体entity,背景文档经过分词和去停用词之后,将实体指称项上下文表示为E(entity)={word1,word2,…,wordk},其中k表示实体指称项的上下文词的个数。使用训练好的词向量模型将文本进行词向量表示,向量表示为w(wordi)={w1,w2,w3,…,wn},其中n表示词向量的维度,wordi表示第i个上下文词语。针对候选实体,通过在知识库中获得实体的摘要和全文信息,同样使用词向量训练模型进行向量化操作,向量表示为E(entity′)={word′1,word′2,…,word′m},其中m表示实体候选项的上下文词语的个数。使用训练好的词向量模型进行向量化表示,向量表示为w(word′j)={w1,w2,w3,…,wn},其中n表示词向量的维度,word′j表示第j个上下文词语。通过计算余弦相似度的方法计算候选实体与实体指称项的上下文相似度,余弦值越大,相似度越高。相似度计算式如式(6)所示。
sim1(entity,entity′)
(6)

2.3.2 基于实体上下文主题的类别主题相似度
实体主题作为描述实体的重要特征,表示实体语义的相关性。主题就是概念的集合,它也可以表示为若干相关的词语。用数学语言描述,主题就是词语的条件概率分布。
主题和类别作为实体抽象出来的概念,在一定程度上所包含的语义信息是相似的。可将实体主题信息与实体对应的类别信息进行语义相似度计算,类别主题的相似度就是计算通过主题模型获取的上下文主题以及知识库中实体对应类别之间的相似度,其计算流程图如图3所示。

图3 类别主题相似度计算流程图
基于实体上下文主题的类别主题相似度计算过程步骤如下:
(1) 对待消歧实体的背景文档进行预处理。预处理后,获取所有预处理的名词类词语,使用LDA主题模型获取待消歧实体上下文的主题,通过实验选取适当的主题个数作为待消歧实体的主题特征。
(2) 每个实体在知识库中都有对应的类别信息,获取知识库中候选实体的类别信息。
(3) 使用余弦相似度计算公式计算每个主题词与类别词之间的距离,计算x个待消歧实体主题与候选实体y个类别的相似度sim′y(x),选取相似度最大的一项作为基于实体上下文主题的类别主题相似度,如式(7)所示。
sim2(entity,entity′)=max{sim′y(x)}
(7)
以“苹果”为例,在知识库中存在“苹果”的三种主要类别,分别是“科技公司”“蔷薇科植物”以及“爱情电影”。假设使用LDA抽取的文本主题为“乔布斯”“美国”以及“互联网”,那么使用词向量的余弦相似度计算实体的类别主题相似度,结果如表1所示。从表中可以看出,主题对应的相似度最高的类别是“科技公司”,说明该方法是可行的。

表1 “苹果”各主题类别相似度计算结果
2.3.3 基于主题词向量的实体主题相似度
LDA主题模型在文本主题识别方面发挥着重要作用,但是LDA主题模型的概率分布只描述了语料库的统计关系。在实际应用中,概率并不是特征表示的最佳选择。在实体消歧过程中,由于实体的名称可能存在一词多义的情况,所以实体的含义不能仅通过整个文档的主题来表达。针对此问题,本文融合词义信息及主题信息,提出在同一个语义向量空间中,使用嵌入表示的方法学习主题表示的主题词向量。
主题词向量模型(topical word embeddings,TWE),其中主题词是指以特定主题为背景的词。TWE的基本思想是“允许每个词在不同的主题下有不同的嵌入向量”。例如,“小米”这个词在食物主题下表示一个谷作物,而在IT主题下代表一家IT公司。由于主题词向量采用“主题-词”序列的训练方式,将主题和词共同表示为低维的向量。每个主题词向量下的词语都携带了各自的主题信息。相比于全局的主题信息,每个词语携带的主题信息更能表达该词语的语境。所以,利用主题词向量计算实体主题的相似度,能够有效减少一词多义带来的相似度计算误差,提高实体消歧结果的精确度。
基于主题词向量的相似度计算过程包括两个部分: 主题词向量训练以及相似度计算。步骤如下:
(1) 对待消歧实体和候选实体的背景文档进行数据预处理,包括中文分词和去停用词;
(2) 使用LDA主题模型对文档的上下文语境进行主题建模,参数推理使用Gibbs抽样算法,获取每个词语对应的主题词。
(3) 基于2.1节训练的词向量模型,将主题zt融入基于上下文词向量模型中[16]。然后基于上下文主题词向量,通过给定当前词t和当前词的主题zt,预测上下文主题词(zt-2,zt-1,zt+1,zt+2)。将背景文档处理成为词语—主题序列Document={t1:z1,t2:z2,…,tM:zM},其中M表示文档中词语—主题序列的个数,zi是从LDA中推断出的wi的主题词。
(4) 主题词向量模型的训练,通过设置投影矩阵,将主题和词语嵌入同一个语义空间,并定义目标函数L(D)如式(8)所示。
+log(p(t+i|zt)+g(t+i,zt)))
(8)
(5) 考虑到简单和有效的解决方案,遵循Word2Vec中使用的优化方案。最终主题词向量的维度为100,窗口大小为5。
(6) 实体指称项的背景文档对应的主题词向量为tw={tw1,…,twk},实体候选项的背景文档对应的主题词向量为tw′={tw′1,…,tw′m},使用余弦相似度计算基于主题词向量的实体主题相似度[17],定义基于主题词向量的实体主题相似度,定义如式(9)所示。
(9)
综上所述,三种相似度特征之间的比较如表2所示。

