盖孜河谷溜石坡调查和易发性分布数据集
2019-11-17田德宇张耀南韩立钦康建芳罗立辉艾鸣浩敏玉芳
田德宇,张耀南,韩立钦,康建芳,罗立辉,艾鸣浩,敏玉芳
1. 中国科学院西北生态环境研究院,科学大数据中心,兰州 730000
2. 中国科学院大学,北京 100049

数据库(集)基本信息简介
引 言
中巴公路从帕米尔高原东北缘穿过了公格尔-慕士塔格-昆盖山的冰缘地带(Preglacial Region)(图1),这里属于塔里木河的支流喀什葛尔河流域的主要组成部分。崩塌及其次生灾害溜石坡在盖孜河谷的公路两侧广泛发育,堆积物有砂石也有大的砾石,其缓慢前进对公路边坡损害较大,堆积物甚至可以蔓延到路面,在强大外力作用下的迅速推进容易彻底堵塞交通[1]。特别是,溜石坡是中巴公路北部地区广泛发育的一类天然崩积坡,呈锥形或面坡形态沿公路延伸,其形态、颗粒、沉积等特征有别于川藏公路沿线的典型溜砂坡[2]。王宗盛[1]对中巴公路(国内段)的溜石坡灾害有过调查研究,但是少见针对这类灾害的评价模拟,也未形成溜石坡的分布数据集,因此本工作对于溜石坡灾害的评价模拟研究具有较为重要的意义,在工程地质防治方面具有启迪和应用价值。

图1 盖孜河谷所在流域示意图
基于数据驱动的方法的一个重要建模思路是机器学习,近年来被广泛用于地质灾害的评价模拟研究。针对地质灾害的评价模拟,虽然基于规则的方法在样本数据未知的情况下具有一定的优势,但是机器学习方法的优化问题求解能力和对随机过程的模拟能力远远优于基于规则的方法。溜石坡调查资料是珍贵的现场地质调查资料,该数据利用GPS测量在盖孜河谷采集。本文基于溜石坡调查资料进行数据驱动建模得到溜石坡的空间分布数据集。本数据集在灾害评价研究领域和工程地质领域都具有潜在的可重用性。
1 数据采集和处理方法
1.1 数据来源与预处理
在同一个坐标空间对慕士塔格山周围的ASTER GDEM产品、STRM DEM产品以及ASTER L1T单景DEM制作三维散点图(图2),发现ASTER L1T单景DEM(图中红色)有明显异常,ASTER GDEM(图中绿色)和STRM DEM(图中黄色)无明显异常,但是STRM DEM最大值比慕士塔格峰主峰海拔多出200 m以上,而ASTER GDEM的最大值最接近最高值,最终选择ASTER GDEM参与到整个研究中。
土壤类型数据依据联合国粮农组织制作的 FAO土壤分类体系,拥有优于 1公里的水平分辨率[3]。在这个分类体系下,不同类型土壤数据定义可能不同:比如浅层土(Leptosol,LP)是依据土壤形成的地形条件定义,主要指侵蚀的高地。钙积土(Calcisol,CL)、石膏土(Gypsisol,GY)、栗钙土(Kastanozem,KS)、黑土(Phaeozem,PH)等是依据土壤形成的气候、时间以及有机体等条件定义。该数据可在寒区旱区科学数据中心免费获取(http://westdc.westgis.ac.cn/data/844010ba-d359-4020-bf76-2b58806f9205),中国境内的数据源为第二次全国土地调查的1∶100万土壤数据。将研究区的数据重投影为UTM Zone 43N World WGS-84坐标系,重采样为30 m的分辨率。根据这份数据,研究区内除冰川外共有土壤类型12种。基于这份数据的对比分析发现:其一,这份数据的冰川(代码11930)范围与Landsat 8 运行陆地成像仪(Operational Land Imager,OLI)融雪末影像提取的最新冰川的边缘差异很大;其二,冰川末梢冰缘地带的土壤类型均为薄层土。因此对获得研究区的这份土壤类型数据进行修正,调整后的土壤类型包含5类,分别是浅层土、黑土、石膏土、钙积土、栗钙土,此外还有冰川、水体2种水体。
区域岩性地图来自汉堡大学的Hartmann等[4]制作的全球岩性矢量数据,这份岩性数据在研究区范围内的岩性图由新疆地质矿产局采集自1992年,数据格式是shapefile文件,比例尺1∶150万,在冰川区内无数据。依据此概略岩性图,研究区内以碳酸盐沉积岩(Carbonate Sedimentary Rocks,SC)和松散沉积物(Unconsolidated Sediments,SU)为主,此外还有混合沉积岩(Mixed Sedimentary Rocks,SM)和酸性火成岩(Acid Plutonic Rocks,PA)。以1∶150万的区域岩性图为地面真值概览底图,基于地质学的理论知识,利用ASTER TIR和Landsat OLI传感器的数据提取岩性指标,来对区域岩性图的岩性类型做出更细致的解释,最终制备一份30 m空间分辨率的岩性地质填图。
溜石坡调查数据是重要的地面真值数据(Ground Truth),中科院成都山地灾害研究所周公旦老师提供了2017年融雪期的地质灾害调查数据。该数据集包含多处溜石坡灾害点的经纬度位置信息。基于正射影像图的室内目视解译对这份调查数据进行核实,并用来进行溜石坡灾害易发性的机器学习建模。图1包含了灾害调查点分布的概览信息。利用GF-1号PMS数据融合镶嵌的中巴公路喀什至伊斯兰堡段正射影像图用作调查底图和辅助地质调查的资料。
文中采用的数据见表1。

