Bi-LSTM+Attention情感分析模型的设计与实现
2019-11-18张量杨元峰李金祥金益刘媛霞
文/张量 杨元峰 李金祥 金益 刘媛霞
1 引言
情感分析(Sentiment Analysis)是自然语言处理任务中的重要组成部分,其概念最初在2003年由Nasukawa等人[1]首次提出,其标准定义为:情感分析是对文本中关于某个实体的观点、情感、情绪及态度的计算研究[2]。它在评论筛选分类、意见挖掘、用户分类聚类、网络舆论预测等应用领域有着极其重要的意义。
基于文本(自然语言)的情感分析通常可分为基于情感词典的方法、基于机器学习的方法和基于深度学习的方法的三类:
(1)基于词典的情感分析方法是一种典型的无监督学习方法。它依靠情感词典和规则,通过计算情感值作为文本的情感倾向依据。这类方法其对情感词典的依赖成为其应用与发展的主要障碍。
(2)基于机器学习的方法由Pang等人[3]提出,它将文本情感分析看作分类问题。然而,传统机器学习方法通常仅在某一特定领域表现优秀,泛化能力较差、拟合精度不高。
(3)基于深度学习的方法较好地避免了上述两类方法的弱点。它最早被应用于机器视觉和语音识别中,并取得了巨大成功。近年来,在自然语言处理和情感分析问题的研究工作中也备受关注。代表性工作包括如:Text CNN[4],RNN[5]等。
2 相关概念
2.1 LSTM与Bi-LSTM
长短期记忆模型(Long Short-Term Memory,LSTM)由 Hochreiter提出[6],作为一种特殊的循环神经网络(RNN)模型,它能够捕捉语句中的长期依赖关系,从而更好地从整体上理解文本的情感。其记忆单元结构如图1所示。
记忆单元中设置了3种门结构:遗忘门ft、输入门it和输出门Ot,用于记录和更新记忆单元的信息。其中各个门t时刻的状态更新状态如下:

其中:x表示输入数据,h表示LSTM的单元输出;C表示记忆单元值,σ表示sigmoid函数;Wf、Wi、Wo、bf、bi、bo分别表示3个门的权重以及偏置值。式(4)表示对记忆单元的更新,表示遗忘多少信息以及当前输入信息哪些需要更新到当前的记忆单元中。式(5)产生当前的输出结果,由输出门决定最终哪些信息输出。
Li等人的研究[7]表明LSTM模型在许多情感分析任务中的表现要优于标准的循环神经网络(RNN)模型。在此基础上,Graves等人[8]提出了双向长短记忆网络(Bidirectional Long Short-Term Memory,Bi-LSTM)。它使用两个LSTM网络从前后两个方向共同训练,并同时连接至同一输出层,从而获得了捕捉过去和将来信息的能力。它避免了传统LSTM由于序列化处理而无法捕捉上下文的信息的缺点。
2.2 Attention注意力机制
注意力模型能够区分各目标单元的重要程度,从而更有利于模型发现重要特征。最早运用于图像分类任务,随后Bahdanau等人[9]将其应用于自然语言处理领域。传统的自注意力机制可以用式(6)、(7)、(8)表示,其中:hi为输入隐向量,tanh为激活函数,t为原语句序列长度。

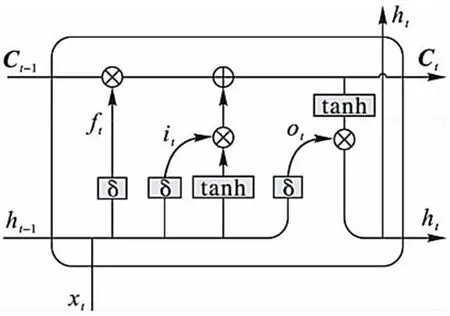
图1:LSTM记忆单元结构
3 基于Bi-LSTM+Attention的情感分析模型
本章将介绍使用Bi-LSTM+Attention模型实现对电影评论的情感倾向性进行分析。使用的深度学习框架是Keras,后端使用TensorFlow,编程语言为Python。
3.1 数据分析与预处理
神经网络中输入的所有文本向量组需要有相同的维度,因此需要对文本进行切割。本文首先使用空格对单词进行切割。经统计语料规模为239600,总单词量为5742708,文本最大长度2450。从图2可以看出,大部分文本长度在1000以内。为尽量保留文本信息的同时提高训练效率,本文截取1000作为文本的长度,长度不足的用0补齐。
原始的文本数据中存在未处理的html标签、换行符等无用字符。因此,需要对数据进行清洗。本文使用Python中的Beautiful Soup进行纯文本数据搜集。

表1:在IMDB数据集上的实验结果
3.2 构造词向量与训练文本矩阵
由于计算机无法直接理解文本,故要将文本表示成词向量的形式。主要方法有:词袋、TF-IDF、Fasttext、Glove、Word2vec 等。前两种方法无法结合上下文信息表征词特征,Fasttext使用所有词的词向量平均来表示一个文本,这对于词序敏感的情感分析而言并不合适。Glove通过对“词-词”共现矩阵分解得到词表示,它能够使用全局信息,因此对于词序要求较高的情感分析任务而言较为适合。本文在使用Glove对文本进行词向量表示。在得到词向量后,即可将每一个文本通过文词向量拼接进行表示。
3.3 情感分析模型
由于循环神经网络(RNN)在文本处理方面的优势,本文使用其变种LSTM和GRU分别进行情感分析。为了克服LSTM的方向性缺点,采用了Bi-LSTM和Bi-GRU结构对模型进行了进一步优化。其中,Embedding层为词向量层,输入文本长度为1000,词向量维度为100;Embedding层之后接入Bi-LSTM进行特征提取;模型中加入了Dropout以防止过拟合;加入Dense层将提取的特征进行整合,对提取的特征进行全连接。最后通过一个判别函数输出所属类别。经过测试,模型在第6次迭代时到最优,准确率为89.28%。
在此基础上,本文增加了Attention机制。即在得到句子的向量表示时对评论文本中不同的词赋予不同的权值,然后由这些不同权值的词向量加权得到句子的向量表示。其模型网络结构如图2所示。
模型共进行了10次迭代,在第五次迭代之后在测试集上的准确率最高,为89.94%,相较于Bi-LSTM,准确率提升了0.66%。

图2:Bi-LSTM+Attention网络结构
4 实验分析与结论
本文使用所使用的数据集为IMDB影评数据集,共25000条数据,数据来源为:https://www.kaggle.com/c/word2vec-nlp-tutorial/data。模型中,文本长度为1000,词向量维度为100;其中Bi-LSTM隐藏层有64个神经元,Adam的学习率为0.001,dropout为0.5;同时设置双向LSTM的层数为128层。
实验将Bi-LSTM模型与Bi-RNN(LSTM、GRU)、BiLSTM+Attention与Fasttext三种具体算法的精度和召回率进行了对比,如表1所示。在对比实验中,我们发现Bi-GRU模型在第4个epoch得到了最高的准确率88.18%,但GRU的整体结果没有LSTM好。使用Attention机制后,BIGRU与Bi-LSTM模型的精度均有提升,分别为0.98%和0.66%,Bi-LSTM+Attention模型达到了89.84%的最高的精度。