表2 三种特征相似度之间的比较
2.3.4 相似度融合
为了保证实体消歧的效果,需要考虑以最优的比例对上述的三种相似度进行融合。利用实体上下文相似度、类别主题相似度以及实体主题相似度,定义最终的相似度计算如式(10)所示。
sim(entity,entity′)=αsim1(entity,entity′)
+βsim2(entity,entity′)
+λsim3(entity,entity′)
(10)
其中,sim1(entity,entity′)表示实体上下文相似度,sim2(entity,entity′)表示类别主题相似度,sim3(entity,entity′)表示实体主题相似度。
相似度融合的步骤为: 按照α+β+λ=1的原则,固定实体上下文相似度特征的权重,调整其他两项的值,即依次固定α=0.1,0.2,…,0.8,改变β和λ的值,得到不同特征权重组合下实体消歧的准确率。例如,固定α=0.1,分别计算β=0.1,λ=0.8;β=0.2,λ=0.7等一系列实体消歧的准确率,取准确率最高的一组值作为α、β、λ的最终取值。
3 实验及结果分析
3.1 评测方法
首先,人工整理了歧义实体库。最初人工整理包含歧义词的实体,如“苹果”“小米”“辣椒”等;接着根据zhishi.me数据中的disambiguation关键字获取包含歧义词的全部实体。例如,“苹果”实体在歧义实体库中被表示为: 苹果(苹果公司、苹果植物、苹果电影)。
然后,根据歧义实体库中的信息,获取zhishi.me的中文离线数据,提取每个实体的维基百科、互动百科以及百度百科的页面信息,共10万条。对语料进行数据预处理,提取每个实体的摘要和全文信息。另外,本文从第三方网站(新华网、人民网等新闻门户网站以及新浪微博等社交网站)爬取与歧义实体相关的贴文,共5万篇,作为词向量模型的训练语料。
最后,人工选取包含歧义实体的文本1 000篇,每个样本中人工标记出歧义实体的正确含义,如文中出现“苹果市值”,将其标注为“苹果(公司)市值”。将其作为待消歧的实体指称项,记为待消歧实体指称集。并根据歧义实体库,人工构建待消歧实体候选集合,记为待消歧实体候选集,用于验证实验结果。其中,实验数据的基本信息如表3所示。
另外,为了测试本文方法在公开数据集上的表现,选用KBP评测2011作为公开数据集。其中,KBP2011数据包括2 250个实体指称。除此之外,获取所有实体指称在英文维基的数据作为知识库背景知识。
本文基于Pycharm以及Anaconda 3.5在Windows 10环境下实现。实验过程包括基于上下文词向量模型训练、文本向量化、候选实体生成、LDA主题提取、实体类别获取、相似度计算以及相似度融合等过程。
语料的预处理过程采用HanLP(2)http://hanlp.linrunsoft.com/分词工具完成,包括分词、去停用词等过程,采用召回率(Recall)、准确率(Precise)与F1值对实验结果进行评估,定义如式(11)~式(13)所示。

(11)