表1 数据来源列表
1.2 数据处理步骤
1.2.1 孕灾因子遴选与特征矩阵构建
基于精度可靠的 DEM 提取的各种地形因子是地质灾害易发性分析的重要的孕灾因子。本文基于Conrad等[5]开源的SAGA GIS系统提取多种孕灾因子用于冰缘灾害的评价研究中,这些因子可以分为基本的地形因子、水文学因子、形态测量学因子(Morphometry)以及岩土水力学因子4类。这些地形因子与岩性类型、土壤类型一道作为溜石坡易发性评价的孕灾因子,全面刻画了溜石坡灾害的孕灾环境,但是难免会有冗余。借鉴数据仓库的理念[6],整合(integration)特征来消除冗余(redundancies)和不一致(inconsistencies)。离散特征的冗余检测采用皮尔逊χ2统计量q的假设检验,其计算如式(1)[7]。皮尔逊χ2检验的原假设H0是两个变量相互独立,当且仅当q<χ21-p(df-1)时接受H0。其中,p是显著性水平,自由度df=(c-1)×(r-1)[7]。在χ2检验中,针对离散变量A和B,假设A有c个唯一值为a1,a2,…,ac,B有r个唯一值为b1,b2,…,br。A的c个值为列,B的r个值为行,构成列联表(contingency table)。在这个表中,每个a值会和对应的b值相遇构成联合事件(Ai,Bj),占据矩阵的一个位置。相关统计量称作皮尔逊χ2统计。式中,oij是联合事件(Ai,Bj)的观测频率,eij是该联合事件的期望频率:

对于任意的连续数值变量A和B,使用经典的皮尔逊相关性检验进行判别,相关统计量为rA,B或者其平方形式r2,在统计机器学习模型中要避免rA,B大的连续变量对同时输入到模型中。图3是经过以上冗余检测后得到的孕灾因子集合。
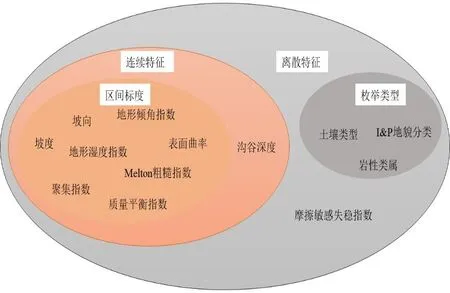
图3 冗余检测后的孕灾因子集合
统计机器学习模型往往需要输入样本服从一定的分布,至少要服从一定的输入规范。本文选择的半监督学习方法会涉及到欧式距离的计算,因此需要对离散特征编码和对连续特征标准化(Standardization)处理。
特征矩阵中包含4个离散变量和9个连续变量。离散变量中包括岩性类属、地表分类[8]、土壤类型3个类别变量和摩擦敏感失稳指数1个二值变量。利用OneHot编码器来对4个离散变量编码,经过OneHot编码后4个离散变量转换为了31维的二进制变量,这个31维的二进制特征和连续特征组成包含40个特征的特征矩阵。
新的特征矩阵中有比率标度也有区间标度,有的单位是弧度也有的无单位,而且取值范围参差不齐,在建模之前要进行标准化,这里选择最小最大标准化方法来处理。对于任意特征X,最小最大标准化方法首先利用样本的最大值和最小值来将其约束为̇,之后继续将̇标准化到用户定义的区间[a, b]为̇。式中min和max分别为求序列的最小值和最大值的函数。