(12)
(13)
3.2 实验结果及分析
本文共进行了以下5个实验。
1) 词向量训练效率实验结果及分析
为了验证本文词向量模型的可用性,选取Skip-Gram[14](SG)词向量训练模型以及Structrual Skip Gram[18](SSG)模型进行训练速度与不同上下文窗口大小的比较。三个模型的对比如表4所示。
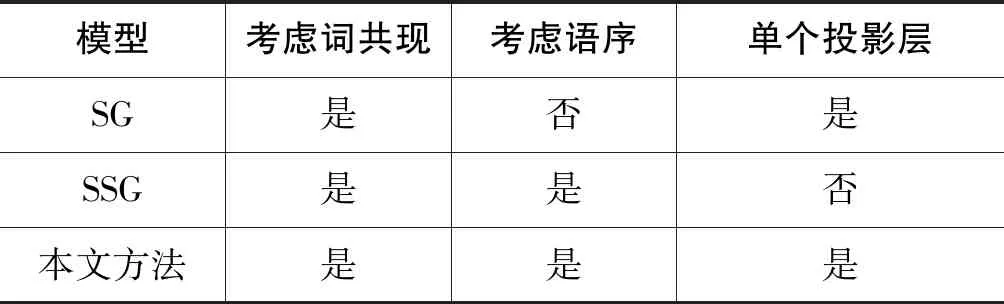
表4 词向量模型对比
在上表中:
(1) SG: 利用一个词与其相邻词之间的关系,利用当前词预测上下文词出现的概率;
(2) SSG: 在上述SG模型的基础上,设置不同的投影层矩阵,使其携带语序信息,与本文方法的区别在于本文只增加一个上下文方向向量用于表征语序特征。
分别选用窗口大小c=1,2,3,4,5,6,7,8,9,10,分析各个训练模型的训练速度与窗口大小的关系,实验结果如图4所示。

图4 训练速度与不同窗口大小比较
实验结果表明,本文方法词向量的训练速度基本与SG模型相同,相比于SSG模型有较大的改进。原因在于本文方法仅增加了表征词序的上下文方向向量,相当于只增加了一个输入向量,没有改变神经网络的内部结构。所以,SG模型的空间复杂度为O(2|V|d),本文方法的空间复杂度为O(3|V|d),而SSG由于为每个投影层设置不同的投影矩阵,其空间复杂度为O((2c+1)|V|d),其中d表示词向量的维度,c表示滑动窗口个数。
另外,SG模型的时间复杂度为O(2c(n+1)V·ζ),本文方法的时间复杂度为O(2c(n+2)V·ζ),而SSG由于为每个投影层设置不同的投影矩阵,其时间复杂度为O(4c2(n+1)V·ζ),其中,ζ表示进行一次词嵌入更新需要的时间开销,n表示负采样样本的个数。
综上所述,本文的词向量训练方法可以在增加词向量语义表达能力的同时,时空复杂度基本与Skip-Gram模型相同,尽可能避免复杂度较高的问题。
2) 基于实体上下文主题的类别主题相似度方法中,主题个数n对于消歧结果的影响
为了获取最优的消歧结果,需要在类别主题相似度计算中确定主题n的个数。基于此进行了10组不同的实验,分别选取n=1,2,3,4,5,6,7,8,9,10时,研究主题个数对消歧结果的影响,结果如图5所示。

图5 不同主题个数的消歧结果
由图5可知,当主题个数n=7时,F1值达到最大值90.3%。原因在于,当主题个数太少时,主题与类别之间的组合相对较少,相似性的度量仅局限在少有的几个主题与类别之间,对于实体指称项的描述不够充分,在语义上区分不够明显,导致实体消歧的准确率不高,从而使得F1值较低。当主题个数太多时,会将语义相差较大的词语或者无区分度的词语引入到相似度的计算中,导致最终消歧结果精度的下降。
3) 相似度特征组合实验结果分析
在实体消歧的过程之中,实体上下文相似度(A_1)、基于实体上下文主题的类别主题相似度(A_2)、基于主题词向量的实体主题相似度(A_3)对于实体消歧的贡献不尽相同,对于最终实体相似度计算的作用也不同。由于相似度特征组合对召回率无影响,所以该部分的实验只针对准确率。实验结果如图6所示。

图6 不同相似度特征组合实验结果
由实验结果可知:
(1) 仅利用单一的相似度特征准确率比使用相似度特征组合方法低。原因在于单一的特征存在自身的局限性,比如在挑选最终候选实体时,使用实体上下文相似度和基于实体上下文主题的类别主题相似度仅考虑待消歧实体的全局特征,基于主题词向量的实体主题相似度仅考虑待消歧实体局部特征,三者均过于片面。
(2) 使用A_1+A_3和A_2+A_3的准确率高于A_1+A_2的准确率,原因在于使用A_1+A_2特征组合的方法仅考虑了待消歧实体的全局特征,而使用A_1+A_3和A_2+A_3则是综合考虑了全局特征以及局部特征,因此准确率相对较高。
(3) 使用A_1+A_2+A_3的相似性度量方法准确率最高。原因在于,综合三种特征,实体的上下文信息特征是从实体的具体内容出发对实体进行描述,实体的类别与主题信息是在上下文的基础上的抽象与概括,基于主题词向量的信息是针对词和词的主题建模,充分考虑了歧义词的一词多义性在同一文档中出现的概率。因此,综合三种信息的相似度度量,准确率较高。
4) 特征权重组合实验结果分析
在实体消歧的过程之中,实体上下文相似度权重(α)、基于实体上下文主题的类别主题相似度权重(β)、基于主题词向量的实体主题相似度权重(λ)对于最终实体相似度计算的作用不同。通过组合不同的特征权重进行对比实验,选取一组最优的权重组合。由于相似度特征权重组合对召回率无影响,所以该部分的实验同样只针对准确率。实验结果如图7所示。
实验结果表明,当α=0.4,β=0.2,λ=0.4时,实体消歧的准确率最高。主要原因在于,实体上下文相似度与主题相似度包含更多的语义信息,在进行实体消歧的过程中,起了较为重要的作用。而类别主题相似度包含的语义信息相对较少,所以其权重若是很高,则会丢失一部分语义信息,造成消歧结果较低。
5) 本方法与主流方法的对比实验
为验证本文方法的可行性,针对本文构建的数据集以及公开数据集,对比5种主流实体消歧方法的召回率,准确率以及F1值,5种方法分别是Wikify[19]、Random Walk[20]、Knowledge Base[21]、基于语义分类的实体链接方法[13](semantic classification based on word emmbedding,SCWE)以及Skip-Gram+LDA[22],实验结果如表5所示。