特征遴选、特征整合、特征编码、特征转换是特征工程的完整流程。特征编码和转换的完整处理流程见图4。
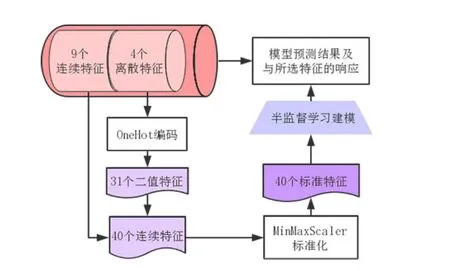
图4 特征编码和转换的流程
1.2.2 算法选择和溜石坡调查数据扩充
野外地质调查很难采集足量的样本来建立监督学习模型,小样本驱动监督学习模型是一个挑战,本文尝试采用半监督(Semi-Supervised)学习的方法来解决这个问题。
半监督学习基于少量的带标签训练样本便可得到不错的预测效果,其原理是标签传播,即对输入数据集中所有样本构建一个相似性图来给无标签数据赋予类别标签。相比Zhu等[9]提出的标签传播方法,Zhou等[10]的方法最小化一个包含正则属性的损失函数,因此该方法更具鲁棒性。本文选择Zhou的方法,算法实现基于Scikit-Learn[11],可供选择的核方法有径向基函数(RBF)和K近邻(KNN),这两种核函数都是在欧式空间计算距离,径向基函数能够将特征映射到高维空间,但是时间复杂度和空间复杂度都很高,K近邻具有更高的计算效率和更低的空间复杂度。
溜石坡灾害调查点数据于2017年夏天采集自中巴公路盖孜河谷两侧,数据格式是矢量点文件。将灾害调查点数据叠加到 GF-1号正射影像中可以清楚地看到溜石坡的形状和分布特点,发育在公路两侧的溜石坡基本呈扇形延伸到河谷以及公路,有的甚至可以蔓延到对岸。图5a是昆盖山东坡的一个溜石坡点,图5b是盖孜河谷公格尔山西坡上的一个溜石坡灾害点,公路等基础设施以及一些村落直接建在溜石坡上,潜在危害巨大。
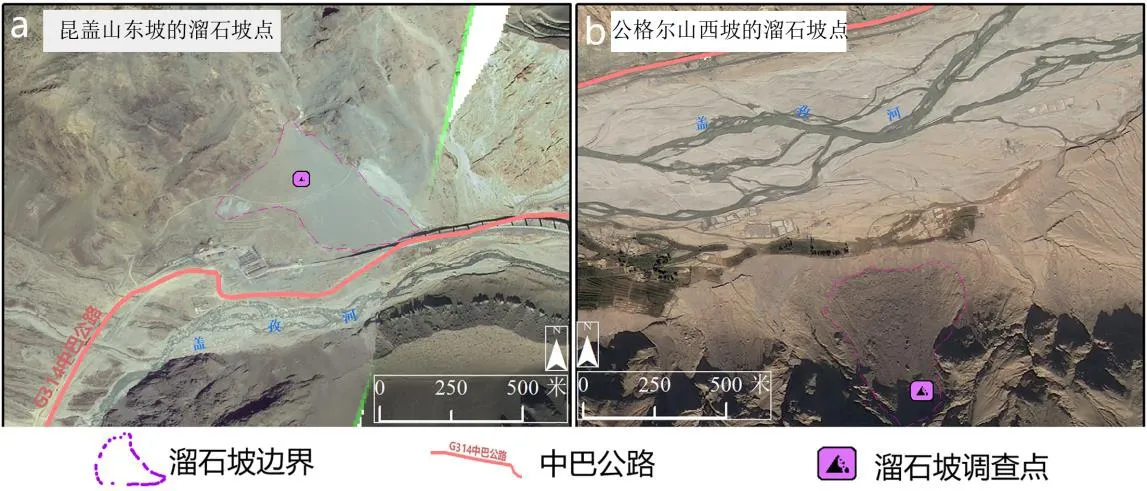
图5 溜石坡调查数据叠加GF-1号影像
本研究采取基于格网点的机器学习模型构建策略,也就是说每个格网点是一个样本。选用的标签传播式半监督学习算法对样本量的要求不高,只要将未知标签和已知标签的比例控制在60∶1左右便可,即有类别标签的格网点占比为1/60左右。通过溜石坡调查点和GF-1号正射影像图叠加可以明显地看到溜石坡的轮廓(图5),基于溜石坡调查资料勾绘得到的矢量图形作为模型训练的标签数据,特征矩阵作为模型训练的初始特征集合进行模型训练。
1.2.3 机器学习模型训练与参数选择
为了权衡预测精度和算法的复杂度(包括时间复杂度和空间复杂度),K近邻被选用为标签传播模型的核函数,K进邻是典型的基于距离的机器学习算法,又被称作懒惰学习。K近邻对每一个无标签数据寻找其在训练集中K个最近的邻居,将邻居中出现次数最多的类别标签赋给无标签数据,迭代这个过程直到所有样本都赋予标签。K近邻的计算流程如图6。

图6 基于KNN的半监督学习计算过程
显然,核函数K近邻的一个重要的超参数是用于邻域距离计算的邻域点个数K,K值直接影响模型的0精度,因此得到最优的K值是至关重要的参数选择问题。调整K值来查看验证集上的精度。当K=18时,验证集中正样本、负样本以及全局精度达到最大。另一个重要的参数是迭代次数,不过迭代次数达到30就已经收敛且是稳定的,所以调整迭代次数到收敛即可。
1.2.4 溜石坡易发性空间区域预测
利用建立的模型遍历公路两侧2公里的范围得到中巴公路在盖孜河谷沿线的潜在溜石坡易发区。虽然建模特征中没有包含任何光学遥感数据的光谱特征和纹理特征,但是模型在盖孜河谷公路两侧2公里的缓冲区内的预测结果与GF-1号正射影像图中目视解译出来的灾害区高度匹配,即使目视看来有不少疑似错判的地方。
2 数据样本描述
本数据集提供盖孜河谷的溜石坡调查GPS点矢量文件和基于调查点模拟得到的中巴公路两侧2公里范围内的溜石坡易发性分布栅格文件。
图7中展示了溜石坡调查点的分布情况和溜石坡易发性预测结果的空间分布,紫色区域是预测为溜石坡的区域。

图7 溜石坡易发性分布图
3 数据质量控制和评估
3.1 原始数据质量控制
参与岩性填图的Landsat OLI数据采取了严格的大气校正,而ASTER TIR数据的岩性指数反演直接基于星上辐射值(radiance at sensor)进行,这是经过前人研究论证的[12]。DEM数据的质量保证是经过比较不同来源的DEM产品来选择最接近研究区真实高程的DEM产品。土壤类型数据经过了基于Landsat OLI提取的融雪末冰川范围的修正来保证该数据在研究区的真实性。对研究区1∶150万岩性地图的遥感填图扩充了岩性的类属,遥感岩性填图的准确性通过设置合理的波段指数下限阈值来保证,即使用波段指数提出者所建议的阈值或更高的阈值进行岩性制图。
3.2 溜石坡预测结果评价
实验证明,少量样本训练出来的半监督学习模型还是比较理想的,在验证集上正样本精度能够达到57%以上,负样本精度在99%以上,总体精度接近80%(图8)。首先,负样本的预测精度拉高了模型的总体精度;其次,基于精度的分析可以得到,如果一个格网点不是溜石坡就一定不会被预测为溜石坡,但如果是溜石坡便极有可能被预测为非溜石坡,也就是说即使溜石坡的预测精度不是很高,但是非溜石坡不会错判为溜石坡。
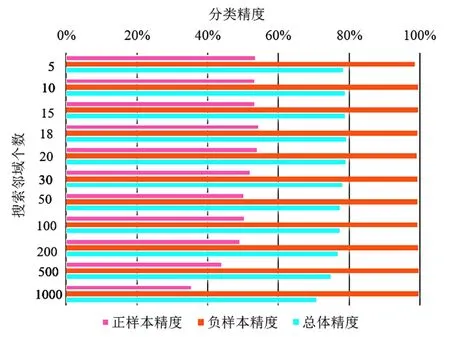
图8 模型精度评价
4 数据使用方法和建议
溜石坡调查点数据为矢量SHP格式,属性表中记录了经度和纬度信息。溜石坡易发性分布数据保存为栅格TIF格式,二者叠加显示最佳。ArcGIS、QGIS、ENVI、ERDAS等常用的GIS与遥感软件可支持该数据的读取和操作。
致 谢
感谢国家特殊环境、特殊功能观测研究台站共享服务平台给与的项目支持。感谢中科院成都山地所周公旦研究员提供2017年的溜石坡调查资料。