图7 特征权重组合实验结果
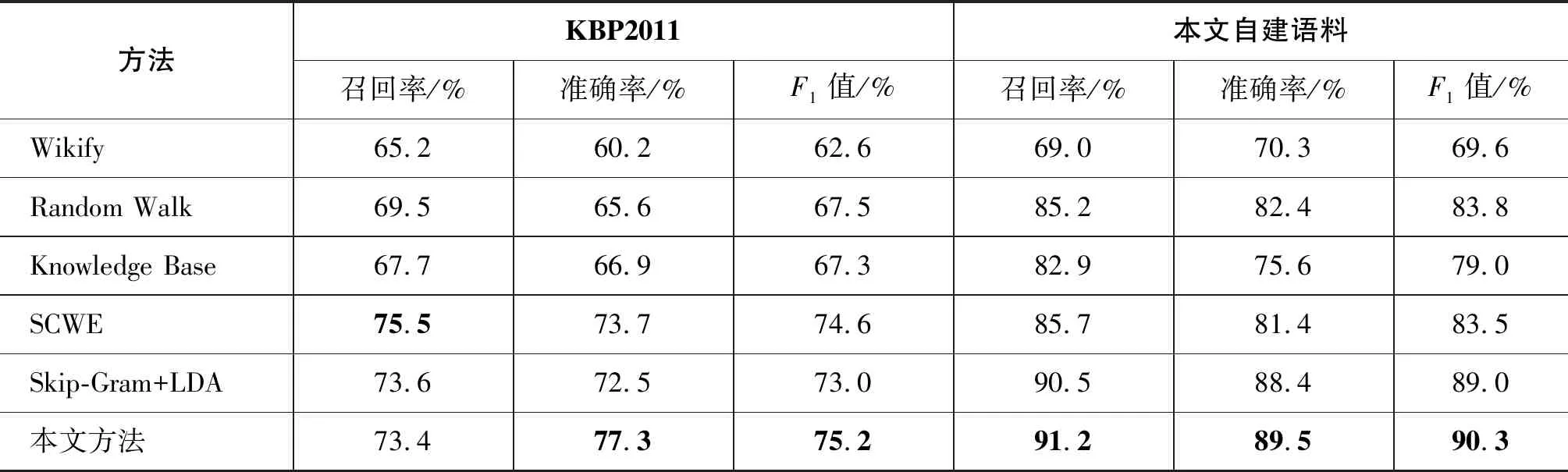
方法KBP2011本文自建语料召回率/%准确率/%F1值/%召回率/%准确率/%F1值/%Wikify65.260.262.669.070.369.6Random Walk69.565.667.585.282.483.8Knowledge Base67.766.967.382.975.679.0SCWE75.573.774.685.781.483.5Skip-Gram+LDA73.672.573.090.588.489.0本文方法73.477.375.291.289.590.3
(1) Wikify: Wikify进行实体消歧的基本思想是统计词语在维基百科文本中链接到对应概念的概率,链接概率较大的将被确认为是候选链接。
(2) Random Walk: Random Walk进行实体消歧的基本思想是基于随机游走算法定义维基概念相似度计算方法,并将该方法应用于实体指称项和实体候选项的相似性计算之中。
(3) Knowledge Base: Knowledge Base进行实体消歧的基本思想是知识库中获取先验知识,结合获取的先验知识以及一系列的证据信息(实体流行度等)进行实体消歧。
(4) SCWE: 基于语义分类的实体链接方法进行实体消歧的基本思想是训练词向量模型,将实体聚类获得类别标签作为特征,再通过多分类模型预测目标实体的主题类别特征,结合实体流行度特征进行实体消歧。
(5) Skip-Gram+LDA: Skip-Gram+LDA进行实体消歧的基本思想是采用传统的Skip-Gram模型进行词向量的训练,然后借助LDA主题模型获取背景文档的主题,两者相结合定义相似性度量方法,进而完成实体消歧。该方法与本文的区别在于: 首先,该方法选用的是Skip-Gram模型进行词向量的训练,本文对该模型进行了优化;其次,该方法的上下文相似度计算使用TF-IDF进行词权值计算,本文采用词向量的方法进行计算;再次,该方法使用聚类的方式获取类别信息,本文使用从知识库中查找实体类别的方法获取实体的类别信息。最后,该方法没有使用主题词向量进行相似度计算。
由表5可知,在公开数据集KBP2011上,本文方法的准确率和F1值都比主流方法要高,但是召回率没有达到最优。上述5种方法均使用百科知识发现候选实体,但本文使用待消歧实体名在百科中自动发现候选实体,在大多数情况下与人工构建差别不大,但是对于KBP2011的某些人物实体,本文方法并不能准确发现其候选实体。在自建语料库中,本文的三个指标均达到了最优,原因是本文采用zhishi.me进行候选实体的生成,其他方法均是使用维基百科进行候选实体生成,zhishi.me融合了三大百科信息,对于实体的描述也更加详细。另外,本文综合考虑了实体的全局和局部特征,改进了输入的词向量,在语义层面提高了相似度计算的精度,所以本文的准确率也较高。最后,自建语料的准确性和公开语料准确性差异比较大。主要原因在于: ①KBP2011数据集中部分实体过于少见,在知识库中找不到对应的候选实体或者候选实体与该实体对应不上,导致消歧结果降低。另外,部分人物实体的候选实体过多且相互之间区分度很小,导致最终消歧出错; ②自建语料库经过了严格的人工筛选和标注,为之后的候选实体生成以及实体消歧提供了良好的数据支撑; ③虽然两者均为实体消歧语料,但是自建语料是基于中文构建的语料,KBP2011是英文语料。区别在于中文语料拥有百度百科、维基百科以及互动百科三大平台的知识,而英文语料只有维基百科的知识,从一定程度上也解释了英文语料的召回率及准确率低的问题。
4 结束语
本文针对现有的实体消歧方法中词向量模型表达能力弱以及缺少对局部主题信息考虑的情况,提出基于上下文词向量和主题模型的实体消歧方法。在原有Skip-Gram词向量训练模型的基础上,增加了表示上下文词序的方向向量,并且基于该方法训练词向量模型与主题词向量模型。基于上述词向量和主题词向量模型进行三种相似度特征的计算,进而融合三种相似度,确定最终的消歧实体。实验表明,相比于现有的方法,本文方法实体消歧效果更有效。
下一步工作首先是针对语料库进行扩展,并定义完善的标注体系,更好地辅助实体消歧;其次是在实体消歧的基础上,针对事件中包含多个实体的问题,综合考虑各个实体的权重,为事件消歧设计消歧模型;再次是利用现有的深度学习模型自动学习实体的特征,以寻求实体消歧更优的特征,改进实验结果;最后是综合实体消歧的方法,结合事件抽取,为事件知识图谱的构建提供有效的前期支撑。
